このチュートリアルでは、2 種類の異種ソース(ApsaraDB RDS for MySQL のテーブルと Object Storage Service (OSS) のファイル)から DataWorks のデータ統合バッチ同期タスクを用いて MaxCompute へデータを読み込む手順について説明します。完了後、両方のデータセットはパーティション化された MaxCompute テーブルに格納され、毎日スケジュール実行されます。
実施内容:
ワークフローの設計およびスケジューリングロジックの構成
送信先 MaxCompute テーブルの作成
MySQL および HttpFile データソースの追加
2 つのバッチ同期タスクの構成
ワークフローの実行および結果の検証
前提条件
開始する前に、以下の準備が完了していることを確認してください。
同期対象データ
| ソース | オブジェクト | 内容 | 送信先テーブル |
|---|---|---|---|
MySQL (user_behavior_analysis_mysql) | テーブル:ods_user_info_d | 基本的なユーザー情報 | ods_user_info_d_odps |
HttpFile (user_behavior_analysis_httpfile) | ファイル:user_log.txt | Web サイトアクセスログ | ods_raw_log_d_odps |
テストデータおよびデータソースは、本チュートリアル向けに事前にプロビジョニングされています。ご利用のワークスペースでデータソース情報を登録するだけで、これらのリソースにアクセスできます。すべてのデータは合成データであり、Data Integration 内では読み取り専用です。
ステップ 1:ワークフローの設計
ワークフローの作成および設計
DataWorks における開発は、ワークフロー単位で管理されます。ノードを追加する前に、まずワークフローを作成します。
DataStudio に移動します。DataWorks コンソールにログインします。上部ナビゲーションバーで対象リージョンを選択します。左側ナビゲーションウィンドウで、データ開発および運用 > データ開発 を選択します。ドロップダウンリストからワークスペースを選択し、データ開発へ移動 をクリックします。
User profile analysis_MaxComputeという名前のワークフローを作成します。手順については、「ワークフローの作成」をご参照ください。
ワークフローの設計を行います。ワークフローキャンバスが開いたら、ツールバーの ノードの作成 をクリックします。ノードをキャンバス上にドラッグし、線を引いてデータ同期のスケジューリング依存関係を設定します。レイアウトは「ワークフロー設計」に基づきます。本チュートリアルでは、以下の 3 つのノードを使用します。ゼロロードノードと同期ノード間にはデータリネージがないため、キャンバス上で線を引くことで依存関係を構成します。詳細については、「スケジューリング依存関係の構成ガイド」をご参照ください。
ノードタイプ ノード名 目的 ゼロロードノード workshop_start_odps毎日 00:30 にワークフロー全体をトリガーします。このノードにはコードは不要です。 バッチ同期 ods_user_info_d_odpsMySQL から基本的なユーザー情報を MaxCompute へ同期します。 バッチ同期 ods_raw_log_d_odpsOSS から Web サイトアクセスログを MaxCompute へ同期します。 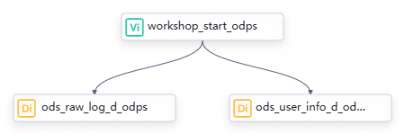
スケジューリングロジックの構成
workshop_start_odps ゼロロードノードがワークフロー全体をトリガーします。このノードを毎日 00:30 に実行するよう構成し、完了後に同期ノードが自動的に実行されるようにします。他のノードのスケジューリング設定はデフォルトのままとします。
workshop_start_odps に依存しているため、ワークフローはこのノードによってトリガーされます。| 構成項目 | 設定値 | 説明 |
|---|---|---|
| スケジューリング時刻 | 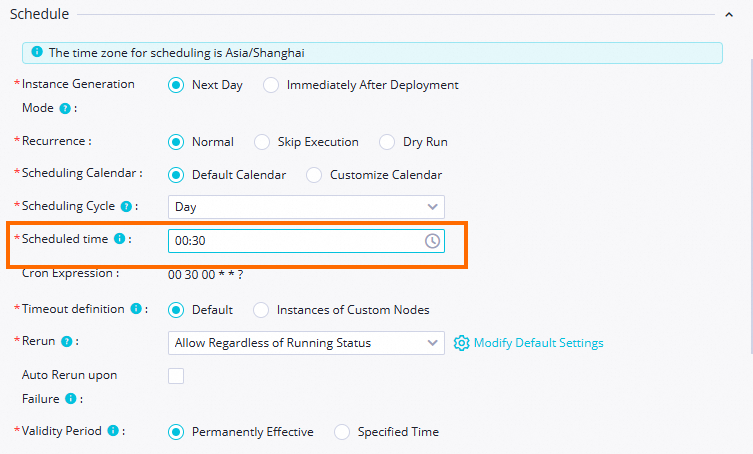 | 00:30 に設定します。ゼロロードノードは、この時刻に毎日ワークフローをトリガーします。 |
| スケジューリング依存関係 | 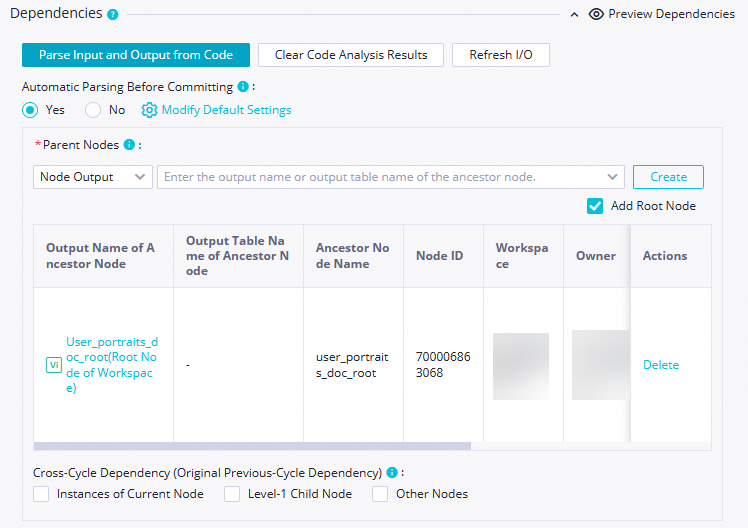 | workshop_start_odps ノードには先祖ノードがありません。ワークスペースのルートノードに依存するよう設定することで、このゼロロードノードをトリガーします。 |
スケジューリング構成の詳細については、「異なるシナリオにおけるワークフロー内ノードのスケジューリング時刻の構成」および「概要」をご参照ください。
ステップ 2:送信先 MaxCompute テーブルの作成
同期タスクの構成前に、同期データを格納する 2 つの MaxCompute テーブルを作成します。MaxCompute テーブル操作に関する一般的な情報については、「MaxCompute テーブルの作成および管理」をご参照ください。
テーブル作成のエントリポイントに移動します。
ods_raw_log_d_odpsテーブルを作成します。テーブルの作成 ダイアログボックスの 名前 フィールドにods_raw_log_d_odpsを入力します。DDL をクリックし、以下の文を貼り付け、テーブルスキーマの生成 をクリックします。確認 ダイアログボックスで 確認 をクリックして適用します。CREATE TABLE IF NOT EXISTS ods_raw_log_d_odps ( col STRING ) PARTITIONED BY ( dt STRING ) LIFECYCLE 7;ods_user_info_d_odpsテーブルを作成します。テーブルの作成 ダイアログボックスの 名前 フィールドにods_user_info_d_odpsを入力します。DDL をクリックし、以下の文を貼り付け、テーブルスキーマの生成 をクリックします。確認 ダイアログボックスで 確認 をクリックして適用します。CREATE TABLE IF NOT EXISTS ods_user_info_d_odps ( uid STRING COMMENT 'ユーザー ID', gender STRING COMMENT '性別', age_range STRING COMMENT '年齢層', zodiac STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING ) LIFECYCLE 7;両方のテーブルをコミットおよびデプロイします。各テーブルの構成タブで、開発環境へのコミット をクリックし、その後 本番環境へのコミット をクリックします。DataWorks は、それぞれの環境に関連付けられた MaxCompute プロジェクト内に物理テーブルを作成します。
説明 開発環境へのコミットは、開発環境に関連付けられた MaxCompute プロジェクト内にテーブルを作成します。本番環境へのコミットは、本番環境のプロジェクト内にテーブルを作成します。
ステップ 3:データソースの追加
同期タスクの構成前に、ワークスペース内に両方のデータソースを登録します。これにより、各タスクの構成時に名前でデータソースを選択できるようになります。
両方のソースのテストデータはインターネット上にホストされています。リソースグループに対してインターネット NAT ゲートウェイが構成されていることを確認してください(「ステップ 2」を参照)。構成されていない場合、接続性テストは以下のエラーで失敗します。
HttpFile:
ErrorMessage:[Connect to dataworks-workshop-2024.oss-cn-shanghai.aliyuncs.com:443 [...] failed: connect timed out]MySQL:
ErrorMessage:[Exception:Communications link failure ... Root Cause:[connect timed out]]
データソース ページに移動するには、以下の手順を実行します。
DataWorks コンソールにログインします。上部ナビゲーションバーで対象リージョンを選択します。左側ナビゲーションウィンドウで、その他 > 管理センター を選択します。ワークスペースを選択し、管理センターへ移動 をクリックします。
左側ナビゲーションウィンドウで、データソース をクリックします。
MySQL データソースの追加
MySQL に格納された基本的なユーザー情報を読み取るため、ApsaraDB RDS for MySQL データソースを追加します。
データソース ページで、データソースの追加 をクリックします。
データソースの追加 ダイアログボックスで、MySQL をクリックします。
MySQL データソースの追加 ページで、以下のパラメーターを入力します。
説明 データソースは 開発環境 および 本番環境 の両方に追加してください。いずれかを省略すると、関連するタスクが実行時に失敗します。パラメーター 値 データソース名 user_behavior_analysis_mysqlデータソースの説明 DataWorks チュートリアルのユースケース用。バッチ同期の読み取り専用ソース。 構成モード 接続文字列モード 環境 開発・本番 ホスト IP アドレス rm-bp1z69dodhh85z9qa.mysql.rds.aliyuncs.comポート番号 3306データベース名 workshopユーザー名 workshopパスワード workshop#2017認証方式 認証なし 
接続構成 セクションで、ご利用のサーバーレスリソースグループを見つけ、ネットワーク接続性のテスト をクリックします。開発環境および本番環境をそれぞれ個別にテストします。テストが成功すると、ステータスが 接続済み に変わります。
HttpFile データソースの追加
OSS に格納された Web サイトアクセスログを読み取るため、HttpFile データソースを追加します。
データソース ページで、データソースの追加 をクリックします。
データソースの追加 ダイアログボックスで、HttpFile をクリックします。
HttpFile データソースの追加 ページで、以下のパラメーターを入力します。
説明 データソースは 開発環境 および 本番環境 の両方に追加してください。いずれかを省略すると、関連するタスクが実行時に失敗します。パラメーター 値 データソース名 user_behavior_analysis_httpfileデータソースの説明 DataWorks チュートリアルのユースケース用。バッチ同期の読み取り専用ソース。 環境 開発環境 および 本番環境 URL ドメイン https://dataworks-workshop-2024.oss-cn-shanghai.aliyuncs.com接続構成 セクションで、ご利用のサーバーレスリソースグループを見つけ、ネットワーク接続性のテスト をクリックします。両方の環境をそれぞれ個別にテストし、それぞれが 接続済み であることを確認します。
ステップ 4:バッチ同期タスクの構成
MySQL から MaxCompute への同期
このタスクは、MySQL テーブル ods_user_info_d から読み取り、MaxCompute テーブル ods_user_info_d_odps へ書き込みます。
ods_user_info_d_odpsノードをダブルクリックして、構成タブを開きます。ソース、リソースグループ、送信先を構成し、次へ をクリックして接続性テストを完了します。
パラメーター 値 ソース MySQL— データソース名:user_behavior_analysis_mysqlリソースグループ ご利用のサーバーレスリソースグループ 送信先 MaxCompute— データソース名:user_behavior_analysis_mysql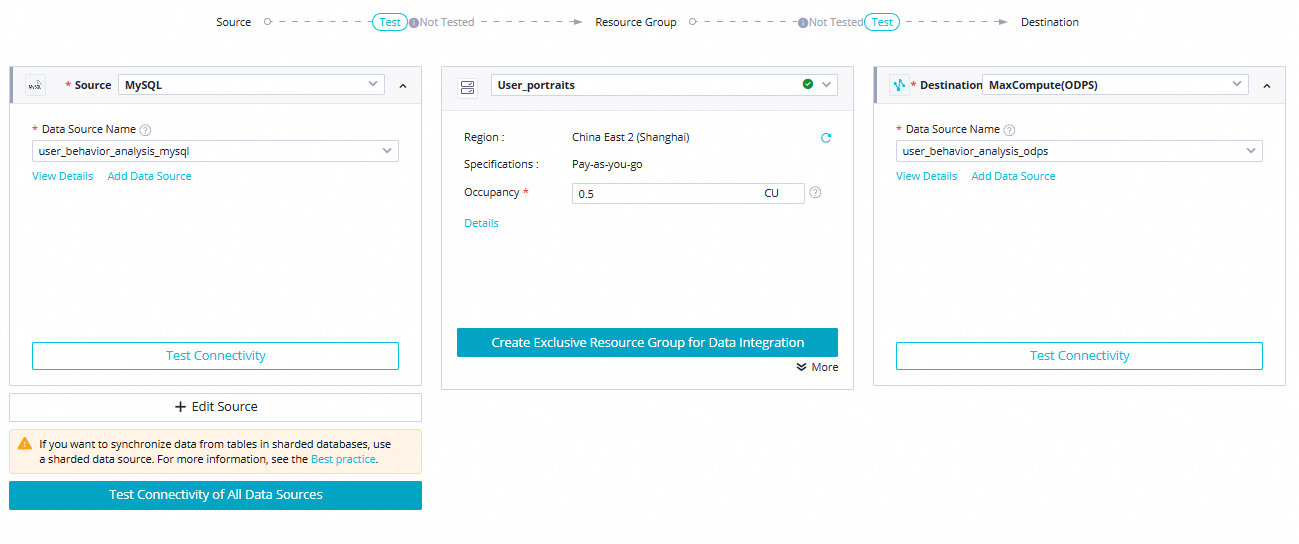
ソースおよび送信先の設定を構成します。デフォルトのフィールドマッピングおよびチャネル制御設定を使用します。利用可能なすべてのオプションについては、「コードレス UI を使用したバッチ同期タスクの構成」をご参照ください。
項目 パラメーター 値 スクリーンショット ソース テーブル ods_user_info_d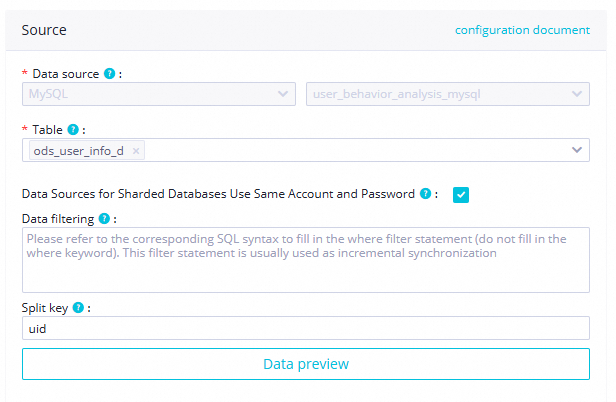
分割キー uid送信先 Tunnel リソースグループ 共通伝送リソース(デフォルト) 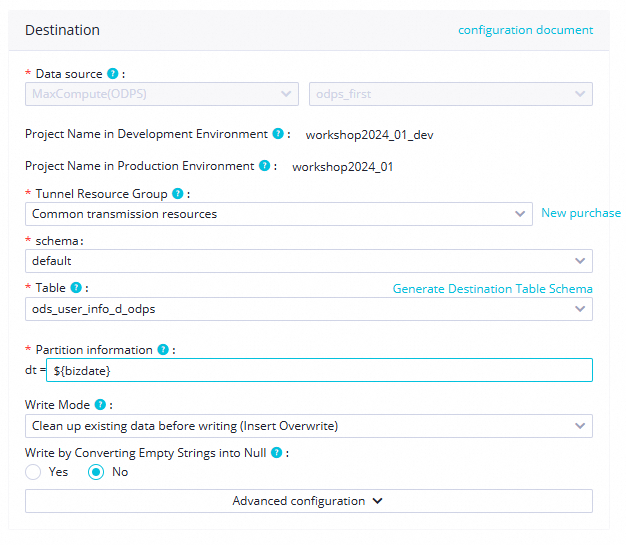
スキーマ defaultテーブル ods_user_info_d_odpsパーティション情報 ${bizdate}書き込みモード 上書き挿入(書き込み前に既存のデータをクリア) 空文字列を NULL に変換して書き込み いいえ スケジューリングプロパティを構成します。右側ナビゲーションペインで プロパティ をクリックし、以下の値を設定します。詳細については、「ノードのスケジューリングプロパティ」をご参照ください。
プロパティ 値 スクリーンショット スケジューリングパラメーター $bizdate(パラメーター名:bizdate;前日の日付をyyyymmdd形式で照会)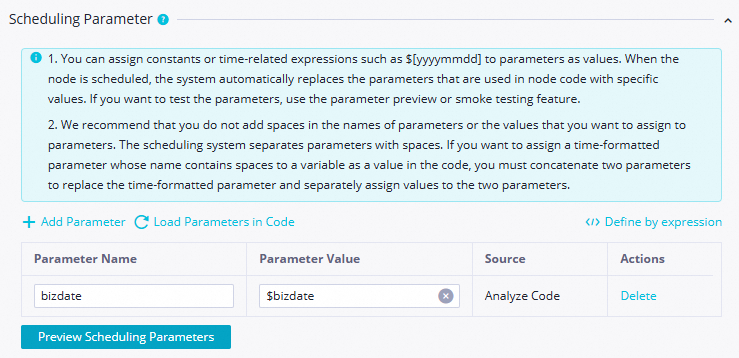
スケジューリング周期 日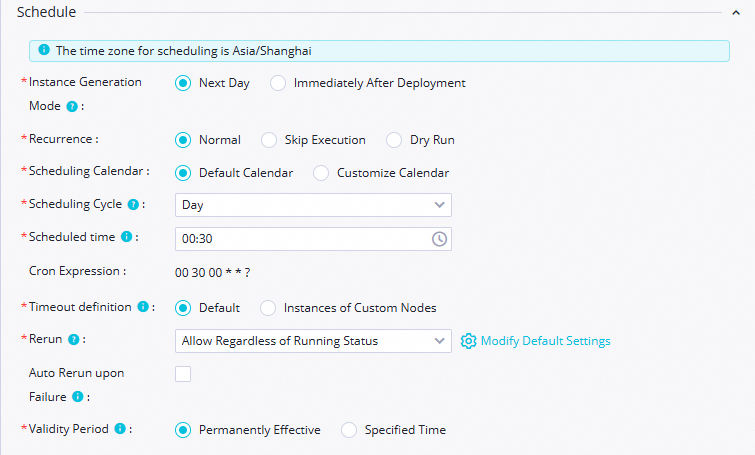
スケジュール時刻 00:30再実行 実行状態に関係なく許可 リソースグループ ご利用のサーバーレスリソースグループ 
依存関係 workshop_startが [親ノード] に表示されていることを確認します。表示されていない場合は、ステップ 1 のワークフロー設計を再確認してください。また、<本番環境の MaxCompute プロジェクト名>.ods_user_info_d_odpsという名前のノード出力が存在することを確認します。存在しない場合は、手動で追加してください。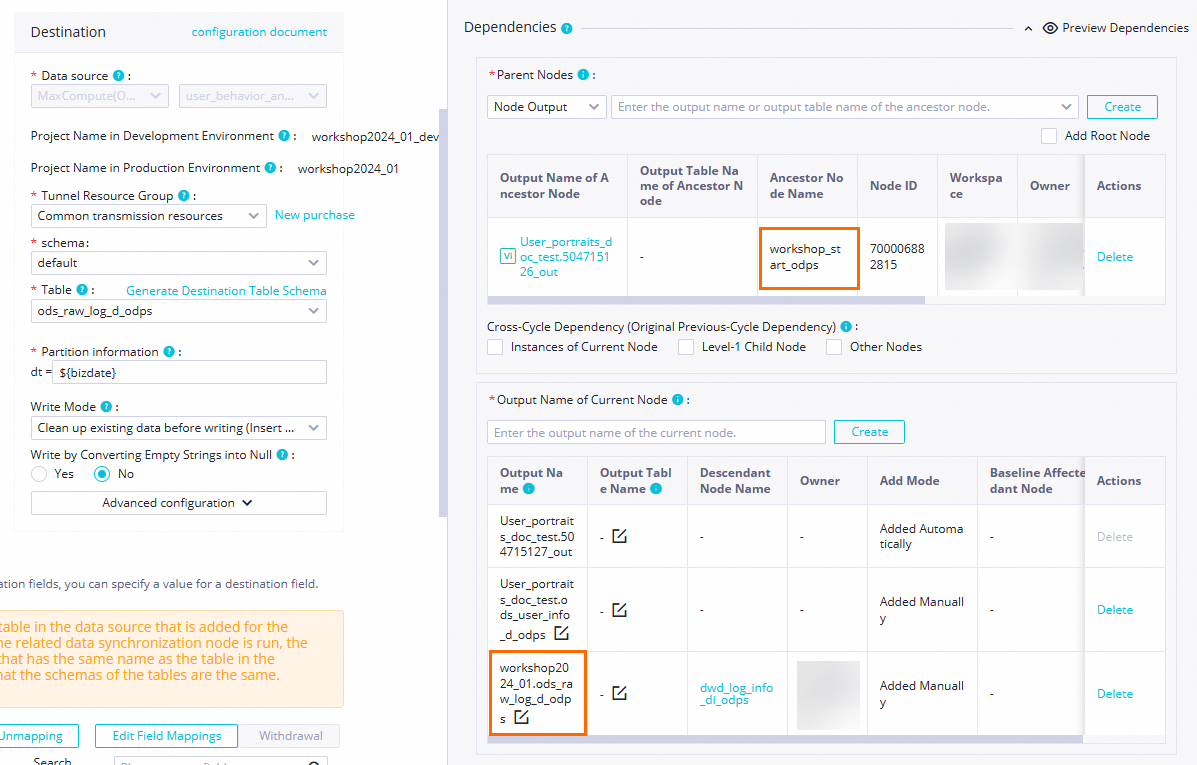
OSS ログの MaxCompute への同期
このタスクは、HttpFile ソースから user_log.txt ファイルを読み取り、MaxCompute テーブル ods_raw_log_d_odps へ書き込みます。
ログファイルは、以下の形式で各行に 1 件のアクセスレコードを格納します。
$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent"$http_referer" "$http_user_agent" [unknown_content];ods_raw_log_d_odpsノードをダブルクリックして、構成タブを開きます。ソース、リソースグループ、送信先を構成し、次へ をクリックして接続性テストを完了します。
パラメーター 値 ソース HttpFile— データソース名:user_behavior_analysis_HttpFileリソースグループ ご利用のサーバーレスリソースグループ 送信先 MaxCompute— データソース名:user_behavior_analysis_mysql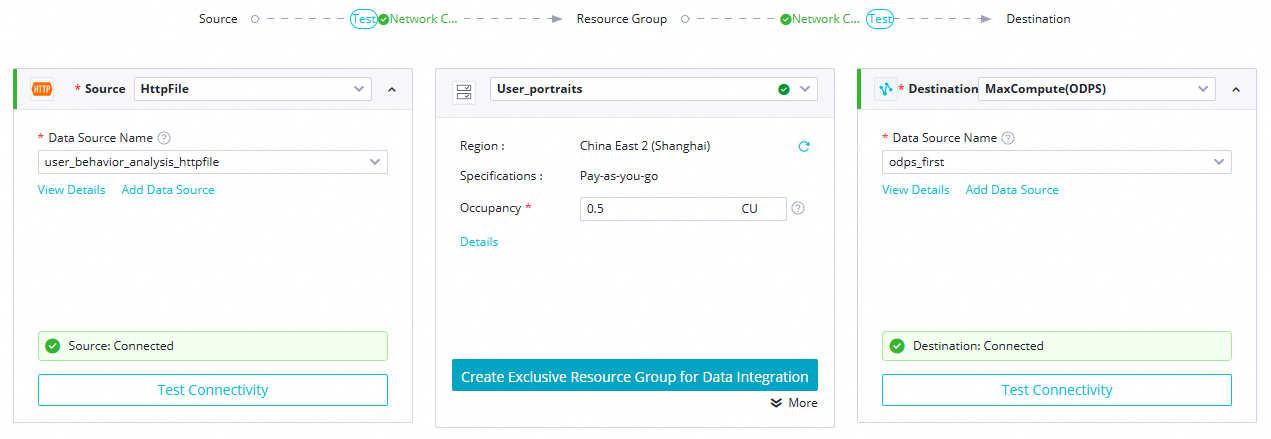
ソースおよび送信先の設定を構成します。ソースを構成した後、データ構造の確認 をクリックして、ログファイルが読み取れることを確認します。デフォルトのフィールドマッピングおよびチャネル制御設定を使用します。利用可能なすべてのオプションについては、「コードレス UI を使用したバッチ同期タスクの構成」をご参照ください。
項目 パラメーター 値 スクリーンショット ソース ファイルパス /user_log.txt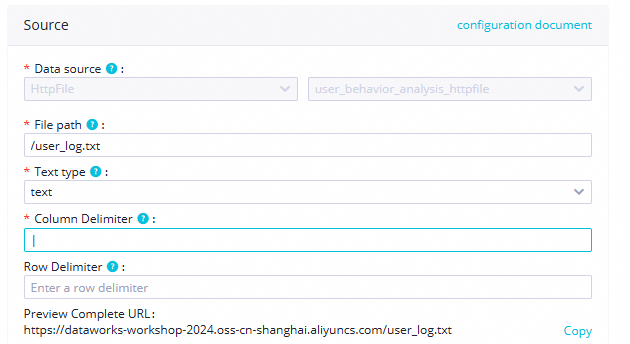
ファイルタイプ text列区切り文字 |高度な構成 コーディング UTF-8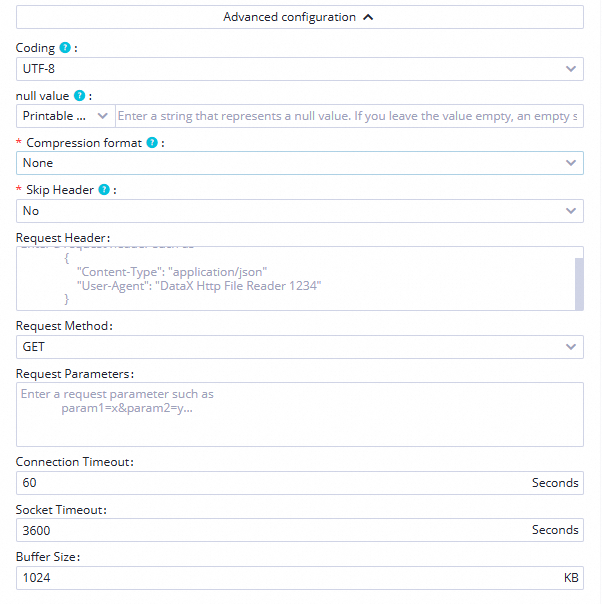
圧縮形式 UTF-8ヘッダーをスキップ いいえ送信先 Tunnel リソースグループ 共通伝送リソース(デフォルト) 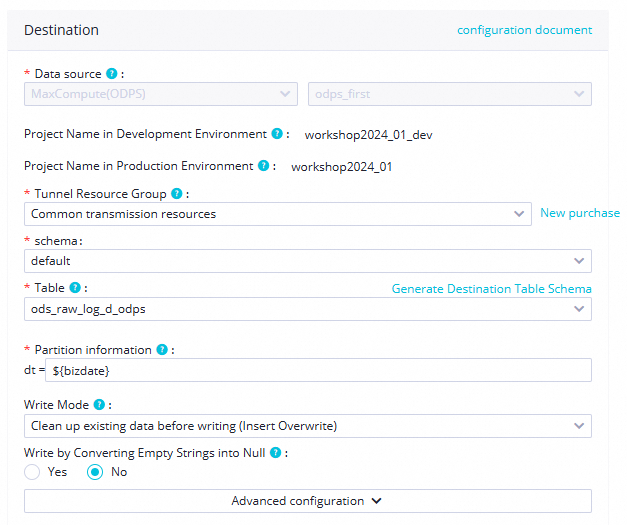
スキーマ defaultテーブル ods_raw_log_d_odpsパーティション情報 ${bizdate}書き込みモード 上書き挿入(書き込み前に既存のデータをクリア) 空文字列を NULL に変換して書き込み いいえ スケジューリングプロパティを構成します。右側ナビゲーションペインで プロパティ をクリックし、以下の値を設定します。詳細については、「ノードのスケジューリングプロパティ」をご参照ください。
属性 値 スクリーンショット スケジューリングパラメーター $bizdate(パラメーター名:bizdate; 前日の日付をyyyymmdd形式で照会します)スケジューリングサイクル Dayスケジュール時刻 00:30再実行 実行ステータスに関わらず許可 リソースグループ ご利用のサーバーレスリソースグループ 依存関係 workshop_startが [親ノード] に表示されていることを確認します。また、<本番環境の MaxCompute プロジェクト名>.ods_raw_log_d_odpsというノード出力が存在することを確認します。存在しない場合は手動で追加します。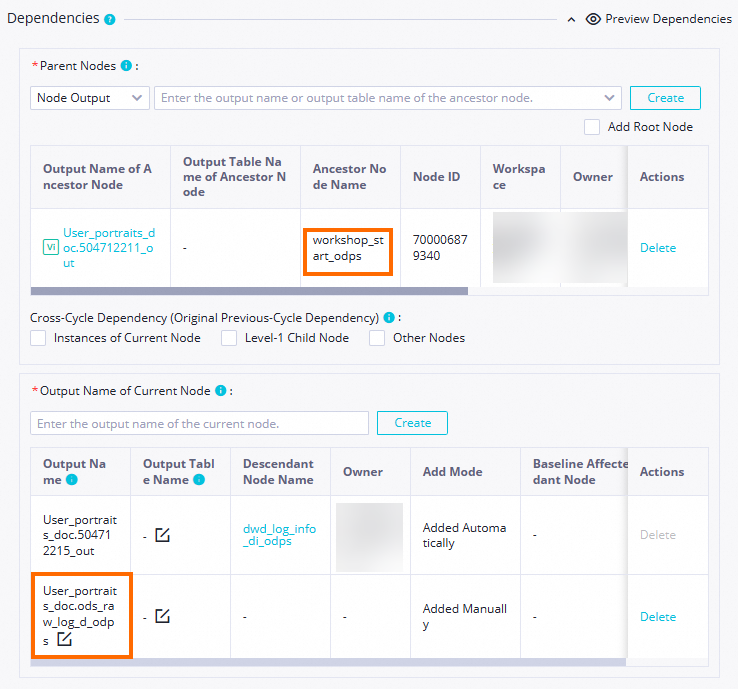
ステップ 5:ワークフローの実行および結果の検証
ワークフローの実行
DataStudio で、ビジネスフロー 下の
User profile analysis_MaxComputeワークフローをダブルクリックします。ワークフローキャンバスで、ツールバーの
 アイコンをクリックして、依存関係順にすべてのノードを実行します。
アイコンをクリックして、依存関係順にすべてのノードを実行します。ステータスを確認します:
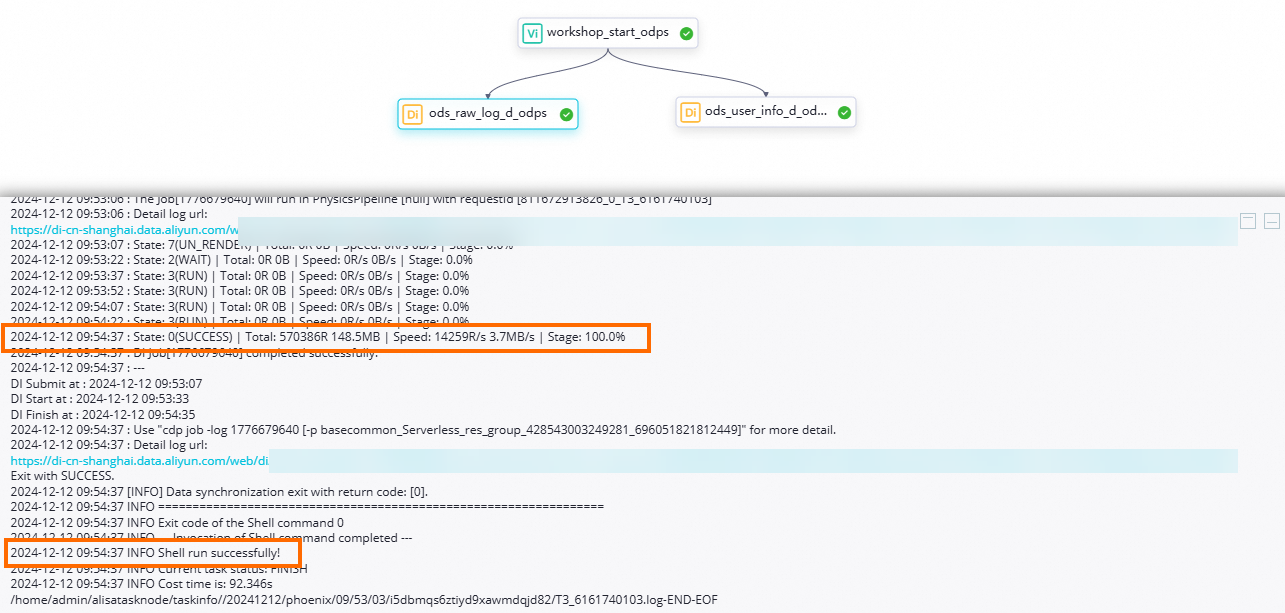
ノードのステータス:
 状態のノードは、正常に実行されたことを示します。
状態のノードは、正常に実行されたことを示します。ノードのログ:
ods_user_info_d_odpsまたはods_raw_log_d_odpsを右クリックし、ログの表示 を選択します。ログに以下のような出力が表示された場合、データの同期が完了しています。
結果の検証
正常に実行された後:
MySQL テーブル
ods_user_info_dのすべての行が、前日の日付でパーティション化されたworkshop2024_01_dev.ods_user_info_d_odpsに格納されます。OSS ファイル
user_log.txtのすべての行が、前日の日付でパーティション化されたworkshop2024_01_dev.ods_raw_log_d_odpsに格納されます。
データが正しく読み込まれたことを確認するために、アドホッククエリで行数を照会します。
DataStudio の左側ナビゲーションウィンドウで、
 アイコンをクリックします。アドホッククエリ ペインで、アドホッククエリ を右クリックし、ノードの作成 > ODPS SQL を選択します。
アイコンをクリックします。アドホッククエリ ペインで、アドホッククエリ を右クリックし、ノードの作成 > ODPS SQL を選択します。以下の SQL を実行して、行数を確認します。
データタイムスタンプを実行時のデータタイムスタンプ(例:ワークフローが 2023 年 6 月 21 日に実行された場合、データタイムスタンプは20230620)に置き換えます。select count(*) from ods_user_info_d_odps where dt='データタイムスタンプ'; select count(*) from ods_raw_log_d_odps where dt='データタイムスタンプ';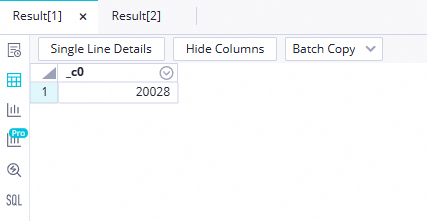
workshop2024_01_dev に表示され、本番プロジェクトには表示されません。次のステップ
データ同期は完了しました。次に、MaxCompute で読み込まれたデータを処理するための次のチュートリアルに進んでください。「データの処理」