MaxCompute のビルトイン関数がビジネス要件を満たさない場合は、ユーザー定義関数(UDF)を作成できます。本トピックでは、IntelliJ IDEA(Maven を使用)や MaxCompute Studio などのツールを使用して、MaxCompute で Java UDF を開発および呼び出す方法について説明します。
制限事項
インターネットアクセス — UDF はデフォルトではインターネットにアクセスできません。インターネットアクセスを有効にするには、ネットワーク接続申請を送信します。承認されると、MaxCompute テクニカルサポートチームが連絡を取り、接続を確立します。詳細については、「ネットワーク接続リクエストフォームネットワーク接続プロセス」をご参照ください。
VPC アクセス — UDF はデフォルトで仮想プライベートクラウド(VPC)内のリソースにアクセスできません。VPC アクセスを有効にするには、MaxCompute と VPC 間のネットワーク接続を確立する必要があります。詳細については、「UDF を使用した VPC 内リソースへのアクセス」をご参照ください。
サポートされていないテーブルタイプ — UDF、UDAF、UDTF は以下のテーブルタイプからデータを読み取ることができません。
-
スキーマ進化が実行されたテーブル
-
複合データ型を含むテーブル
-
JSON データ型を含むテーブル
-
トランザクションテーブル
注意事項
Java UDF を記述する前に、UDF コード構造 および Java データ型と MaxCompute データ型のマッピングを理解しておく必要があります。これらのマッピングの詳細については、「付録:データ型」をご参照ください。
Java UDF を記述する際は、以下の点にご注意ください。
異なる UDF JAR ファイル間で、同じクラス名だが異なるロジックを持つクラスの使用を避けてください。たとえば、リソース JAR ファイル
udf1.jarおよびudf2.jarに依存する UDF1 および UDF2 の 2 つの UDF を考えます。両方の JAR ファイルにcom.aliyun.UserFunction.classという名前のクラスが含まれているがロジックが異なる場合、同一の SQL ステートメント内で両方の UDF を呼び出すと、MaxCompute がランダムにいずれかのクラスをロードします。これにより、予期しない結果やコンパイルエラーが発生する可能性があります。Java UDF では、入力パラメーターおよび戻り値のデータ型はオブジェクトタイプである必要があります。型名は大文字で始まる必要があります(例:String)。
SQL の
NULL値は Java ではnullとして表現されます。Java のプリミティブ型は SQL のNULL値を表現できないため、使用できません。
UDF 開発ワークフロー
一般的な UDF 開発ワークフローには、準備、コード記述、UDF のアップロードおよび登録、デバッグが含まれます。MaxCompute は複数のツールをサポートしています。以下のセクションでは、MaxCompute Studio、DataWorks、MaxCompute クライアント(odpscmd)を例として、一般的な開発ワークフローを説明します。
MaxCompute Studio の使用
この例では、MaxCompute Studio を使用して文字列を小文字に変換する Java UDF を開発および呼び出す方法を示します。
環境を準備します。
MaxCompute Studio で UDF を開発およびデバッグする前に、MaxCompute Studio をインストールし、MaxCompute プロジェクトに接続する必要があります。詳細については、以下をご参照ください。
UDF コードを記述します。
Project ビューで、モジュールのソースコードディレクトリ()を右クリックし、 を選択します。
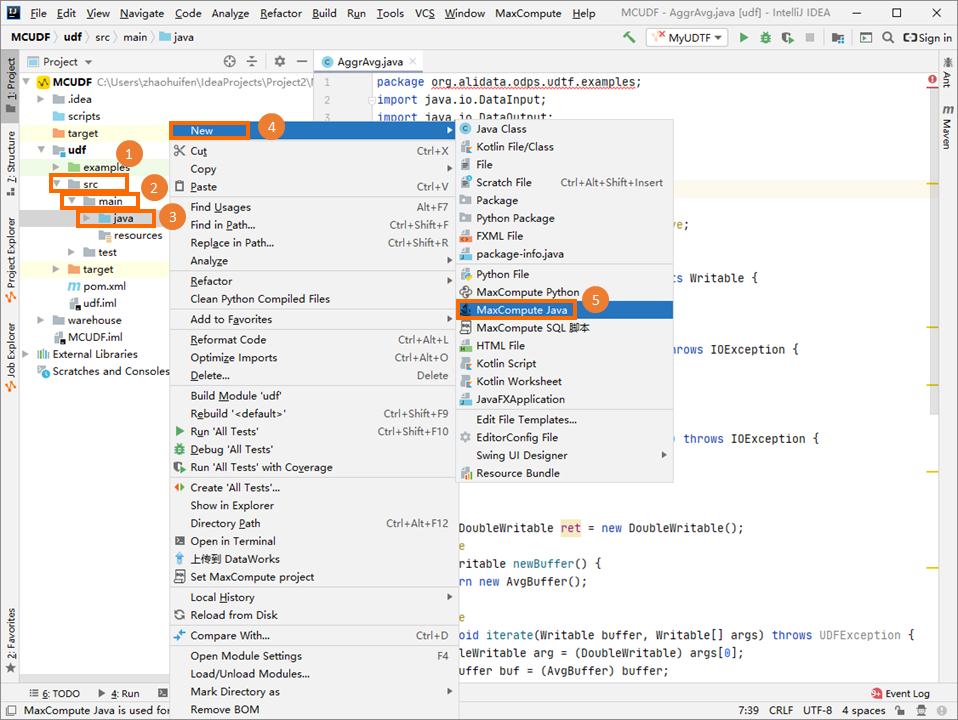
Create new MaxCompute java class ダイアログボックスで、UDF をクリックし、Name に名前を入力して Enter キーを押します。
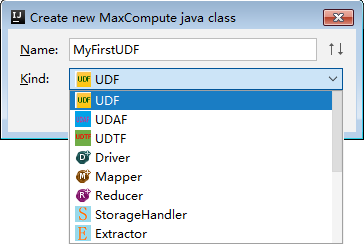
Name は MaxCompute Java クラスの名前です。パッケージを作成していない場合は、packagename.classname と入力すると自動的に作成されます。この例では、Java クラス名を Lower とします。
エディターで UDF コードを記述します。
 以下のコードがその例です。
以下のコードがその例です。package com.aliyun.odps.udf.example; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }説明Java UDF をローカルでデバッグする方法については、「UDF の開発およびデバッグ」をご参照ください。
UDF をアップロードおよび登録します。
UDF Java ファイルを右クリックし、Deploy to server... を選択します。Package a jar, submit resource and register function ダイアログボックスでパラメーターを設定し、OK をクリックします。

MaxCompute project:UDF を登録する MaxCompute プロジェクト。
Resource file:UDF が依存するリソースファイルのパス。
Resource name:MaxCompute 内での UDF の JAR ファイルリソース名。
Function name:登録される関数の名前。これは SQL ステートメントで使用する UDF 名です(例:Lower_test)。
UDF をデバッグします。
左側のナビゲーションウィンドウで Project Explore をクリックします。対象の MaxCompute プロジェクトを右クリックし、Open Console を選択します。次に、UDF を呼び出す SQL ステートメントを入力し、Enter キーを押して実行します。
 以下の SQL ステートメントがその例です。
以下の SQL ステートメントがその例です。select lower_test('ABC');以下の結果が返されます。
+-----+ | _c0 | +-----+ | abc | +-----+
DataWorks の使用
環境を準備します。
DataWorks で UDF を開発およびデバッグする前に、DataWorks を有効化し、DataWorks ワークスペースを MaxCompute プロジェクトに関連付ける必要があります。詳細については、「DataWorks からの MaxCompute 接続」をご参照ください。
UDF コードを記述します。
任意の Java 開発ツールで UDF コードを開発し、JAR ファイルにパッケージ化できます。以下のコードがその例です。
package com.aliyun.odps.udf.example; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }UDF をアップロードおよび登録します。
パッケージ化されたコードを DataWorks にアップロードし、UDF を登録できます。詳細については、以下をご参照ください。
UDF をデバッグします。
UDF を登録後、ODPS SQL ノードを作成します。ノード内で SQL コマンドを記述・実行して UDF をデバッグします。ODPS SQL ノードの作成方法については、「ODPS SQL ノードの作成」をご参照ください。以下はデバッグコマンドの例です。
select lower_test('ABC');
odpscmd の使用
環境を準備します。
MaxCompute クライアント (odpscmd) を使用して UDF を開発およびデバッグする前に、クライアントをダウンロードしてインストールします。次に、設定ファイルを構成して、MaxCompute プロジェクトに接続します。詳細については、「MaxCompute クライアント (odpscmd) を使用して MaxCompute に接続する」をご参照ください。
UDF コードを記述します。
任意の Java 開発ツールで UDF コードを開発し、JAR ファイルにパッケージ化できます。以下のコードがその例です。
package com.aliyun.odps.udf.example; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }UDF をアップロードおよび登録します。
MaxCompute クライアント(odpscmd)を使用してパッケージ化されたコードをアップロードし、UDF を登録できます。詳細については、以下をご参照ください。
UDF をデバッグします。
UDF を登録後、SQL コマンドを記述・実行して UDF をデバッグできます。以下はデバッグコマンドの例です。
select lower_test('ABC');
UDF の呼び出し
UDF を登録後、ビルトイン関数と同様に呼び出します。
プロジェクト内 — ビルトイン関数 と同様に直接 UDF を呼び出します。
プロジェクト間 — プロジェクト A からプロジェクト B の UDF を使用するには、プロジェクトプレフィックスを付けて参照します。
select B:udf_in_other_project(arg0, arg1) as res from table_t;プロジェクト間共有の設定方法については、「パッケージに基づくプロジェクト間リソースアクセス」をご参照ください。
付録:UDF コード構造
Java UDF コードには以下のコンポーネントが含まれている必要があります。
Java パッケージ:任意。
定義した Java クラスをパッケージ化することで、検索および使用が容易になります。
UDF クラスの継承:必須。
クラスは基底クラス
com.aliyun.odps.udf.UDFを継承する必要があります。他の UDF クラスまたは複合データ型を使用する必要がある場合は、MaxCompute SDK から必要なクラスを追加します。たとえば、STRUCT データ型に対応する UDF クラスはcom.aliyun.odps.data.Structです。@Resolveアノテーション:任意。形式は
@Resolve(<signature>)で、signatureは関数の入力パラメーターおよび戻り値のデータ型を定義します。ユーザー定義関数(UDF)で STRUCT データ型を使用する場合、フィールド名およびフィールド型をcom.aliyun.odps.data.Structからリフレクションを使用して解析できません。そのため、この情報を取得するために@Resolveアノテーションを使用する必要があります。UDF で STRUCT を使用する場合は、UDF クラスに@Resolveアノテーションを追加する必要があります。このアノテーションは、パラメーターまたは戻り値に com.aliyun.odps.data.Struct を含むオーバーロードにのみ影響します。たとえば、@Resolve("struct<a:string>,string->string")のようになります。詳細については、「複合データ型の例」をご参照ください。カスタム Java クラス:必須。
UDF のビジネスロジック(変数およびメソッドを含む)を含むクラス。
evaluateメソッド:必須。カスタム Java クラス内の非静的パブリックメソッド。
evaluateメソッドの入力パラメーターおよび戻り値のデータ型が、UDF の SQL シグネチャを定義します。1 つの UDF 内に複数の
evaluateメソッドを実装できます。UDF が呼び出されると、MaxCompute は引数の型に基づいて適切なevaluateメソッドをマッチングします。Java UDF を記述する際は、Java 型または Java 書き込み可能型を使用できます。MaxCompute データ型と Java データ型のマッピングの詳細については、「付録:データ型」をご参照ください。
UDF 初期化または終了コード:任意。
void setup(ExecutionContext ctx)およびvoid close()を使用して、それぞれ UDF の初期化および終了を実装できます。void setup(ExecutionContext ctx)メソッドはevaluateメソッドの前に 1 回だけ呼び出され、計算に必要なリソースやクラスのメンバー オブジェクトの初期化に使用できます。void close()メソッドはevaluateメソッドの終了後に呼び出され、ファイルのクローズなどクリーンアップ タスクの実行に使用できます。
以下は UDF のコード例です。
Java 型を使用
// 定義した Java クラスを org.alidata.odps.udf.examples パッケージに配置。 package org.alidata.odps.udf.examples; // UDF 基底クラスを継承。 import com.aliyun.odps.udf.UDF; // カスタム Java クラスを定義。 public final class Lower extends UDF { // evaluate メソッド。入力および戻り値の型はどちらも String。 public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }Java 書き込み可能型を使用
// 定義した Java クラスを com.aliyun.odps.udf.example パッケージに配置。 package com.aliyun.odps.udf.example; // Java 書き込み可能型に必要なクラスを追加。 import com.aliyun.odps.io.Text; // UDF 基底クラスを継承。 import com.aliyun.odps.udf.UDF; // カスタム Java クラスを定義。 public class MyConcat extends UDF { private Text ret = new Text(); // evaluate メソッド。入力および戻り値の型はどちらも Text。 public Text evaluate(Text a, Text b) { if (a == null || b == null) { return null; } ret.clear(); ret.append(a.getBytes(), 0, a.getLength()); ret.append(b.getBytes(), 0, b.getLength()); return ret; } }
MaxCompute は、互換性のある Hive バージョンで開発された Hive UDF もサポートしています。詳細については、「Hive 互換性」をご参照ください。
付録:データ型
データ型マッピング
互換性を確保するため、Java データ型と MaxCompute データ型のマッピングを理解しておく必要があります。以下の表にこれらのマッピングを示します。
MaxCompute データ型のサポートはエディションによって異なります。バージョン 2.0 以降では、ARRAY、MAP、STRUCT などの複合データ型を含む、より多くの型がサポートされています。MaxCompute データ型エディションの詳細については、「データ型エディション」をご参照ください。
MaxCompute 型 | Java 型 | Java 書き込み可能型 |
TINYINT | java.lang.Byte | ByteWritable |
SMALLINT | java.lang.Short | ShortWritable |
INT | java.lang.Integer | IntWritable |
BIGINT | java.lang.Long | LongWritable |
FLOAT | java.lang.Float | FloatWritable |
DOUBLE | java.lang.Double | DoubleWritable |
DECIMAL | java.math.BigDecimal | BigDecimalWritable |
BOOLEAN | java.lang.Boolean | BooleanWritable |
STRING | java.lang.String | Text |
VARCHAR | com.aliyun.odps.data.Varchar | VarcharWritable |
BINARY | com.aliyun.odps.data.Binary | BytesWritable |
DATE | java.sql.Date | DateWritable |
DATETIME | java.util.Date | DatetimeWritable |
TIMESTAMP | java.sql.Timestamp | TimestampWritable |
INTERVAL_YEAR_MONTH | N/A | IntervalYearMonthWritable |
INTERVAL_DAY_TIME | N/A | IntervalDayTimeWritable |
ARRAY | java.util.List | N/A |
MAP | java.util.Map | N/A |
STRUCT | com.aliyun.odps.data.Struct | N/A |
Hive 互換性
MaxCompute プロジェクトでデータ型エディション 2.0 を使用している場合、Hive スタイルの UDF がサポートされます。MaxCompute と互換性のある Hive バージョンで開発された Hive UDF を直接使用できます。
MaxCompute は Hive 2.1.0(Hadoop 2.7.2 に対応)と互換性があります。UDF が別のバージョンの Hive または Hadoop で開発されている場合は、互換性のあるバージョンを使用して UDF JAR ファイルを再コンパイルする必要があります。
MaxCompute での Hive UDF 使用例については、「UDF の例:Hive 互換性」をご参照ください。