カテゴリ | リンク |
ログ収集 | |
アプリケーション監視 | |
Managed Service for Prometheus | |
オープンソース Prometheus モニタリング (ack-prometheus-operator コンポーネント) | |
アラート管理 | |
その他の問題 |
ログ収集
コンテナログ収集エラーのトラブルシューティング方法
症状
ACK クラスターのコンテナーログを収集するの手順に従っても、Simple Log Service コンソールの[プレビュー] ページでログが見つからない場合は、ログ収集が失敗した可能性があります。この問題をトラブルシューティングするには、構成、収集コンポーネントとノードのステータス、およびログ収集コンテナーの操作ログを確認してください。
事前準備
コンテナファイルからログを収集する際は、次の点にご注意ください。
ステップ 1:収集構成の確認
Logtail 構成が正しいことを確認します。すべてのログ収集設定が正確であり、コンテナが継続的にログを生成していることを確認してください。
コンソール
[リソースオブジェクトブラウザー] タブで、clusteraliyunpipelineconfig を検索し、ClusterAliyunPipelineConfig の結果をクリックします。
[ClusterAliyunPipelineConfig] パネルで、対象のリソースを見つけ、[アクション] 列の [YAMLの編集] をクリックします。
kubectl
次のコマンドを実行して、
AliyunPipelineConfigによって作成されたすべての Logtail 構成を表示します。kubectl get clusteraliyunpipelineconfigsAliyunPipelineConfigによって作成された Logtail 構成の詳細とステータスを表示します。次のコマンドを実行します。必要に応じて、
<config_name>をAliyunPipelineConfigの名前に置き換えます。kubectl get clusteraliyunpipelineconfigs <config_name> -o yaml
構成項目の詳細については、「CRD パラメーター」をご参照ください。
設定項目 | チェックポイントの概要 | 例 |
| プロジェクト名が正しいかどうかを確認します。Simple Log Service コンソールにログインし、インストールされたログ収集コンポーネントによって生成されたプロジェクトの名前を見つけます。 |
|
| ログファイルのパスが存在し、出力があるかどうかを確認します。詳細については、「コンテナファイルパスのマッピング」をご参照ください。 |
|
| コンテナ検出機能が有効になっています。 |
|
| Simple Log Service のエンドポイントが正しいです。 |
|
| リージョン情報が正しいです。 |
|
ステップ 2:収集コンポーネントとマシングループのステータスの確認
Logtail や LoongCollector などのコレクションコンポーネントが各ワーカーノードにデプロイされて実行中であること、およびコレクションコンテナーからの [OK] ハートビートの数がワーカーノードの数と一致することを確認します。
収集コンポーネント Pod のステータスを確認します。
次のコマンドを実行して、関連するすべての収集 Pod が
Running状態であることを確認します。Pod が異常な状態にある場合は、「Pod の例外のトラブルシューティング」をご参照ください。kubectl get pods -n kube-system -l 'k8s-app in (loongcollector-ds,logtail)'出力は次のようになります:
NAME READY STATUS RESTARTS AGE loongcollector-ds-fn5zn 1/1 Running 0 3d19h loongcollector-ds-ks76g 1/1 Running 0 3d19h
マシングループのハートビートステータスを確認します。
Simple Log Service コンソールにログインします。
[プロジェクト] セクションで、目的のプロジェクトをクリックします。

左側のナビゲーションウィンドウで、
 [リソース] > [マシングループ] を選択します。
[リソース] > [マシングループ] を選択します。マシングループリストで、目的のマシングループをクリックします。
[マシングループ設定] ページで、ハートビートステータスが [OK] のマシンの数を確認します。この数がクラスター内のワーカーノードの数と一致することを確認します。 詳細については、「ハートビートステータスの解決策」をご参照ください。
ステップ 3:LoongCollector (Logtail) の操作ログの表示
収集コンテナで収集エラーやエラーメッセージを確認し、問題の原因をさらに分析します。
収集コンポーネント Pod に入ります。
kubectl exec -it -n kube-system loongcollector-ds-XXXX -- bashLogtail のログは、Logtail コンテナの
/usr/local/ilogtail/ディレクトリに保存されます。ファイル名はilogtail.LOGとlogtail_plugin.LOGです。Logtail コンテナにログインし、次のコマンドを実行してログファイルを表示できます:# /usr/local/ilogtail/ ディレクトリを開きます。 cd /usr/local/ilogtail # ilogtail.LOG と logtail_plugin.LOG ファイルを表示します。 cat ilogtail.LOG cat logtail_plugin.LOGエラーログのアラートメトリックを表示し、「Simple Log Service でのデータ収集における一般的なエラータイプ」で対応するソリューションを見つけます。
その他の O&M 操作
Kubernetes クラスター内の Simple Log Service コンポーネントのステータスの表示
Kubernetes クラスター内の Simple Log Service コンポーネントのステータスの表示
次のコマンドを実行して、Simple Log Service デプロイメントのステータスと情報を表示します。
kubectl get deploy -n kube-system | grep -E 'alibaba-log-controller|loongcollector-operator'次の結果が返されます:
NAME READY UP-TO-DATE AVAILABLE AGE alibaba-log-controller 1/1 1 1 11d次のコマンドを実行して、DaemonSet リソースのステータス情報を表示します。
kubectl get ds -n kube-system | grep -E 'logtail-ds|loongcollector-ds'次の結果が返されます:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE logtail-ds 2 2 2 2 2 **ux 11dLogtail のバージョン番号、IP アドレス、および起動時間の表示
情報は Logtail コンテナの
/usr/local/ilogtail/app_info.jsonファイルに保存されます。kubectl exec logtail-ds-****k -n kube-system cat /usr/local/ilogtail/app_info.json次のような結果が返されます。
{ "UUID" : "", "hostname" : "logtail-****k", "instance_id" : "0EB****_172.20.4.2_1517810940", "ip" : "172.20.4.2", "logtail_version" : "0.16.2", "os" : "Linux; 3.10.0-693.2.2.el7.x86_64; #1 SMP Tue Sep 12 22:26:13 UTC 2017; x86_64", "update_time" : "2018-02-05 06:09:01" }
プロジェクトを削除できない理由
症状
このトピックでは、プロジェクトの削除方法と、「権限が不十分です」というエラーメッセージが表示されてプロジェクトを削除できない場合の対処法について説明します。
ソリューション
プロジェクトまたは Logstore の削除方法の詳細については、「プロジェクトの管理」および「Logstore の管理」をご参照ください。プロジェクトの削除に失敗した場合は、「プロジェクトを削除する際に「操作が拒否されました、権限が不十分です」というエラーメッセージが返された場合の対処法」をご参照ください。
Simple Log Service でのデータ収集における一般的なエラータイプ
エラータイプ | 説明 | ソリューション |
LOG_GROUP_WAIT_TOO_LONG_ALARM | データパケットが生成された後、送信されるまでの待機時間が長すぎます。 | パケットが期待どおりに送信されているか確認してください。このエラーは、データ量がデフォルト構成を超えている、クォータが不足している、またはネットワークの問題が原因である可能性があります。 |
LOGFILE_PERMISSION_ALARM | Logtail には指定されたファイルを読み取る権限がありません。 | サーバー上の Logtail 起動アカウントを確認してください。Logtail を root ユーザーとして起動することで解決します。 |
SPLIT_LOG_FAIL_ALARM | 行の開始を示す正規表現がログの内容と一致しないため、Logtail がログを個別の行に分割できません。 | 正規表現が正しいか確認してください。 単一行のログの場合、正規表現を |
MULTI_CONFIG_MATCH_ALARM | デフォルトでは、1 つのログファイルは 1 つの Logtail 構成にしか一致しません。複数の Logtail 構成が同じファイルに一致する場合、1 つしか有効になりません。 説明 複数の Logtail 構成を使用して、Docker からの標準出力を収集できます。 |
|
REGEX_MATCH_ALARM | 完全な正規表現モードでは、ログの内容が指定された正規表現と一致しません。 | エラーメッセージからログサンプルをコピーして、新しい正規表現を生成します。 |
PARSE_LOG_FAIL_ALARM | JSON やデリミタなどのモードで、ログ形式が定義された形式に準拠していないため、解析に失敗します。 | エラーメッセージをクリックして、詳細なエラーレポートを表示します。 |
CATEGORY_CONFIG_ALARM | Logtail 収集構成が無効です。 | 一般的な原因は、正規表現がファイルパスを抽出して Topic として使用できなかったことです。 |
LOGTAIL_CRASH_ALARM | Logtail がサーバーのリソース使用量制限を超えたため、クラッシュしました。 | CPU とメモリの使用量制限を増やします。詳細については、「Logtail 起動パラメーターの設定」をご参照ください。 |
REGISTER_INOTIFY_FAIL_ALARM | Logtail が Linux でログリスナーを登録できませんでした。このエラーは、Logtail がフォルダにアクセスする権限がないか、フォルダが削除された場合に発生する可能性があります。 | Logtail がフォルダにアクセスする権限があるか、またはフォルダが削除されたかを確認してください。 |
DISCARD_DATA_ALARM | Logtail に構成された CPU リソースが不足しているか、ネットワーク経由でデータを送信する際にスロットリングがトリガーされます。 | CPU 使用量制限またはネットワーク送信同時実行数制限を増やします。詳細については、「Logtail 起動パラメーターの設定」をご参照ください。 |
SEND_DATA_FAIL_ALARM |
|
|
REGISTER_INOTIFY_FAIL_ALARM | Logtail がログディレクトリの inotify ウォッチャーを登録できませんでした。 | ディレクトリが存在するかどうかを確認し、その権限設定を確認してください。 |
SEND_QUOTA_EXCEED_ALARM | ログの書き込みトラフィックが構成された制限を超えています。 | コンソールでシャード数を増やします。詳細については、「シャードの分割」をご参照ください。 |
READ_LOG_DELAY_ALARM | ログ収集が遅延し、ログ生成に追いついていません。このエラーは通常、Logtail の CPU リソース不足またはネットワーク送信のスロットリングが原因です。 | CPU 使用量制限またはネットワーク送信同時実行数制限を増やします。詳細については、「Logtail 起動パラメーターの設定」をご参照ください。 既存データをインポートしている場合、短時間で大量のデータが収集されます。このエラーは無視できます。 |
DROP_LOG_ALARM | ログ収集が遅延し、未処理のローテーションされたログファイルの数が 20 を超えています。このエラーは通常、Logtail の CPU リソース不足またはネットワーク送信のスロットリングが原因です。 | CPU 使用量制限またはネットワーク送信同時実行数制限を増やします。詳細については、「Logtail 起動パラメーターの設定」をご参照ください。 |
LOGDIR_PERMISSION_ALARM | Logtail にはログ監視ディレクトリを読み取る権限がありません。 | ログ監視ディレクトリが存在するかどうかを確認します。存在する場合は、その権限設定を確認してください。 |
ENCODING_CONVERT_ALARM | エンコード変換に失敗しました。 | 構成されたエンコード形式がログの実際のエンコード形式と一致していることを確認してください。 |
OUTDATED_LOG_ALARM | ログのタイムスタンプが収集時間より 12 時間以上古いため、ログは古くなっています。考えられる原因は次のとおりです:
|
|
STAT_LIMIT_ALARM | 収集構成で指定されたディレクトリ内のファイル数が制限を超えています。 | ターゲットの収集ディレクトリに多数のファイルとサブディレクトリが含まれているかどうかを確認します。監視に適したルートディレクトリを設定し、サブディレクトリの最大監視深度を指定します。 また、mem_usage_limit パラメーターを変更することもできます。詳細については、「Logtail 起動パラメーターの設定」をご参照ください。 |
DROP_DATA_ALARM | プロセス終了時にローカルディスクへのログ保存がタイムアウトしました。保存されなかったログは破棄されます。 | このエラーは通常、収集プロセスが深刻にブロックされているために発生します。CPU 使用量制限またはネットワーク送信同時実行数制限を増やします。詳細については、「Logtail 起動パラメーターの設定」をご参照ください。 |
INPUT_COLLECT_ALARM | 入力ソースからの収集中にエラーが発生しました。 | エラーメッセージの詳細に基づいてエラーを解決します。 |
HTTP_LOAD_ADDRESS_ALARM | HTTP データ収集構成で指定された Addresses パラメーターが無効です。 | Addresses パラメーターが有効かどうかを確認してください。 |
HTTP_COLLECT_ALARM | HTTP データ収集中にエラーが発生しました。 | エラーメッセージの詳細に基づいて問題をトラブルシューティングします。このエラーは通常、タイムアウトが原因です。 |
FILTER_INIT_ALARM | フィルターの初期化中にエラーが発生しました。 | このエラーは通常、フィルター内の無効な正規表現が原因です。エラーメッセージの詳細に基づいて式を修正してください。 |
INPUT_CANAL_ALARM | MySQL バイナリロギングで実行時エラーが発生しました。 | エラーメッセージの詳細に基づいて問題をトラブルシューティングします。 構成が更新されると、canal サービスが再起動することがあります。サービスの再起動によって引き起こされるエラーは無視してください。 |
CANAL_INVALID_ALARM | MySQL バイナリロギングの内部状態が異常です。 | このエラーは通常、実行時のテーブルスキーマの変更によってメタデータの不整合が発生した場合に発生します。エラーが報告された時点でテーブルスキーマが変更されたかどうかを確認してください。 |
MYSQL_INIT_ALARM | MySQL の初期化中にエラーが発生しました。 | エラーメッセージの詳細に基づいてエラーを解決します。 |
MYSQL_CHECKPOINT_ALARM | MySQL のチェックポイント形式が異常です。 | この構成のチェックポイント関連の設定が変更されたかどうかを確認してください。 |
MYSQL_TIMEOUT_ALARM | MySQL クエリがタイムアウトしました。 | MySQL サーバーとネットワークが正常に機能していることを確認してください。 |
MYSQL_PARSE_ALARM | MySQL クエリ結果の解析に失敗しました。 | MySQL 構成のチェックポイント形式が対応するフィールドの形式と一致していることを確認してください。 |
AGGREGATOR_ADD_ALARM | キューへのデータの追加に失敗しました。 | このエラーは、データが速すぎる速度で送信されていることを示します。実際のデータ量が大きい場合は、このエラーを無視してください。 |
ANCHOR_FIND_ALARM | processor_anchor プラグインでエラーが発生しました。これは、構成が正しくないか、ログが構成に準拠していないことが原因である可能性があります。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーには次のサブタイプがあります。特定のサブタイプの詳細に基づいて構成を確認してください。
|
ANCHOR_JSON_ALARM | processor_anchor プラグインで、Start および Stop パラメーターで定義された JSON コンテンツを展開する際にエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。処理中のコンテンツと関連する構成を確認して、構成エラーを特定するか、無効なログを見つけます。 |
CANAL_RUNTIME_ALARM | バイナリロギングプラグインで実行時エラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示し、問題をトラブルシューティングします。このエラーは通常、接続されているプライマリ MySQL インスタンスに関連しています。 |
CHECKPOINT_INVALID_ALARM | チェックポイントの解析に失敗しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。チェックポイントキー、チェックポイントコンテンツ (最初の 1024 バイト)、および特定のエラーメッセージに基づいて問題をトラブルシューティングします。 |
DIR_EXCEED_LIMIT_ALARM | Logtail が同時にリッスンしているディレクトリの数が制限を超えています。 | 現在の Logstore の収集構成および Logtail に適用されている他の構成が多くのディレクトリを含んでいるかどうかを確認します。監視に適したルートディレクトリを設定し、サブディレクトリの最大監視深度を指定します。 |
DOCKER_FILE_MAPPING_ALARM | Logtail がコマンドを実行して Docker ファイルマッピングを追加できませんでした。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。コマンドと特定のエラーメッセージに基づいて問題をトラブルシューティングします。 |
DOCKER_FILE_MATCH_ALARM | Docker コンテナで指定されたファイルが見つかりません。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。コンテナ情報と検索中のファイルパスに基づいて問題をトラブルシューティングします。 |
DOCKER_REGEX_COMPILE_ALARM | service_docker_stdout プラグインでエラーが発生しました。プラグインが構成から BeginLineRegex をコンパイルできませんでした。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。正規表現が正しいかどうかを確認してください。 |
DOCKER_STDOUT_INIT_ALARM | service_docker_stdout プラグインの初期化に失敗しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーには次のサブタイプがあります。
|
DOCKER_STDOUT_START_ALARM | service_docker_stdout プラグインによる収集中に stdout サイズが制限を超えました。 | このエラーは通常、最初の収集中に stdout データが既に存在する場合に発生します。このエラーは無視してください。 |
DOCKER_STDOUT_STAT_ALARM | service_docker_stdout プラグインが stdout を検出できません。 | このエラーは通常、コンテナが終了するときに stdout にアクセスできないために発生します。このエラーは無視してください。 |
FILE_READER_EXCEED_ALARM | Logtail が同時に開いているファイルオブジェクトの数が制限を超えています。 | このエラーは通常、同時に収集されているファイルが多すぎるために発生します。収集構成が合理的かどうかを確認してください。 |
GEOIP_ALARM | processor_geoip プラグインでエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーには次のサブタイプがあります。
|
HTTP_INIT_ALARM | metric_http プラグインでエラーが発生しました。構成で指定された ResponseStringMatch 正規表現のコンパイルに失敗しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。正規表現が正しいかどうかを確認してください。 |
HTTP_PARSE_ALARM | metric_http プラグインでエラーが発生しました。プラグインが HTTP 応答を取得できませんでした。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。特定のエラーメッセージに基づいて、構成内容または要求された HTTP サーバーを確認してください。 |
INIT_CHECKPOINT_ALARM | バイナリロギングプラグインでエラーが発生しました。プラグインがチェックポイントファイルの読み込みに失敗しました。プラグインはチェックポイントを無視し、最初から処理を開始します。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。特定のエラー情報に基づいて、このエラーを無視するかどうかを判断します。 |
LOAD_LOCAL_EVENT_ALARM | Logtail はローカルイベントを処理しています。 | この警告はまれです。手動操作が原因でない場合は、問題をトラブルシューティングする必要があります。エラーリンクをクリックして詳細なエラーメッセージを表示します。ファイル名、構成名、プロジェクト、および Logstore に基づいて問題をトラブルシューティングします。 |
LOG_REGEX_FIND_ALARM | processor_split_log_regex および processor_split_log_string プラグインでエラーが発生しました。構成で指定された SplitKey がログに見つかりません。 | エラーリンクをクリックして詳細なエラーメッセージを表示し、構成エラーを確認します。 |
LUMBER_CONNECTION_ALARM | service_lumberjack プラグインでエラーが発生しました。プラグインが停止している間にサーバーがシャットダウンされました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。特定のエラー情報に基づいて問題をトラブルシューティングします。通常、このエラーは無視できます。 |
LUMBER_LISTEN_ALARM | service_lumberjack プラグインのリスナー初期化中にエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーには次のサブタイプがあります。
|
LZ4_COMPRESS_FAIL_ALARM | Logtail が LZ4 圧縮を実行中にエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。ログ行、プロジェクト、カテゴリ、およびリージョンの値に基づいて問題をトラブルシューティングします。 |
MYSQL_CHECKPOINT_ALARM | MySQL プラグインでチェックポイントに関連するエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーには次のサブタイプがあります。
|
NGINX_STATUS_COLLECT_ALARM | nginx_status プラグインがステータスを取得中にエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。URL と特定のエラー情報に基づいて問題をトラブルシューティングします。 |
NGINX_STATUS_INIT_ALARM | nginx_status プラグインでエラーが発生しました。プラグインの初期化と構成で指定された URL の解析に失敗しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。URL が正しく構成されているかどうかを確認してください。 |
OPEN_FILE_LIMIT_ALARM | Logtail が開いたファイルの数が制限を超え、新しいファイルを開けません。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。ログファイルパス、プロジェクト、および Logstore に基づいて問題をトラブルシューティングします。 |
OPEN_LOGFILE_FAIL_ALARM | Logtail がファイルを開こうとしたときにエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。ログファイルパス、プロジェクト、および Logstore に基づいて問題をトラブルシューティングします。 |
PARSE_DOCKER_LINE_ALARM | service_docker_stdout プラグインでエラーが発生しました。プラグインがログの解析に失敗しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーには次のサブタイプがあります。
|
PLUGIN_ALARM | プラグインの初期化および関連する呼び出し中にエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーには次のサブタイプがあります。特定のエラー詳細に基づいて問題をトラブルシューティングします。
|
PROCESSOR_INIT_ALARM | processor_regex プラグインでエラーが発生しました。プラグインが構成で指定された Regex 正規表現のコンパイルに失敗しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。正規表現が正しいかどうかを確認してください。 |
PROCESS_TOO_SLOW_ALARM | Logtail がログを解析する速度が遅すぎます。 |
|
REDIS_PARSE_ADDRESS_ALARM | Redis プラグインでエラーが発生しました。プラグインが構成で提供された ServerUrls の解析に失敗しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーが報告された URL を確認してください。 |
REGEX_FIND_ALARM | processor_regex プラグインでエラーが発生しました。プラグインが構成で SourceKey によって指定されたフィールドを見つけられません。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。SourceKey 構成が正しくないか、または無効なログがないかを確認してください。 |
REGEX_UNMATCHED_ALARM | processor_regex プラグインでエラーが発生しました。一致に失敗しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーには次のサブタイプがあります。特定のエラー情報に基づいて問題をトラブルシューティングします。
|
SAME_CONFIG_ALARM | Logstore に同じ名前の構成が既に存在します。後で検出された構成は破棄されます。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。構成パスやその他の情報に基づいて構成エラーを確認してください。 |
SPLIT_FIND_ALARM | split_char および split_string プラグインでエラーが発生しました。プラグインが構成で SourceKey によって指定されたフィールドを見つけられません。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。SourceKey 構成が正しくないか、または無効なログがないかを確認してください。 |
SPLIT_LOG_ALARM | processor_split_char および processor_split_string プラグインでエラーが発生しました。解析されたフィールドの数が SplitKeys で指定された数と異なります。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。SourceKey 構成が正しくないか、または無効なログがないかを確認してください。 |
STAT_FILE_ALARM | LogFileReader オブジェクトを使用してファイルからデータを収集する際にエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。ファイルパスとエラー情報に基づいて問題をトラブルシューティングします。 |
SERVICE_SYSLOG_INIT_ALARM | service_syslog プラグインでエラーが発生しました。プラグインの初期化に失敗しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。構成の Address パラメーターが正しいかどうかを確認してください。 |
SERVICE_SYSLOG_STREAM_ALARM | service_syslog プラグインが TCP 経由でデータを収集する際にエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーには次のサブタイプがあります。特定のエラー詳細に基づいて問題をトラブルシューティングします。
|
SERVICE_SYSLOG_PACKET_ALARM | service_syslog プラグインが UDP 経由でデータを収集する際にエラーが発生しました。 | エラーリンクをクリックして詳細なエラーメッセージを表示します。エラーには次のサブタイプがあります。特定のエラー詳細に基づいて問題をトラブルシューティングします。
|
PARSE_TIME_FAIL_ALARM | プラグインがログ時間の解析に失敗しました。 | 次のいずれかの方法で問題を特定して解決します:
|
アプリケーション監視
ACK クラスター内のアプリケーションにプローブをインストールした後、モニタリングデータが利用できない理由
原因
アプリケーション監視が一時停止しています。
アプリケーションが配置されている Pod に ARMS エージェントが期待どおりにロードされていません。
ソリューション
アプリケーション監視が一時停止しているかどうかの確認。
ARMS コンソールにログインします。 左側のナビゲーションウィンドウで、を選択します。
[アプリケーション一覧] ページで、上部のナビゲーションバーでリージョンを選択し、アプリケーション名をクリックします。
アプリケーションが見つからない場合は、ステップ 2:ARMS エージェントが期待どおりにロードされているかどうかの確認に進みます。
新しい Application Real-Time Monitoring Service (ARMS) コンソールを使用している場合は、アプリケーション詳細ページのトップナビゲーションバーで を選択します。 [プローブスイッチ設定] セクションで、アプリケーション監視が一時停止されているかどうかを確認します。
[アプリケーション監視を一時停止] がオンになっている場合は、スイッチをオフにして [保存] をクリックします。
[アプリケーション監視を一時停止] がオフになっている場合は、ステップ 2:ARMS エージェントが期待どおりにロードされているかどうかの確認に進みます。
旧バージョンの ARMS コンソールを使用している場合は、アプリケーション詳細ページの左側のナビゲーションウィンドウで [アプリケーション設定] をクリックします。 表示されたページで、[カスタム設定] タブをクリックします。 [エージェントスイッチ設定] セクションで、[Probe Master Switch] がオンになっているかどうかを確認します。
[プローブマスタースイッチ] がオフになっている場合は、[プローブマスタースイッチ] をオンにして、ページ下部の [保存] をクリックします。
[プローブマスタースイッチ] がオンになっている場合は、ステップ 2:ARMS エージェントが期待どおりにロードされているかどうかの確認に進みます。
プローブが正しくロードされているかどうかの確認
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。「クラスター」ページで、クラスターの名前をクリックしてクラスターの詳細ページに移動します。
左側のナビゲーションウィンドウで、 の順に選択します。
[Pod] ページで、アプリケーションが存在する名前空間を選択し、アプリケーションを見つけ、[アクション] 列の [YAML の編集] をクリックします。
[YAML の編集] ダイアログボックスで、YAML ファイルに initContainers が含まれているかどうかを確認します。

クラスターの詳細ページの左側のナビゲーションウィンドウで、 を選択します。表示されたページで、[名前空間] パラメーターを [ack-onepilot] に設定します。Pod リストに、ローリングアップデートが完了した
ack-onepilot-*という名前の Pod が存在するかどうかを確認します。指定された Pod が存在する場合は、ステップ 6 を実行します。
指定された Pod が存在しない場合は、アプリケーションマーケットから ack-onepilot コンポーネントをインストールします。詳細については、「ack-onepilot をインストールして arms-pilot をアンインストールする方法」をご参照ください。
クラスター詳細ページの左側のナビゲーションウィンドウで、[ワークロード] > [デプロイメント] または [StatefulSet] を選択します。 表示されたページで、アプリケーションを見つけ、[アクション] 列で
 > [YAML の編集] を選択します。 [YAML の編集] ダイアログボックスで、YAML ファイルの spec.template.metadata セクションに次のラベルが含まれているかどうかを確認します。
> [YAML の編集] を選択します。 [YAML の編集] ダイアログボックスで、YAML ファイルの spec.template.metadata セクションに次のラベルが含まれているかどうかを確認します。 labels: armsPilotAutoEnable: "on" armsPilotCreateAppName: "<your-deployment-name>" # <your-deployment-name> を実際のアプリケーション名に置き換えます。 armsSecAutoEnable: "on" # アプリケーションを Application Security に接続する場合は、このパラメーターを構成する必要があります。YAML ファイルにラベルが含まれている場合は、ステップ 7 を実行します。
YAML ファイルにラベルが含まれていない場合は、[YAML の編集] ダイアログボックスで、spec > template > metadata セクションにラベルを追加し、<your-deployment-name> を実際のアプリケーション名に置き換えます。その後、[更新] をクリックします。
クラスター詳細ページの左側のナビゲーションウィンドウで、 の順に選択します。表示されたページで Pod を見つけ、[アクション] 列で の順に選択し、ack-onepilot の Pod ログに
"Message":"STS error"フォーマットでセキュリティトークンサービス (STS) エラーが報告されているかどうかを確認します。エラーが報告されている場合は、アプリケーションのクラスターを承認し、アプリケーションの Pod を再起動します。詳細については、「ACK にデプロイされた Java アプリケーション用の ARMS エージェントのインストール」をご参照ください。
エラーが報告されない場合は、チケットを送信してください。
クラスターの詳細ページの左側のナビゲーションウィンドウで、 を選択し、目的の Pod を見つけ、[アクション] 列の [YAML の編集] をクリックします。[YAML の編集] ダイアログボックスで、YAML ファイルに次の javaagent パラメーターが含まれているかを確認します。
-javaagent:/home/admin/.opt/ArmsAgent/aliyun-java-agent.jar説明2.7.3.5 より前の ARMS エージェントを使用している場合は、上記のコードの aliyun-java-agent.jar を arms-bootstrap-1.7.0-SNAPSHOT.jar に置き換えます。エージェントをできるだけ早く最新バージョンにアップグレードすることを推奨します。
クラスターに ARMS Addon Token が存在しない
症状
ターゲットクラスターに ARMS Addon Token が存在しません。
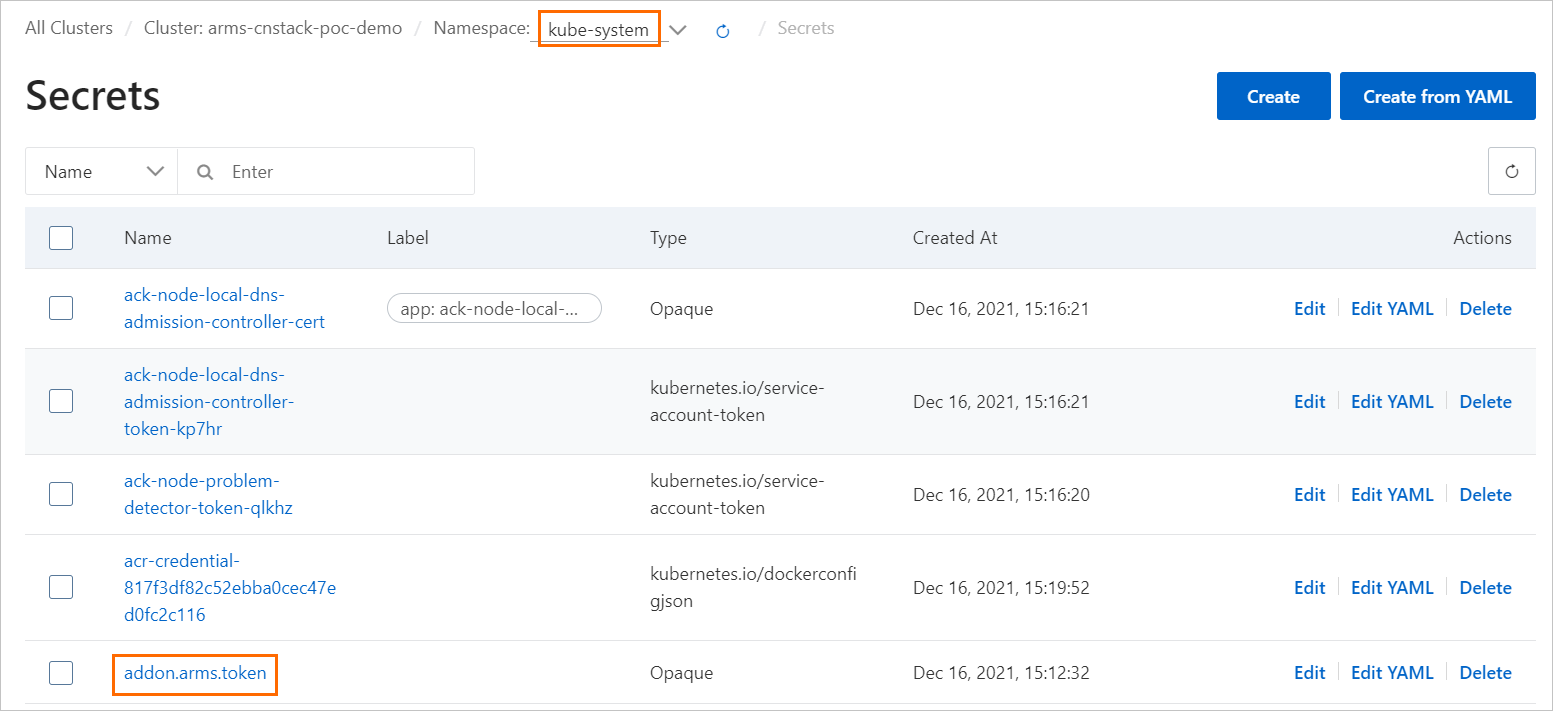
ACK コンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。 [クラスター]ページで、クラスターの名前をクリックすると、クラスターの詳細ページに移動します。
左側のナビゲーションウィンドウで、 を選択します。
ページの上部で、名前空間 ドロップダウンリストから [kube-system] を選択し、[addon.arms.token] が有効になっているかどうかを確認します。
ソリューション
Container Service for Kubernetes (ACK) に ARMS リソースへのアクセス権限を付与します。
アプリケーションを別のクラスターまたは名前空間に移動した後、モニタリングデータが異常になる理由
症状
アプリケーションの名前空間を変更した後、カスタムダッシュボードの名前空間列に表示される値が更新されません。

アプリケーションのクラスターを変更した後、レート、エラー、および期間 (RED) メトリックのデータは正常に表示されますが、CPU やメモリなどのコンテナ監視メトリックのデータは表示されません。
考えられる原因
Namespace や ClusterId などのコンテナ関連パラメーターは、アプリケーションの作成時に構成され、これらのパラメーターの値は自動的に更新できません。アプリケーションのクラスターまたは名前空間を変更すると、コンテナ関連のデータのクエリまたは表示に失敗する可能性があります。
ソリューション
アプリケーションを削除し、アプリケーションを再作成してから、再度モニタリングデータをレポートします。詳細については、「アプリケーションの削除」をご参照ください。
この方法では、既存データが失われます。
チケットを送信します。
Java プローブのマウントパスをカスタマイズする方法
背景情報
標準的なデプロイメントでは、ack-onepilot コンポーネントは JAVA_TOOL_OPTIONS 環境変数をインジェクションすることで Java エージェントのマウントパスを指定します。ただし、次のような特定のシナリオでは、エージェントのマウントパスをカスタマイズする必要がある場合があります:
構成管理の一元化
Kubernetes ConfigMap を使用してエージェントパスを一元管理し、複数の環境間で構成の一貫性を確保できます。
永続ストレージの要件
企業のセキュリティポリシーや O&M 要件により、プローブファイルをカスタムの永続ボリューム (PVC) に保存する必要がある場合があります。
ソリューション
Java エージェントのマウントパスをカスタマイズするには、次のコンポーネントバージョンが必要です:
ack-onepilot:バージョン 4.1.0 以降。
ARMS Java エージェント:バージョン 4.2.2 以降。必要に応じてJava エージェントのバージョンを制御することもできます。
ack-onepilot コンポーネントは Microservice Engine (MSE) と Application Real-Time Monitoring Service (ARMS) で共有されています。したがって、この手順は MSE サービス管理アプリケーションにも適用されます。
カスタムマウントされた Java エージェントを必要とする Deployment などの Kubernetes ワークロードに
disableJavaToolOptionsInjectionアノテーションを追加します。このアノテーションを追加すると、ack-onepilot コンポーネントは JAVA_TOOL_OPTIONS 環境変数を使用してエージェントのマウントパスや他の Java 仮想マシン (JVM) パラメーターを自動的に指定しなくなります。
次のコマンドを実行して、ターゲット Deployment の YAML ファイルを表示します。
kubectl get deployment YOUR_DEPLOYMENT_NAME -o yaml説明Deployment 名がわからない場合は、次のコマンドを実行してすべての Deployment を一覧表示できます。結果からターゲット Deployment を見つけ、その YAML ファイルを表示します。
kubectl get deployments --all-namespacesターゲットのステートレスアプリケーション (Deployment) の YAML ファイルを編集できます。
kubectl edit deployment YOUR_DEPLOYMENT_NAME -o yamlYAML ファイルで、`spec.template.metadata` の下に次の内容を追加します。
labels: armsPilotAutoEnable: "on" armsPilotCreateAppName: "<span class="var-span" contenteditable="true" data-var="YOUR_DEPLOYMENT_NAME">YOUR_DEPLOYMENT_NAME"</span> # YOUR_DEPLOYMENT_NAME をアプリケーション名に置き換えます。 disableJavaToolOptionsInjection: "true" # Java エージェントのマウントパスをカスタマイズするには、これを true に設定します。
ARMS Java エージェントのマウントパスをアプリケーションの起動スクリプトまたは Java 起動コマンドに追加します。
デフォルトのマウントパスは
/home/admin/.opt/AliyunJavaAgent/aliyun-java-agent.jarです。このパスをカスタムパスに置き換えます。java -javaagent:/home/admin/.opt/AliyunJavaAgent/aliyun-java-agent.jar ... ... -jar xxx.jarレポートリージョンやライセンスキーなどの他の情報は、ack-onepilot によって環境変数を通じてインジェクションされます。
ACK クラスターからリージョンをまたいでデータをレポートする方法
症状
リージョン A からリージョン B にデータをレポートする方法は?
ソリューション
ack-onepilot コンポーネントを V4.0.0 以降に更新します。
ack-onepilot 名前空間の ack-onepilot-ack-onepilot アプリケーションに ARMS_REPORT_REGION 環境変数を追加します。値は ARMS が利用可能なリージョンの ID である必要があります。例:cn-hangzhou または cn-beijing。
既存のアプリケーションを再起動するか、新しいアプリケーションをデプロイして、リージョンをまたいでデータをレポートします。
説明環境変数を追加した後、クラスターにデプロイされたすべてのアプリケーションは、前のステップで指定されたリージョンにデータをレポートします。
arms-pilot をアンインストールして ack-onepilot をインストールする方法
背景情報
古いアプリケーション監視エージェント arms-pilot はメンテナンスされなくなりました。新しいエージェント ack-onepilot をインストールしてアプリケーションを監視できます。ack-onepilot は arms-pilot と完全に互換性があります。アプリケーション構成を変更することなく、ack-onepilot をシームレスにインストールできます。このトピックでは、arms-pilot をアンインストールして ack-onepilot をインストールする方法について説明します。
ソリューション
ack-onepilot は ACK クラスター V1.16 以降にインストールする必要があります。クラスターが V1.16 より古い場合は、まずクラスターをアップグレードしてください。詳細については、「ACK クラスターの Kubernetes バージョンの更新」をご参照ください。
ack-onepilot をインストールする前に arms-pilot をアンインストールする必要があります。ack-onepilot と arms-pilot の両方がインストールされている場合、ARMS エージェントはマウントできません。arms-pilot が完全にアンインストールされていない場合、ack-onepilot は環境内で arms-pilot がまだ動作しているとみなし、動作しません。
arms-pilot をアンインストールして ack-onepilot をインストールする場合、arms-pilot の構成は ack-onepilot に自動的に同期されません。構成を記録してから、手動で ack-onepilot を構成することを推奨します。
arms-pilot のアンインストール。
ACK コンソールにログインします。 [クラスター] ページで、クラスターの名前をクリックします。
左側のナビゲーションウィンドウで、 を選択します。
[Helm] ページで、[arms-pilot] を探し、[アクション] 列の [削除] をクリックします。
[削除] メッセージで、[OK] をクリックします。
arms-pilot がアンインストールされたかどうかの確認。
ACK コンソールのクラスター詳細ページに移動します。 左側のナビゲーションウィンドウで、を選択します。 [デプロイメント] ページで、[名前空間] ドロップダウンリストから[arms-pilot]を選択し、名前空間の Pod が期待どおりに削除されているかどうかを確認します。
説明arms-pilot が属する名前空間を変更した場合は、新しい名前空間を選択します。
ack-onepilot のインストール。
ACK コンソールにログインします。 [クラスター] ページで、クラスターの名前をクリックします。
左側のナビゲーションウィンドウでをクリックし、[アドオン]ページで[ack-onepilot] を検索します。
[ack-onepilot] カードの [インストール] をクリックします。
説明デフォルトでは、ack-onepilot コンポーネントは 1,000 個の Pod をサポートします。クラスター内の Pod が 1,000 個増えるごとに、コンポーネントに 0.5 CPU コアと 512 MB のメモリを追加する必要があります。
表示されるダイアログボックスで、パラメーターを設定し、[OK] をクリックします。デフォルト値を使用することをお勧めします。
説明ack-onepilot のインストール後は、[アドオン] ページでアップグレード、設定、またはアンインストールできます。
ack-onepilot がインストールされたかどうかの確認。
ACK コンソールのクラスターの詳細ページに移動します。 左側のナビゲーションウィンドウで、を選択します。 [デプロイメント] ページで、[Namespace] ドロップダウンリストから ack-onepilot を選択し、名前空間の Pod が期待どおりに実行されているかどうかを確認します。

Managed Service for Prometheus
Prometheus モニタリングページに「関連するダッシュボードが見つかりません」と表示される
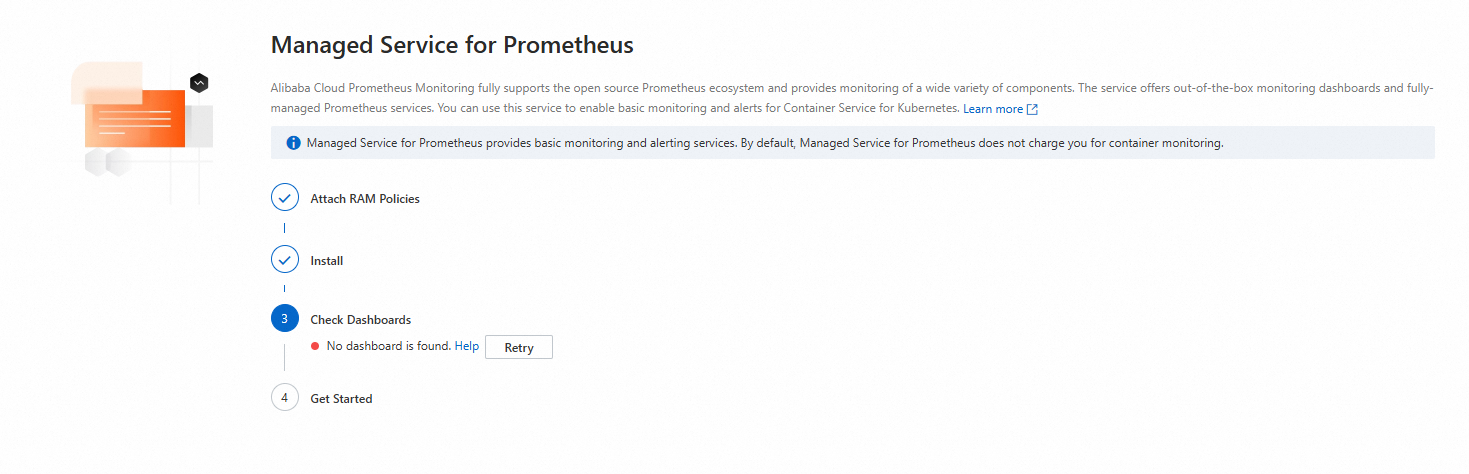
症状
Prometheus モニタリングを有効にすると、ターゲットクラスターの ページにメッセージ [ダッシュボードが見つかりません] が表示される場合は、以下のプロシージャに従って問題を解決してください。
ソリューション
Prometheus モニタリングコンポーネントを再インストールします。
コンポーネントを再インストールします:
アンインストールが完了したことを確認したら、[インストール] をクリックし、次にダイアログボックスで [OK] をクリックします。
インストールが完了したら、Prometheus モニタリングページに戻り、問題が解決したかどうかを確認します。
問題が解決しない場合は、次のステップに進みます。
Prometheus インスタンスの接続を確認します。
ARMS コンソールの左側のナビゲーションウィンドウで、[統合管理] をクリックします。
[統合環境] タブで、[コンテナーサービス] リストにクラスターと同じ名前のコンテナー環境があることを確認します。
対応するコンテナ環境が存在しない場合:「ARMS または Prometheus コンソールを使用して接続する」をご参照ください。
コンテナー環境がある場合は、対象の環境の[アクション] 列で[エージェントの設定] をクリックし、[エージェントの設定] ページを開きます。
インストールされたエージェントが期待どおりに実行されているかどうかを確認します。
Managed Service for Prometheus でデータが表示されない理由
原因
Managed Service for Prometheus でデータが表示されないのは、Alibaba Cloud Prometheus サービスとの同期タスクが失敗し、リソース登録が失敗したか、Prometheus インスタンスが正しくプロビジョニングされなかったことが原因である可能性があります。以下の手順に従って問題を確認し、解決してください。
ソリューション
Managed Service for Prometheus のプロビジョニングタスクのステータスを確認します。
[ジョブ] ページで、ページ上部で [名前空間] を [arms-prom] に設定し、次に [o11y-init-environment] をクリックしてジョブが成功したことを確認します。
成功しなかった場合、Alibaba Cloud Prometheus サービスとの同期およびリソースの登録に失敗した可能性があります。その Pod のログを表示して、失敗の具体的な原因を見つけることができます。詳細については、「Pod の例外のトラブルシューティング」をご参照ください。
Pod がもう存在しない場合は、次の手順に進みます。
Prometheus モニタリングコンポーネントを再インストールします。
コンポーネントを再インストールします:
アンインストールが完了したことを確認したら、[インストール] をクリックし、ダイアログボックスで [OK] をクリックします。
インストールが完了したら、Prometheus モニタリングページに戻り、問題が解決したかどうかを確認します。
問題が解決しない場合は、次のステップに進みます。
Prometheus インスタンスのプロビジョニングを確認します。
ARMS コンソールの左側のナビゲーションウィンドウで、[統合管理] をクリックします。
[統合環境] タブの [コンテナーサービス] リストで、クラスターと同じ名前のコンテナー環境を確認します。
対応するコンテナ環境が存在しない場合:「ARMS または Prometheus コンソールを使用して接続する」をご参照ください。
コンテナー環境がある場合は、対象の環境の [アクション] 列にある [エージェントの設定] をクリックして、[エージェントの設定] ページを開きます。
インストールされたエージェントが期待どおりに実行されているかどうかを確認します。
Managed Service for Prometheus の再インストールに失敗し、「rendered manifests contain a resource that already exists」というエラーメッセージが報告される
症状
Prometheus エージェントをアンインストールして再インストールすると、次のエラーメッセージが表示されます:
rendered manifests contain a resource that already exists. Unable to continue with install: existing resource conflict: kind: ClusterRole, namespace: , name: arms-pilot-prom-k8s
原因
コマンドを実行して Prometheus エージェントを手動でアンインストールした後、ロールなどのリソースが削除されない場合があります。
ソリューション
次のコマンドを実行して、Prometheus エージェントの ClusterRole を見つけます:
kubectl get ClusterRoles --all-namespaces | grep prom次のコマンドを実行して、前のステップでクエリされた ClusterRole を削除します:
kubectl delete ClusterRole [$Cluster_Roles] -n arms-prom説明[$Cluster_Roles] パラメーターは、前のステップでクエリされた ClusterRole を指定します。
ClusterRole を削除しても問題が解決しない場合は、エラーメッセージの kind の値を確認して、ClusterRole 以外のリソースが存在するかどうかを確認します。上記の手順を実行して、それらを順番に削除します。
ack-arms-prometheus コンポーネントのバージョンを確認する方法
背景情報
クラスターにデプロイされている ack-arms-prometheus コンポーネントのバージョンと、更新が必要かどうかを確認する必要があります。
ソリューション
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
クラスター ページで、管理するクラスターを見つけ、その名前をクリックします。左側のナビゲーションウィンドウで、アドオン管理 をクリックします。
[コンポーネント管理] ページで、[ログとモニタリング] タブをクリックし、[ack-arms-prometheus] コンポーネントを探します。
現在のバージョンはコンポーネント名の下に表示されます。新しいバージョンが利用可能な場合は、バージョン番号の横にある[アップグレード]をクリックしてコンポーネントをアップグレードします。
説明インストールされているコンポーネントが最新バージョンではない場合にのみ、[アップグレード] ボタンが表示されます。
GPU モニタリングをデプロイできない理由
原因
GPU ノードに Taint がある場合、GPU モニタリングのデプロイに失敗することがあります。以下の手順で GPU ノードの Taint を確認できます。
ソリューション
次のコマンドを実行して、ターゲット GPU ノードの Taint を表示します。
GPU ノードにカスタム Taint がある場合、出力に関連するエントリが見つかります。このトピックでは、
keyがtest-key、valueがtest-value、effectがNoScheduleの Taint を例として使用します:kubectl describe node cn-beijing.47.100.***.***期待される出力:
Taints:test-key=test-value:NoScheduleGPU ノードの Taint は、次のいずれかの方法で処理できます。
次のコマンドを実行して、GPU ノードの Taint を削除します。
kubectl taint node cn-beijing.47.100.***.*** test-key=test-value:NoSchedule-GPU ノードの Taint に対して Toleration を宣言し、Pod がノードにスケジュールされることを許可します。
# 1. 次のコマンドを実行して ack-prometheus-gpu-exporter を編集します。 kubectl edit daemonset -n arms-prom ack-prometheus-gpu-exporter # 2. YAML ファイルに次のフィールドを追加して、Taint に対する Toleration を宣言します。 # 他のフィールドは省略します。 # tolerations フィールドは containers フィールドの上に追加され、containers フィールドと同じレベルにあります。 tolerations: - key: "test-key" operator: "Equal" value: "test-value" effect: "NoSchedule" containers: # 他のフィールドは省略します。
再インストール失敗を避けるために ARMS-Prometheus を完全にアンインストールする方法
背景情報
Prometheus Monitoring for Alibaba Cloud の名前空間のみを削除した場合、残存する構成が残り、再インストールが失敗する可能性があります。すべての ARMS-Prometheus 構成を完全に手動で削除するには、次の操作を実行します。
ソリューション
arms-prom 名前空間を削除します。
kubectl delete namespace arms-promClusterRoles を削除します。
kubectl delete ClusterRole arms-kube-state-metrics kubectl delete ClusterRole arms-node-exporter kubectl delete ClusterRole arms-prom-ack-arms-prometheus-role kubectl delete ClusterRole arms-prometheus-oper3 kubectl delete ClusterRole arms-prometheus-ack-arms-prometheus-role kubectl delete ClusterRole arms-pilot-prom-k8s kubectl delete ClusterRole gpu-prometheus-exporter kubectl delete ClusterRole o11y:addon-controller:role kubectl delete ClusterRole arms-aliyunserviceroleforarms-clusterroleClusterRoleBinding を削除します。
kubectl delete ClusterRoleBinding arms-node-exporter kubectl delete ClusterRoleBinding arms-prom-ack-arms-prometheus-role-binding kubectl delete ClusterRoleBinding arms-prometheus-oper-bind2 kubectl delete ClusterRoleBinding arms-kube-state-metrics kubectl delete ClusterRoleBinding arms-pilot-prom-k8s kubectl delete ClusterRoleBinding arms-prometheus-ack-arms-prometheus-role-binding kubectl delete ClusterRoleBinding gpu-prometheus-exporter kubectl delete ClusterRoleBinding o11y:addon-controller:rolebinding kubectl delete ClusterRoleBinding arms-kube-state-metrics-agent kubectl delete ClusterRoleBinding arms-node-exporter-agent kubectl delete ClusterRoleBinding arms-aliyunserviceroleforarms-clusterrolebindingRole と RoleBinding を削除します。
kubectl delete Role arms-pilot-prom-spec-ns-k8s kubectl delete Role arms-pilot-prom-spec-ns-k8s -n kube-system kubectl delete RoleBinding arms-pilot-prom-spec-ns-k8s kubectl delete RoleBinding arms-pilot-prom-spec-ns-k8s -n kube-system
ARMS-Prometheus リソースを手動で削除した後、Container Service for Kubernetes (ACK) コンソールで [運用管理 > コンポーネント管理] に移動し、[ack-arms-prometheus] コンポーネントを再インストールします。
ack-arms-prometheus コンポーネントのインストール中に「xxx in use」エラーが発生する
原因
ack-arms-prometheus コンポーネントをデプロイする際に、「xxx in use」エラーが報告されます。これは、リソースが占有されているか、残存リソースが原因でコンポーネントのインストールが失敗している可能性があります。
ソリューション
[クラスター] ページで、対象クラスターの名前をクリックします。クラスター詳細ページの左側のナビゲーションウィンドウで、 を選択します。
[Helm] ページで、ack-arms-prometheus が存在することを確認します。
[Helm] ページから ack-arms-prometheus を削除し、[アドオン] ページで再インストールします。 詳細については、「コンポーネントの管理」をご参照ください。
見つからない場合:
ack-arms-prometheusが見つからない場合、ack-arms-prometheusHelm Release の削除から残存リソースが残っていることを示します。その後、手動で ARMS-Prometheus を完全に削除する必要があります。
「コンポーネントがインストールされていません」というメッセージが表示された後、ack-arms-prometheus コンポーネントのインストールに失敗する
症状
ack-arms-prometheus コンポーネントをインストールしようとすると、最初に「コンポーネントがインストールされていません」というメッセージが表示され、2 回目の試行でもインストールに失敗します。
ソリューション
ack-arms-prometheus コンポーネントが既にインストールされているかどうかを確認します。
[クラスター] ページで対象のクラスターの名前をクリックし、クラスター詳細ページの左側のナビゲーションウィンドウで を選択します。
[Helm] ページで、ack-arms-prometheus が存在することを確認します。
[Helm] ページから ack-arms-prometheus を削除し、[アドオン] ページで再インストールします。 詳細については、「コンポーネントの管理」をご参照ください。
見つからない場合:
ack-arms-prometheusが見つからない場合、ack-arms-prometheusHelm Release の削除から残存リソースが残っていることを示します。その後、手動で ARMS-Prometheus を完全に削除する必要があります。
ack-arms-prometheus のログにエラーがないか確認します。
クラスター詳細ページの左側にあるナビゲーションウィンドウで、 を選択します。
[デプロイメント] ページの上部で、[名前空間]を [arms-prom] に設定し、arms-prometheus-ack-arms-prometheus をクリックします。
[ログ] タブをクリックし、ログでエラーを確認します。
エージェントのインストール中にエラーが発生したかどうかを確認します。
ARMS コンソールにログインします。左側のナビゲーションウィンドウで、[統合管理] をクリックします。
[統合管理] タブで、[コンテナーサービス] リストから目的のコンテナー環境を探します。[アクション] 列で [エージェントの設定] をクリックして、[エージェントの設定] ページを開きます。
オープンソース Prometheus モニタリング
DingTalk アラート通知を設定する方法
症状
オープンソース Prometheus をデプロイした後、DingTalk を使用してアラート通知を送信するように構成する必要があります。
ソリューション
prometheus-operator のデプロイ中にエラーが発生する
症状
Can't install release with errors: rpc error: code = Unknown desc = object is being deleted: customresourcedefinitions.apiextensions.k8s.io "xxxxxxxx.monitoring.coreos.com" already existsソリューション
エラーメッセージは、クラスターが以前のデプロイメントのカスタムリソース定義 (CRD) オブジェクトをクリアできなかったことを示しています。次のコマンドを実行して CRD オブジェクトを削除します。その後、prometheus-operator を再度デプロイします:
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.comメールアラートが機能しない
症状
オープンソース Prometheus をデプロイした後、構成したメールアラートがアラート通知を送信しません。
ソリューション
smtp_auth_password の値がメールアカウントのログインパスワードではなく、SMTP 認証コードであることを確認してください。SMTP サーバーのエンドポイントにポート番号が含まれていることを確認してください。
[YAML の更新] をクリックすると、「クラスターにアクセスできません。後でもう一度試すか、チケットを送信してください。」というエラーメッセージが表示される
症状
オープンソース Prometheus をデプロイした後、[YAML の更新] をクリックすると、「現在のクラスターは一時的にアクセスできません。後でもう一度試すか、フィードバックのためにチケットを送信してください」というエラーメッセージが表示されます。
ソリューション
Tiller の構成ファイルが大きすぎると、クラスターにアクセスできなくなります。この問題を解決するには、構成ファイル内の一部の注釈を削除し、ファイルを ConfigMap として Pod にマウントします。ConfigMap の名前は、prometheus および alertmanager セクションの configMaps フィールドで指定できます。詳細については、「Prometheus への ConfigMap のマウント」の 2 番目の方法をご参照ください。
prometheus-operator をデプロイした後に機能を有効にする方法
症状
オープンソース Prometheus をデプロイした後、その機能を有効にするためにさらに構成を行う必要がある場合があります。
ソリューション
prometheus-operator がデプロイされた後、次の手順を実行して prometheus-operator の機能を有効にできます。クラスターの詳細ページに移動し、左側のナビゲーションウィンドウで を選択します。[Helm] ページで [ack-prometheus-operator] を探し、[操作] 列の [更新] をクリックします。[リリース更新] パネルで、コードブロックを設定して機能を有効にします。次に、[OK] をクリックします。
TSDB と Alibaba Cloud ディスクの選択方法
症状
ストレージソリューションを選択する際、TSDB と Alibaba Cloud ディスクのどちらを選択し、データ保持ポリシーをどのように構成すればよいですか?
ソリューション
TSDB ストレージは限られたリージョンで利用可能です。ただし、ディスクストレージはすべてのリージョンでサポートされています。次の図は、データ保持ポリシーの構成方法を示しています。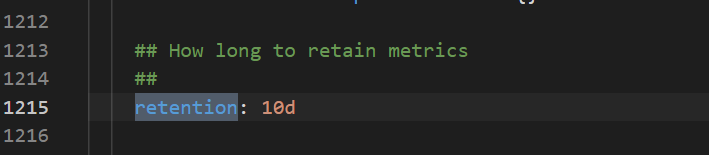
Grafana ダッシュボードが正しく表示されない
症状
オープンソース Prometheus をデプロイした後、Grafana ダッシュボードが正しく表示されません。
ソリューション
クラスターの詳細ページに移動し、左側のナビゲーションウィンドウで を選択します。 Helm ページで、[ack-prometheus-operator] を見つけ、アクション列の [更新] をクリックします。 Update Release パネルで、[clusterVersion] フィールドの値が正しいかどうかを確認します。 クラスターの Kubernetes バージョンが 1.16 より前の場合は、clusterVersion を 1.14.8-aliyun.1 に設定します。 クラスターの Kubernetes バージョンが 1.16 以降の場合は、clusterVersion を 1.16.6-aliyun.1 に設定します。
名前空間を削除した後、ack-prometheus-operator の再インストールに失敗する
原因
ack-prometheus 名前空間を削除した後、関連するリソース構成が保持される場合があります。この場合、ack-prometheus を再度インストールできないことがあります。次の操作を実行して、関連するリソース構成を削除できます:
ソリューション
ロールベースのアクセス制御 (RBAC) 関連のリソース構成を削除します。
次のコマンドを実行して、関連する ClusterRole を削除します:
kubectl delete ClusterRole ack-prometheus-operator-grafana-clusterrole kubectl delete ClusterRole ack-prometheus-operator-kube-state-metrics kubectl delete ClusterRole psp-ack-prometheus-operator-kube-state-metrics kubectl delete ClusterRole psp-ack-prometheus-operator-prometheus-node-exporter kubectl delete ClusterRole ack-prometheus-operator-operator kubectl delete ClusterRole ack-prometheus-operator-operator-psp kubectl delete ClusterRole ack-prometheus-operator-prometheus kubectl delete ClusterRole ack-prometheus-operator-prometheus-psp次のコマンドを実行して、関連する ClusterRoleBinding を削除します:
kubectl delete ClusterRoleBinding ack-prometheus-operator-grafana-clusterrolebinding kubectl delete ClusterRoleBinding ack-prometheus-operator-kube-state-metrics kubectl delete ClusterRoleBinding psp-ack-prometheus-operator-kube-state-metrics kubectl delete ClusterRoleBinding psp-ack-prometheus-operator-prometheus-node-exporter kubectl delete ClusterRoleBinding ack-prometheus-operator-operator kubectl delete ClusterRoleBinding ack-prometheus-operator-operator-psp kubectl delete ClusterRoleBinding ack-prometheus-operator-prometheus kubectl delete ClusterRoleBinding ack-prometheus-operator-prometheus-psp
次のコマンドを実行して、関連する CRD オブジェクトを削除します:
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com kubectl delete crd alertmanagers.monitoring.coreos.com kubectl delete crd podmonitors.monitoring.coreos.com kubectl delete crd probes.monitoring.coreos.com kubectl delete crd prometheuses.monitoring.coreos.com kubectl delete crd prometheusrules.monitoring.coreos.com kubectl delete crd servicemonitors.monitoring.coreos.com kubectl delete crd thanosrulers.monitoring.coreos.com
アラート管理
アラートルールの同期に失敗し、「The Project does not exist : k8s-log-xxx」というエラーメッセージが報告される
症状
アラートセンターで、アラートルールの同期ステータスに The Project does not exist : k8s-log-xxx というメッセージが表示されます。
原因
SLS イベントセンターのリソースが作成されていません。
ソリューション
Simple Log Service コンソールで、クォータ制限に達しているかどうかを確認します。リソースの詳細については、「基本リソース制限」をご参照ください。
ack-node-problem-detector コンポーネントを再インストールします。
コンポーネントを再インストールすると、k8s-log-xxxxxx という名前のデフォルトプロジェクトが再作成されます。
ack-node-problem-detector コンポーネントをアンインストールします。
Container Service for Kubernetes コンソールの対象クラスターの管理ページで、左側のナビゲーションウィンドウからを選択します。
[ログとモニタリング] タブをクリックします。次に、[ack-node-problem-detector] コンポーネントカード上の [アンインストール] をクリックし、ダイアログボックスで [確認] をクリックします。
アンインストールが完了したら、ack-node-problem-detector コンポーネントをインストールします。
左側のナビゲーションウィンドウで、 を選択します
[アラートルール] ページで [インストールを開始] をクリックすると、コンソールによってプロジェクトが自動的に作成され、コンポーネントがインストールおよびアップグレードされます。
[アラート ルール] ページで対応するアラート ルール セットを無効にし、その [アラート ルール ステータス] が [ルール無効] に変わるまで待機してから、ルール セットを再度有効にしてリトライします。
アラートルールが同期に失敗し、this rule have no xxx contact groups reference というエラーメッセージが報告される
症状
構成またはデプロイ中にアラートルールの同期に失敗し、this rule have no xxx contact groups reference などのエラーメッセージがシステムに表示されます。その結果、このアラートルールの通知は配信されません。
原因
アラートルールの同期に失敗し、this rule have no xxx contact groups reference のようなエラーメッセージが報告されます。
ソリューション
連絡先を作成し、連絡先グループに追加していること。
対象のアラートルールセットの右にある [通知ポリシーの編集] をクリックし、アラートルールセットをサブスクライブする連絡先グループを設定します。
その他の問題
kubectl top pod/node でデータが返されない理由
症状
コマンドラインで kubectl top pod または kubectl top node を実行すると、データが返されません。
ソリューション
次のコマンドを実行して、metrics-server API Service が正常かどうかを確認します。
kubectl get apiservices | grep metrics-server
v1beta1.metrics.k8s.ioの返された結果がTrueを示している場合、metrics-server API Service は正常です。オプション: metrics-server API Service が正常でない場合は、クラスターノードで次のコマンドを実行して、クラスター内で metrics-server のポート 443 と 8082 に正常にアクセスできるかどうかを確認します。
curl -v <metrics-server_Pod_IP>:8082/apis/metrics/v1alpha1/nodes curl -v <metrics-server_Pod_IP>:443/apis/metrics/v1alpha1/nodesコマンドが正常にデータを返す場合、クラスター内で metrics-server のポート 443 と 8082 に正常にアクセスできます。
オプション: クラスター内で metrics-server のポート 443 と 8082 に正常にアクセスできない場合は、metrics-server を再起動します。
metrics-server は、その Pod を削除することで再起動できます。
[ステートレス] ページの上部で、[名前空間] を `kube-system` に設定し、`metrics-server` をクリックします。
[Pods] タブで、metrics-server Pod の [アクション] 列で [その他] > [削除] を選択し、ダイアログボックスで [OK] をクリックします。
kubectl top pod/node で一部のデータが欠落する理由
症状
kubectl top pod または kubectl top node を実行すると、一部のデータが欠落します。
ソリューション
以下の事前チェックを実行します。
特定のノード上のすべての Pod にデータがないか、または特定の Pod にデータがないかを確認します。特定のノード上のすべての Pod にデータがない場合は、ノードにタイムゾーンのずれがあるかどうかを確認します。NTP サーバーで
dateコマンドを使用してタイムゾーンを確認できます。metrics-server Pod から特定のノードのポート 10255 へのネットワーク接続を確認します。
HPA がメトリックデータを取得できない場合の対処法
症状
Kubernetes Horizontal Pod Autoscaler (HPA) を使用していると、メトリックデータを取得できない状況に遭遇することがあります。
ソリューション
以下の事前チェックを実行します。
対応する Pod に対して kubectl top pod を実行した結果を確認します。データが異常な場合は、「kubectl top pod/node でデータが返されない理由」および「kubectl top pod/node で一部のデータが欠落する理由」のチェック方法をご参照ください。
ローリングデプロイ中に HPA が余分な Pod を作成する理由
症状
Kubernetes のローリングアップデート中に、Horizontal Pod Autoscaler (HPA) が予期せず余分な Pod を起動することがあります。
ソリューション
以下の事前チェックを実行します。
metrics-server が最新バージョンにアップグレードされているかどうかを確認します。バージョンが正しい場合は、kubectl edit deployments -n kube-system metrics-server コマンドを使用して、command セクションに次の起動パラメーターを追加します。
--metric-resolution=15s
--enable-hpa-rolling-update-skipped=true