ACK One 登録済みクラスターのアラートを設定して、Container Service for Kubernetes (ACK) の異常なアクティビティとメトリックの異常を迅速に検出します。
前提条件
ACK One 登録済みクラスターが作成され、オンプレミスのデータセンターにデプロイされた外部 Kubernetes クラスターが ACK One 登録済みクラスターに接続されています。
登録済みクラスターで Cloud Monitor コンポーネントを設定する
ステップ 1: Cloud Monitor コンポーネントに RAM 権限を付与する
onectl の使用
オンプレミスマシンに onectl をインストールします。詳細については、「onectl を使用して登録済みクラスターを管理する」をご参照ください。
Cloud Monitor コンポーネントに Resource Access Management (RAM) 権限を付与します。
onectl ram-user grant --addon alicloud-monitor-controller予想される出力:
Ram policy ack-one-registered-cluster-policy-alicloud-monitor-controller granted to ram user ack-one-user-ce313528c3 successfully.
コンソールの使用
登録済みクラスターにコンポーネントをインストールする前に、Alibaba Cloud サービスにアクセスするための AccessKey ペアを取得する必要があります。AccessKey ペアを作成するには、まず RAM ユーザーを作成し、その RAM ユーザーにクラウドリソースにアクセスするために必要な権限を付与する必要があります。
カスタムポリシーの作成。次のコードは例です。
{ "Action": [ "log:*", "arms:*", "cms:*", "cs:UpdateContactGroup" ], "Resource": [ "*" ], "Effect": "Allow" }RAM ユーザーの AccessKey ペアを作成します。
警告ネットワークアクセス制御のために AccessKey ペアベースのポリシーを設定し、AccessKey の呼び出し元を信頼できるネットワーク環境に限定して AccessKey のセキュリティを強化することをお勧めします。
AccessKey ペアを使用して、登録済みクラスターに alibaba-addon-secret という名前の Secret を作成します。
Cloud Monitor コンポーネントをインストールすると、システムはこの AccessKey ペアを自動的に使用して、必要なクラウドリソースにアクセスします。
kubectl -n kube-system create secret generic alibaba-addon-secret --from-literal='access-key-id=<your access key id>' --from-literal='access-key-secret=<your access key secret>'説明<your access key id>と<your access key secret>を、取得した AccessKey ペアに置き換えてください。
ステップ 2: Cloud Monitor コンポーネントのインストールとアップグレード
onectl の使用
Cloud Monitor コンポーネントをインストールします。
onectl addon install alicloud-monitor-controller予想される出力:
Addon alicloud-monitor-controller, version **** installed.コンソールの使用
コンソールは、アラート設定が要件を満たしているかどうかを自動的にチェックし、コンポーネントのアクティブ化、インストール、またはアップグレードをガイドします。
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
クラスター ページで、目的のクラスターを見つけてその名前をクリックします。左側のペインで、 を選択します。
[アラート] ページで、画面の指示に従ってコンポーネントをインストールまたはアップグレードします。
インストールまたはアップグレードが完了したら、[アラート] ページに移動してアラート情報を設定します。
タブ
説明
アラートルール管理
ステータス: ターゲットのアラートルールセットをオンまたはオフにします。
通知オブジェクトの編集: アラート通知の連絡先グループを設定します。
これを設定する前に、連絡先とグループを作成し、連絡先をグループに追加します。通知オブジェクトとして選択できるのは連絡先グループのみです。個人に通知するには、その連絡先のみを含むグループを作成し、そのグループを選択します。
アラート履歴
過去 24 時間の最新 100 件のアラートレコードを表示できます。
[アラートルール] 列のリンクをクリックして、対応する監視システムに移動し、詳細なルール設定を表示します。
[トラブルシューティング] をクリックして、異常が発生したリソース (異常イベントまたはメトリック) をすばやく特定します。
[インテリジェント分析] をクリックして、AI アシスタントを使用して問題を分析し、トラブルシューティングのガイダンスを提供します。
連絡先管理
連絡先を管理します。連絡先の作成、編集、削除ができます。
連絡方法:
電話/ショートメッセージ: 連絡先に携帯電話番号を設定すると、連絡先は電話とショートメッセージでアラート通知を受信できます。
電話通知を受信するために使用できるのは、認証済みの携帯電話番号のみです。携帯電話番号の認証方法の詳細については、「携帯電話番号を認証する」をご参照ください。
メール: 連絡先にメールアドレスを設定すると、連絡先はメールでアラート通知を受信できます。
ロボット: DingTalk ロボット、WeCom ロボット、Lark ロボット。
DingTalk ロボットの場合、セキュリティキーワードとして「Alerting」、「Dispatch」を追加する必要があります。
メールとロボットの通知を設定する前に、CloudMonitor コンソールでそれらを検証します。 を選択して、アラート情報を受信できることを確認します。
連絡先グループ管理
連絡先グループを管理します。連絡先グループの作成、編集、削除ができます。[通知オブジェクトの編集] では、連絡先グループのみを選択できます。
連絡先グループが存在しない場合、コンソールは Alibaba Cloud アカウント情報に基づいてデフォルトの連絡先グループを作成します。
アラートの設定
ステップ 1: デフォルトのアラートルールを有効にする
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
クラスター ページで、目的のクラスターを見つけてその名前をクリックします。左側のペインで、 を選択します。
[アラートルール] タブで、アラートルールセットを有効にします。
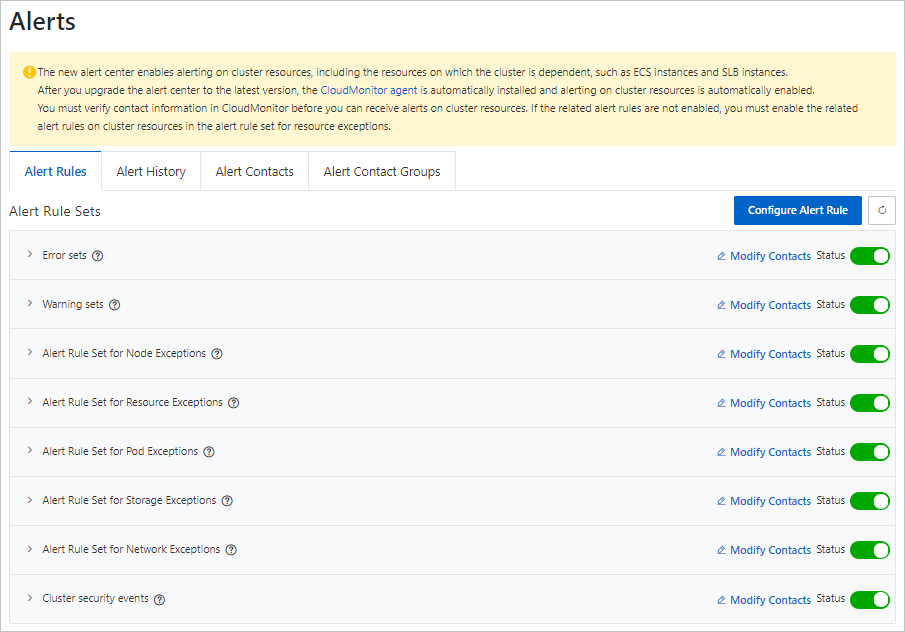
ステップ 2: アラートルールを手動で設定する
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
クラスター ページで、目的のクラスターを見つけてその名前をクリックします。左側のペインで、 を選択します。
[アラートルール管理] タブで、[通知オブジェクトの編集] をクリックして通知オブジェクトを関連付けます。次に、[有効] スイッチをオンにして、アラートルールセットを有効にします。
機能
説明
アラートルール
ACK のアラート機能は、コンテナーシナリオ用のアラートテンプレートを自動的に生成します。テンプレートには、異常イベントやメトリック異常に関するアラートが含まれます。
アラートルールはアラートルールセットに分類されます。複数の連絡先グループをアラートルールセットに関連付け、アラートルールセットを有効または無効にすることができます。
アラートルールセットには複数のアラートルールが含まれています。各アラートルールは、単一の異常に対するチェック項目に対応します。YAML リソースを使用して、対応するクラスターに複数のアラートルールセットを設定できます。YAML ファイルを変更すると、アラートルールが同期されます。
アラートルールの YAML 設定の詳細については、「CRD を使用してアラートルールを設定する」をご参照ください。
デフォルトのアラートルールテンプレートの詳細については、「Container Service アラート管理」をご参照ください。
アラート履歴
最新 100 件のアラートレコードを表示できます。[アラートルールタイプ] 列のリンクをクリックして、対応する監視システムに移動し、詳細なルール設定を表示します。[詳細] 列のリンクをクリックして、アラートがトリガーされたリソースページに移動します。リソースは、異常イベントまたはメトリック異常のあるリソースです。
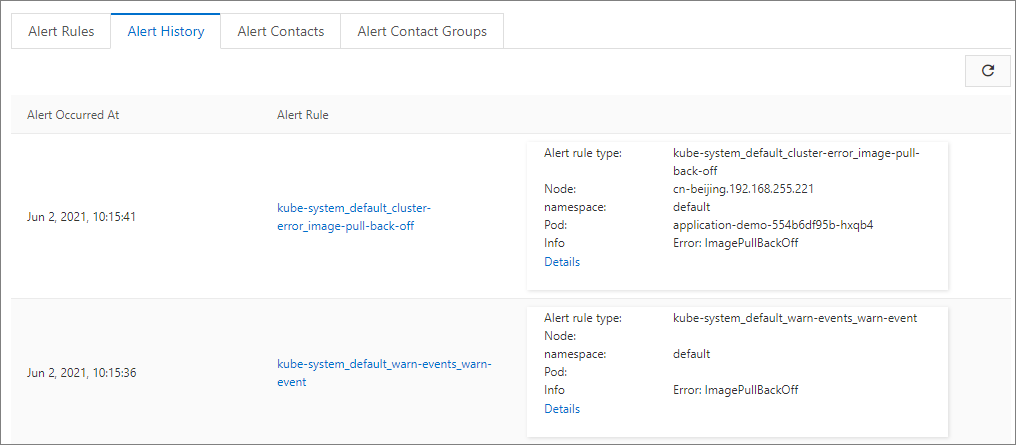
連絡先管理
連絡先の作成、編集、または削除。
アラート連絡先グループ
連絡先グループを作成、編集、または削除します。連絡先グループが存在しない場合、コンソールは Alibaba Cloud アカウントの情報に基づいてデフォルトの連絡先グループを作成します。
CRD を使用してアラートルールを設定する方法
アラート機能が有効になると、デフォルトのアラートルールテンプレートを含む AckAlertRule リソースが [kube-system] 名前空間に作成されます。このリソースを使用して、クラスター内の ACK のアラートルールセットを設定できます。
コンソール
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
クラスター ページで、目的のクラスターを見つけてその名前をクリックします。左側のペインで、 を選択します。
[アラートルール管理] タブで、右上隅にある [アラート設定の編集] をクリックします。次に、ターゲットルールの [アクション] 列にある [YAML] をクリックして、現在のクラスターの AckAlertRule リソース設定を表示します。
必要に応じて YAML ファイルを変更します。詳細については、「デフォルトのアラートルールテンプレート」をご参照ください。
次のコードは、アラートルールの YAML 設定のサンプルを示しています。
rules.thresholdsを使用して、アラートのしきい値をカスタマイズできます。パラメーターの詳細については、次の表をご参照ください。たとえば、上記の設定では、クラスターノードの CPU 使用率が 3 回連続のチェックで 85% を超え、前回のアラートが 900 秒以上前にトリガーされた場合にアラート通知がトリガーされます。パラメーター
必須
説明
デフォルト値
CMS_ESCALATIONS_CRITICAL_Threshold必須
アラートのしきい値。このパラメーターが設定されていない場合、ルールの同期に失敗し、無効になります。
unit: 単位。percent、count、または qps に設定できます。value: しきい値。
デフォルトのアラートテンプレート設定に依存します。
CMS_ESCALATIONS_CRITICAL_Timesオプション
CloudMonitor ルールの再試行回数。設定されていない場合は、デフォルト値が使用されます。
3
CMS_RULE_SILENCE_SECオプション
CloudMonitor が異常によりルールを継続的にトリガーしたときに、最初のアラートが報告された後の解約待機期間 (秒単位)。これにより、アラート疲れを防ぎます。設定されていない場合は、デフォルト値が使用されます。
900
kubectl
次のコマンドを実行して、アラートルールの YAML ファイルを編集します。
kubectl edit ackalertrules default -n kube-system必要に応じて YAML ファイルを変更し、保存して終了します。詳細については、「デフォルトのアラートルールテンプレート」をご参照ください。
rules.thresholdsを使用して、アラートのしきい値をカスタマイズできます。たとえば、上記の設定では、クラスターノードの CPU 使用率が 3 回連続のチェックで 85% を超え、前回のアラートが 900 秒以上前にトリガーされた場合にアラート通知がトリガーされます。パラメーター
必須
説明
デフォルト値
CMS_ESCALATIONS_CRITICAL_Threshold必須
アラートのしきい値。このパラメーターが設定されていない場合、ルールの同期に失敗し、無効になります。
unit: 単位。percent、count、または qps に設定できます。value: しきい値。
デフォルトのアラートテンプレート設定に依存します。
CMS_ESCALATIONS_CRITICAL_Timesオプション
CloudMonitor ルールの再試行回数。設定されていない場合は、デフォルト値が使用されます。
3
CMS_RULE_SILENCE_SECオプション
CloudMonitor が異常によりルールを継続的にトリガーしたときに、最初のアラートが報告された後の解約待機期間 (秒単位)。これにより、アラート疲れを防ぎます。設定されていない場合は、デフォルト値が使用されます。
900
デフォルトのアラートルールテンプレート
次の状況で、登録済みクラスターにデフォルトのアラートルールが作成されます。
デフォルトのアラートルール機能が有効になっている。
デフォルトのアラートルール機能が無効になっているときに、初めてアラートルールページに移動する。
次の表に、作成されるデフォルトのアラートルールを示します。
アラート項目 | ルールの説明 | アラートソース | Rule_Type | ACK_CR_Rule_Name | SLS_Event_ID |
クラスター検査で異常が検出される | 自動検査メカニズムが潜在的な異常をキャプチャします。特定の問題と日常のメンテナンスポリシーを分析する必要があります。 | Simple Log Service | event | cis-sched-failed | sls.app.ack.cis.schedule_task_failed |