可観測性は、本番環境で大規模言語モデル(LLM)推論サービスを管理するために不可欠です。 サービス、そのポッド、および関連 GPU の主要なパフォーマンスメトリックを監視することにより、パフォーマンスのボトルネックを効果的に特定し、障害を診断できます。 このトピックでは、LLM 推論サービスのモニタリングを設定する方法について説明します。
前提条件
Container Service for Kubernetes(ACK)クラスタでManaged Service for Prometheus が有効になっていること。
課金
LLM 推論サービスのモニタリングを有効にすると、そのメトリックは Managed Service for Prometheus にカスタムメトリックとして送信されます。
カスタムメトリックを使用すると、追加料金が発生します。 コストは、クラスタサイズ、アプリケーション数、データ量などの要因によって異なる場合があります。 使用量クエリを使用して、リソース消費量を監視および管理できます。
ステップ 1:LLM 推論サービスのモニタリングダッシュボードにアクセスする
ARMS コンソールにログオンします。
左側のナビゲーションウィンドウで、[統合センター] をクリックします。 [AI] セクションで、[クラウドネイティブ AI スイート LLM 推論] カードをクリックします。
[クラウドネイティブ AI スイート LLM 推論] パネルで、ターゲットクラスタを選択します。
コンポーネントがすでにインストールされている場合は、この手順をスキップします。
[構成情報] セクションで、パラメータを設定し、[OK] をクリックしてコンポーネントを接続します。
パラメータ
説明
アクセス名
現在の LLM 推論サービスモニタリングの一意の名前。 このパラメータはオプションです。
名前空間
メトリックを収集する名前空間。 このパラメータはオプションです。 空のままにすると、条件を満たすすべての名前空間からメトリックが収集されます。
ポッドポート
LLM 推論サービスポッドのポートの名前。 このポートはメトリック収集に使用されます。 デフォルト値:
http。メトリック収集パス
Prometheus 形式でメトリックを公開する LLM 推論サービスポッドの HTTP パス。 デフォルト値:
/metrics。収集間隔(秒)
モニタリングデータを収集する間隔。
ARMS コンソールの[統合管理] ページで、すべての統合コンポーネントを表示できます。
統合センターの詳細については、「統合ガイド」をご参照ください。
ステップ 2:メトリック収集を有効にして推論サービスをデプロイする
LLM 推論サービスのメトリック収集を有効にするには、デプロイメントマニフェストのポッドスペックに次のラベルを追加します。
...
spec:
template:
metadata:
labels:
alibabacloud.com/inference-workload: <workload_name>
alibabacloud.com/inference-backend: <backend>ラベル | 目的 | 説明 |
| 名前空間内の推論サービスの一意の識別子。 | 推奨値:ポッドを管理するワークロードリソースの名前(StatefulSet、Deployment、RoleBasedGroup など)。 このラベルが存在する場合、ポッドは ARMS メトリック収集ターゲットに追加されます。 |
| サービスで使用される推論エンジン。 | サポートされている値は次のとおりです。
|
上記のコードスニペットは、LLM 推論サービスポッドのメトリック収集を有効にする方法を示しています。 完全なデプロイメント例については、次のトピックを参照してください。
ステップ 3:推論サービスのモニタリングダッシュボードを表示する
ACK コンソールにログオンします。
左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、ターゲットの ACK または Alibaba Cloud Container Compute Service(ACS)クラスタをクリックします。 左側のナビゲーションウィンドウで、 を選択します。
[Prometheus モニタリング] ページで、 を選択して、詳細なパフォーマンスデータを表示します。
ダッシュボードフィルターを使用して、検査する
namespace、workload_name、およびmodel_nameを選択します。 各パネルの詳細な説明については、「ダッシュボードパネルの説明」をご参照ください。
メトリック リファレンス
モニタリングダッシュボードは、次のソースからのメトリックを集約します。
vLLM メトリック:公式のvLLM メトリックリストを参照してください。
SGLang メトリック:公式のSGLang メトリックリストを参照してください。
ダッシュボードパネルの説明
LLM 推論サービスダッシュボードは、サービスのパフォーマンスを階層的に表示するように設計されています。 Kubernetes ワークロードが推論サービスをデプロイしていると想定しています。 推論サービスには複数のインスタンスが含まれる場合があり、インスタンスは 1 つ以上のポッドで構成される場合があります。 各推論サービスインスタンスは、ベースモデルと LoRA アダプターの組み合わせなど、1 つ以上のモデルに LLM 推論機能を提供できます。
ダッシュボードは、次の 3 つの主要なセクションに分かれています。
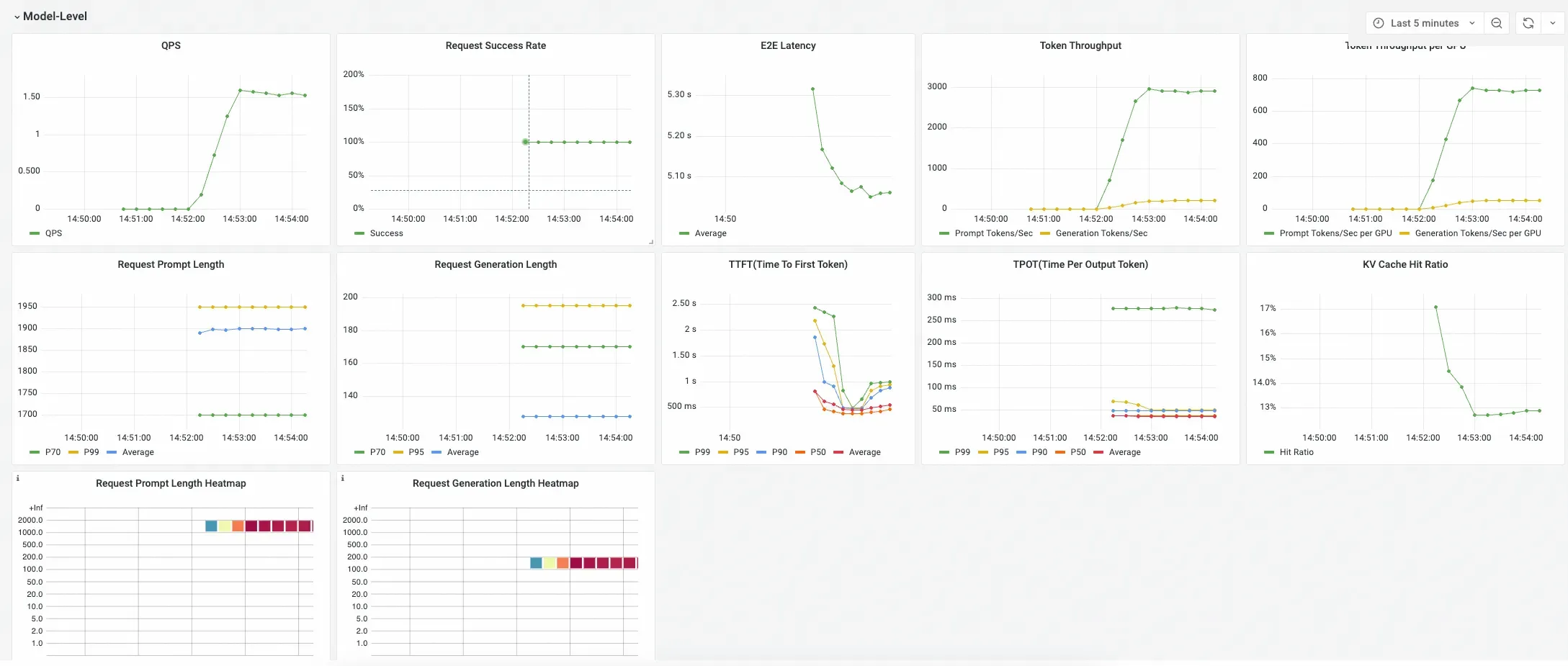
モデルレベル
このセクションには、提供されているすべての推論サービスにわたる特定のモデルの集約メトリックが表示されます。 これらのパネルを使用して、モデルサービスの全体的なパフォーマンスと正常性を評価します。
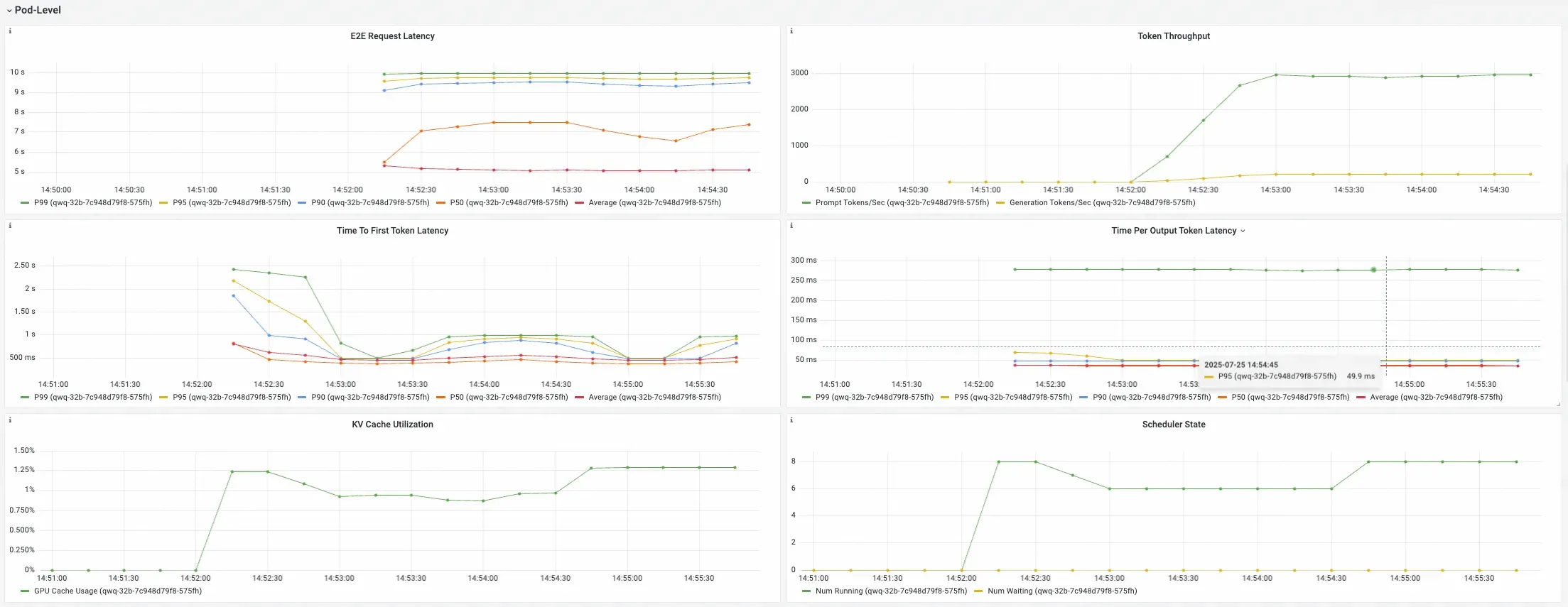
ポッドレベル
このセクションでは、パフォーマンスメトリックを個々のポッドごとに分類します。 これらのパネルを使用して、負荷分散を分析し、サービスのポッド間のパフォーマンスのばらつきを特定します。
GPU 統計(ポッドに関連付けられています)
このセクションでは、各ポッドの詳細な GPU 使用率メトリックを提供します。 これらのパネルを使用して、各推論サービスポッドが GPU リソースをどのように消費しているかを理解します。

パネルの詳細情報
次の表に、ダッシュボードの各パネルとその異なる推論バックエンドとの互換性を示します。