このトピックでは、Qwen3-32B モデルを例に、vLLM および SGLang フレームワークを使用して、Container Service for Kubernetes (ACK) クラスタにマルチノード分散モデル推論サービスをデプロイする方法を示します。
背景
Qwen3-32B
Qwen3-32B は、Qwen シリーズの最新進化形であり、推論効率と会話の流暢さの両方に最適化された 328 億パラメータの密なアーキテクチャを備えています。
主な機能:
デュアルモードパフォーマンス: 論理的推論、数学、コード生成などの複雑なタスクに優れ、一般的なテキスト生成においても高い効率性を維持します。
高度な機能: 命令の追従、複数ターンの対話、クリエイティブライティング、そして AI エージェントタスクのためのクラス最高のツール使用において優れたパフォーマンスを発揮します。
大きなコンテキストウィンドウ: ネイティブで最大 32,000 トークンのコンテキストを処理し、YaRN テクノロジーを使用して 131,000 トークンまで拡張できます。
多言語サポート: 100 以上の言語を理解し、翻訳できるため、グローバルなアプリケーションに最適です。
vLLM
vLLM は、LLM の推論と提供を最適化するために設計された高速で軽量なライブラリであり、スループットを大幅に向上させ、レイテンシを削減します。
コア最適化:
PagedAttention: メモリの無駄を最小限に抑え、スループットを向上させるために、キーバリュー (KV) キャッシュを効率的に管理する革新的な注意アルゴリズムです。
高度な推論: 連続バッチ処理、投機的デコード、および CUDA/HIP グラフアクセラレーションにより、速度と使用率を向上させます。
幅広い並列処理: テンソル並列処理 (TP)、パイプライン並列処理 (PP)、データ並列処理 (DP)、およびエキスパート並列処理 (EP) をサポートし、複数の GPU に拡張できます。
量子化サポート: GPTQ、AWQ、INT4/8、FP8 などの一般的な量子化フォーマットと互換性があり、モデルのメモリフットプリントを削減します。
幅広い互換性:
ハードウェアとモデル: NVIDIA、AMD、Intel の GPU で動作し、Hugging Face および ModelScope の主流モデル (Qwen、Llama、Deepseek、E5-Mistral など) をサポートします。
標準 API: OpenAI 互換 API を提供し、既存のアプリケーションへの統合を容易にします。
詳細については、vLLM GitHub をご参照ください。
SGLang
SGLang は、高性能バックエンドと柔軟なフロントエンドを組み合わせた推論エンジンであり、LLM とマルチモーダルワークロードの両方に設計されています。
高性能バックエンド:
高度なキャッシング: RadixAttention (効率的なプレフィックスキャッシュ) と PagedAttention を備え、複雑な推論タスク中のスループットを最大化します。
効率的な実行: 連続バッチ処理、投機的デコード、PD 分離、マルチ LoRA バッチ処理を使用して、複数のユーザーとファインチューニングされたモデルを効率的に処理します。
完全な並列処理と量子化: TP、PP、DP、EP 並列処理、およびさまざまな量子化手法 (FP8、INT4、AWQ、GPTQ) をサポートします。
柔軟なフロントエンド:
強力なプログラミングインターフェイス: 開発者は、連鎖生成、制御フロー、並列処理などの機能を使用して、複雑なアプリケーションを簡単に構築できます。
マルチモーダルおよび外部インタラクション: マルチモーダル入力 (テキストや画像など) をネイティブでサポートし、外部ツールとのインタラクションを可能にするため、高度なエージェントワークフローに最適です。
幅広いモデルサポート: 生成モデル (Qwen、DeepSeek、Llama)、埋め込みモデル (E5-Mistral)、報酬モデル (Skywork) をサポートします。
詳細については、SGLang GitHub をご参照ください。
分散デプロイメント
LLM のサイズが大きくなるにつれて、そのパラメータは単一の GPU のメモリを超えることがよくあります。これらの大規模モデルを実行するには、さまざまな並列化戦略を使用して、推論タスクを複数のサブタスクに分割します。これらのサブタスクは、GPU に割り当てられます。その後、結果は集約され、LLM 推論タスクが迅速に完了します。一般的な並列化戦略:
データ並列処理 (DP)
各 GPU はモデルの完全なコピーを保持しますが、異なるデータバッチを処理します。これは最も単純で一般的な戦略です。
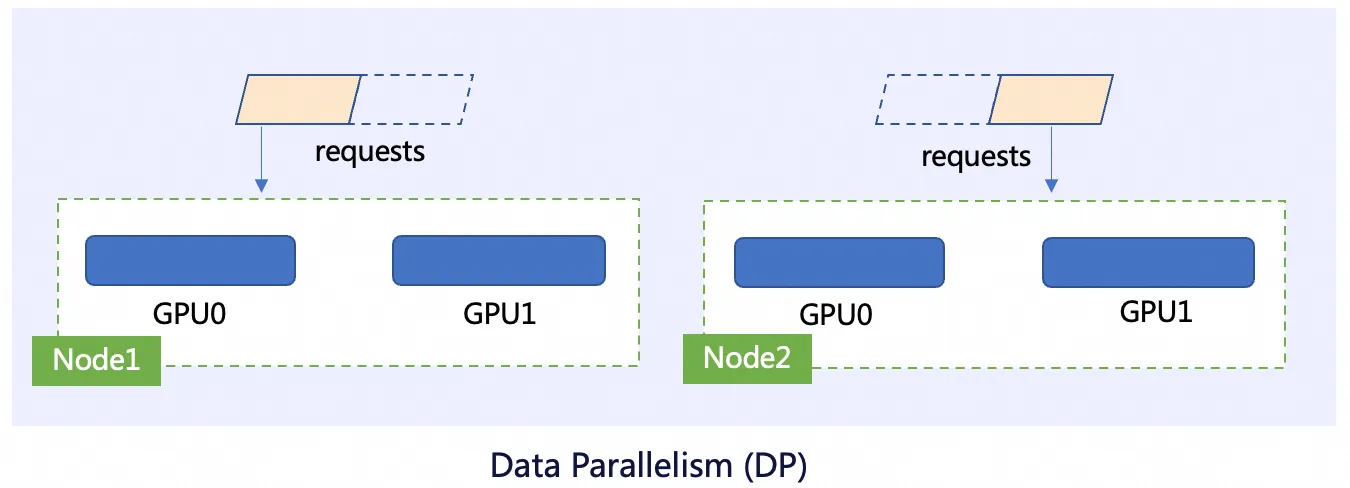
テンソル並列処理 (TP)
モデルの重み行列 (テンソル) を複数の GPU に分割します。各 GPU は、モデルの重みの一部のみを保持し、その部分で計算を行います。
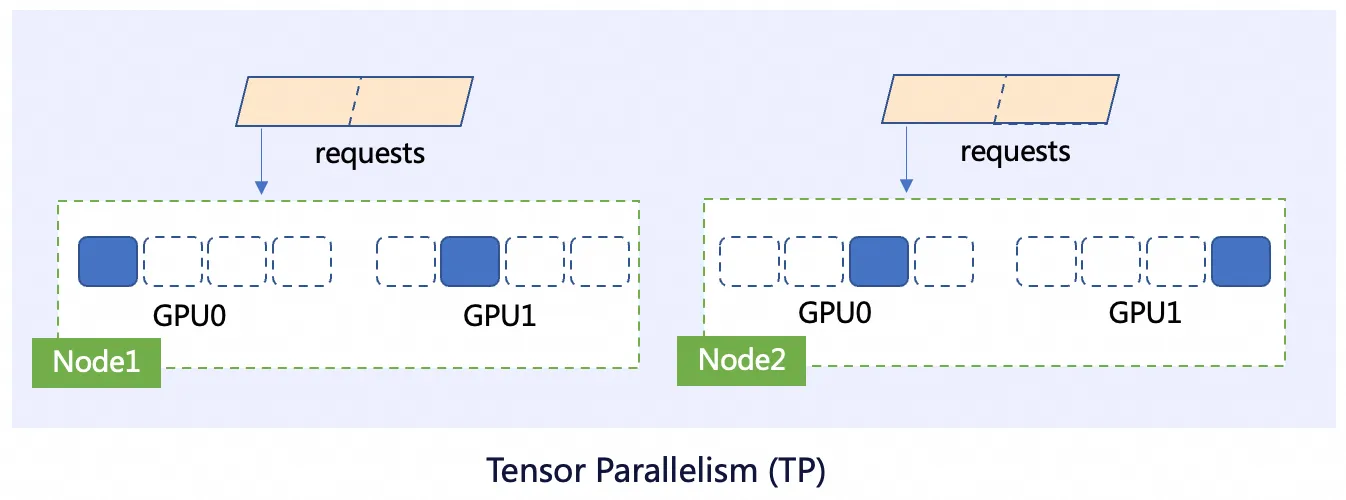
パイプライン並列処理 (PP)
モデルの異なる層を異なる GPU に割り当て、パイプラインを作成します。 GPU 上の 1 つの層の出力は、別の GPU 上の次の層への入力として渡されます。
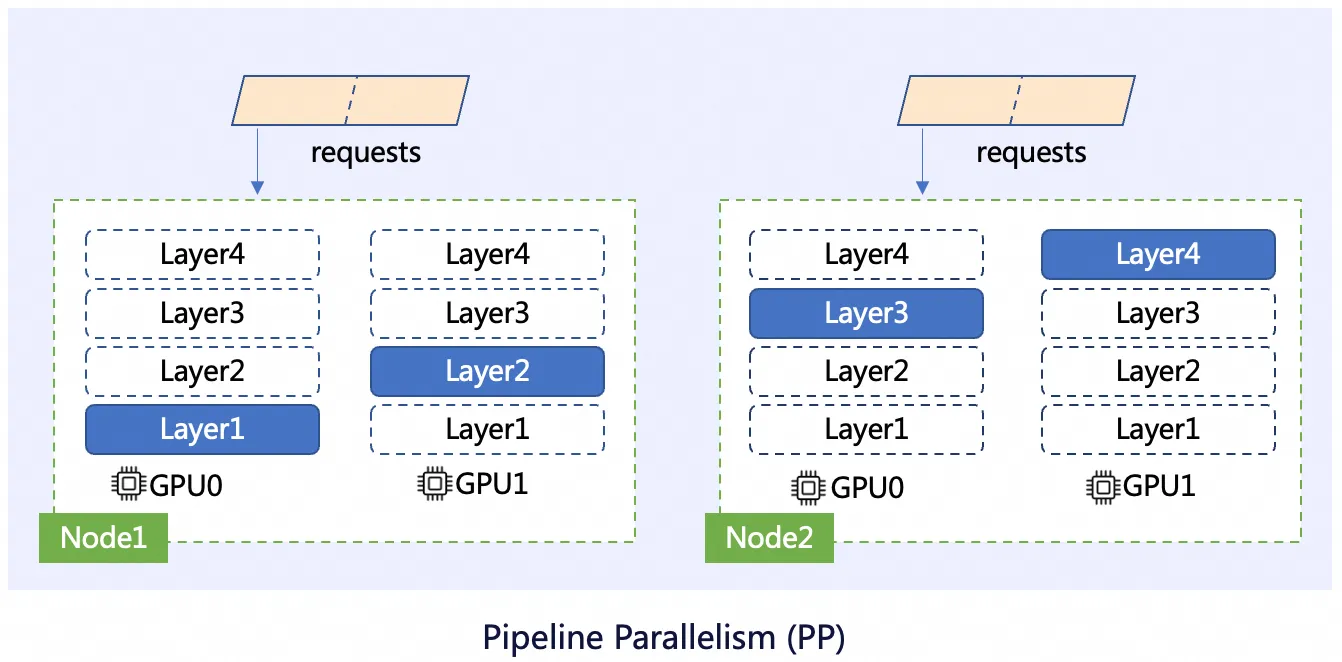
エキスパート並列処理 (EP)
Mixture-of-Experts (MoE) アーキテクチャを持つモデルには、多くの「エキスパート」サブモデルが含まれています。これらのエキスパートのサブセットのみがアクティブ化され、各リクエストを処理します。したがって、これらのエキスパートサブモデルは異なる GPU に格納できます。推論ワークロードに特定のエキスパートが必要な場合、データは関連する GPU にルーティングされます。

前提条件
Kubernetes 1.28 以降を実行する ACK マネージドクラスターがあり、2 つ以上の GPU アクセラレーションノードがあります。各 GPU アクセラレーションノードには、少なくとも 32 GB のメモリが必要です。手順については、「ACK マネージドクラスターを作成する」および「クラスターに GPU アクセラレーションノードを追加する」をご参照ください。
ecs.gn8is.4xlarge インスタンスタイプをお勧めします。詳細については、「GPU コンピューティング最適化インスタンスファミリー gn8is」をご参照ください。
LeaderWorkerSet コンポーネント V0.6.0 以降がインストールされています。 ACK コンソールからインストールできます。
ACK コンソール にログインします。
左側のナビゲーションウィンドウで、[クラスター] をクリックし、作成したクラスターの名前をクリックします。
左側のナビゲーションウィンドウで、 をクリックします。 [Helm] ページで、[デプロイ] をクリックします。
[基本情報] ステップで、[アプリケーション名] と [名前空間] を入力し、[lws] を [チャート] セクションで見つけて、[次へ] をクリックします。 この例では、アプリケーション名 ([lws]) と名前空間 ([lws-system]) が使用されます。
[パラメータ] ステップで、最新の [チャートバージョン] を選択し、[OK] をクリックして [lws] をインストールします。
モデルデプロイメント
ステップ 1: Qwen3-32B モデルファイルを準備する
次のコマンドを実行して、ModelScope から Qwen3-32B モデルをダウンロードします。
git-lfsプラグインがインストールされていない場合は、yum install git-lfsまたはapt-get install git-lfsを実行してインストールします。その他のインストール方法については、「Git Large File Storage のインストール」をご参照ください。git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/Qwen/Qwen3-32B.git cd Qwen3-32B/ git lfs pullOSS コンソール にログインし、バケットの名前を記録します。バケットを作成していない場合は、「バケットを作成する」をご参照ください。 Object Storage Service (OSS) にディレクトリを作成し、モデルをアップロードします。
ossutil のインストールと使用方法の詳細については、「ossutil をインストールする」をご参照ください。
ossutil mkdir oss://<your-bucket-name>/Qwen3-32B ossutil cp -r ./Qwen3-32B oss://<your-bucket-name>/Qwen3-32Bllm-modelという永続ボリューム (PV) と、クラスターの永続ボリューム要求 (PVC) を作成します。詳細な手順については、「PV と PVC を作成する」をご参照ください。コンソールを使用した例
PV を作成する
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、目的のクラスターを見つけて名前をクリックします。左側のペインで、 を選択します。
[永続ボリューム] ページで、右上隅にある [作成] をクリックします。
[永続ボリュームの作成] ダイアログボックスで、パラメータを構成します。
次の表は、サンプル PV の基本構成を示しています。
パラメータ
説明
[PV タイプ]
この例では、[OSS] を選択します。
[ボリューム名]
この例では、[llm-model] と入力します。
[アクセス証明書]
OSS バケットにアクセスするために使用する AccessKey ID と AccessKey シークレットを構成します。
[バケット ID]
前のステップで作成した OSS バケットを選択します。
OSS パス
/Qwen3-32Bなどのモデルが配置されているパスを入力します。
PVC を作成する
[クラスター] ページで、目的のクラスターを見つけて名前をクリックします。左側のペインで、 を選択します。
[永続ボリューム要求] ページで、右上隅にある [作成] をクリックします。
[永続ボリューム要求の作成] ページで、パラメータを入力します。
次の表は、サンプル PVC の基本構成を示しています。
構成項目
説明
[PVC タイプ]
この例では、[OSS] を選択します。
[名前]
この例では、[llm-model] と入力します。
[割り当てモード]
この例では、[既存のボリューム] を選択します。
[既存のボリューム]
[PV を選択] ハイパーリンクをクリックし、作成した PV を選択します。
kubectl を使用した例
次の YAML テンプレートを使用して、
llm-model.yamlという名前のファイルを作成します。このファイルには、Secret、静的 PV、および 静的 PVC の構成が含まれています。apiVersion: v1 kind: Secret metadata: name: oss-secret stringData: akId: <your-oss-ak> # OSS バケットにアクセスするために使用する AccessKey ID。 akSecret: <your-oss-sk> # OSS バケットにアクセスするために使用する AccessKey シークレット。 --- apiVersion: v1 kind: PersistentVolume metadata: name: llm-model labels: alicloud-pvname: llm-model spec: capacity: storage: 30Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: llm-model nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: <your-bucket-name> # バケット名。 url: <your-bucket-endpoint> # エンドポイント。例: oss-cn-hangzhou-internal.aliyuncs.com。 otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: <your-model-path> # この例では、パスは /Qwen3-32B/ です。 --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: llm-model spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gi selector: matchLabels: alicloud-pvname: llm-modelSecret、静的 PV、および 静的 PVC を作成します。
kubectl create -f llm-model.yaml
ステップ 2: 分散推論サービスをデプロイする
このトピックでは、LeaderWorkerSet ワークロードを使用して、TP サイズ 2 の 2 つの GPU アクセラレーションノードに推論サービスをデプロイします。
vLLM でデプロイする
vllm_multi.yamlという名前のファイルを作成します。次のコマンドを実行して、vLLM フレームワークを使用してマルチノード LLM 推論サービスをデプロイします。
kubectl create -f vllm_multi.yaml
SGLang でデプロイする
sglang_multi.yamlという名前のファイルを作成します。次のコマンドを実行して、SGLang フレームワークを使用してマルチノード LLM 推論サービスをデプロイします。
kubectl create -f sglang_multi.yaml
ステップ 3: 推論サービスの検証
次のコマンドを実行して、推論サービスとローカル環境の間でポート フォワーディングを確立します。
重要kubectl port-forwardによって確立されたポート フォワーディングは、本番環境レベルの信頼性、セキュリティ、およびスケーラビリティを欠いています。開発およびデバッグの目的にのみ適しており、本番環境では使用しないでください。 Kubernetes クラスターの本番環境対応ネットワーク ソリューションについては、「Ingress 管理」をご参照ください。kubectl port-forward svc/multi-nodes-service 8000:8000想定される出力:
Forwarding from 127.0.0.1:8000 -> 8000 Forwarding from [::1]:8000 -> 8000次のコマンドを実行して、サンプルの推論リクエストをサービスに送信します。
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "/models/Qwen3-32B", "messages": [{"role": "user", "content": "Test it"}], "max_tokens": 30, "temperature": 0.7, "top_p": 0.9, "seed": 10}'想定される出力:
{"id":"chatcmpl-ee6b347a8bd049f9a502669db0817938","object":"chat.completion","created":1753685847,"model":"/models/Qwen3-32B","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"<think>\nOkay, the user sent "Test it". I need to confirm their request first. They might be testing my functionality or want to see my reaction.","tool_calls":[]},"logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":10,"total_tokens":40,"completion_tokens":30,"prompt_tokens_details":null},"prompt_logprobs":null,"kv_transfer_params":null}この出力は、分散モデル サービスが正常に動作し、応答を生成できることを確認します。