このトピックでは、Qwen3-32B モデルを例として使用し、Prefill/decode (PD) 分離アーキテクチャを持つ SGLang 推論エンジンを使用して、Container Service for Kubernetes (ACK) クラスターにモデル推論サービスをデプロイする方法を説明します。
背景
Qwen3-32B
Qwen3-32B は Qwen シリーズの最新の進化形であり、推論効率と会話の流暢さの両方に最適化された 32.8B パラメーターの高密度アーキテクチャを特徴としています。
主な特徴:
デュアルモードパフォーマンス: 論理的推論、数学、コード生成などの複雑なタスクに優れ、一般的なテキスト生成においても高い効率を維持します。
高度な機能: 命令追従、マルチターン対話、創造的な文章作成、および AI エージェントタスクのためのクラス最高のツール使用において優れたパフォーマンスを発揮します。
大規模なコンテキストウィンドウ: ネイティブで最大 32,000 トークンのコンテキストを処理し、YaRN テクノロジーを使用して 131,000 トークンまで拡張できます。
多言語サポート: 100 以上の言語を理解し、翻訳できるため、グローバルなアプリケーションに最適です。
SGLang
SGLang は、高性能なバックエンドと柔軟なフロントエンドを組み合わせた推論エンジンであり、大規模言語モデル (LLM) とマルチモーダルワークロードの両方向けに設計されています。
高性能バックエンド:
高度なキャッシング: RadixAttention (効率的なプレフィックスキャッシュ) と PagedAttention を搭載し、複雑な推論タスク中のスループットを最大化します。
効率的な実行: 継続的なバッチ処理、投機的デコーディング、PD 分離、およびマルチ LoRA バッチ処理を使用して、複数のユーザーとファインチューニングされたモデルに効率的にサービスを提供します。
完全な並列処理と量子化: TP、PP、DP、EP の並列処理をサポートし、さまざまな量子化メソッド (FP8、INT4、AWQ、GPTQ) にも対応しています。
柔軟なフロントエンド:
強力なプログラミングインターフェイス: 開発者は、連鎖生成、制御フロー、並列処理などの機能を使用して、複雑なアプリケーションを簡単に構築できます。
マルチモーダルおよび外部との対話: テキストや画像などのマルチモーダル入力をネイティブでサポートし、外部ツールとの対話を可能にするため、高度なエージェントワークフローに最適です。
幅広いモデルサポート: 生成モデル (Qwen、DeepSeek、Llama)、埋め込みモデル (E5-Mistral)、および報酬モデル (Skywork) をサポートします。
詳細については、「SGLang GitHub」をご参照ください。
PD 分離
PD 分離アーキテクチャは、LLM 推論のための主要な最適化技術です。これは、推論の 2 つのコアステージの競合するリソース要求を解決します:
Prefill ステージ (プロンプト処理): これは、入力プロンプト全体を並行して処理し、初期のキー-値 (KV) キャッシュを生成する計算集約型のプロセスです。計算負荷が高いですが、リクエストの最初に一度だけ実行されます。
Decode ステージ (トークン生成): これは、新しいトークンが 1 つずつ生成されるメモリ集約型の自己回帰プロセスです。各ステップは計算量が少ないですが、GPU メモリ内の大規模なモデルの重みと KV キャッシュへの繰り返し高速アクセスが必要です。
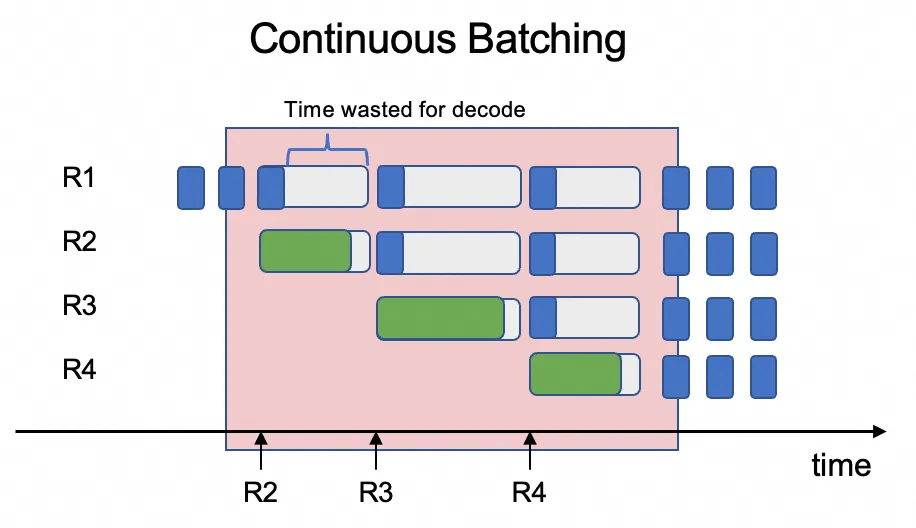
コアの問題: 非効率な混合ワークロードのスケジューリング
課題は、これら 2 つの異なるワークロードを同じ GPU でスケジューリングすることが非常に非効率であることです。推論エンジンは通常、継続的なバッチ処理を使用して複数のユーザーリクエストを同時に処理し、同じバッチ内で異なるリクエストの Prefill ステージと Decode ステージを混合します。これにより、リソースの競合が発生します。計算集約型の Prefill ステージ (プロンプト全体の処理) が GPU のリソースを占有し、はるかに軽量な Decode ステージ (単一トークンの生成) が待機することになります。このリソース競合により、Decode ステージのレイテンシーが増加し、結果としてシステム全体のレイテンシーが増加し、スループットが大幅に低下します。
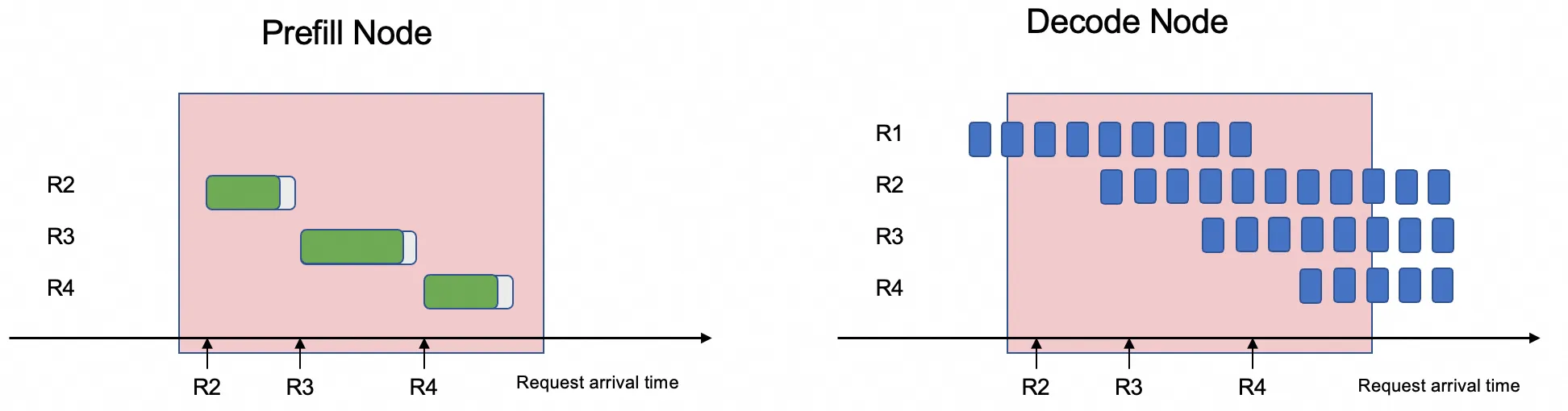
PD 分離アーキテクチャは、2 つのステージを分離し、それぞれを異なる専用の GPU にデプロイすることで、この競合を解決します。
この分離により、システムは各ワークロードのスケジューリングを個別に最適化できます。特定の GPU を Prefill タスクに、他の GPU を Decode タスクに割り当てることで、リソースの競合が解消されます。これにより、平均出力トークンあたりの時間 (TPOT) が大幅に短縮され、システム全体のスループットが大幅に向上します。
RoleBasedGroup
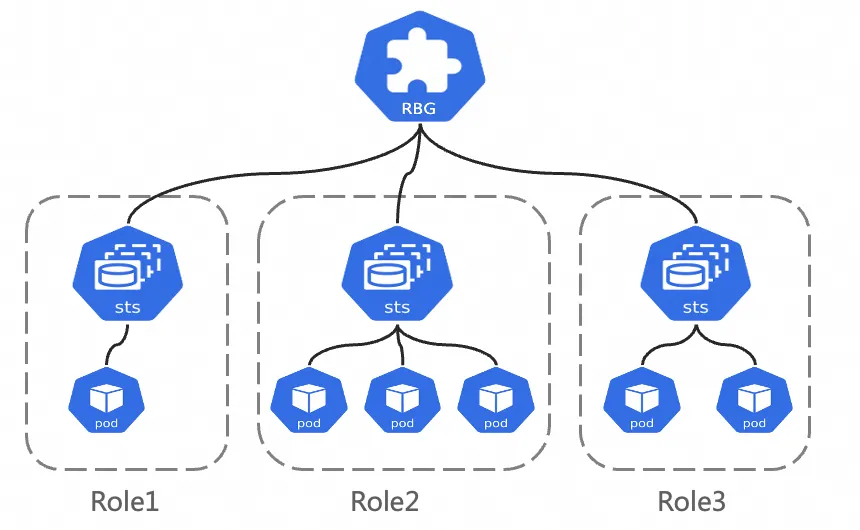
RoleBasedGroup (RBG) は、PD 分離などの複雑なアーキテクチャの大規模なデプロイメントと O&M を簡素化するために ACK チームによって設計された新しい Kubernetes ワークロードです。詳細については、「RBG GitHub プロジェクト」をご参照ください。
RBG はロールのグループによって定義され、各ロールは StatefulSet、Deployment、または他のワークロードタイプに基づいて構築できます。主な特徴:
柔軟なマルチロール定義: RBG を使用すると、任意の名前で任意の数のロールを定義できます。それらの間の起動依存関係を指定し、各ロールを個別にスケーリングできます。
グループレベルのランタイム管理: グループ内での自動サービス検出を提供し、さまざまな再起動ポリシー、ローリングアップデート、およびギャングスケジューリングをサポートします。
前提条件
Kubernetes 1.22 以降を実行し、少なくとも 6 つの GPU を搭載した ACK マネージドクラスター。各 GPU には少なくとも 32 GB のメモリが必要です。詳細については、「ACK マネージドクラスターの作成」および「クラスターへの GPU 高速化ノードの追加」をご参照ください。
ノードは、SGLang PD アーキテクチャで必要とされる GPU Direct RDMA のための elastic RDMA (eRDMA) をサポートする必要があります。
ecs.ebmgn8is.32xlargeインスタンスタイプを推奨します。詳細については、「ECS ベアメタルインスタンスタイプ」をご参照ください。
ノードのオペレーティングシステムは、eRDMA ソフトウェアスタックがプリインストールされたイメージである必要があります。たとえば、Alibaba Cloud Marketplace の Alibaba Cloud Linux 3 64 ビット (eRDMA 付き) などです。オペレーティングシステムイメージ: eRDMA を使用するには、eRDMA ソフトウェアスタックが必要です。ノードプールを作成する際は、必要なソフトウェアスタックがプリインストールされている Alibaba Cloud Marketplace の Alibaba Cloud Linux 3 64 ビットイメージを選択することをお勧めします。詳細については、「ACK での eRDMA ノードの追加」をご参照ください。
クラスターに ACK eRDMA Controller をインストールして構成します。詳細については、「eRDMA を使用してコンテナーネットワークを高速化する」をご参照ください。
ack-rbgs コンポーネントがクラスターにインストールされている必要があります。次の手順を実行してコンポーネントをインストールできます。
Container Service 管理コンソールにログインします。左側のナビゲーションウィンドウで、[クラスターリスト] を選択します。ターゲットクラスターの名前をクリックします。クラスターの詳細ページで、Helm を使用して [ack-rbgs] コンポーネントをインストールします。コンポーネントの [アプリケーション名] または [名前空間] を構成する必要はありません。[次へ] をクリックすると、[確認] ダイアログボックスが表示されます。[はい] をクリックして、デフォルトのアプリケーション名 ([ack-rbgs]) と名前空間 ([rbgs-system]) を受け入れます。次に、最新の Chart バージョンを選択し、[OK] をクリックしてインストールを完了します。
モデルのデプロイメント
Prefill/Decode 分離アーキテクチャで推論サービスをデプロイします。次の時系列グラフは、SGLang Prefill Server と Decode Server 間の相互作用を示しています。
ユーザーの推論リクエストが受信されると、Prefill Server は Sender オブジェクトを作成し、Decode Server は Receiver オブジェクトを作成します。
Prefill Server と Decode Server は、ハンドシェイクを通じて接続を確立します。Decode Server はまず、KV キャッシュを受信するための GPU メモリアドレスを割り当てます。Prefill Server が計算を完了すると、KV キャッシュを Decode Server に送信します。その後、Decode Server は、ユーザーの推論リクエストが完了するまで後続のトークンの計算を続行します。

ステップ 1: Qwen3-32B モデルファイルの準備
次のコマンドを実行して、ModelScope から Qwen3-32B モデルをダウンロードします。
git-lfsプラグインがインストールされていない場合は、yum install git-lfsまたはapt-get install git-lfsを実行してインストールします。その他のインストール方法については、「Git Large File Storage のインストール」をご参照ください。git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/Qwen/Qwen3-32B.git cd Qwen3-32B/ git lfs pullOSS コンソールにログインし、バケットの名前を記録します。まだ作成していない場合は、「バケットの作成」をご参照ください。Object Storage Service (OSS) にディレクトリを作成し、モデルをアップロードします。
ossutil のインストールと使用方法の詳細については、「ossutil のインストール」をご参照ください。
ossutil mkdir oss://<your-bucket-name>/Qwen3-32B ossutil cp -r ./Qwen3-32B oss://<your-bucket-name>/Qwen3-32Bクラスター用に
llm-modelという名前の永続ボリューム (PV) と永続ボリューム要求 (PVC) を作成します。詳細な手順については、「PV と PVC の作成」をご参照ください。コンソールを使用した例
PV の作成
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
クラスター ページで、目的のクラスターを見つけてその名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。
[ボリューム] ページで、右上の [作成] をクリックします。
[ボリュームの作成] ダイアログボックスで、パラメーターを設定します。
次の表に、サンプル PV の基本構成を示します:
パラメーター
説明
PV タイプ
この例では、[OSS] を選択します。
ボリューム名
この例では、[llm-model] と入力します。
アクセス証明書
OSS バケットへのアクセスに使用する AccessKey ID と AccessKey Secret を設定します。
バケット ID
前のステップで作成した OSS バケットを選択します。
OSS パス
モデルが配置されているパス (例:
/Qwen3-32B) を入力します。
PVC の作成
クラスター ページで、目的のクラスターを見つけてその名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。
[PersistentVolumeClaims] ページで、右上の [作成] をクリックします。
[PersistentVolumeClaim の作成] ページで、パラメーターを設定します。
次の表に、サンプル PVC の基本構成を示します。
設定項目
説明
PVC タイプ
この例では、[OSS] を選択します。
名前
この例では、[llm-model] と入力します。
割り当てモード
この例では、[既存のボリューム] を選択します。
既存のボリューム
[PV の選択] ハイパーリンクをクリックし、作成した PV を選択します。
kubectl を使用した例
次の YAML テンプレートを使用して、
llm-model.yamlという名前のファイルを作成します。このファイルには、Secret、静的 PV、および 静的 PVC の構成が含まれています。apiVersion: v1 kind: Secret metadata: name: oss-secret stringData: akId: <your-oss-ak> # OSS バケットへのアクセスに使用する AccessKey ID。 akSecret: <your-oss-sk> # OSS バケットへのアクセスに使用する AccessKey Secret。 --- apiVersion: v1 kind: PersistentVolume metadata: name: llm-model labels: alicloud-pvname: llm-model spec: capacity: storage: 30Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: llm-model nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: <your-bucket-name> # バケット名。 url: <your-bucket-endpoint> # エンドポイント (例: oss-cn-hangzhou-internal.aliyuncs.com)。 otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: <your-model-path> # この例では、パスは /Qwen3-32B/ です。 --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: llm-model spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gi selector: matchLabels: alicloud-pvname: llm-modelSecret、静的 PV、および 静的 PVC を作成します。
kubectl create -f llm-model.yaml
ステップ 2: Prefill/Decode 分離で SGLang 推論サービスをデプロイする
このトピックでは、RBG を使用して 2P1D SGLang 推論サービスをデプロイします。デプロイメントアーキテクチャを次の図に示します。
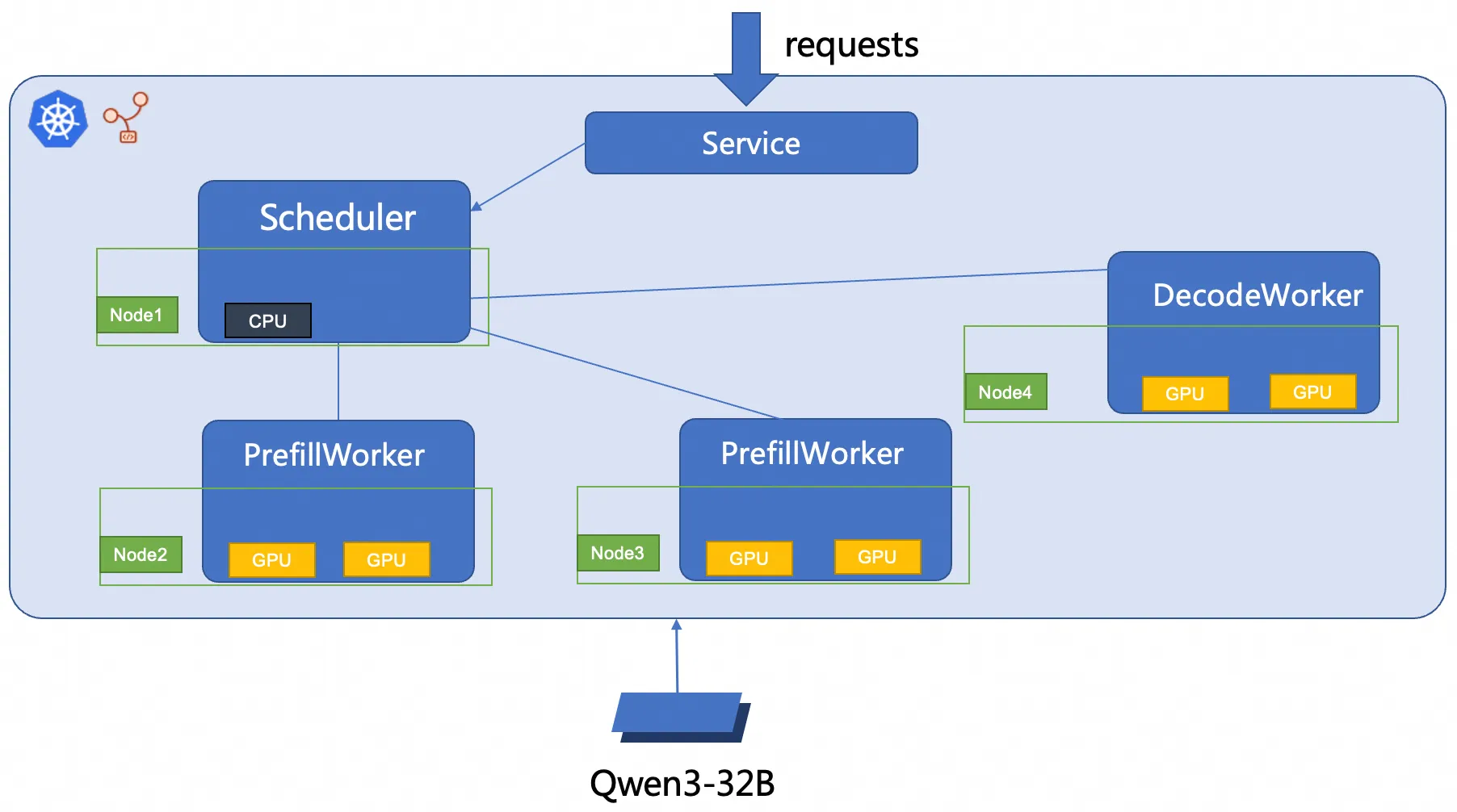
sglang_pd.yamlファイルを作成します。Prefill/Decode 分離で SGLang 推論サービスをデプロイします。
kubectl create -f sglang_pd.yaml
ステップ 3: 推論サービスの検証
次のコマンドを実行して、推論サービスとローカル環境の間にポートフォワーディングを確立します。
重要kubectl port-forwardによって確立されたポートフォワーディングには、本番環境レベルの信頼性、セキュリティ、スケーラビリティがありません。開発およびデバッグ目的でのみ使用するのに適しており、本番環境では使用しないでください。Kubernetes クラスターでの本番環境に対応したネットワークソリューションについては、「Ingress 管理」をご参照ください。kubectl port-forward svc/sglang-pd 8000:8000期待される出力:
Forwarding from 127.0.0.1:8000 -> 8000 Forwarding from [::1]:8000 -> 8000次のコマンドを実行して、モデル推論サービスにサンプルの推論リクエストを送信できます。
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "/models/Qwen3-32B", "messages": [{"role": "user", "content": "test"}], "max_tokens": 30, "temperature": 0.7, "top_p": 0.9, "seed": 10}'期待される出力:
{"id":"29f3fdac693540bfa7808fc1a8701758","object":"chat.completion","created":1753695366,"model":"/models/Qwen3-32B","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\nOkay, the user wants me to do a test. I need to first confirm their specific needs. Maybe they want to test my functions, such as answering questions or generating content.","reasoning_content":null,"tool_calls":null},"logprobs":null,"finish_reason":"length","matched_stop":null}],"usage":{"prompt_tokens":10,"total_tokens":40,"completion_tokens":30,"prompt_tokens_details":null}}この出力は、モデルが入力テストメッセージに基づいて応答を生成できることを示しています。
参考資料
LLM 推論サービスの Prometheus モニタリングを設定する
本番環境では、LLM サービスの正常性とパフォーマンスを監視することが、安定性を維持するために不可欠です。Managed Service for Prometheus と統合することで、詳細なメトリックを収集して次のことを行うことができます:
障害とパフォーマンスのボトルネックを検出する。
リアルタイムデータで問題をトラブルシューティングする。
長期的なパフォーマンストレンドを分析して、リソース割り当てを最適化する。
OSS や File Storage NAS などのサービスに保存されている大規模なモデルファイル (>10 GB) は、ダウンロード時間が長いため、Pod の起動が遅くなる (コールドスタート) 可能性があります。Fluid は、クラスターのノード全体に分散キャッシングレイヤーを作成することで、この問題を解決します。これにより、次の 2 つの主要な方法でモデルの読み込みが大幅に高速化されます:
データスループットの高速化: Fluid は、クラスター内のすべてのノードのストレージ容量とネットワーク帯域幅をプールします。これにより、単一のリモートソースから大きなファイルをプルする際のボトルネックを克服する高速な並列データレイヤーが作成されます。
I/O レイテンシーの削減: モデルファイルを必要とされる計算ノードに直接キャッシュすることで、Fluid はアプリケーションにローカルでほぼ瞬時のデータアクセスを提供します。この最適化された読み取りメカニズムにより、ネットワーク I/O に関連する長い遅延が解消されます。
Gateway with Inference Extension を使用してインテリジェントなルーティングとトラフィック管理を実装する
ACK Gateway with Inference Extension は、Kubernetes Gateway API 上に構築された強力な Ingress コントローラーであり、AI/ML ワークロードのルーティングを簡素化および最適化します。主な特徴は次のとおりです:
モデルを意識した負荷分散: 最適化された負荷分散ポリシーを提供し、推論リクエストの効率的な分散を保証します。
インテリジェントなモデルルーティング: リクエストペイロード内のモデル名に基づいてトラフィックをルーティングします。これは、単一のエンドポイントの背後で複数のファインチューニングされたモデル (例: 異なる LoRA バリアント) を管理したり、カナリアリリースのためのトラフィック分割を実装したりするのに最適です。
リクエストの優先順位付け: 異なるモデルに優先度レベルを割り当て、最も重要なモデルへのリクエストが最初に処理されるようにし、サービス品質を保証します。