このトピックでは、ノード例外の診断およびトラブルシューティング方法、よくある質問、およびソリューションについて説明します。
目次
カテゴリ | 内容 |
診断プロシージャ | |
一般的なトラブルシューティング方法 | |
一般的な問題とソリューション |
|
診断プロシージャ
ノードが異常状態かどうかを確認します。詳細については、「ノードステータスの確認」をご参照ください。
ノードが 準備未完了 状態の場合、以下の手順で問題をトラブルシューティングしてください。
ノードのステータス情報を確認します。PIDPressure、DiskPressure、MemoryPressure のいずれかの条件が True の場合、その条件に基づいて問題をトラブルシューティングしてください。ソリューションについては、「dockerd 例外 - RuntimeOffline のトラブルシューティング」、「ノードメモリ不足 - MemoryPressure」、「ノード inode 不足 - InodesPressure」をご参照ください。
ノードの主要コンポーネントおよびログを確認します。
kubelet
kubelet のステータス、ログ、構成に例外がないかを確認します。詳細については、「ノード主要コンポーネントの確認」をご参照ください。
kubelet が異常な場合は、「kubelet 例外のトラブルシューティング」をご参照ください。
dockerd
dockerd のステータス、ログ、構成に例外がないかを確認します。詳細については、「ノード主要コンポーネントの確認」をご参照ください。
dockerd が異常な場合は、「dockerd 例外 - RuntimeOffline のトラブルシューティング」をご参照ください。
containerd
containerd のステータス、ログ、構成に例外がないかを確認します。詳細については、「ノード主要コンポーネントの確認」をご参照ください。
containerd が異常な場合は、「containerd 例外 - RuntimeOffline のトラブルシューティング」をご参照ください。
NTP
NTP サービスのステータス、ログ、構成に例外がないかを確認します。詳細については、「ノード主要コンポーネントの確認」をご参照ください。
NTP サービスが異常な場合は、「NTP 例外 - NTPProblem のトラブルシューティング」をご参照ください。
ノードの診断ログを収集して確認します。詳細については、「ノード診断ログの収集」をご参照ください。
ノードのモニタリングデータを確認し、リソース負荷(CPU、メモリ、ネットワークなど)に異常がないかを確認します。詳細については、「ノードモニタリングデータの確認」をご参照ください。ノード負荷が異常な場合は、「ノード CPU 不足」および「ノードメモリ不足 - MemoryPressure」のソリューションをご参照ください。
ノードが 不明 状態の場合、以下の手順で問題をトラブルシューティングしてください。
基盤となる ECS インスタンスが 実行中 状態かどうかを確認します。
ノードの主要コンポーネントを確認します。
kubelet
kubelet のステータス、ログ、構成に例外がないかを確認します。詳細については、「ノード主要コンポーネントの確認」をご参照ください。
kubelet が異常な場合は、「kubelet 例外のトラブルシューティング」をご参照ください。
dockerd
dockerd のステータス、ログ、構成に例外がないかを確認します。詳細については、「ノード主要コンポーネントの確認」をご参照ください。
dockerd が異常な場合は、「dockerd 例外 - RuntimeOffline のトラブルシューティング」をご参照ください。
containerd
containerd のステータス、ログ、構成に例外がないかを確認します。詳細については、「ノード主要コンポーネントの確認」をご参照ください。
containerd が異常な場合は、「containerd 例外 - RuntimeOffline のトラブルシューティング」をご参照ください。
NTP
NTP サービスのステータス、ログ、構成に例外がないかを確認します。詳細については、「ノード主要コンポーネントの確認」をご参照ください。
NTP サービスが異常な場合は、「NTP 例外 - NTPProblem のトラブルシューティング」をご参照ください。
ノードのネットワーク接続を確認します。詳細については、「ノードセキュリティグループの確認」をご参照ください。ネットワーク例外が発生した場合は、「ノードネットワーク例外」のソリューションをご参照ください。
ノードの診断ログを収集して確認します。詳細については、「ノード診断ログの収集」をご参照ください。
ノードのモニタリングデータを確認し、リソース負荷(CPU、メモリ、ネットワークなど)に異常がないかを確認します。詳細については、「ノードモニタリングデータの確認」をご参照ください。ノード負荷が異常な場合は、「ノード CPU 不足」および「ノードメモリ不足 - MemoryPressure」のソリューションをご参照ください。
このプロシージャに従っても問題が解決しない場合は、Container Service for Kubernetes (ACK) の障害診断機能を使用してください。詳細については、「ノード障害診断」をご参照ください。
トラブルシューティング
ノード障害診断
ノードが障害を起こした場合、ACK の例外診断機能を使用して、ワンクリックでノードを診断できます。
ACK コンソールにログインします。左側のナビゲーションウィンドウで、クラスターリスト をクリックします。
クラスターリスト ページで、ご利用のクラスター名をクリックします。左側のナビゲーションウィンドウで、 をクリックします。
[ノード]ページで、診断するノードを見つけ、[アクション]列で[]を選択します。
表示されたパネルで、[診断開始] をクリックします。その後、コンソールで診断結果と推奨されるソリューションを確認します。
ノードの詳細
ACK コンソールにログインします。左側のナビゲーションウィンドウで、クラスターリスト をクリックします。
クラスターリスト ページで、ご利用のクラスター名をクリックします。左側のナビゲーションウィンドウで、 をクリックします。
ノード ページで、対象ノードの名前をクリックするか、詳細 を アクション 列からクリックして、詳細を表示します。
ノードステータス
ACK コンソールにログインします。左側のナビゲーションウィンドウで、クラスターリスト をクリックします。
クラスターリスト ページで、ご利用のクラスター名をクリックします。左側のナビゲーションウィンドウで、 をクリックします。
ノード ページで、ノードのステータスを確認します。
ノードが 準備完了 状態の場合、正常に動作しています。
ノードが 準備完了 状態でない場合、ノード名をクリックするか、詳細 を アクション 列からクリックして、詳細を表示します。
説明InodesPressure、DockerOffline、RuntimeOffline などの条件のステータス情報を収集するには、node-problem-detector をインストールし、クラスターにイベントセンターを作成する必要があります。新規クラスターでは、デフォルトでイベントセンターが自動的に作成されます。詳細については、「Kubernetes クラスターのイベントセンターの作成と使用」をご参照ください。
ノードイベント
ACK コンソールにログインします。左側のナビゲーションウィンドウで、クラスターリスト をクリックします。
クラスターリスト ページで、ご利用のクラスター名をクリックします。左側のナビゲーションウィンドウで、 をクリックします。
ノード ページで、対象ノードの名前をクリックするか、詳細 を アクション 列からクリックして、詳細を表示します。
ノードのイベントは、詳細ページの下部に一覧表示されます。
ノード診断ログ
コンソールの Container Intelligence Service が提供するノード診断機能を使用して、診断ログを収集します。詳細については、「ノード診断」をご参照ください。
スクリプトを使用して診断ログを収集します。詳細については、「Kubernetes クラスターの診断情報の収集方法」をご参照ください。
ノード主要コンポーネント
kubelet
kubelet ステータスの確認
ノードにログインして、次のコマンドを実行します。
systemctl status kubelet期待される出力:
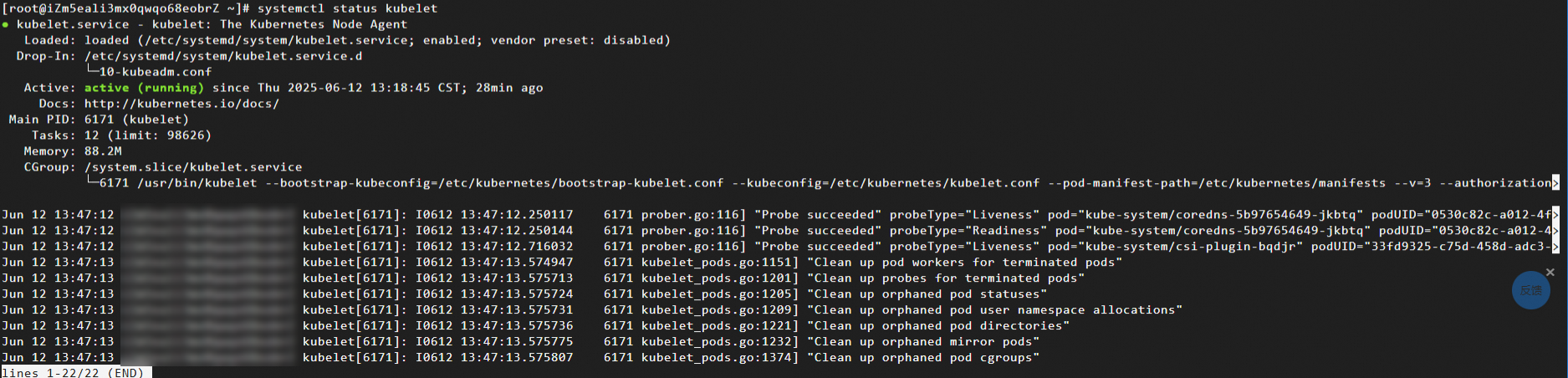
kubelet ログの確認
ノードにログインして、次のコマンドを実行して kubelet ログを表示します。kubelet ログの表示方法の詳細については、「ノード診断ログの収集」をご参照ください。
journalctl -u kubeletkubelet 構成の確認
ノードにログインして、次のコマンドを実行します。
cat /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
ランタイム
dockerd の確認
dockerd ステータスの確認
ノードにログインして、次のコマンドを実行します。
systemctl status docker期待される出力:

dockerd ログの確認
ノードにログインして、次のコマンドを実行して dockerd ログを表示します。dockerd ログの表示方法の詳細については、「ノード診断ログの収集」をご参照ください。
journalctl -u dockerdockerd 構成の確認
ノードにログインして、次のコマンドを実行します。
cat /etc/docker/daemon.json
containerd の確認
containerd ステータスの確認
ノードにログインして、次のコマンドを実行します。
systemctl status containerd期待される出力:
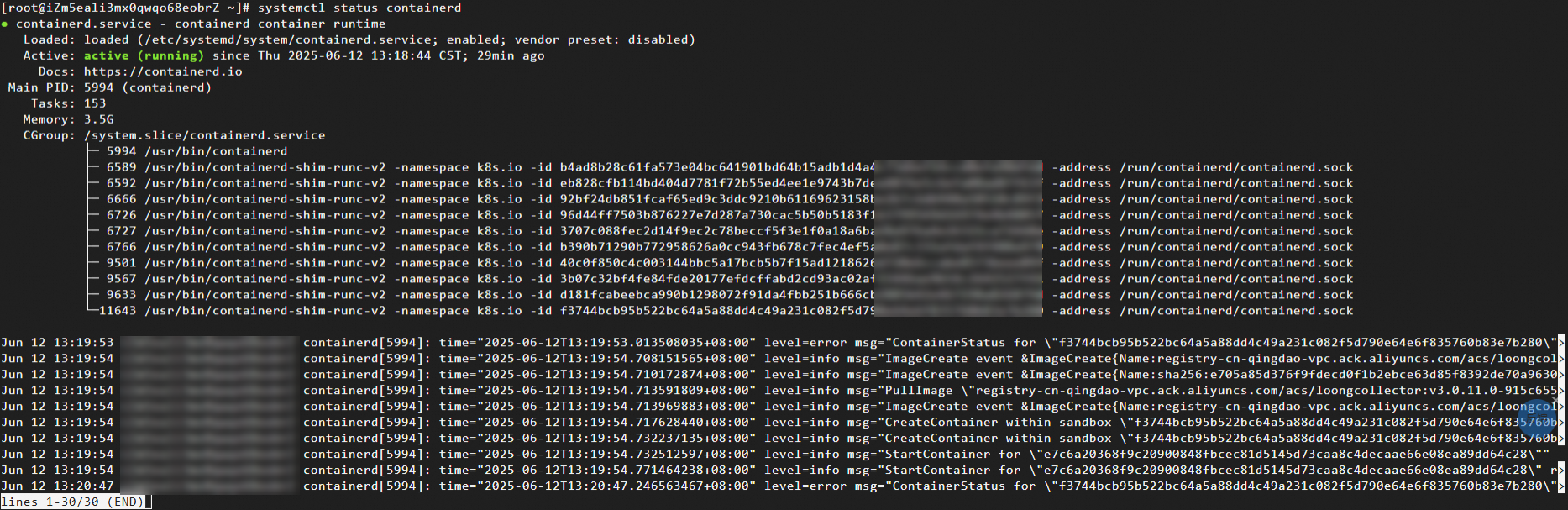
containerd ログの確認
ノードにログインして、次のコマンドを実行して containerd ログを表示します。containerd ログの表示方法の詳細については、「ノード診断ログの収集」をご参照ください。
journalctl -u containerd
NTP
NTP サービスステータスの確認
ノードにログインして、次のコマンドを実行します。
systemctl status chronyd期待される出力:
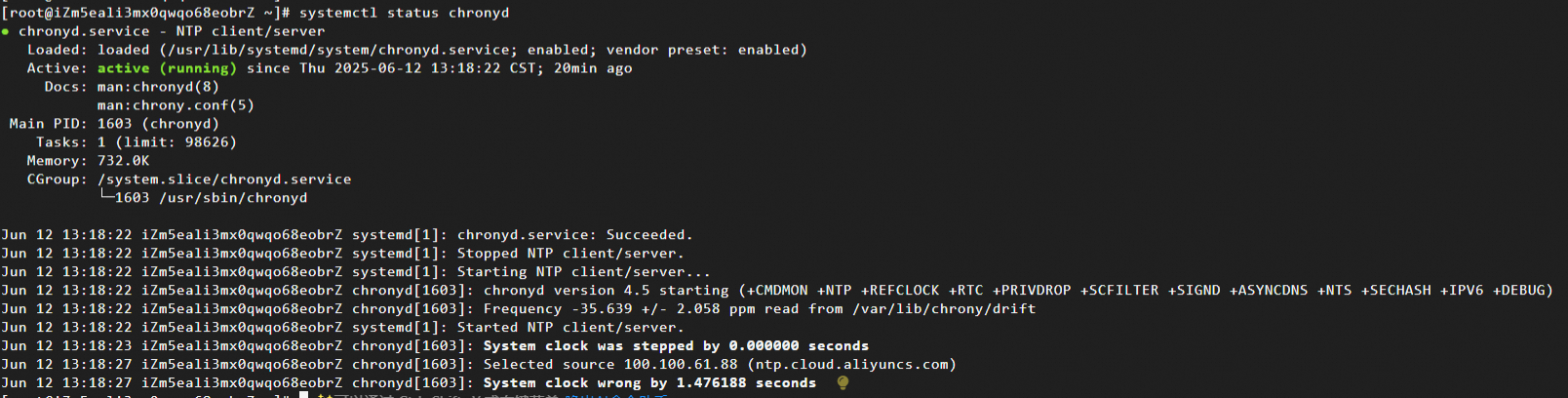
NTP サービスログの確認
ノードにログインして、次のコマンドを実行します。
journalctl -u chronyd
ノードモニタリング
Cloud Monitor
ACK クラスターは CloudMonitor と統合されています。CloudMonitor コンソールにログインして、対応する ECS インスタンスの基本的なモニタリング情報を表示できます。ノードのモニタリング方法の詳細については、「ノードのモニタリング」をご参照ください。
Managed Service for Prometheus
ACK コンソールにログインします。左側のナビゲーションウィンドウで、クラスターリスト をクリックします。
クラスターリスト ページで、ご利用のクラスター名をクリックします。左側のナビゲーションウィンドウで、 をクリックします。
Prometheus 監視 ページで、ノードモニタリング タブをクリックし、続いて ノード数 タブをクリックします。
ノード数 ページで、表示対象のノードを選択します。このページには、ノードの CPU、メモリ、ディスク使用率などのモニタリング情報が表示されます。
ノードセキュリティグループ
ノードのセキュリティグループの確認方法の詳細については、「セキュリティグループ概要」および「クラスターセキュリティグループの設定」をご参照ください。
kubelet 例外のトラブルシューティング
原因
kubelet プロセス、コンテナランタイム、または無効な kubelet 構成の問題が、通常 kubelet 例外の原因となります。
症状
kubelet ステータスが inactive になります。
ソリューション
次のコマンドを実行して kubelet を再起動します。kubelet を再起動しても、実行中のコンテナには影響しません。
systemctl restart kubeletkubelet を再起動後、ノードにログインして、次のコマンドを実行して kubelet ステータスを確認します。
systemctl status kubeletkubelet ステータスが依然として異常な場合は、ノードにログインして、次のコマンドを実行して kubelet ログを表示します。
journalctl -u kubeletログに特定のエラーメッセージが含まれている場合、メッセージのキーワードを使用して問題をトラブルシューティングしてください。
kubelet 構成が無効であると判断した場合は、次のコマンドを実行して構成を変更してください。
vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf # kubelet 構成を変更します。 systemctl daemon-reload;systemctl restart kubelet # 構成を再読み込みして kubelet を再起動します。
dockerd 例外:RuntimeOffline
原因
この問題は、通常、無効な dockerd 構成、プロセス負荷の高さ、またはノード負荷の高さによって引き起こされます。
症状
dockerd のステータスが inactive になります。
dockerd のステータスが active (running) であっても、サービスが応答しなくなり、ノード例外を引き起こします。たとえば、
docker psやdocker execなどのコマンドが失敗します。ノードの RuntimeOffline 条件が True になります。
クラスターでノード例外のアラートを設定している場合、dockerd 例外が発生するとアラートが通知されます。アラートの設定方法の詳細については、「アラート管理」をご参照ください。
ソリューション
次のコマンドを実行して dockerd を再起動します。
systemctl restart dockerdockerd を再起動後、ノードにログインして、次のコマンドを実行して dockerd ステータスを確認します。
systemctl status dockerステータスが依然として異常な場合は、ノードにログインして、次のコマンドを実行して dockerd ログを確認します。
journalctl -u docker
containerd 例外のトラブルシューティング:RuntimeOffline
原因
この問題は、通常、無効な containerd 構成、プロセス負荷の高さ、またはノード負荷の高さによって引き起こされます。
containerd のステータスが inactive になります。
ノードの RuntimeOffline 条件が True になります。
クラスターでノード例外のアラートを設定している場合、containerd 例外が発生するとアラートが通知されます。詳細については、「ACK アラート管理」をご参照ください。
ソリューション
次のコマンドを実行して containerd を再起動します。
systemctl restart containerdノードにログインして、次のコマンドを実行して containerd のステータスを確認します。
systemctl status containerdステータスが依然として異常な場合は、ノードにログインして、次のコマンドを実行して containerd ログを表示します。
journalctl -u containerd
NTP 問題のトラブルシューティング - NTPProblem
原因
この問題は、通常、NTP プロセスの異常状態によって引き起こされます。
症状
chronyd のステータスが inactive になります。
ノードの NTPProblem 条件が True になります。
クラスターでノード例外のアラートを設定している場合、ノードの時刻サービスに障害が発生するとアラートが通知されます。アラートの設定方法の詳細については、「ACK アラート管理」をご参照ください。
ソリューション
次のコマンドを実行して chronyd を再起動します。
systemctl restart chronydchronyd を再起動後、ノードにログインして、次のコマンドを実行して chronyd ステータスを確認します。
systemctl status chronyd再起動後も chronyd ステータスが依然として異常な場合は、ノードにログインして、次のコマンドを実行して chronyd ログを確認します。
journalctl -u chronyd
「PLEG is not healthy」エラー
原因
Pod Lifecycle Event Generator (PLEG) は、コンテナの起動や終了など、Pod のライフサイクル全体にわたるイベントを記録します。PLEG is not healthy エラーは、通常、ノード上のコンテナランタイムが応答していないか、ノードの systemd バージョンに既知の問題があることを示します。
症状
ノードステータスが NotReady になります。
kubelet ログに次のメッセージが含まれます。
I0729 11:20:59.245243 9575 kubelet.go:1823] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m57.138893648s ago; threshold is 3m0s.クラスターでノード例外のアラートを設定している場合、PLEG 例外のアラートが通知されます。アラートの設定方法の詳細については、「ACK アラート管理」をご参照ください。
ソリューション
ノード上の主要コンポーネントを次の順序で再起動します:dockerd または containerd、その後 kubelet。コンポーネントを再起動した後、ノードステータスが正常に戻ったかどうかを確認します。
コンポーネントを再起動しても問題が解決しない場合は、影響を受けたノードインスタンスを再起動します。詳細については、「インスタンスの再起動」をご参照ください。
警告ノードを再起動すると、ワークロードが中断される可能性があります。慎重に操作してください。
影響を受けたノードが CentOS 7.6 を実行している場合は、「CentOS 7.6 での「PLEG is not healthy」エラーのトラブルシューティング」をご参照ください。
スケジューリングに必要なノードリソースが不足
原因
この問題は、通常、クラスター内のノードに十分なリソースがない場合に発生します。
症状
クラスターノードのリソースが不足している場合、Pod のスケジューリングが失敗し、次の一般的なエラーメッセージが表示されることがあります。
CPU リソースが不足: 0/2 nodes are available: 2 Insufficient cpu
メモリリソースが不足しています: 0/2 ノードが利用可能: 2 件のメモリ不足
一時ストレージが不足しています: 0/2 ノードが利用可能: 2 一時ストレージが不足しています
スケジューラは、ノードに十分なリソースがあるかどうかを判断するために、次の計算を使用します。
CPU 不足: Pod CPU リクエスト > (ノード割り当て可能 CPU - ノード割り当て済み CPU)
メモリ不足: Pod メモリリクエスト > (ノード割り当て可能メモリ - ノード割り当て済みメモリ)
一時ストレージ不足: Pod 一時ストレージリクエスト > (ノード割り当て可能一時ストレージ - ノード割り当て済み一時ストレージ)
Pod のリソースリクエストがノードの利用可能リソース(割り当て可能 - 割り当て済み)を超える場合、その Pod はそのノードにスケジュールされません。
ノードのリソース割り当ての詳細を表示するには、次のコマンドを実行します。
kubectl describe node [$nodeName]出力の次のセクションに注目してください。
Allocatable:
cpu: 3900m
ephemeral-storage: 114022843818
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 12601Mi
pods: 60
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 725m (18%) 6600m (169%)
memory 977Mi (7%) 16640Mi (132%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)ここで:
Allocatable: Pod に利用可能な、CPU、メモリ、一時ストレージなどのノード上の総リソース。
Allocated resources: ノード上で実行中のすべての Pod がリクエストしたリソースの合計。
ソリューション
スケジューリングに必要なリソース不足を解消するには、ノードの負荷を軽減してください。
不要な Pod を削除するか、その数を減らしてノードの負荷を下げます。詳細については、「Pod の管理」をご参照ください。
ワークロードに基づいて、Pod のリソースリクエストと制限を調整します。詳細については、「コンテナの CPU およびメモリリソース制限の設定」をご参照ください。
クラスターに新しいノードを追加します。詳細については、「ノードプールの作成と管理」をご参照ください。
ノードスペックをアップグレードします。詳細については、「ノードリソースのリサイズ」をご参照ください。
詳細については、「CPU リソースが不足」、「メモリリソースが不足 - MemoryPressure」、「ディスク領域が不足 - DiskPressure」をご参照ください。
ノード CPU 不足
原因
この問題は、通常、ノード上のコンテナが過剰な CPU を消費している場合に発生します。
症状
ノード CPU が不足すると、ノードが不安定になる可能性があります。
クラスターでノード例外のアラートを設定している場合、ノードの CPU 使用率が 85 % 以上になるとアラートが通知されます。アラートの設定方法の詳細については、「ACK アラート管理」をご参照ください。
ソリューション
ノードのモニタリングデータの CPU 使用率トレンドを確認して、例外が発生したタイミングを特定し、ノード上のプロセスが過剰な CPU を消費していないかを確認します。詳細については、「ノードモニタリングデータの確認」をご参照ください。
ノードの負荷を軽減します。詳細については、「スケジューリングに必要なノードリソースが不足」をご参照ください。
必要に応じて、影響を受けたノードを再起動します。詳細については、「インスタンスの再起動」をご参照ください。
警告ノードを再起動すると、サービスが中断される可能性があります。慎重に操作してください。
メモリ不足:MemoryPressure
原因
この問題は、通常、ノード上のコンテナが過剰なメモリを使用している場合に発生します。
症状
ノードの使用可能なメモリが
memory.availableしきい値を下回ると、MemoryPressure 条件が True に設定され、システムがノードからコンテナをエビクトします。このプロセスの詳細については、Node-pressure Eviction をご参照ください。ノードのメモリが不足している場合、次の現象が観察されることがあります。
ノードの MemoryPressure 条件が True になります。
ノード上のコンテナがエビクトされた場合:
エビクトされたコンテナのイベントに、The node was low on resource: memory というメッセージが表示されます。
ノードイベントに、attempting to reclaim memory というメッセージが表示されます。
ノードで System OOM イベントが発生する可能性があります。この場合、ノードイベントに System OOM というメッセージが含まれます。
クラスターでアラートを設定している場合、ノードのメモリ使用率が 85 % 以上になるとアラートが通知されます。アラートの設定方法の詳細については、「ACK アラート管理」をご参照ください。
ソリューション
ノードのモニタリングデータのメモリ使用率トレンドを確認して、問題が発生したタイミングを特定します。ノード上のプロセスにメモリリークがないかを確認します。詳細については、「ノードモニタリングデータの確認」をご参照ください。
ノードの負荷を軽減します。詳細については、「スケジューリングに必要なノードリソースが不足」をご参照ください。
必要に応じて、影響を受けたノードを再起動します。詳細については、「インスタンスの再起動」をご参照ください。
警告ノードを再起動すると、ワークロードが中断される可能性があります。慎重に操作してください。
ノード inode 不足 - InodesPressure
原因
この問題は、通常、ノード上のコンテナが過剰な数の inode を消費している場合に発生します。
症状
ノード上の使用可能な inode 数が
inodesFreeパラメーターの値を下回ると、InodesPressure ノード条件が True になり、ノードがコンテナをエビクトします。詳細については、Node-pressure eviction をご参照ください。ノードの inode が不足している場合、次の現象が観察されることがあります。
InodesPressure ノード条件が True になります。
ノードがコンテナをエビクトした場合:
エビクトされたコンテナのイベントに、The node was low on resource: inodes というメッセージが表示されます。
ノードイベントに、attempting to reclaim inodes というメッセージが表示されます。
クラスターでアラートを設定している場合、ノードの inode が不足するとアラートが通知されます。アラートの設定方法については、「アラート管理」をご参照ください。
ソリューション
ノードのモニタリングデータの inode 使用率トレンドを確認して、問題が発生し始めたタイミングを特定します。ノード上のプロセスが過剰な数の inode を消費していないかを確認します。詳細については、「ノードモニタリングデータの確認」をご参照ください。
追加のトラブルシューティングについては、「Linux インスタンスのディスク領域不足問題のトラブルシューティング」をご参照ください。
ノード PID 不足 - NodePIDPressure
原因
この問題は、通常、ノード上のコンテナが過剰な PID を消費している場合に発生します。
症状
ノード上の使用可能な PID 数が
pid.availableしきい値を下回ると、NodePIDPressure 条件が True に設定され、kubelet がノードからコンテナをエビクトします。ノードエビクションの詳細については、Node-pressure Eviction をご参照ください。クラスターノード例外のアラートを設定している場合、ノードが NodePIDPressure 状態になるとアラートが通知されます。アラートの設定方法の詳細については、「ACK アラート管理」をご参照ください。
ソリューション
次のコマンドを実行して、ノードの最大 PID 制限と使用中の最高 PID を確認します。
sysctl kernel.pid_max # 最大 PID 制限を確認します。 ps -eLf|awk '{print $2}' | sort -rn| head -n 1 # 使用中の最高 PID を確認します。次のコマンドを実行して、スレッド数が最も多い上位 5 つのプロセスを特定します。
ps -elT | awk '{print $4}' | sort | uniq -c | sort -k1 -g | tail -5期待される出力:
# 1 列目はスレッド数、2 列目はプロセス ID を示します。 73 9743 75 9316 76 2812 77 5726 93 5691プロセス ID を使用してプロセスと対応する Pod を特定します。これらのプロセスが過剰な PID を使用している理由を分析し、アプリケーションを最適化してください。
ノードの負荷を軽減します。詳細については、「スケジューリングに必要なノードリソースが不足」をご参照ください。
必要に応じて、影響を受けたノードを再起動します。詳細については、「インスタンスの再起動」をご参照ください。
警告ノードを再起動すると、サービスが中断される可能性があります。慎重に操作してください。
ノードディスク領域不足 - DiskPressure
原因
この問題は、通常、ノード上のコンテナまたは大きなイメージが過剰なディスク領域を消費している場合に発生します。
症状
ノードの使用可能なディスク領域が
imagefs.availableしきい値を下回ると、DiskPressure 条件が True に設定されます。ノードのルートファイルシステムの使用可能なディスク領域が
nodefs.availableしきい値を下回ると、ノード上の Pod がエビクトされます。ノード圧力によるエビクションの詳細については、Node-pressure Eviction をご参照ください。ノードのディスク領域が不足している場合、次の現象が観察されることがあります。
ノードの DiskPressure 条件が True になります。
イメージ回収ポリシーがトリガーされた後も、使用可能なディスク領域が正常性しきい値(デフォルトで 80 %)を満たさない場合、ノードイベントに failed to garbage collect required amount of images というメッセージが含まれます。
ノード上の Pod がエビクトされた場合:
エビクトされた Pod のイベントに、The node was low on resource: [DiskPressure] というメッセージが含まれます。
ノードイベントに、attempting to reclaim ephemeral-storage または attempting to reclaim nodefs などのメッセージが含まれます。
クラスターでアラート機能を設定している場合、ノードのディスク使用率が 85 % 以上になるとアラートが通知されます。アラートの設定方法の詳細については、「ACK アラート管理」をご参照ください。
ソリューション
ノードのモニタリングデータのディスク使用率トレンドを確認して、例外が発生したタイミングを特定し、ノード上のプロセスが過剰なディスク領域を消費していないかを確認します。詳細については、「ノードモニタリングデータの確認」をご参照ください。
ディスクから不要なファイルを削除します。詳細については、「Linux での「no space left」問題の解決」をご参照ください。
ワークロードに基づいて、Pod の
ephemeral-storageリソースを制限します。詳細については、「コンテナの CPU およびメモリ制限の設定」をご参照ください。Alibaba Cloud ストレージ製品を使用し、hostPath ボリュームの使用は可能な限り避けてください。詳細については、「ストレージ」をご参照ください。
ノードのディスクサイズを増やします。
ノードの負荷を軽減します。詳細については、「スケジューリングに必要なノードリソースが不足」をご参照ください。
IP アドレス不足:InvalidVSwitchId.IpNotEnough
原因
この問題は、ノード上のコンテナが多すぎて、利用可能な IP アドレスをすべて使用してしまう場合に発生します。
症状
Pod が起動できず、ContainerCreating 状態のままになります。Pod ログに InvalidVSwitchId.IpNotEnough キーワードを含むエラーメッセージが表示されます。Pod ログの確認方法については、「Pod のトラブルシューティング」をご参照ください。
time="2020-03-17T07:03:40Z" level=warning msg="Assign private ip address failed: Aliyun API Error: RequestId: 2095E971-E473-4BA0-853F-0C41CF52651D Status Code: 403 Code: InvalidVSwitchId.IpNotEnough Message: The specified VSwitch \"vsw-AAA\" has not enough IpAddress., retrying"クラスターノードのアラート機能を有効にしている場合、ノードの IP アドレスが不足するとアラートが通知されます。アラートの設定方法については、「ACK アラート管理」をご参照ください。
ソリューション
ノード上のコンテナ数を減らしてください。手順については、「スケジューリングに必要なノードリソースが不足」をご参照ください。詳細については、「Terway を使用するクラスターで VSwitch が提供する IP アドレスが不足している場合の対処方法」および「Terway ネットワークモードでの Pod IP 割り当て失敗」をご参照ください。
ノードネットワーク例外
原因
一般的な原因には、ノードステータスの異常、セキュリティグループの誤った構成、ネットワーク負荷の高さなどがあります。
症状
ノードにログインできません。
ノード条件が Unknown になります。
ノード例外のアラートを設定している場合、ノードのアウトバウンドインターネット帯域幅使用量が 85 % 以上になるとアラートがトリガーされます。アラートの設定方法の詳細については、「ACK アラート管理」をご参照ください。
ソリューション
ノードにログインできない場合は、次の手順で問題をトラブルシューティングしてください。
ノードインスタンスが 実行中 であることを確認します。
ノードのセキュリティグループ構成を確認します。詳細については、「ノードセキュリティグループの確認」をご参照ください。
ノードのネットワーク負荷が高い場合は、次の手順で問題をトラブルシューティングしてください。
モニタリングデータのノードネットワーク使用率トレンドを確認して、過剰なネットワーク帯域幅を消費している Pod を特定します。詳細については、「ノードモニタリングデータの確認」をご参照ください。
ネットワークポリシーを使用して Pod トラフィックを制御します。詳細については、「ACK クラスターでのネットワークポリシーの使用」をご参照ください。
予期しないノード再起動
原因
この問題は、通常、ノードが過負荷になっている場合に発生します。
症状
再起動中、ノードステータスが NotReady になります。
クラスターでノード例外のアラートを設定している場合、ノードが予期せず再起動するとアラートが通知されます。詳細については、「ACK アラート管理」をご参照ください。
ソリューション
次のコマンドを実行して、ノードが再起動したタイミングを確認します。
last reboot期待される出力:

ノードのモニタリングデータを確認し、再起動時間に基づいてリソースの異常をトラブルシューティングします。詳細については、「ノードモニタリングデータの確認」をご参照ください。
ノードのカーネルログを確認し、再起動時間付近に記録された例外をトラブルシューティングします。詳細については、「ノード診断ログの収集」をご参照ください。
auditd:ディスク I/O 高負荷およびバックログエラーの解決
原因
デフォルトでは、クラスター内の一部の既存ノードに Docker の auditd ルールが設定されています。これらのノードが Docker コンテナランタイムを使用している場合、これらのルールにより、Docker 操作の監査ログがシステムに記録されます。まれに、大量のコンテナ再起動、コンテナ内での集中したファイル I/O、またはカーネルのバグなどの状況で、システムが大量の監査ログを生成することがあります。これにより、auditd プロセスのディスク I/O が高くなったり、システムログに audit: backlog limit exceeded エラーが表示されたりする可能性があります。
症状
この問題は、Docker コンテナランタイムを使用するノードにのみ影響します。影響を受けたノードでは、次の症状が観察されることがあります。
iotop -o -d 1 コマンドを実行すると、出力に auditd プロセスの
DISK WRITE値が 1 MB/s 以上で継続的に表示されます。dmesg -d コマンドを実行すると、出力に
audit_printk_skbキーワードを含むログ(例:audit_printk_skb: 100 callbacks suppressed)が含まれます。dmesg -d コマンドを実行すると、出力に
audit: backlog limit exceededというメッセージが含まれます。
ソリューション
ノードの auditd 構成が問題の原因となっているかどうかを確認するには、次の手順を実行します。
影響を受けたノードにログインします。
次のコマンドを実行して auditd ルールを確認します。
sudo auditctl -l | grep -- ' -k docker'出力に次の行が含まれている場合、auditd 構成が問題の原因です。
-w /var/lib/docker -k docker
原因が確認された場合は、次のいずれかのソリューションを選択してください。
クラスターバージョンをアップグレードする
クラスターをアップグレードすると、この問題が解消されます。詳細については、「クラスターの手動アップグレード」をご参照ください。
containerd コンテナランタイムを使用する
アップグレードできないクラスターでは、Docker の代わりに containerd をコンテナランタイムとして使用することで、この問題を回避できます。Docker コンテナランタイムを使用する各ノードプールに対して、次の手順を実行します。
ソースノードプールを複製して、containerd をコンテナランタイムとして使用する新しいノードプールを作成します。新しいノードプールの他のすべての構成が、ソースノードプールと同一であることを確認します。
オフピーク時間帯に、ソースノードプールのノードを 1 台ずつドレインします。ノードプールにアプリケーション Pod がデプロイされていないことを確認します。
ノードの auditd 構成を更新する
クラスターをアップグレードできない場合や containerd コンテナランタイムに切り替えることができない場合は、auditd 構成を手動で更新することで、この問題を回避できます。Docker コンテナランタイムを使用する各ノードで、次の手順を実行します。
影響を受けたノードにログインします。
次のコマンドを実行して、Docker 関連の auditd ルールを削除します。
sudo test -f /etc/audit/rules.d/audit.rules && sudo sed -i.bak '/ -k docker/d' /etc/audit/rules.d/audit.rules sudo test -f /etc/audit/audit.rules && sudo sed -i.bak '/ -k docker/d' /etc/audit/audit.rules次のコマンドを実行して、新しい auditd ルールを適用します。
if service auditd status |grep running || systemctl status auditd |grep running; then sudo service auditd restart || sudo systemctl restart auditd sudo service auditd status || sudo systemctl status auditd fi