診断チェックと AI 支援による根本原因分析で、ノードの問題を特定し、解決します。
ノード診断が実行されると、ACK は各ノードからシステムバージョン、Workload、Docker、kubelet のステータス、およびシステムログの主要なエラーを収集します。ビジネスデータや機密情報は収集されません。
ノード診断は次の 2 つのコンポーネントで構成されています:
-
[診断項目]:ノード、ノードコンポーネント、クラスターコンポーネント、Elastic Compute Service (ECS) controller manager、および GPU 高速化ノードを診断します。
-
[根本原因]:クラスターとノードのデータを収集し、異常を特定し、詳細な分析を行うことで、根本原因を特定して修正案を提案します。
仕組み
診断結果は、4 つのステージを経て生成されます:
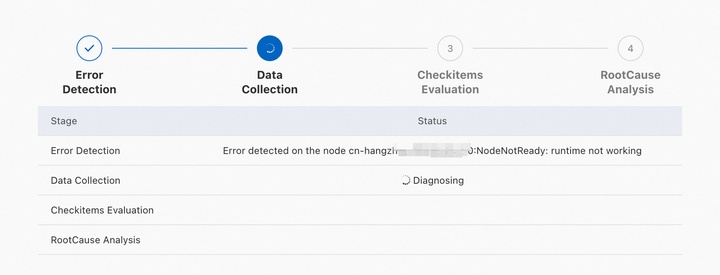
-
[異常の特定]:基本シグナル (ノードのステータス、Pod のステータス、クラスターイベントストリーム) を収集し、異常を特定します。
-
[データ収集]:特定された異常に基づいて、Kubernetes ノード情報、ECS インスタンスの詳細、Docker/kubelet のプロセスのステータスなど、コンテキスト固有のデータを収集します。
-
[診断項目のチェック]:主要なメトリクスが正常範囲内にあるかどうかを確認します。項目はカテゴリ別にグループ化され、それぞれに説明が付いています。
-
[根本原因分析]:収集したデータとチェック結果に基づいて、問題の根本原因を特定します。
診断結果
結果は次の2つのタイプに分かれます。
-
[根本原因分析結果]:検出された異常、特定された根本原因、および修正案が含まれます。
-
[診断項目のチェック結果]:項目ごとのチェック結果が含まれます。これらは、根本原因分析では見逃されがちな原因の特定に役立ちます。
診断項目はクラスター設定によって異なり、実際のクラスター構成を反映します。
ユースケース
ノード診断と AI 支援診断は、これらのシナリオに対応しています。
| カテゴリ | シナリオ |
|---|---|
| ノード診断 | Node NotReady — ネットワーク未準備、プロセス ID (PID) の不足、メモリ不足、ディスク領域不足、ランタイム例外、またはハートビートの未検出 |
| inode クォータ不足 | |
| PID クォータ不足 | |
| 不正確なノード時刻 | |
| 読み取り専用のノードファイルシステム | |
| ノードカーネルのデッドロック | |
| AI 支援診断 | ノードステータスの異常 |
| ECS インスタンスステータスの異常 | |
| ノードにおける kubelet エラー | |
| ノードにおけるランタイム例外 | |
| ディスク領域不足 | |
| ノードの高い CPU 使用率 |
診断項目
| カテゴリー | チェック内容 |
|---|---|
| ノード | ノードステータス、ネットワークステータス、カーネルログ、カーネルプロセス、サービス可用性 |
| NodeComponent | ネットワークおよびストレージコンポーネントなど、主要なノードコンポーネントのステータス |
| ClusterComponent | API サーバーの可用性、DNS 可用性、NAT ゲートウェイステータス |
| ECSControllerManager | ECS インスタンスステータス、ネットワーク接続、オペレーティングシステムのヘルス、ディスク I/O |
| GPUNode | GPU アクセラレーションノードにおける NVIDIA モジュールステータスとコンテナランタイムの構成 |
ノード
提案された修正を適用しても問題が解決しない場合は、ノードのログを収集し、チケットを送信してください。
| 診断項目 | 検出内容 | 修正方法 |
|---|---|---|
| Kubernetes API サーバーへの接続エラー | ノードがクラスターの API サーバーに到達できるかどうか。接続できない場合、ノードはワークロードの割り当てを受信できなくなります。 | クラスター設定を確認してください。詳細については、「ACK クラスターのトラブルシューティング」をご参照ください。 |
| AUFS マウントのハング | ノードで AUFS マウントのハングが発生しているかどうか。 | チケットを送信してください。 |
| BufferIOError | ノードカーネルに BufferIOError が存在するかどうか。 | チケットを送信してください。 |
| cgroup リーク | cgroup リークが発生しているかどうか。cgroup リークは、監視データの収集を妨げ、コンテナの起動失敗の原因となる可能性があります。 | ノードにログオンし、該当する cgroup ディレクトリを削除してください。 |
| chronyd プロセスの異常なステータス | chronyd プロセスが正常に実行されているかどうか。chronyd プロセスが異常な場合、クロック同期が中断され、時間に依存する操作に影響を及ぼします。 | systemctl restart chronyd を実行してプロセスを再起動してください。 |
| containerd によるイメージのプル | containerd ランタイムが期待どおりにイメージをプルできるかどうか。 | ノードのネットワーク設定とイメージ設定を確認してください。 |
| containerd のステータス | containerd ランタイムが実行されているかどうか。 | チケットを送信してください。 |
| CoreDNS Pod の可用性 | ノードが CoreDNS Pod の IP アドレスに到達できるかどうか。CoreDNS Pod に到達できない場合、このノード上のワークロードで DNS 名前解決の失敗が発生します。 | ノードが CoreDNS Pod の IP アドレスにアクセスできるかどうかを確認してください。詳細については、「CoreDNS Pod 間で DNS クエリの負荷が分散されない場合はどうすればよいですか?」をご参照ください。 |
| イメージのステータス | イメージが破損しているかどうか。イメージが破損していると、コンテナが起動できません。 | チケットを送信してください。 |
| イメージの overlay2 ステータス | イメージ内の overlay2 ファイルシステムが破損しているかどうか。 | チケットを送信してください。 |
| システム時刻 | システムクロックが正確かどうか。 | なし。 |
| Docker コンテナの起動 | Docker コンテナの起動に失敗しているかどうか。 | チケットを送信してください。 |
| Docker イメージのプル | ノードが期待どおりに Docker イメージをプルできるかどうか。 | ノードのネットワーク設定とイメージ設定を確認してください。 |
| Docker のステータス | Docker ランタイムが実行されているかどうか。 | チケットを送信してください。 |
| Docker の起動時間 | Dockerd の起動時間。 | なし。 |
| Docker ハングエラー | ノードで Docker ハングエラーが発生しているかどうか。Docker がハングすると、コンテナが応答しなくなる可能性があります。 | systemctl restart docker を実行して Docker を再起動してください。 |
| ECS インスタンスの存在 | 基盤となる ECS インスタンスが存在するかどうか。 | ECS インスタンスのステータスを確認してください。詳細については、「ノードとノードプールに関する FAQ」をご参照ください。 |
| ECS インスタンスのステータス | ECS インスタンスが正常な状態であるかどうか。 | ECS インスタンスのステータスを確認してください。詳細については、「ノードとノードプールに関する FAQ」をご参照ください。 |
| Ext4FsError | ノードカーネルに Ext4FsError が存在するかどうか。 | チケットを送信してください。 |
| 読み取り専用のノードファイルシステム | ノードのファイルシステムが読み取り専用になっているかどうか。これは通常、ディスク障害を示します。この状態では、すべての書き込み操作がブロックされ、ワークロードに影響が出ます。 | fsck を実行してファイルシステムを修復し、ノードを再起動してください。 |
| ハードウェア時刻 | ハードウェアクロックとシステムクロックが同期しているかどうか。2 分を超える差があると、コンポーネントエラーが発生する可能性があります。 | hwclock --systohc を実行して、システム時刻をハードウェアクロックに同期させてください。 |
| DNS | ノード上でドメイン名を解決できるかどうか。 | 詳細については、「DNS のトラブルシューティング」をご参照ください。 |
| カーネル oops | ノードカーネルに oops が存在するかどうか。これは予期しないコードパスを示しており、不安定性の原因となる可能性があります。 | チケットを送信してください。 |
| カーネルのバージョン | カーネルのバージョンが古いかどうか。古いカーネルには、既知の安定性の問題がある場合があります。 | ノードのカーネルを更新してください。詳細については、「ノードとノードプールに関する FAQ」をご参照ください。 |
| DNS の可用性 | ノードが kube-dns Service のクラスター IP に到達して、クラスターの DNS サービスを使用できるかどうか。 | CoreDNS Pod のステータスとログを確認してください。詳細については、「DNS のトラブルシューティング」をご参照ください。 |
| Kubelet のステータス | kubelet が正常に実行されているかどうか。kubelet に障害が発生すると、ノードは Pod を管理できなくなります。 | kubelet のログを確認してください。詳細については、「ACK クラスターのトラブルシューティング」をご参照ください。 |
| Kubelet の起動時間 | kubelet の起動時間。 | なし。 |
| CPU 使用率 | ノードの CPU 使用率が過度に高いかどうか。 | なし。 |
| メモリ使用率 | ノードのメモリ使用率が過度に高いかどうか。 | なし。 |
| メモリの断片化 | ノードにメモリの断片化が存在するかどうか。断片化は連続したメモリ領域を減少させ、ワークロードのパフォーマンスを低下させる可能性があります。 | ノードにログオンし、 echo 3 \> /proc/sys/vm/drop_caches を実行してキャッシュをドロップしてください。 |
| スワップメモリ | スワップメモリが有効になっているかどうか。Kubernetes ではスワップを無効にする必要があります。有効にすると、kubelet が予期しない動作をする可能性があります。 | ノードにログオンし、スワップメモリを無効にしてください。 |
| ネットワークデバイスドライバーの読み込み | ネットワークデバイス上の VirtIO ドライバーが正しくロードされているかどうか。 | チケットを送信してください。 |
| ノードの過度に高い CPU 使用率 | 過去 1 週間で CPU 使用率が高かったかどうか。CPU 使用率が常に高いノードに多くの Pod がスケジュールされている場合、リソースの競合によってサービスが中断される可能性があります。 | ノードの過負荷を避けるために、リソース要求とリソース上限を適切に設定してください。 |
| ノードのプライベート IP の存在 | ノードにプライベート IP アドレスが割り当てられているかどうか。プライベート IP がないと、ノードはクラスター内で通信できません。 | ノードをクラスターから削除し、再度追加してください。削除時に ECS インスタンスを解放しないでください。詳細については、「ノードの削除」および「既存の ECS インスタンスの追加」をご参照ください。 |
| ノードの過度に高いメモリ使用率 | 過去 1 週間でメモリ使用率が高かったかどうか。高いメモリ使用率と大量の Pod スケジューリングが組み合わさると、メモリ不足 (OOM) エラーやサービスの中断につながる可能性があります。 | ノードの過負荷を避けるために、リソース要求とリソース上限を適切に設定してください。 |
| ノードのステータス | ノードが Ready 状態であるかどうか。 | ノードを再起動してください。詳細については、「ノードとノードプールに関する FAQ」をご参照ください。 |
| ノードのスケジューリング可否 | ノードがスケジュール不可とマークされているかどうか。スケジュール不可のノードは、新しい Pod の割り当てを受け取りません。 | ノードのスケジューリング設定を確認してください。詳細については、「ノードのドレインとスケジューリングステータス」をご参照ください。 |
| OOM エラー | ノードでメモリ不足 (OOM) エラーが発生しているかどうか。OOM エラーにより、Pod やシステムプロセスが強制終了される可能性があります。 | チケットを送信してください。 |
| ランタイムチェック | ノードのコンテナランタイムがクラスターの設定済みランタイムと一致するかどうか。不一致があると、Pod の起動に失敗する可能性があります。 | 詳細については、「クラスターのコンテナランタイムを containerd から Docker に変更できますか?」をご参照ください。 |
| 古い OS バージョン | ノードの OS バージョンに既知のバグや安定性の問題があるかどうか。古い OS バージョンは、Docker および containerd ランタイムの誤動作の原因となる可能性があります。 | OS のバージョンを更新してください。 |
| インターネットアクセス | ノードがインターネットに到達できるかどうか。 | クラスターで SNAT が有効になっているかどうかを確認してください。詳細については、「既存の ACK クラスターがインターネットにアクセスできるようにする」をご参照ください。 |
| RCUStallError | ノードカーネルに RCUStallError が存在するかどうか。このエラーは、CPU コアが read-copy-update (RCU) クリティカルセクションでスタックしていることを示し、ノードがハングする原因となる可能性があります。 | チケットを送信してください。 |
| OS バージョン | ノードで使用されている OS のバージョン。古い OS バージョンは、クラスターが正常に動作しなくなる原因となる可能性があります。 | なし。 |
| runc プロセスリーク | runc プロセスリークが発生しているかどうか。runc プロセスリークにより、ノードが定期的に NotReady 状態になる可能性があります。 | リークした runc プロセスを特定し、手動で終了させてください。 |
| SoftLockupError | ノードカーネルに SoftLockupError が存在するかどうか。これは、CPU コアが割り込みに応答していないことを示し、ノードが不安定になる原因となる可能性があります。 | チケットを送信してください。 |
| systemd ハング | systemd ハングが発生しているかどうか。systemd がハングすると、サービスの開始または停止ができなくなり、ノードの安定性に影響を与えます。 | ノードにログオンし、 systemctl daemon-reexec を実行して systemd を再起動してください。 |
| 古い systemd バージョン | systemd のバージョンに既知のバグがあるかどうか。古いバージョンは、Docker と containerd の誤動作の原因となる可能性があります。 | systemd のバージョンを更新してください。詳細については、「systemd」をご参照ください。 |
| ハングしたプロセス | ノードにハングしたプロセスが存在するかどうか。ハングしたプロセスは、処理が進まないままリソースを消費し、ノードのパフォーマンスを低下させます。 | チケットを送信してください。 |
| unregister_netdevice エラー | ノードカーネルに unregister_netdevice エラーが存在するかどうか。これは、カーネルリソースリークやネットワークが不安定になる原因となる可能性があります。 | チケットを送信してください。 |
NodeComponent
| 診断項目 | 検出内容 | 対処法 |
|---|---|---|
| CNI コンポーネントの状態 | Container Network Interface (CNI) プラグインが期待どおりに実行されているかどうかを検出します。 CNI プラグインに障害が発生すると、ノード上の Pod のネットワーキングが停止します。 | クラスターのネットワークコンポーネントの状態を確認してください。詳細については、「ネットワーク管理に関するよくある質問」をご参照ください。 |
| CSI コンポーネントの状態 | Container Storage Interface (CSI) プラグインが期待どおりに実行されているかどうかを検出します。 CSI プラグインに障害が発生すると、Pod はボリュームをマウントできなくなります。 | クラスターのストレージコンポーネントの状態を確認してください。詳細については、「CSI に関するよくある質問」をご参照ください。 |
ClusterComponent
| 診断項目 | 検出内容 | 対処法 |
|---|---|---|
| aliyun-acr-credential-helper のバージョン | aliyun-acr-credential-helper コンポーネントのバージョンが古いかどうかを確認します。 | aliyun-acr-credential-helper を更新します。詳細については、「aliyun-acr-credential-helper コンポーネントを使用して Secret を使わずにイメージをプルする」をご参照ください。 |
| API Service の可用性 | クラスターの API Service が利用可能かどうかを確認します。API Service が利用できない場合、ワークロード管理操作がブロックされます。 | kubectl get apiservicekubectl describe apiservice を実行して可用性を確認します。利用できない場合は、 を実行して原因を特定します。 |
| 利用可能な Pod の CIDR ブロックの不足 | Flannel クラスターで利用可能な Pod の CIDR ブロックの数が 5 未満であるかどうかを確認します。各ノードには 1 つの Pod CIDR ブロックが必要です。すべてのブロックが使用されると、新しいノードはクラスターに参加できません。 | チケットを送信してください。 |
| CoreDNS エンドポイント | アクティブな CoreDNS エンドポイントの数。エンドポイントが少なすぎると、DNS の可用性が低下します。 | CoreDNS Pod のステータスとログを確認してください。詳細については、「DNS のトラブルシューティング」をご参照ください。 |
| CoreDNS のクラスターIP アドレス | クラスターIP アドレスが CoreDNS Pod に割り当てられているかどうかを確認します。クラスターIP がないと、DNS リクエストは CoreDNS に到達できず、サービス全体の DNS 障害を引き起こします。 | CoreDNS Pod のステータスとログを確認してください。詳細については、「DNS のトラブルシューティング」をご参照ください。 |
| NAT ゲートウェイのステータス | クラスターの NAT ゲートウェイが正常に機能しているかどうかを確認します。NAT ゲートウェイに障害が発生すると、パブリック IP を持たないノードからのアウトバウンドインターネットトラフィックがブロックされます。 | NAT ゲートウェイコンソールにログオンし、料金滞納によりゲートウェイがロックされているかどうかを確認します。 |
| NAT ゲートウェイでの同時接続ドロップ率の異常な高さ | NAT ゲートウェイが異常に高いレートで同時接続をドロップしているかどうかを確認します。高いドロップ率は、ゲートウェイが接続容量に達したことを示します。 | NAT ゲートウェイをアップグレードします。詳細については、「標準インターネット NAT ゲートウェイから拡張インターネット NAT ゲートウェイへのアップグレードに関する FAQ」をご参照ください。 |
ECSControllerManager
| 診断項目 | 検出内容 | 対処法 |
|---|---|---|
| ECS インスタンスのコンポーネントに関連する料金滞納 | インスタンスのディスクまたはネットワーク帯域幅が料金滞納により制限されているかを確認します。リソースが制限されると、ワークロードの障害が発生する可能性があります。 | アカウントに入金してアクセスを復元してください。 |
| ECS インスタンスに関連する料金滞納 | 従量課金の ECS インスタンスが料金滞納により停止されているかを確認します。 | アカウントに入金してから、インスタンスを再起動してください。 |
| ECS インスタンスの NIC ステータス | インスタンスのネットワークインターフェイスカード (NIC) が正常に機能しているかを確認します。NIC が異常な場合、ネットワーク接続が失われます。 | インスタンスを再起動してください。 |
| ECS インスタンスの起動ステータス | インスタンスが正常に起動できるかを確認します。 | 起動に失敗した場合は、新しいインスタンスを作成してください。 |
| ECS インスタンスのバックエンド管理システムのステータス | インスタンスのバックエンド管理システムが正常に動作しているかを確認します。 | インスタンスを再起動してください。 |
| ECS インスタンスの CPU のステータス | インスタンスの基盤レイヤーで CPU 競合または CPU バインディングの障害が発生しているかを確認します。CPU 競合により、インスタンスが CPU リソースを取得できなくなり、パフォーマンスが低下する可能性があります。 | インスタンスを再起動してください。 |
| ECS インスタンスの CPU におけるスプリットロック | ECS インスタンスの CPU でスプリットロックが発生しているかを確認します。スプリットロックは CPU のパフォーマンスを著しく低下させる可能性があります。 | 詳細については、「スプリットロックの検出と処理」をご参照ください。 |
| ECS インスタンスの DDoS 対策のステータス | インスタンスのパブリック IP アドレスが DDoS 攻撃を受けているかを確認します。 | DDoS 対策サービスを購入してください。詳細については、「Alibaba Cloud の DDoS 対策ソリューションの比較」をご参照ください。 |
| クラウドディスクの読み書き機能の制限 | クラウドディスクの読み書きスループットがスロットリングされているかを確認します。スロットリングは、最大 IOPS に達したときに発生し、I/O 操作が遅くなったり、キューに入ったりする原因となります。 | 詳細については、「ブロックストレージのパフォーマンス」をご参照ください。 |
| ECS インスタンスのディスク読み込み | インスタンスの起動時にクラウドディスクをアタッチできるかを確認します。 | インスタンスを停止してから、再度起動してください。 |
| ECS インスタンスの有効期限切れ | サブスクリプションインスタンスの有効期限が切れているかを確認します。有効期限が切れたインスタンスは停止され、そのリソースは利用できなくなります。 | インスタンスを更新してください。詳細については、「サブスクリプションインスタンスの更新」をご参照ください。 |
| ECS インスタンスの OS クラッシュ | 過去 48 時間以内に OS クラッシュが発生したかを確認します。 | システムログを確認して原因を特定してください。詳細については、「システムログとスクリーンショットの表示」をご参照ください。 |
| ECS インスタンスのホストのステータス | インスタンスをホストしている物理サーバーに障害があるかを確認します。ホストに障害があると、インスタンスのパフォーマンスが低下する可能性があります。 | インスタンスを再起動してください。 |
| ECS インスタンスのイメージ読み込み | インスタンスが初期化中にイメージをロードできるかを確認します。 | インスタンスを再起動してください。 |
| ECS インスタンスのディスクでの I/O ハング | システムディスクで I/O ハングが発生しているかを確認します。ディスクの I/O ハングは、オペレーティングシステムが応答しなくなる原因となる可能性があります。 | ディスクのメトリクスを確認してください。詳細については、「クラウドディスクの監視データの表示」をご参照ください。 Alibaba Cloud Linux 2 の場合は、「ファイルシステムとブロックレイヤーの I/O ハングの検出」をご参照ください。 |
| ECS インスタンスの帯域幅上限 | インスタンスの合計帯域幅がそのインスタンスタイプの最大値に達しているかを確認します。上限に達すると、ネットワークスループットが制限され、パケットがドロップされる可能性があります。 | より高い帯域幅を持つインスタンスタイプにアップグレードしてください。詳細については、「インスタンス設定変更の概要」をご参照ください。 |
| ECS インスタンスのバースト帯域幅の上限 | インスタンスのバースト帯域幅が、そのインスタンスタイプで許可されている最大値を超えているかを確認します。 | より高い帯域幅を持つインスタンスタイプにアップグレードしてください。詳細については、「インスタンス設定変更の概要」をご参照ください。 |
| ECS インスタンスの NIC 読み込み | インスタンスで NIC を読み込めるかを確認します。NIC の読み込みに失敗すると、インスタンスはネットワーク接続を失います。 | インスタンスを再起動してください。 |
| ECS インスタンスでの NIC セッションの確立 | NIC へのセッションを確立できるかを確認します。NIC がセッションを確立できない場合、またはセッションの上限に達した場合、ネットワーク接続またはスループットに影響が出ます。 | インスタンスを再起動してください。 |
| ECS インスタンスでの主要な操作 | インスタンスに対する最近の操作 (起動、停止、アップグレードなど) が正常に完了したかを確認します。 | 失敗した操作を再試行してください。 |
| ECS インスタンスの NIC でのパケット損失 | NIC でインバウンドまたはアウトバウンドのパケット損失が発生しているかを確認します。パケット損失はネットワークエラーを引き起こし、サービスを中断させる可能性があります。 | インスタンスを再起動してください。 |
| ECS インスタンスのパフォーマンス低下 | ソフトウェアまたはハードウェアの問題により、インスタンスのパフォーマンスが一時的に低下したかを確認します。 | インスタンスの履歴イベントまたはシステムログを表示して原因を特定してください。詳細については、「履歴システムイベントの表示」をご参照ください。 |
| ECS インスタンスのパフォーマンス低下 (CPU クレジット枯渇) | インスタンスのパフォーマンスが低下しているかを確認します。CPU クレジットが不足すると、バーストパフォーマンスインスタンスはベースラインパフォーマンスにフォールバックします。 | 利用可能な CPU クレジットが不足しているため、ECS インスタンスはベースラインパフォーマンスしか提供できません。 |
| ECS インスタンスのディスクのサイズ変更 | ディスクのサイズは変更されたものの、OS がまだファイルシステムを拡張していないかを確認します。ファイルシステムのサイズが変更されるまで、追加のディスク領域は利用できません。 | ディスクのサイズ変更後、OS は自動的にファイルシステムのサイズを変更しません。ディスクが使用できないままである場合は、再度サイズ変更を行ってください。 |
| ECS インスタンスのリソース可用性 | インスタンスに十分な物理 CPU およびメモリリソースが利用可能かを確認します。リソースが不足している場合、インスタンスは起動できません。 | 数分待ってから、インスタンスの起動を再試行してください。問題が解決しない場合は、別のリージョンにインスタンスを作成してください。 |
| ECS インスタンスの OS ステータス | インスタンスの OS でカーネルパニック、OOM エラー、または内部障害が発生したかを確認します。これらは、設定の誤りやユーザープログラムが原因で発生することがよくあります。 | インスタンスを再起動してください。 |
| ECS インスタンスの仮想化ステータス | 基盤となる仮想化レイヤーで例外が発生しているかを確認します。これらは、インスタンスが応答を停止したり、予期せず中断されたりする原因となる可能性があります。 | インスタンスを再起動してください。 |
GPU ノード
| 診断項目 | 検出内容 | 対処法 |
|---|---|---|
| コンテナランタイム | GPU アクセラレーテッドノード上のコンテナランタイムが有効かどうか。ACK は、GPU アクセラレーテッドノードでは Docker と containerd のみをサポートしています。 | ノード上の Docker または containerd ランタイムの状態を確認してください。 |
| NVIDIA-Container-Runtime のバージョン | NVIDIA-Container-Runtime のバージョンがクラスターと互換性があるかどうか。互換性がない、または存在しない場合、GPU コンテナは起動しません。 | 1. NVIDIA-Container-Runtime のバージョンがクラスターの Kubernetes バージョンと一致するかどうかを確認してください。詳細は、「Kubernetes バージョンのリリースノート」をご参照ください。 2. 問題が解決しない場合は、診断データを収集し、チケットを送信してください。詳細は、「GPU アクセラレーテッドノードから診断データを収集する」をご参照ください。 |
| cGPU モジュールのステータス | GPU 共有が有効になっているノードで cGPU モジュールが期待どおりに実行されているかどうか。 | 1. cGPU コンポーネントがインストールされているか確認してください。詳細は、「GPU 共有コンポーネントのインストール」をご参照ください。 2. それでもモジュールが失敗する場合は、診断データを収集し、チケットを送信してください。詳細は、「GPU アクセラレーテッドノードから診断データを収集する」をご参照ください。 |
| コンテナランタイム設定 | GPU アクセラレーテッドノード上のコンテナランタイムが正しく設定されているかどうか。設定が間違っていると、GPU コンテナは実行できなくなります。 | ランタイム設定ファイルで nvidia-container-runtime フィールドが指定されているか確認してください。Docker の場合は /etc/docker/daemon.json、containerd の場合は /etc/containerd/config.toml です。 |
| NVIDIA-Container-Runtime のステータス | NVIDIA-Container-Runtime が期待どおりに実行されているかどうか。 | 診断データを収集し、チケットを送信してください。詳細は、「GPU アクセラレーテッドノードから診断データを収集する」をご参照ください。 |
| NVIDIA カーネルモジュールのステータス | GPU アクセラレーテッドノードで NVIDIA カーネルモジュールが期待どおりに実行されているかどうか。NVIDIA カーネルモジュールに障害が発生すると、すべての GPU ワークロードが実行できなくなります。 | 1. GPU アクセラレーテッドノードを診断してください。詳細は、「GPU に関するよくある質問」をご参照ください。 2. 診断データを収集し、チケットを送信してください。詳細は、「GPU アクセラレーテッドノードから診断データを収集する」をご参照ください。 |