モニタリングダッシュボードを使用して、kube-controller-manager のワークキュー、リソース、および Kube API のメトリックを確認します。
基本概念
ワークキュー
事前準備
ダッシュボードへのアクセス
詳細については、「クラスターのコントロールプレーンコンポーネント向けモニタリングダッシュボードの表示」をご参照ください。
メトリックリスト
次の表は、
|
メトリクス |
タイプ |
説明 |
|
workqueue_adds_total |
Counter |
|
|
workqueue_depth |
Gauge |
現在の |
|
workqueue_queue_duration_seconds_bucket |
ヒストグラム |
アイテムが |
|
memory_utilization_byte |
Gauge |
メモリ使用量。単位:バイト。 |
|
cpu_utilization_core |
Gauge |
CPU 使用率。単位:コア。 |
|
resource_utilization_level |
Gauge |
リソース使用率レベル。
|
|
rest_client_requests_total |
Counter |
状態コード、メソッド、ホスト別に集計した HTTP リクエストの総数です。 |
|
rest_client_request_duration_seconds_bucket |
Histogram |
動詞および URL 別に集計した HTTP リクエストの遅延時間です。 |
以下のリソース使用率メトリックは、すでに使用されていません。これらのメトリックに依存するアラートやモニタリングルールを削除してください。
cpu_utilization_ratio:CPU 使用率。
memory_utilization_ratio:メモリ使用率。
ダッシュボードの使用方法
ダッシュボード上でリクエストの分位数および PromQL サンプリング間隔を設定します。以下のセクションでは、各チャートとその PromQL クエリについて説明します。
ワークキュー
ダッシュボードビュー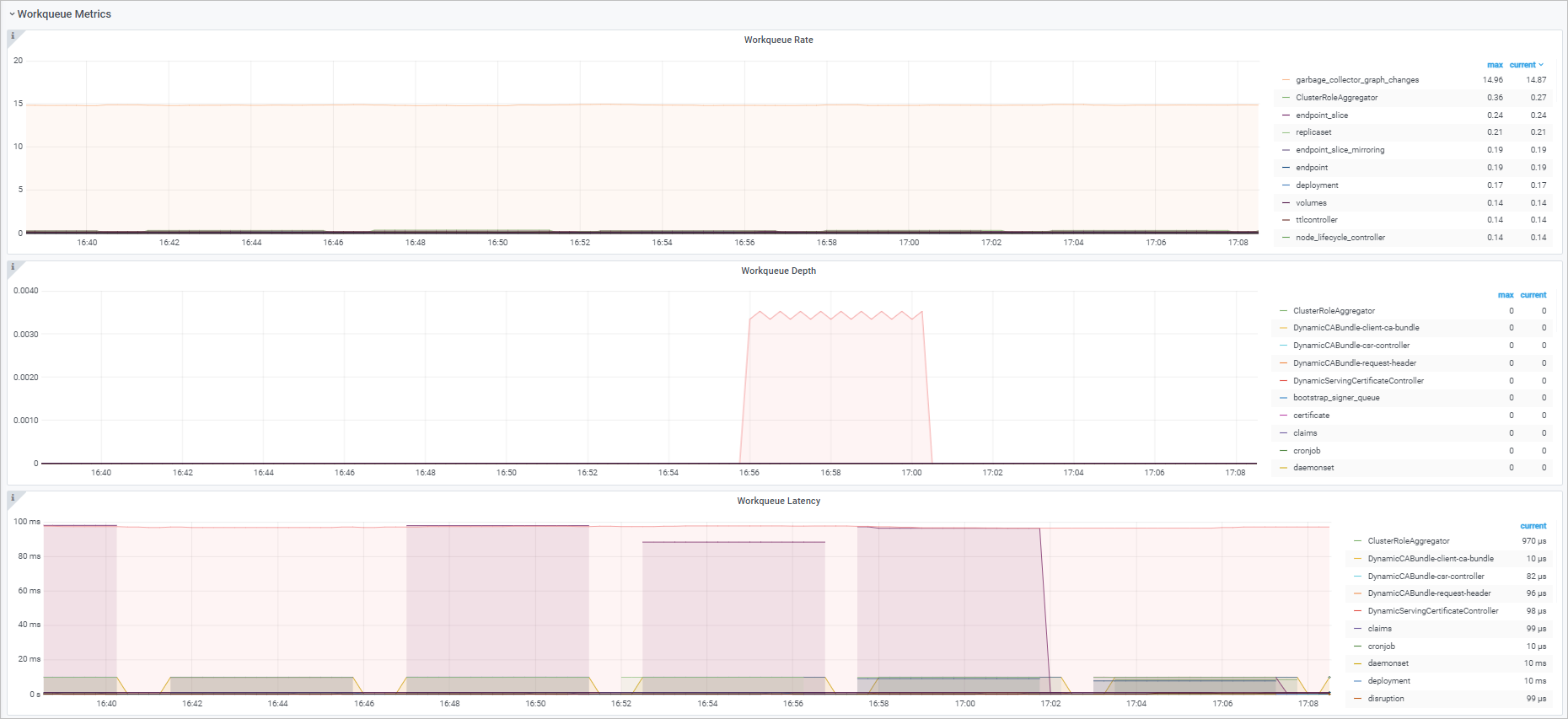
チャート
名前 |
PromQL |
説明 |
|
ワークキュー追加レート |
sum(rate(workqueue_adds_total{job="ack-kube-controller-manager"}[$interval])) by (name) |
|
|
ワークキューの深さ |
sum(rate(workqueue_depth{job="ack-kube-controller-manager"}[$interval])) by (name) |
|
|
ワークキュー処理遅延 |
histogram_quantile($quantile, sum(rate(workqueue_queue_duration_seconds_bucket{job="ack-kube-controller-manager"}[5m])) by (name, le)) |
アイテムが |
リソース
ダッシュボードビュー
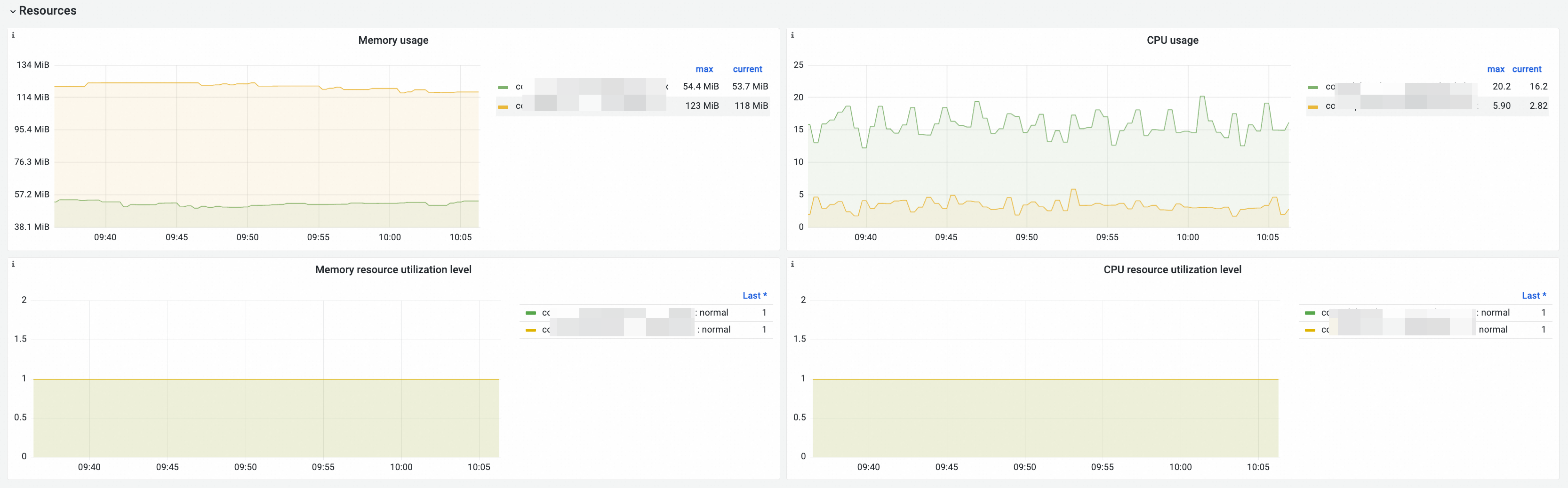
チャート
|
チャート名 |
PromQL |
説明 |
|
メモリ使用率 |
memory_utilization_byte{container="kube-controller-manager"} |
メモリ使用量。単位:バイト。 |
|
CPU 使用率 |
cpu_utilization_core{container="kube-controller-manager"}*1000 |
CPU 使用量。単位:ミリコア。 |
|
メモリリソース使用率レベル |
|
|
|
CPU リソース使用率レベル |
|
Kube API
ダッシュボードビュー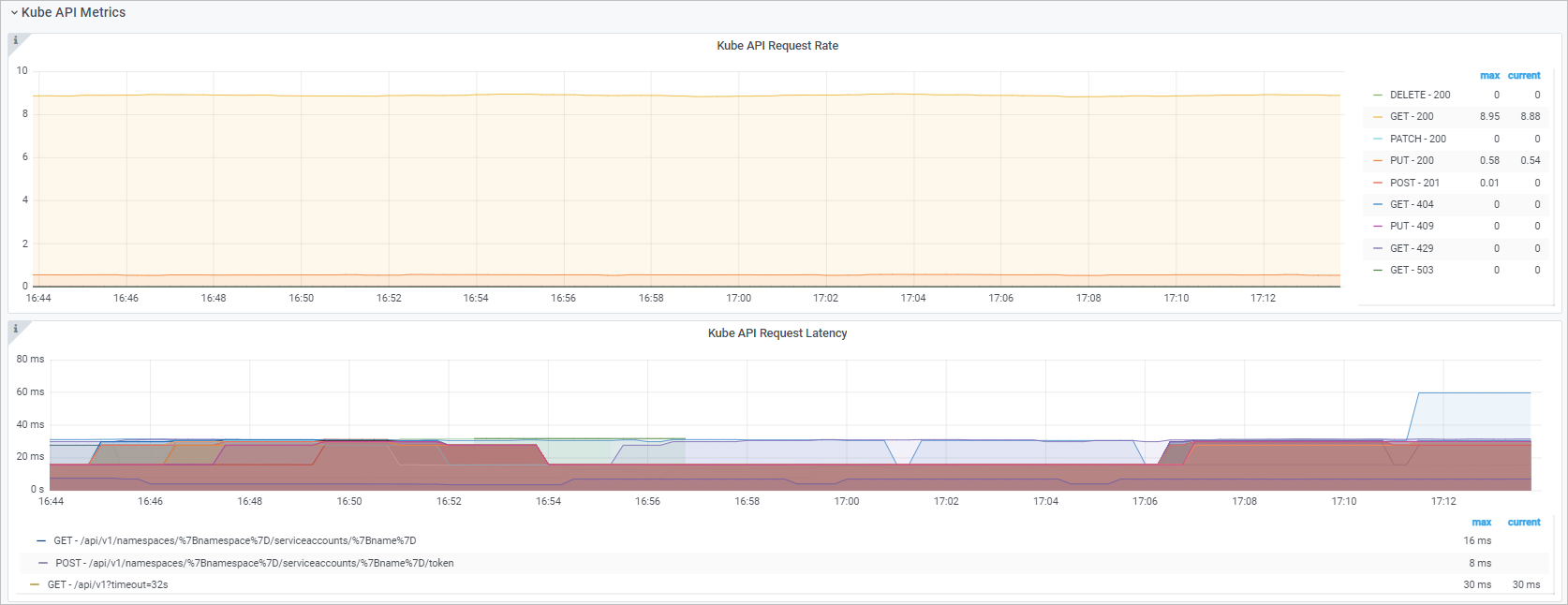
チャート
|
チャート名 |
PromQL |
説明 |
|
Kube API リクエスト QPS |
|
kube-controller-manager から kube-apiserver への HTTP リクエストの QPS(メソッドおよび状態コード別)です。 |
|
Kube API リクエスト遅延 |
histogram_quantile($quantile, sum(rate(rest_client_request_duration_seconds_bucket{job="ack-kube-controller-manager"}[$interval])) by (verb,url,le)) |
kube-controller-manager から kube-apiserver への HTTP リクエストの遅延時間(動詞および URL 別)です。 |
参照
他のコントロールプレーンコンポーネントのメトリックおよびダッシュボードについては、「kube-apiserver コンポーネントのモニタリングメトリック」、「etcd コンポーネントのモニタリングメトリック」、「kube-scheduler コンポーネントのモニタリングメトリック」、および「cloud-controller-manager コンポーネントのモニタリングメトリック」をご参照ください。