etcd のメトリックおよびダッシュボードパネルを使用して、ACK クラスターのコントロールプレーンの問題を検出し、診断します。
前提条件
アクセス
詳細については、「コントロールプレーンコンポーネントのモニタリングダッシュボードの表示」をご参照ください。
メトリック一覧
以下の表に、etcd コンポーネントのメトリックを示します。
|
Metric |
Type |
Description |
|
cpu_utilization_core |
Gauge |
CPU 使用量(コア単位)。 |
|
etcd_server_has_leader |
Gauge |
Raft コンセンサスアルゴリズムでは、etcd メンバーの 1 つがリーダーとして選出されます。リーダーは定期的にハートビートを送信し、クラスターの安定性を維持します。 etcd メンバー間にリーダーが存在するかどうかを示します。
|
|
etcd_server_is_leader |
Gauge |
この etcd メンバーがリーダーであるかどうかを示します。
|
|
etcd_server_leader_changes_seen_total |
Counter |
この etcd メンバーが観測したリーダー変更の合計回数。 |
|
etcd_mvcc_db_total_size_in_bytes |
Gauge |
etcd メンバーのデータベースの合計サイズ。 |
|
etcd_mvcc_db_total_size_in_use_in_bytes |
Gauge |
etcd メンバーのデータベースの使用済みサイズ。 |
|
etcd_disk_backend_commit_duration_seconds_bucket |
Histogram |
データ変更がバックエンドストレージに書き込まれ、コミットされるまでの時間。 バケットの境界値は |
|
etcd_debugging_mvcc_keys_total |
Gauge |
etcd に保存されているキーの総数。 |
|
etcd_server_proposals_committed_total |
Gauge |
Raft では、状態の変更は提案(proposal)として送信されます。 Raft ログにコミットされた提案の合計数。 |
|
etcd_server_proposals_applied_total |
Gauge |
適用された提案の合計数。 |
|
etcd_server_proposals_pending |
Gauge |
保留中の提案の数。 |
|
etcd_server_proposals_failed_total |
Counter |
失敗した提案の数。 |
|
memory_utilization_byte |
Gauge |
メモリ使用量(バイト単位)。 |
|
resource_utilization_level |
Gauge |
リソース使用率レベル。
|
以下のリソース使用率メトリックは廃止されました。これらのメトリックに依存するアラートやモニタリングルールは削除してください。
cpu_utilization_ratio:CPU 使用率。
memory_utilization_ratio:メモリ使用率。
ダッシュボードガイド
ダッシュボードは PromQL クエリを使用して etcd のメトリックを可視化します。
ダッシュボード概要
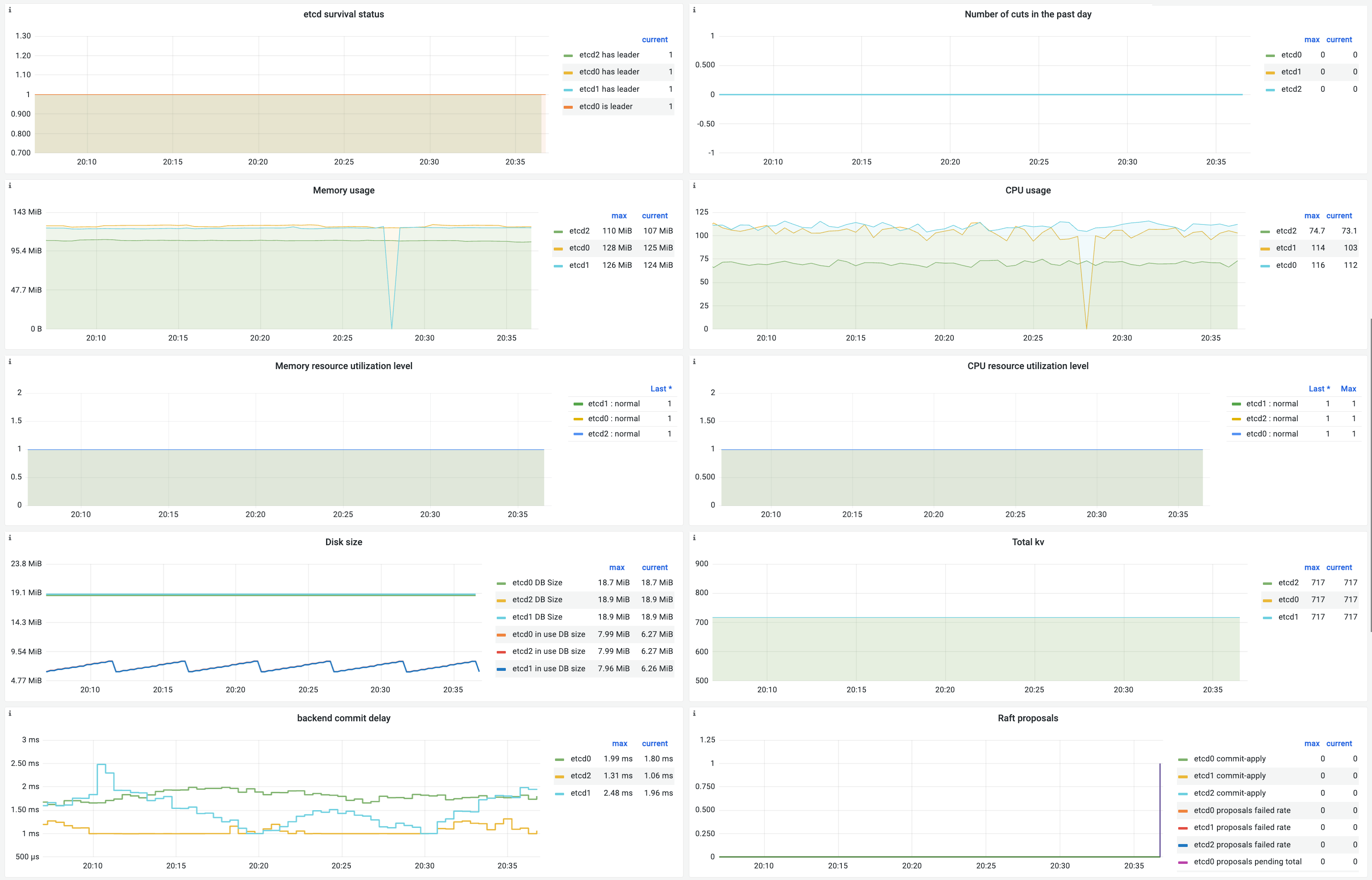
パネルの説明
|
Parameter |
PromQL |
Description |
|
etcd liveness status |
|
|
|
過去 24 時間のリーダーの変更 |
|
過去 1 日間に発生した etcd リーダー変更の回数。 |
|
メモリ使用量 |
|
メモリ使用量(バイト単位)。 |
|
CPU 使用量 |
|
CPU 使用量(ミリコア単位)。 |
|
メモリ使用率レベル |
|
|
|
CPU 使用率レベル |
|
|
|
ディスクサイズ |
etcd_mvcc_db_total_size_in_bytes |
etcd バックエンドデータベースの合計サイズ。 |
|
etcd_mvcc_db_total_size_in_use_in_bytes |
etcd バックエンドデータベースの使用済みサイズ。 |
|
|
キーと値のペアの総数 |
etcd_debugging_mvcc_keys_total |
etcd クラスター内のキーと値のペアの総数。 |
|
バックエンドコミット遅延 |
|
etcd データベースで提案を永続化するために必要な時間。 |
|
Raft 提案ステータス |
|
1 分あたりの失敗した Raft 提案のレート。 |
|
|
保留中の Raft 提案の合計数。 |
|
|
|
コミット済みだが未適用の提案の数。 |
一般的なメトリックアノマリー
etcd liveness status
|
正常ケース |
異常ケース |
説明 |
|
3 つの etcd メンバーすべてにリーダーが存在し、そのうち 1 つがリーダーである必要があります。 |
1 つのメンバーが異常です。 |
対応する |
|
複数のメンバーが異常です。 |
複数のメンバーが また、いずれかのメンバーが |
バックエンドコミット遅延
|
正常ケース |
異常ケース |
説明 |
|
遅延は通常、数ミリ秒から数十ミリ秒の範囲です。 |
数百ミリ秒以上の遅延が継続的に発生しています。 |
ディスク I/O の問題を示しています。 |
Raft 提案アノマリー
|
正常ケース |
異常ケース |
説明 |
|
失敗した Raft 提案のレートは 0 です。 |
失敗した Raft 提案のレートが 0 より大きいです。 |
一部の提案がコミットに失敗しています。失敗率が高い場合は調査が必要です。 |
|
保留中の Raft 提案の合計数は 0 です。 |
0 以外の保留中の Raft 提案が継続的に存在しています。 |
Raft 提案のバックログが発生しており、これは通常、適用速度が遅いことが原因です。バックエンドコミット遅延との相関を確認してください。 |
|
コミット済みと適用済みの Raft 提案の差分は 0 です。 |
コミット済みと適用済みの提案の差分が 0 より大きいです。 |
etcd へのクライアントリクエスト量が過剰である可能性があります。 この値が 5000 を超えると、etcd はバックログされた提案が処理されるまで、 |
参考
詳細については、「kube-apiserver のモニタリングメトリック」、「kube-scheduler のモニタリングメトリック」、「kube-controller-manager のモニタリングメトリック」、および「cloud-controller-manager のモニタリングメトリック」をご参照ください。