cloud-controller-manager コンポーネントは、コア Kubernetes コンポーネントが Kubernetes API を介してクラウド サービス プロバイダー (CSP) と対話できるようにします。このトピックでは、cloud-controller-manager コンポーネントのメトリックについて説明し、そのダッシュボードの使用方法を説明し、一般的なメトリックの異常に対するソリューションを提供します。
始める前に
エントリポイント
詳細については、「コントロールプレーンコンポーネントのモニタリングダッシュボードを表示する」をご参照ください。
メトリックリスト
メトリックは、コンポーネントのステータスとパラメーターを公開します。次の表に、cloud-controller-manager コンポーネントのメトリックを示します。
メトリック | タイプ | 説明 |
ccm_slb_latency_ms | ヒストグラム | Classic Load Balancer (CLB) の同期遅延。単位: ms。 バケットのしきい値は |
ccm_node_latency_ms | ヒストグラム | ノードの同期遅延。単位: ms。 バケットのしきい値は |
ccm_route_latency_ms | ヒストグラム | ルートの同期遅延。単位: ms。 バケットのしきい値は |
workqueue_adds_total | カウンター | ワークキューによって処理された Adds イベントの数。 |
workqueue_depth | ゲージ | ワークキューの長さ。ワークキューの長さが長時間にわたって高いレベルのままである場合、コントローラーはワークキュー内のタスクをタイムリーに処理できず、タスクの蓄積につながります。 |
workqueue_queue_duration_seconds_bucket | ヒストグラム | タスクがワークキューに残る期間。バケットのしきい値は、セット {10-8, 10-7, 10-6, 10-5, 10-4, 10-3, 10-2, 10-1, 1, 10} として定義されます。単位: 秒。 |
memory_utilization_byte | ゲージ | メモリ使用量。単位: バイト。 |
cpu_utilization_core | ゲージ | 使用済み CPU 容量。単位: コア。 |
rest_client_requests_total | カウンター | 状態コード、メソッド、およびホストに基づいて計算された HTTP リクエストの数。 |
rest_client_request_duration_seconds_bucket | ヒストグラム | Verbs と URL に基づいて計算された HTTP 応答遅延。 |
ダッシュボード使用ガイド
ダッシュボードは、コンポーネントのメトリックと関連する Prometheus Query Language (PromQL) クエリを使用して作成されます。次のセクションでは、ダッシュボードの可観測性表示と特徴について説明します。
CCM
可観測性表示
特徴の説明
ダッシュボード名 | PromQL | 説明 |
ルート同期遅延 | histogram_quantile($quantile, sum(rate(ccm_route_latencies_duration_milliseconds_bucket[$interval])) by (verb, le)) | ルートの同期遅延。単位: ms。 |
ノード同期遅延 | histogram_quantile($quantile, sum(rate(ccm_node_latencies_duration_milliseconds_bucket[$interval])) by (verb, le)) | ノードの同期遅延。単位: ms。 |
CLB (Classic Load Balancer) 同期遅延 | histogram_quantile($quantile, sum(rate(ccm_slb_latencies_duration_milliseconds_bucket[$interval])) by (verb, le)) | CLB の同期遅延。単位: ms。 |
キュー
可観測性表示
特徴の説明
ダッシュボード名 | PromQL | 説明 |
ワークキューエンキューレート | sum(rate(workqueue_adds_total{job="ack-cloud-controller-manager"}[$interval])) by (name) | 指定された間隔でワークフローに追加される Adds イベントの数。 |
ワークキューの深さ | workqueue_depth{job="ack-cloud-controller-manager"} | 指定された間隔でのワークキューの長さの変化。 |
ワークキュー処理遅延 | histogram_quantile($quantile, sum(rate(workqueue_queue_duration_seconds_bucket{job="ack-cloud-controller-manager"}[$interval])) by (name, le)) | ワークキュー内のイベントの期間。 |
リソース
可観測性表示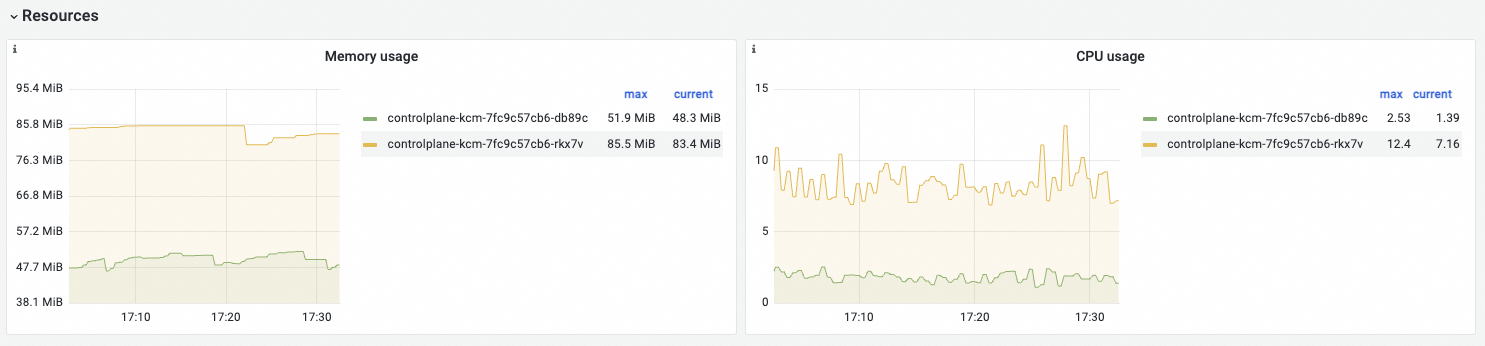
特徴の説明
ダッシュボード名 | PromQL | 説明 |
メモリ使用量 | memory_utilization_byte{container="cloud-controller-manager"} | メモリ使用量。単位: バイト。 |
CPU 使用量 | cpu_utilization_core{container="cloud-controller-manager"}*1000 | 使用済み CPU 容量。単位: ミリコア。 |
Kube API
可観測性表示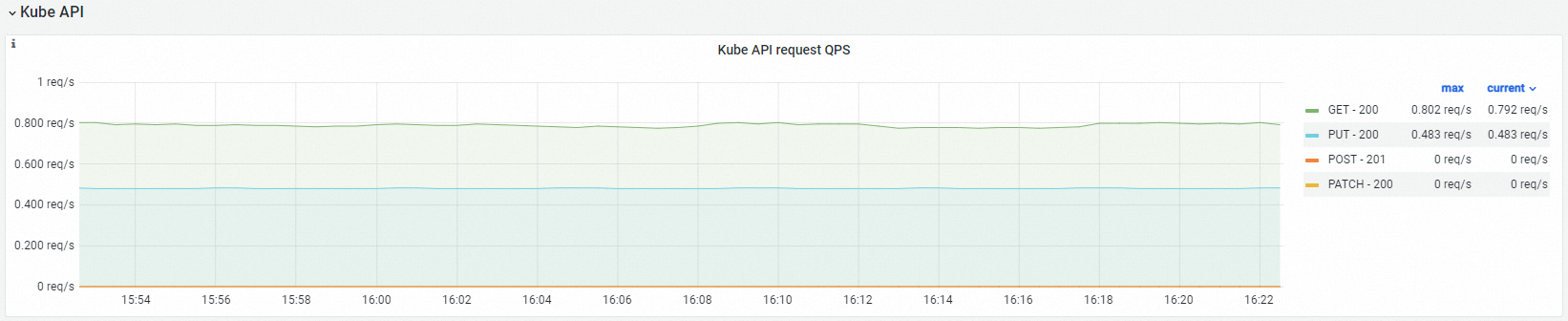
特徴の説明
ダッシュボード名 | PromQL | 説明 |
Kube API リクエスト QPS |
| cloud-controller-manager が kube-apiserver に送信する HTTP リクエストのクエリ/秒 (QPS)。verb とリクエスト URL によって分析されます。 |
一般的なメトリックの異常
CLB (Classic Load Balancer) 同期遅延
正常な条件 | 異常な条件 | 説明 | 提案 |
[CLB (Classic Load Balancer) 同期遅延] は 10s 以内です。 | [CLB (Classic Load Balancer) 同期遅延] は 10s を超えています。 | CLB の同期に時間がかかりすぎます。 | サービスの異常なアクティビティを確認してください。 |
ワークキューの深さ
正常な条件 | 異常な条件 | 説明 | 提案 |
[ワークキューの深さ] は 10 未満です。 | [ワークキューの深さ] は 10 を超えています。 | ワークキューには同期するサービスが多数含まれています。 | キューが長すぎると、サービスの同期が遅くなります。必要に応じて、クラスター内のノード、Pod、およびサービスへの変更の頻度を減らしてください。 |
参照
他のコントロールプレーンコンポーネントのメトリック、ダッシュボード使用ガイド、および一般的なメトリックの異常に関する詳細については、「kube-apiserver コンポーネントのメトリック」、「etcd コンポーネントのメトリック」、「kube-scheduler コンポーネントのメトリック」、および「kube-controller-manager コンポーネントのメトリック」をご参照ください。