Pemilik dataset dan administrator ruang kerja yang memiliki izin dataset Q Chat configuration dapat melakukan Q Chat configuration dan Q Chat permission configuration. Untuk informasi tentang cara memperoleh izin yang diperlukan, lihat role management. Topik ini menjelaskan cara mengonfigurasi pengaturan dan izin Q Chat untuk suatu dataset.
Fitur ini saat ini hanya tersedia di wilayah China (Hong Kong) dan Malaysia (Kuala Lumpur). Fitur ini sedang diluncurkan secara bertahap ke wilayah lainnya.
Q Chat configuration
Untuk menggunakan fitur Q Chat di Quick BI, Anda harus mengonfigurasi pengaturan Q Chat untuk dataset Anda.
Entry points
Anda dapat mengakses halaman konfigurasi Q Chat dengan salah satu dari dua cara berikut.
Metode 1: Di halaman pengeditan dataset, buka Q Chat configuration.
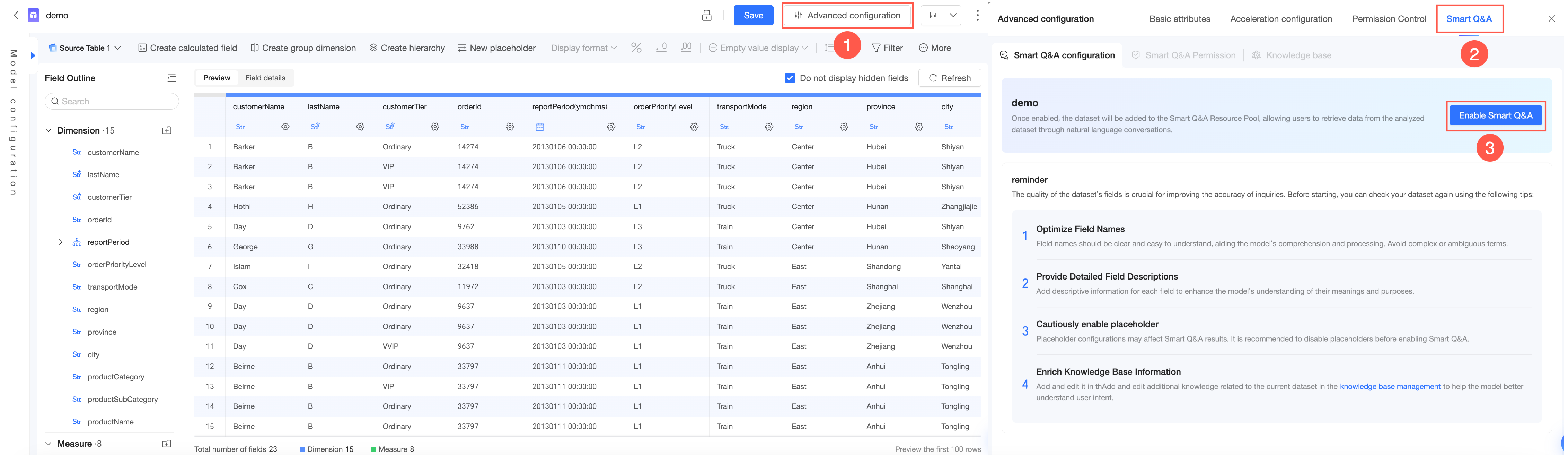
Metode 2: Saat Anda membuat dataset, buka Q Chat configuration.
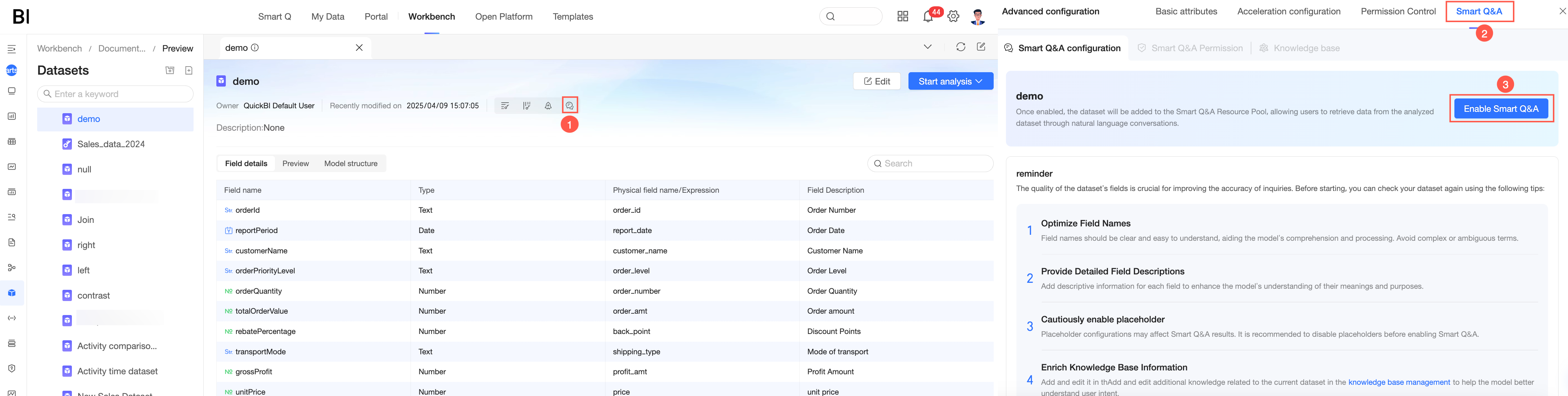
Basic information
Buka halaman Q Chat configuration dan konfigurasikan Basic Information.
Kualitas bidang dataset Anda sangat penting untuk meningkatkan akurasi Q Chat. Sebelum memulai, tinjau dataset Anda menggunakan praktik terbaik berikut:
Optimize field names
Nama bidang harus jelas dan mudah dipahami agar model besar dapat memprosesnya dengan benar. Hindari nama yang kompleks atau ambigu.
Provide detailed field descriptions
Tambahkan deskripsi untuk setiap bidang guna membantu model lebih memahami makna dan tujuannya.
Use placeholders with caution
Mengonfigurasi placeholder dapat memengaruhi hasil kueri. Kami menyarankan Anda menonaktifkan placeholder sebelum mengaktifkan fitur Q Chat.
Enrich the knowledge base
Di bagian manajemen basis pengetahuan, tambahkan dan edit informasi tambahan tentang dataset saat ini untuk meningkatkan pemahaman model besar terhadap maksud pengguna.
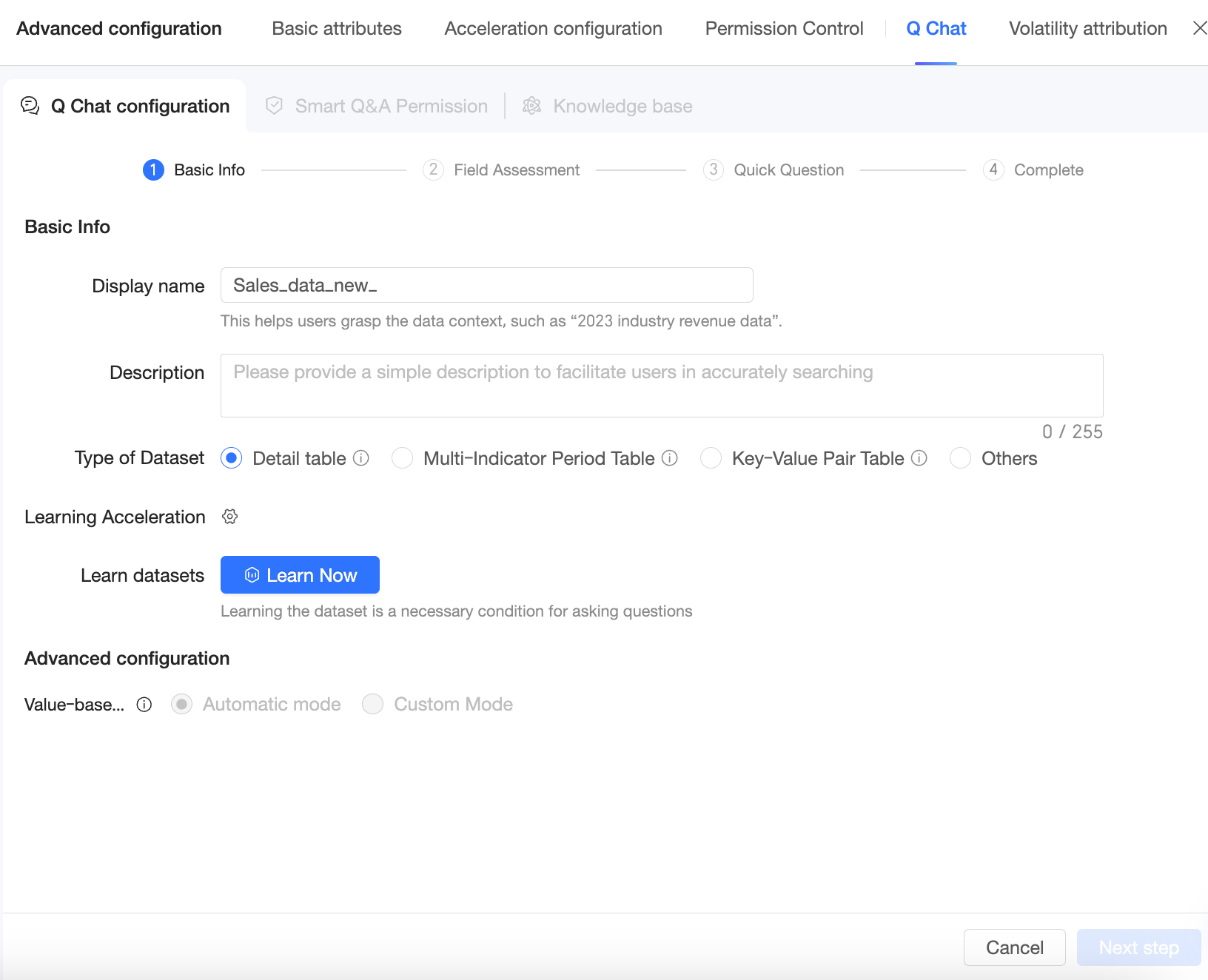
Anda dapat mengubah Display Name dataset.
CatatanAnda dapat menetapkan nama tampilan yang ramah bisnis untuk dataset yang terlihat oleh pengguna. Nama ini membantu pengguna memahami isi dataset, misalnya, "Data Pendapatan 2023 Berdasarkan Industri".
Description
Berikan deskripsi singkat untuk membantu pengguna menemukan dataset dengan mudah.
Dataset Type
Pilih jenis dataset untuk membantu asisten AI memahami struktur data Anda dan meningkatkan akurasi respons. Jenis yang didukung meliputi details table, multi-metric period table, key-value table, dan other.
Details table
Menampilkan informasi detail, dengan satu catatan per baris. Setiap catatan berisi beberapa nilai dimensi atau informasi ukuran, seperti "Or****ID, Us***ID, Order Status, Order Amount".
Multi-metric period table
Menampilkan nilai statistik metrik selama periode berbeda, seperti "penjualan kumulatif 7 hari", "penjualan kumulatif 15 hari", dan "penjualan kumulatif 30 hari".
Key-value table
Tabel pasangan kunci-nilai yang terutama berisi bidang untuk tanggal, dimensi, nama metrik, dan nilai metrik, seperti "Statistics Date", "KPI Name", "KPI Actual Value", dan "KPI Target Value".
Learning acceleration
Anda dapat memilih tabel sumber dalam ruang kerja Anda untuk menyediakan nilai dimensi bagi setiap bidang. Proses ini juga dikenal sebagai dimension value acceleration.
Klik ikon
 di samping Learning Acceleration dan aktifkan sakelar learning acceleration.
di samping Learning Acceleration dan aktifkan sakelar learning acceleration.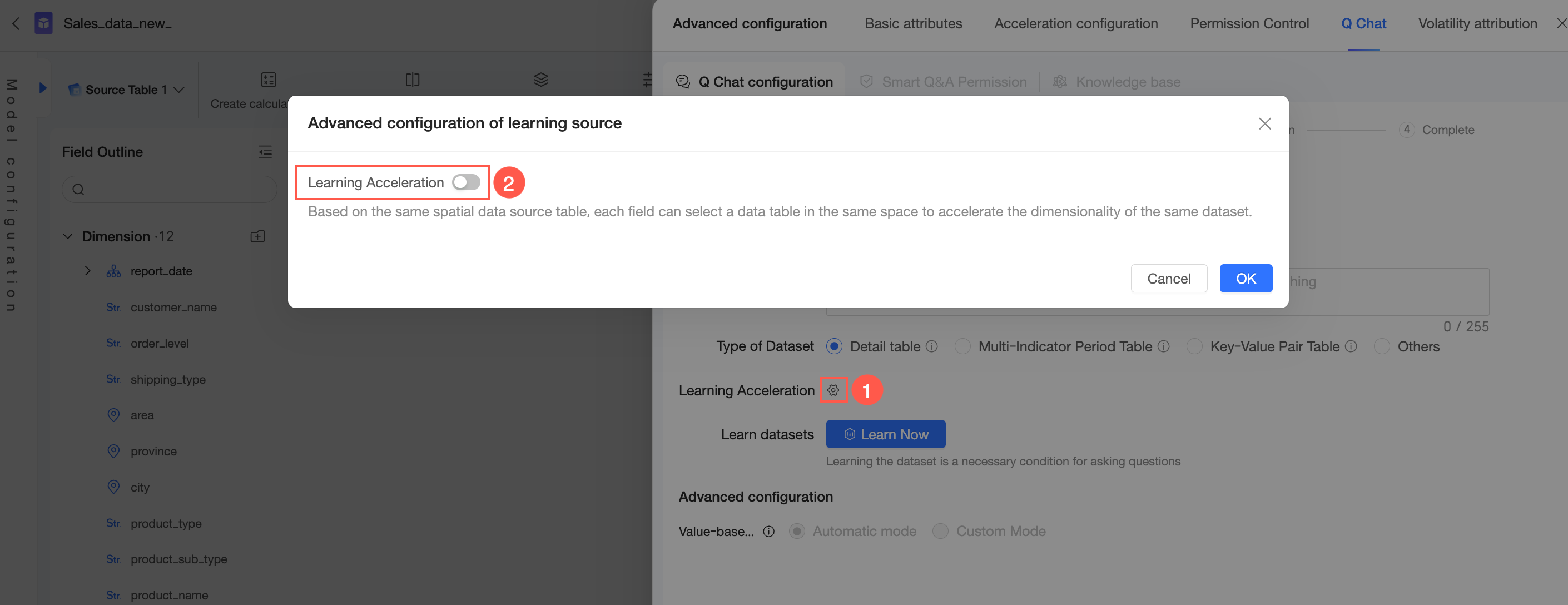
Di halaman konfigurasi lanjutan untuk sumber pembelajaran, petakan bidang dimensi dataset Anda ke bidang dalam tabel sumber.
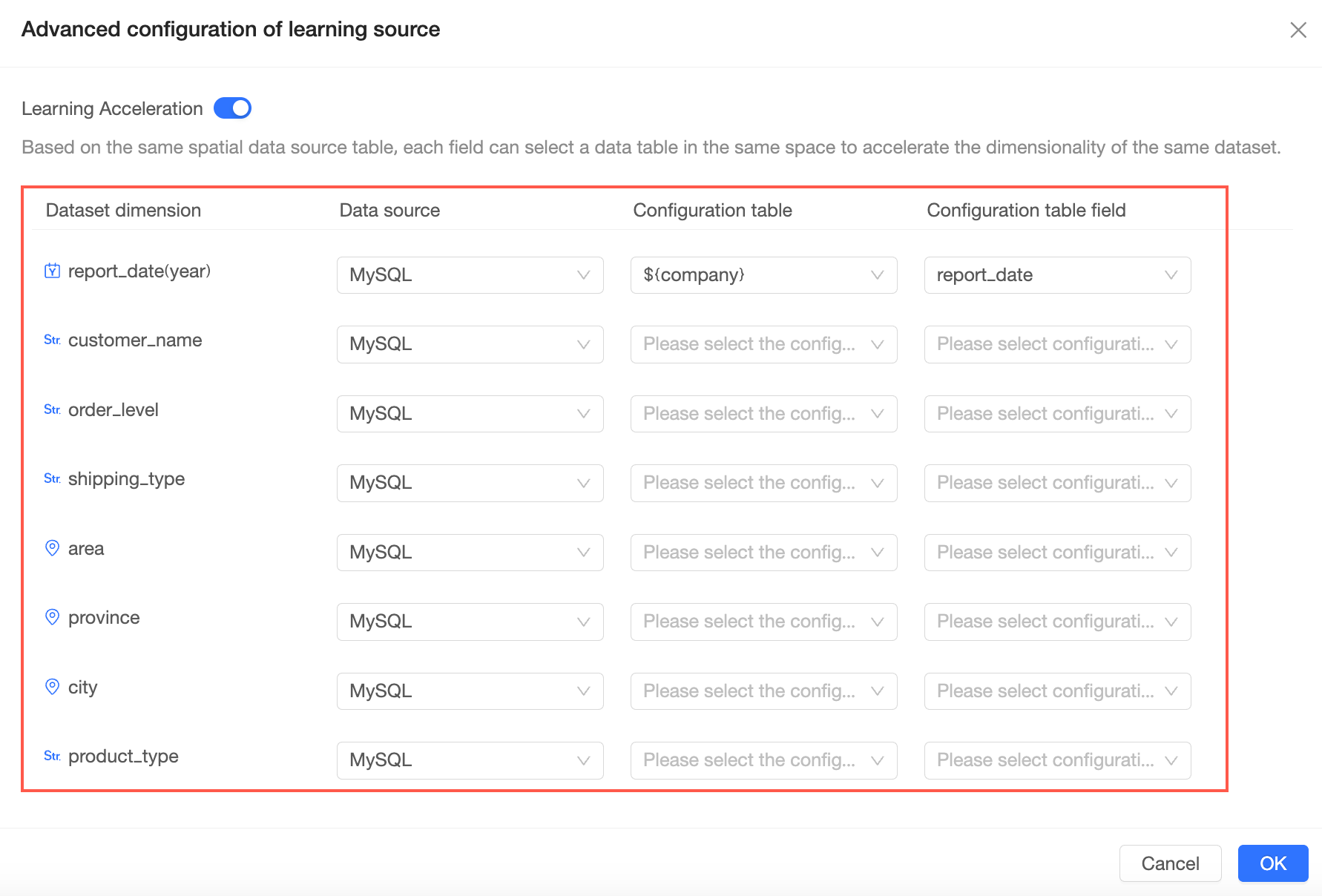
Setelah semua pemetaan dikonfigurasi, klik OK.
Klik Learn Now untuk memulai proses pembelajaran untuk dataset.
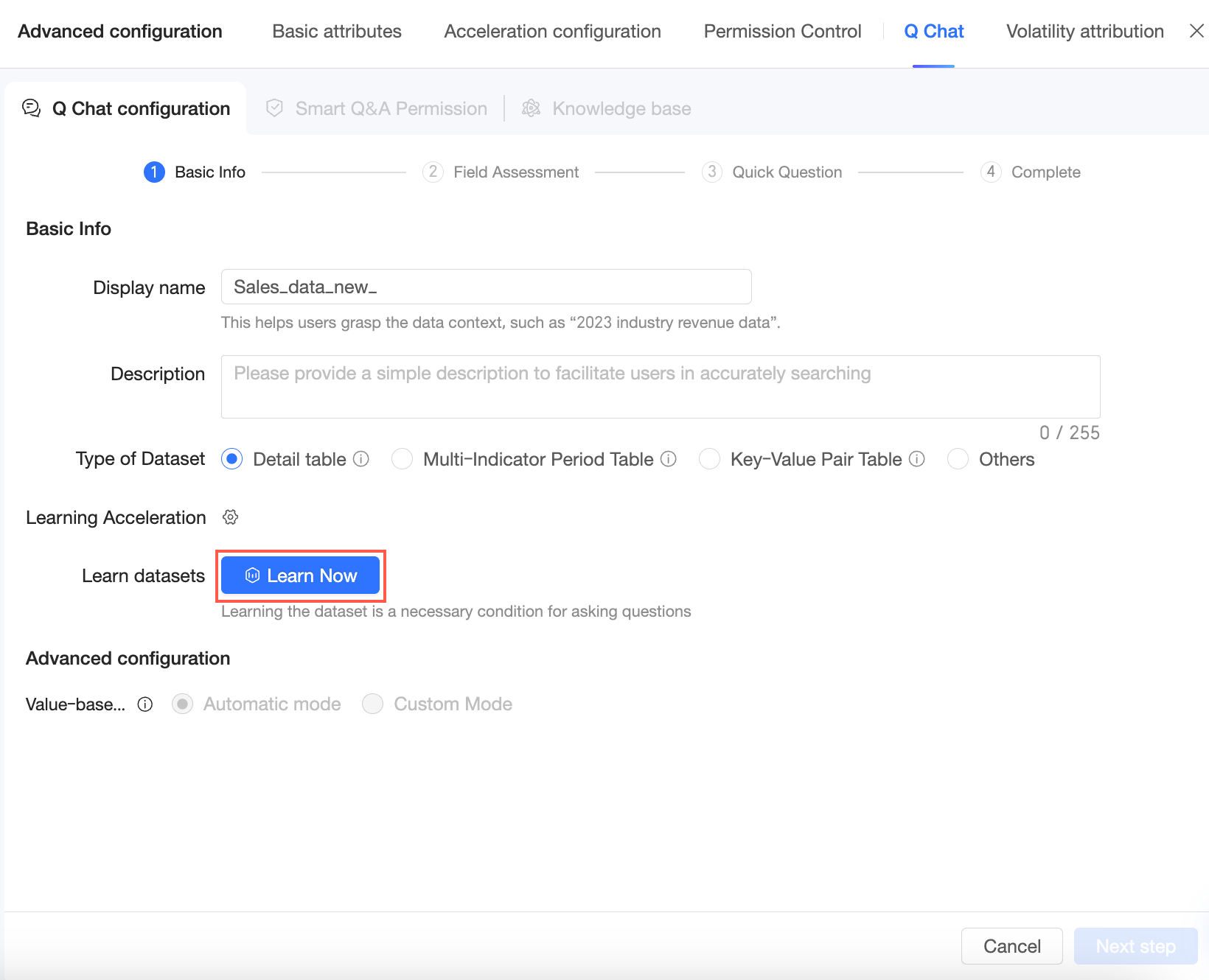
Setelah proses pembelajaran selesai, Anda dapat mengklik Re-learn jika dataset berubah.
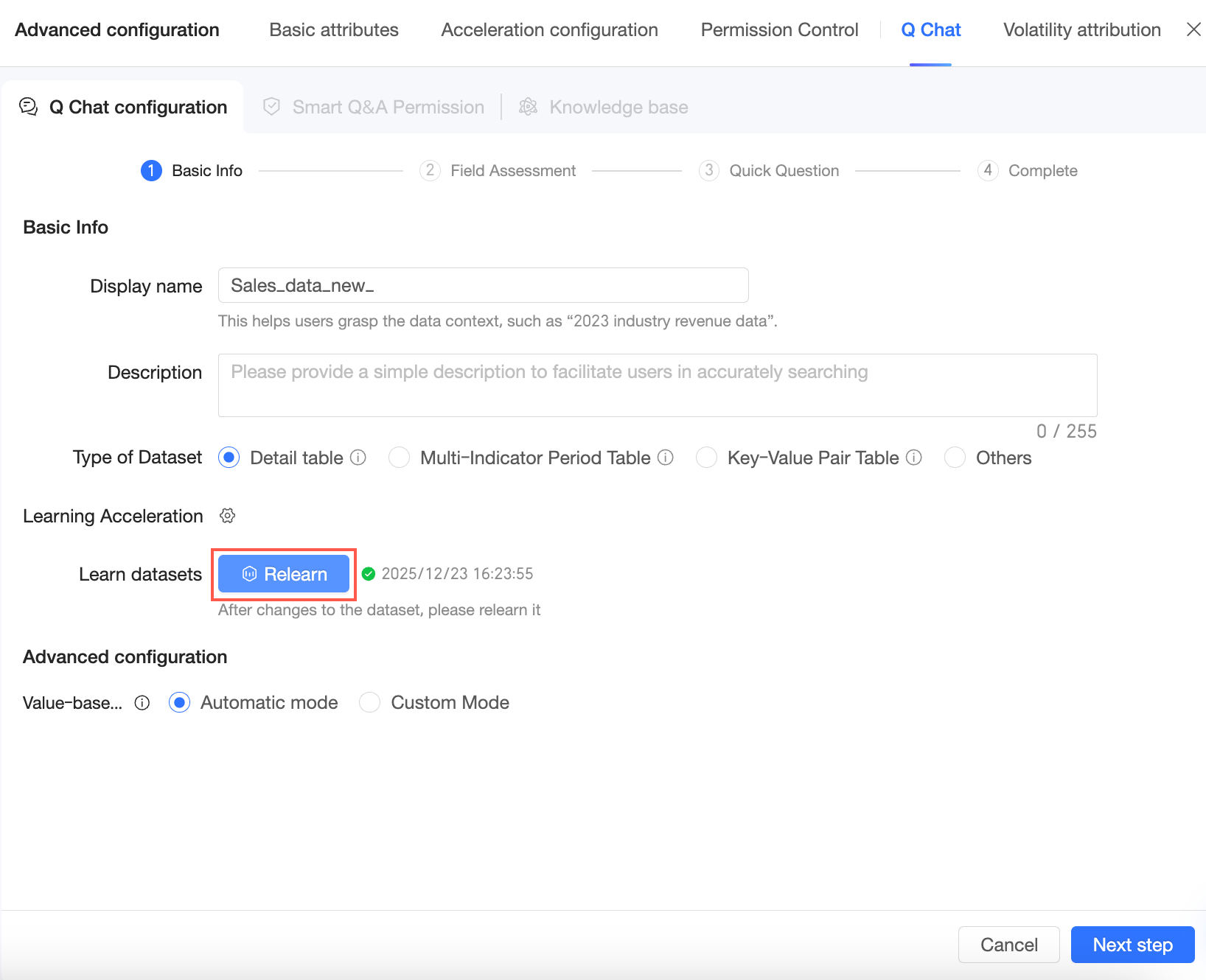
Di pengaturan lanjutan, konfigurasikan dimension value matching mode. Anda dapat memilih antara automatic mode dan custom mode.
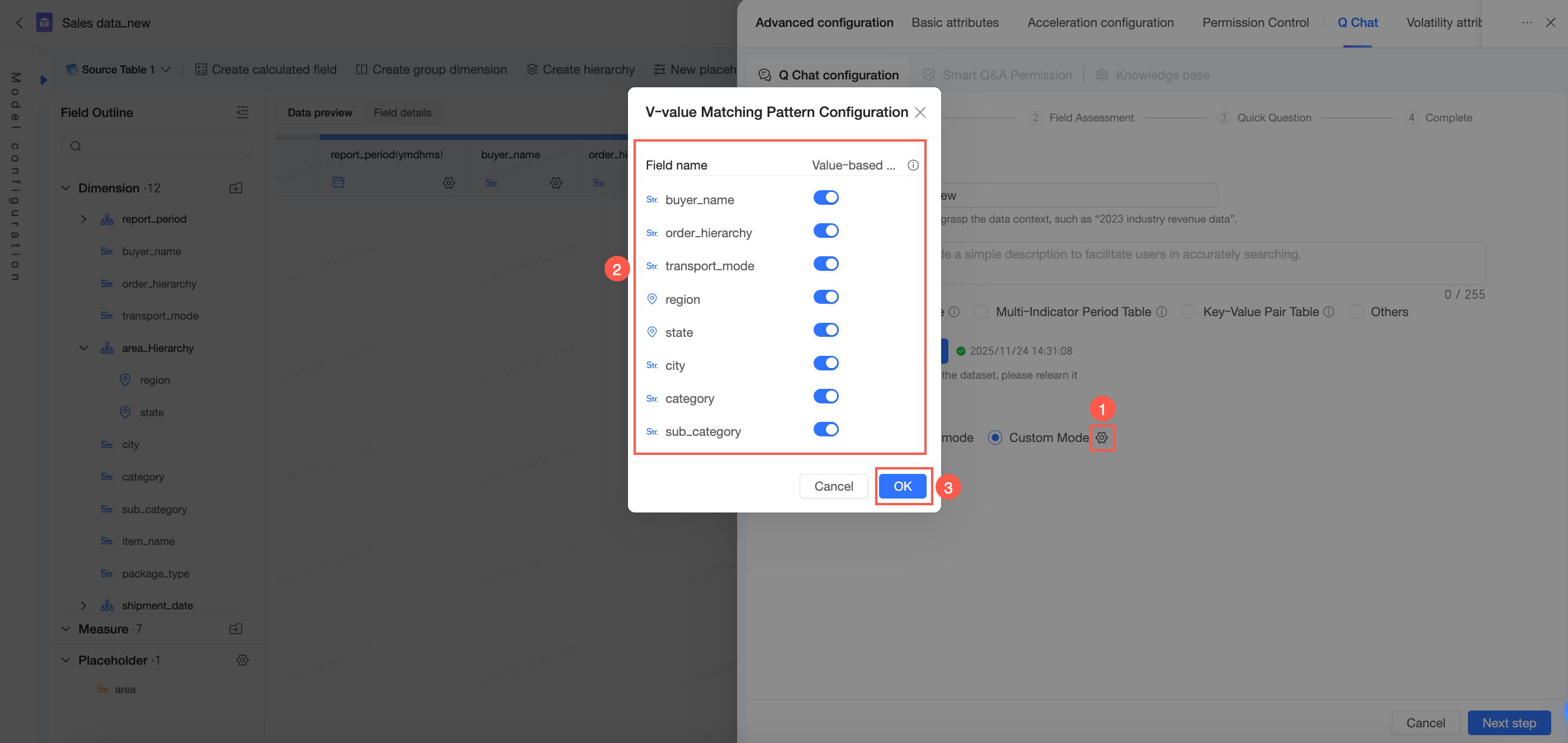
Jika kueri pengguna berisi nilai dimensi yang belum dipelajari sistem karena jumlah nilainya melebihi batas pembelajaran, Anda dapat memilih salah satu dari dua strategi pencocokan berikut:
Automatic mode: Sistem secara otomatis menentukan apakah akan menulis ulang nilai yang diberikan pengguna menjadi nilai yang telah dipelajari.
Custom mode: Administrator dapat mengatur secara individual apakah akan mengaktifkan penulisan ulang untuk setiap dimensi.
Enable rewriting: Mengizinkan sistem memetakan nilai yang diberikan pengguna ke nilai yang telah dipelajari.
Disable rewriting: Melakukan pencocokan ketat terhadap input pengguna tanpa menulis ulang.
Klik Next untuk melanjutkan ke halaman field quality assessment.
Field quality assessment
Di halaman ini, sistem mengevaluasi kualitas bidang dataset Anda untuk meningkatkan hasil kueri.
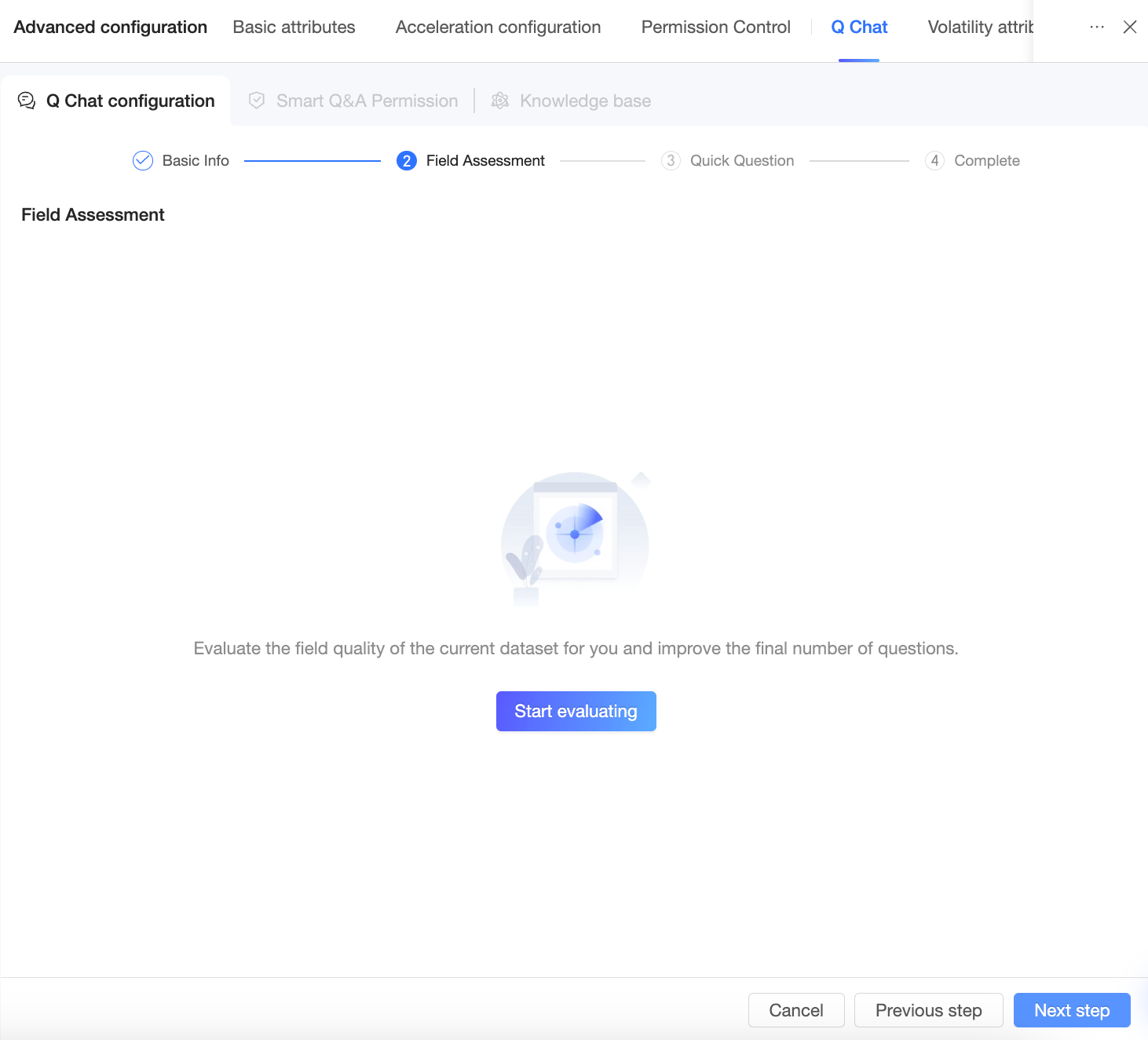
Klik Start Assessment.
CatatanPenilaian kualitas bidang mungkin memerlukan waktu 1 hingga 2 menit. Anda dapat melanjutkan ke langkah berikutnya, dan Anda akan diberi tahu ketika hasilnya siap.
Setelah penilaian, sistem memberikan saran modifikasi yang dapat Anda terima atau abaikan.
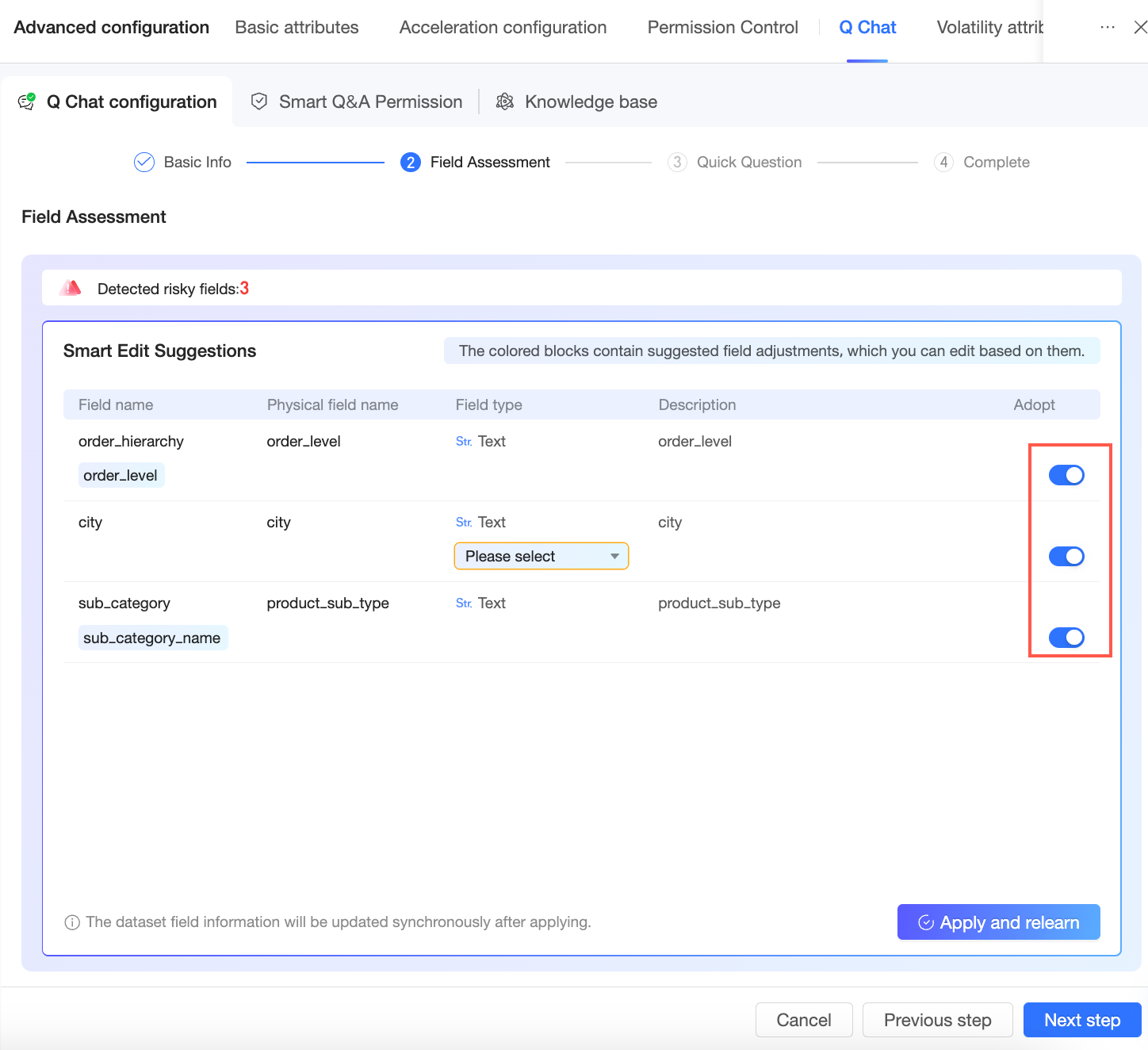
Klik Apply and Re-learn untuk memperbarui informasi bidang dataset, lalu klik Next untuk menuju halaman quick question.
Quick questions
Pertanyaan yang direkomendasikan ditampilkan setelah pengguna memilih dataset untuk membantu mereka memulai. Tiga mode didukung: system recommendation, expert customization, dan recommendation by recipient.
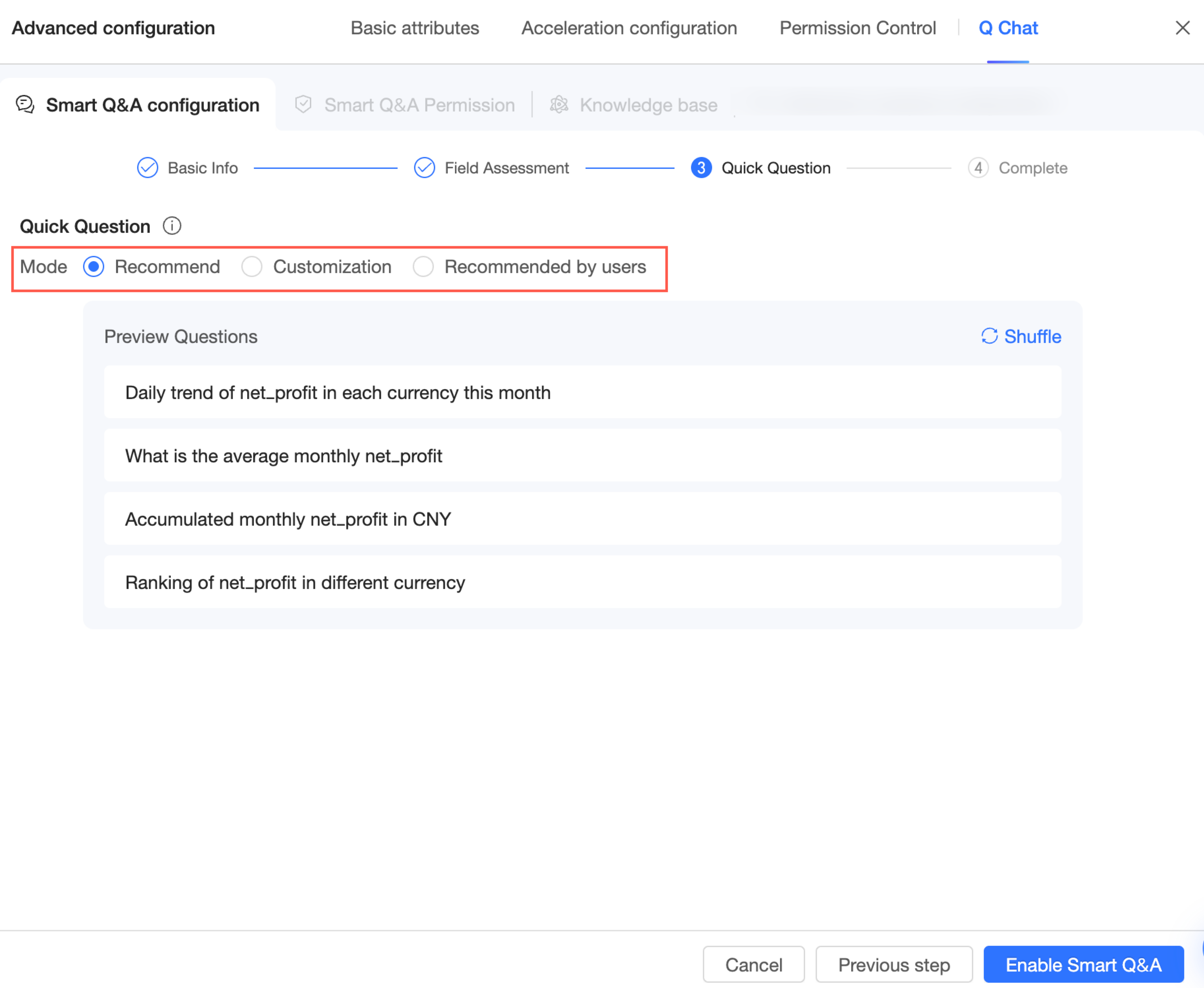
System recommendation
Anda dapat melihat pratinjau pertanyaan cepat. Klik Refresh untuk melihat kumpulan pertanyaan yang berbeda.
Expert customization
Dalam mode ini, Anda dapat mengklik Add Question untuk memasukkan pertanyaan yang ingin dilihat pengguna. Empat pertanyaan pertama ditampilkan secara default. Jika Anda menambahkan lebih dari empat, pengguna dapat mengklik Refresh untuk berganti-ganti melihatnya.
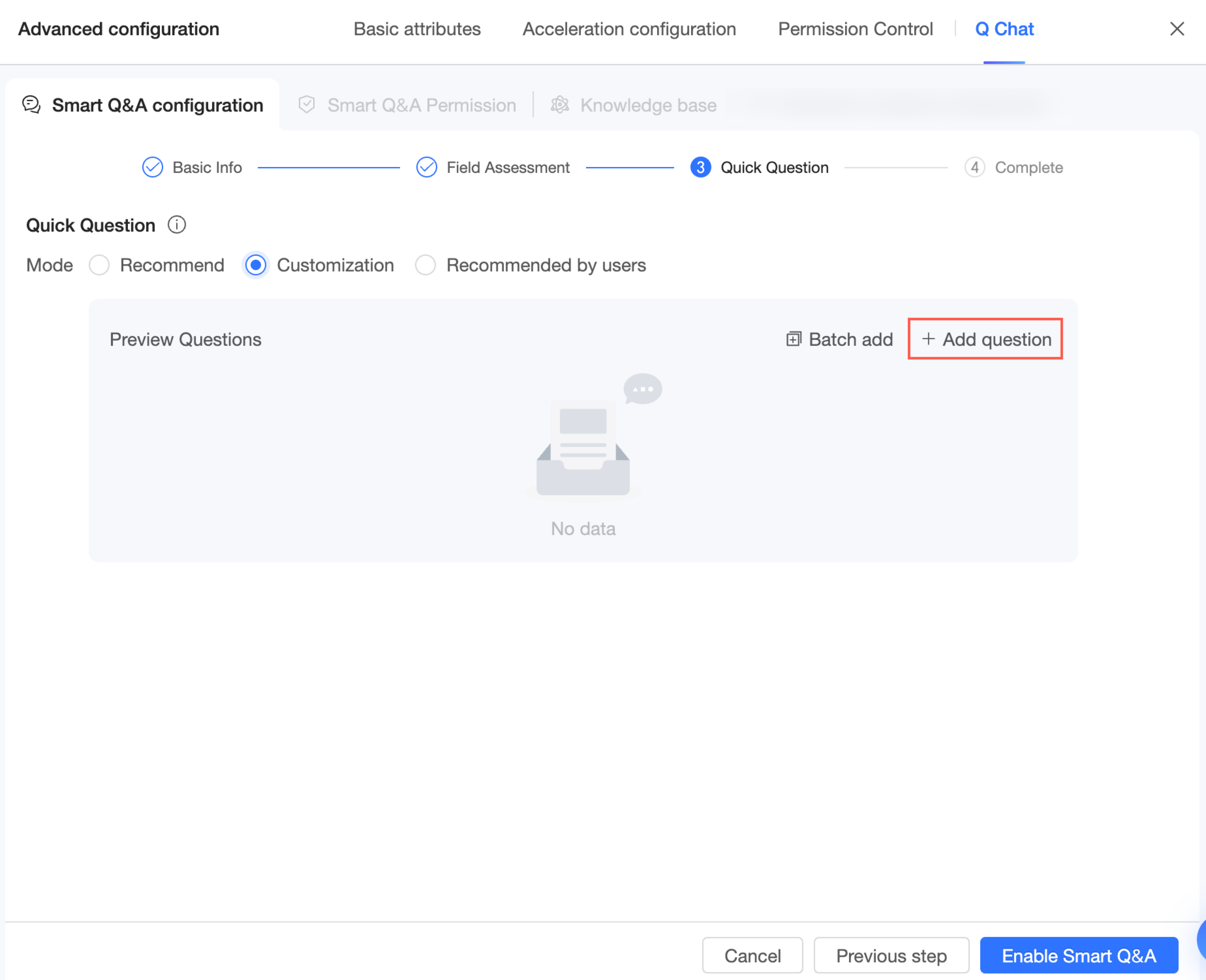
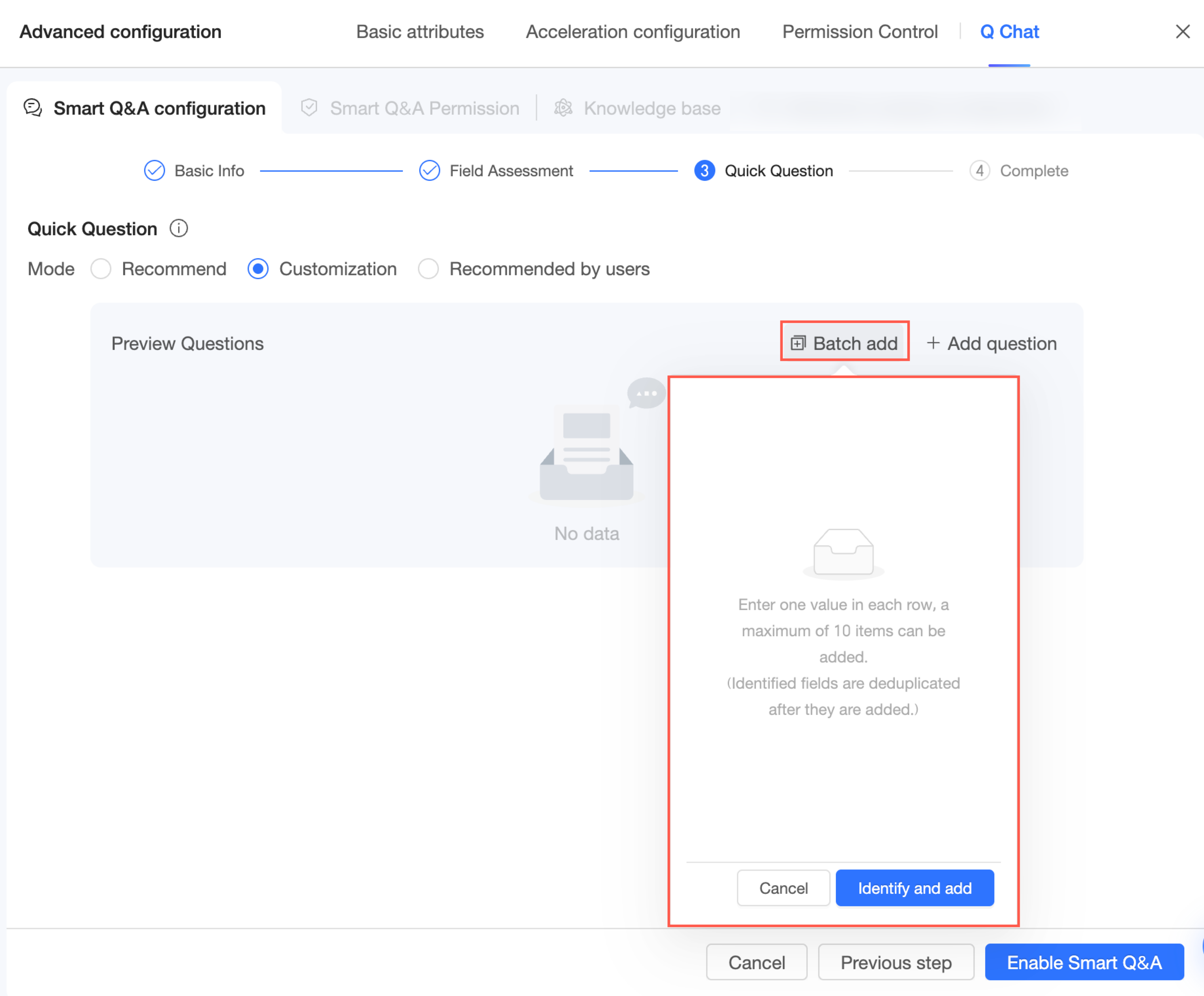
Jika perlu menambahkan beberapa pertanyaan sekaligus, klik Batch Add dan masukkan pertanyaan tersebut.
CatatanMasukkan satu pertanyaan per baris. Anda dapat menambahkan hingga 10 pertanyaan.
Recommendation by recipient
Saat Anda memilih mode recommendation by recipient, ikuti langkah-langkah berikut untuk menambahkan aturan:
Klik Add Recommendation Rule atau Add Rule di pojok kiri bawah.
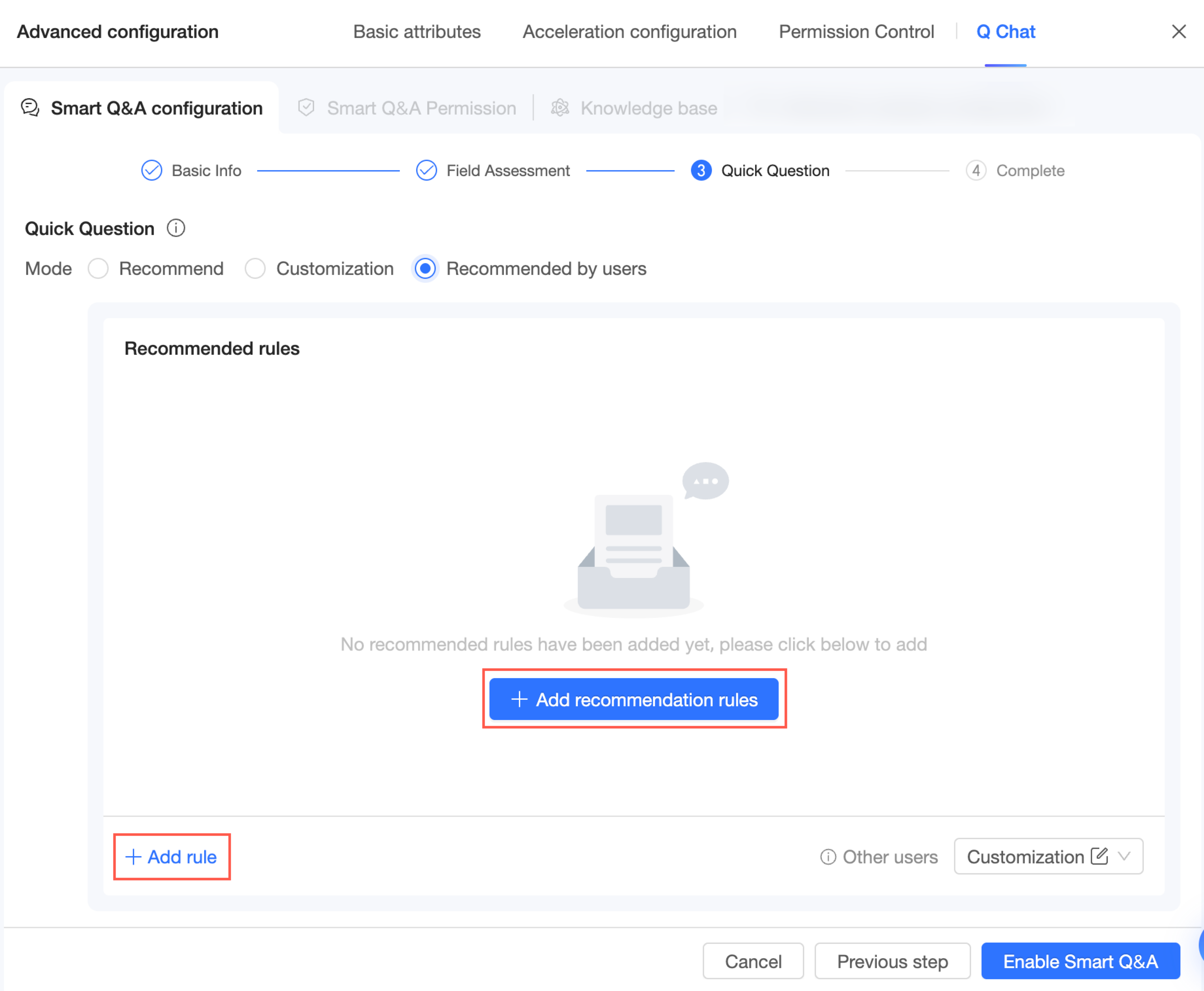
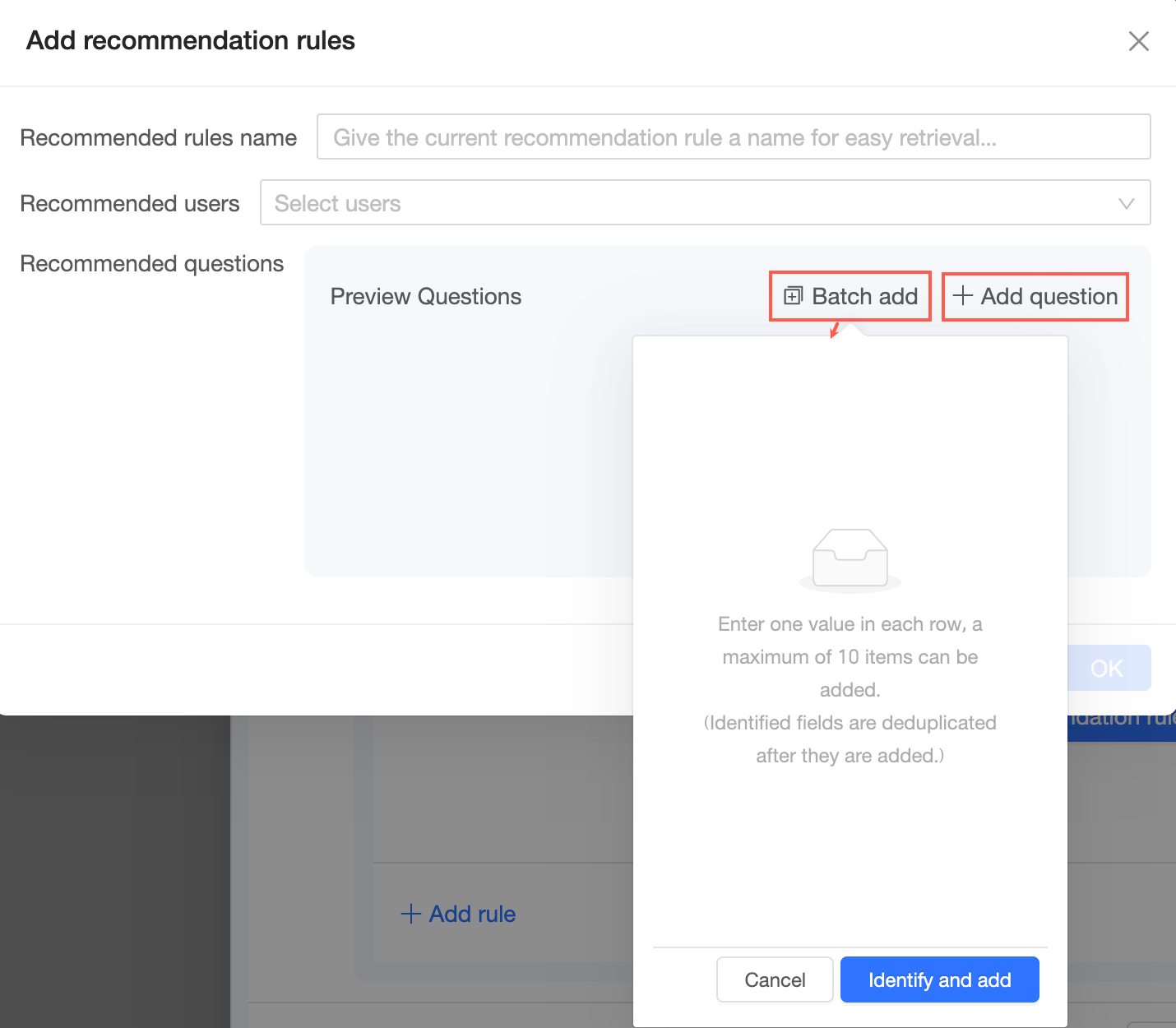
Di halaman Add Recommendation Rule, masukkan nama aturan, tentukan penerima rekomendasi, dan tambahkan pertanyaan yang direkomendasikan.
Nama aturan rekomendasi: Beri nama aturan agar mudah diidentifikasi.
Penerima rekomendasi: Pilih pengguna sebagai audiens target untuk rekomendasi.
Pertanyaan yang direkomendasikan: Klik Add Question untuk menambahkan satu pertanyaan, atau klik Batch Add untuk menambahkan beberapa pertanyaan.
CatatanAnda dapat menambahkan hingga 10 pertanyaan.
Pilih salah satu dari system recommendation atau expert customization sebagai aturan fallback untuk pengguna lain.
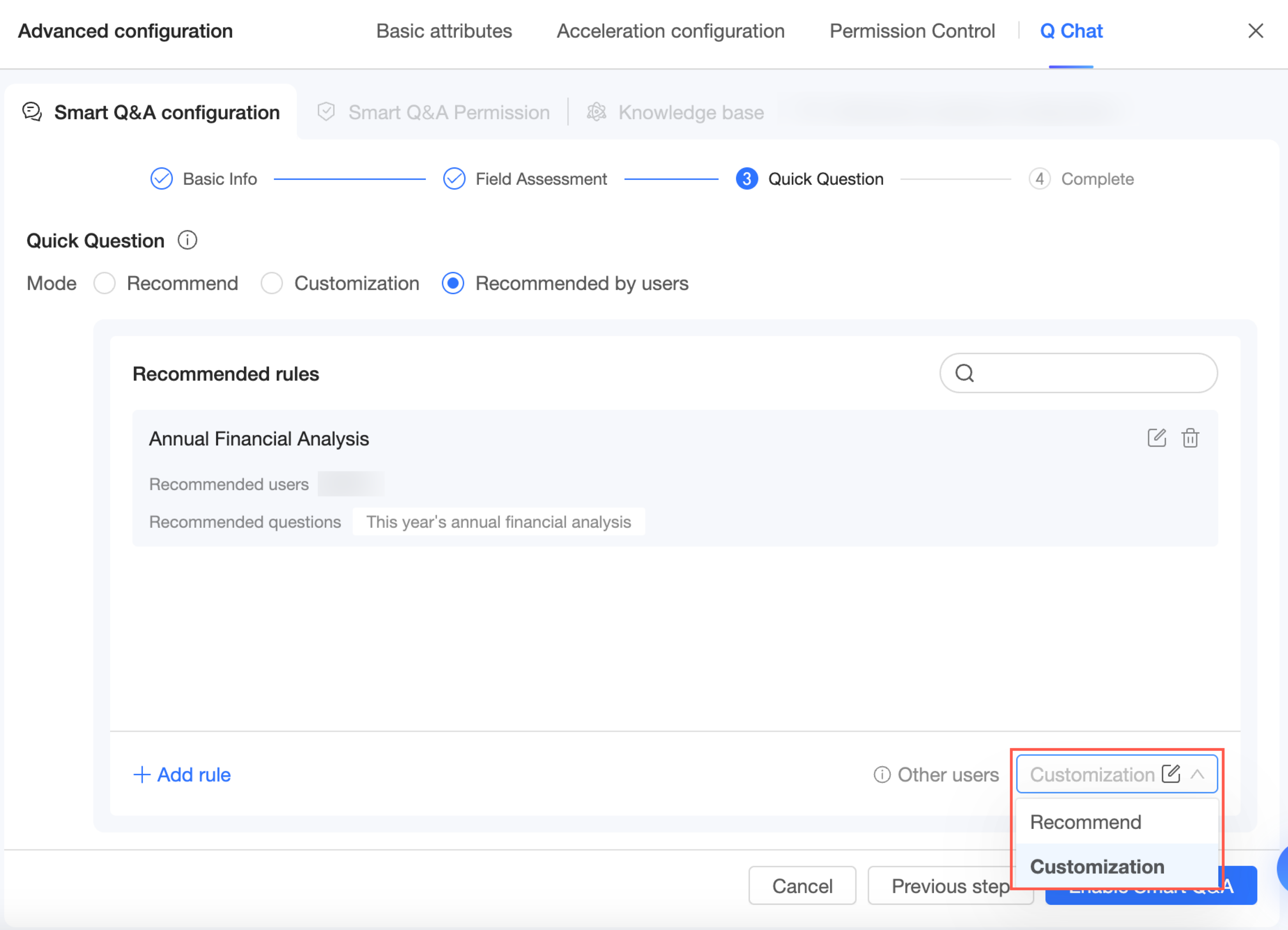
Klik Confirm Changes untuk menyimpan konfigurasi Anda.
Setelah menyelesaikan konfigurasi, Anda dapat mengklik Go to Quick BI Q Chat Permission Management atau mengklik tab Q Chat Permissions untuk menuju halaman konfigurasi Q Chat permission. Di halaman ini, Anda dapat memberikan akses pengguna ke dataset yang telah diaktifkan Q Chat ini. Untuk informasi lebih lanjut, lihat Q Chat permission configuration.
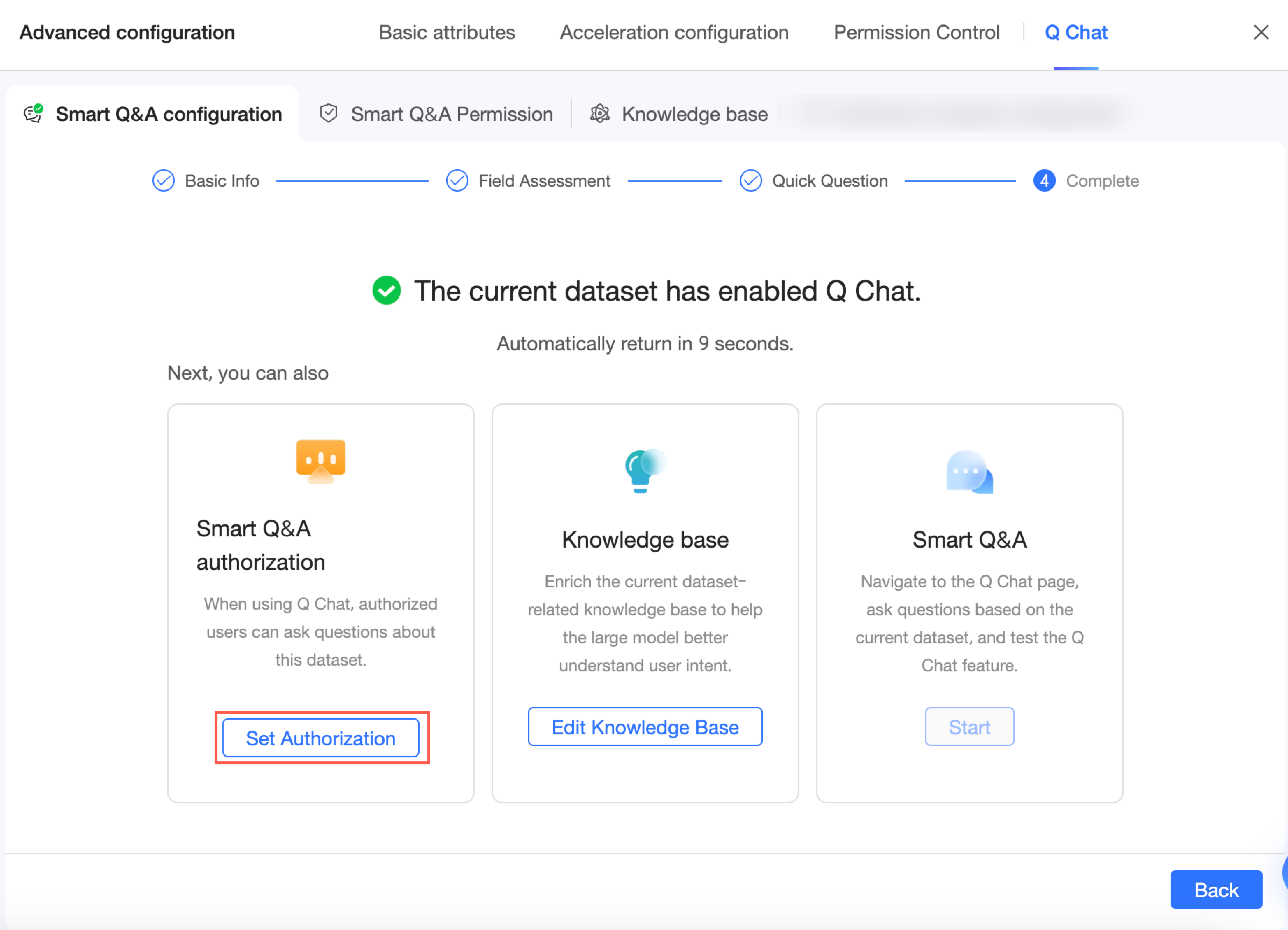
Q Chat permissions
Setelah mengonfigurasi pengaturan Q Chat, Anda dapat mengelola izin akses.
Buka halaman konfigurasi Q Chat Permissions.
Di halaman konfigurasi Q Chat Permissions, klik Add Authorization.
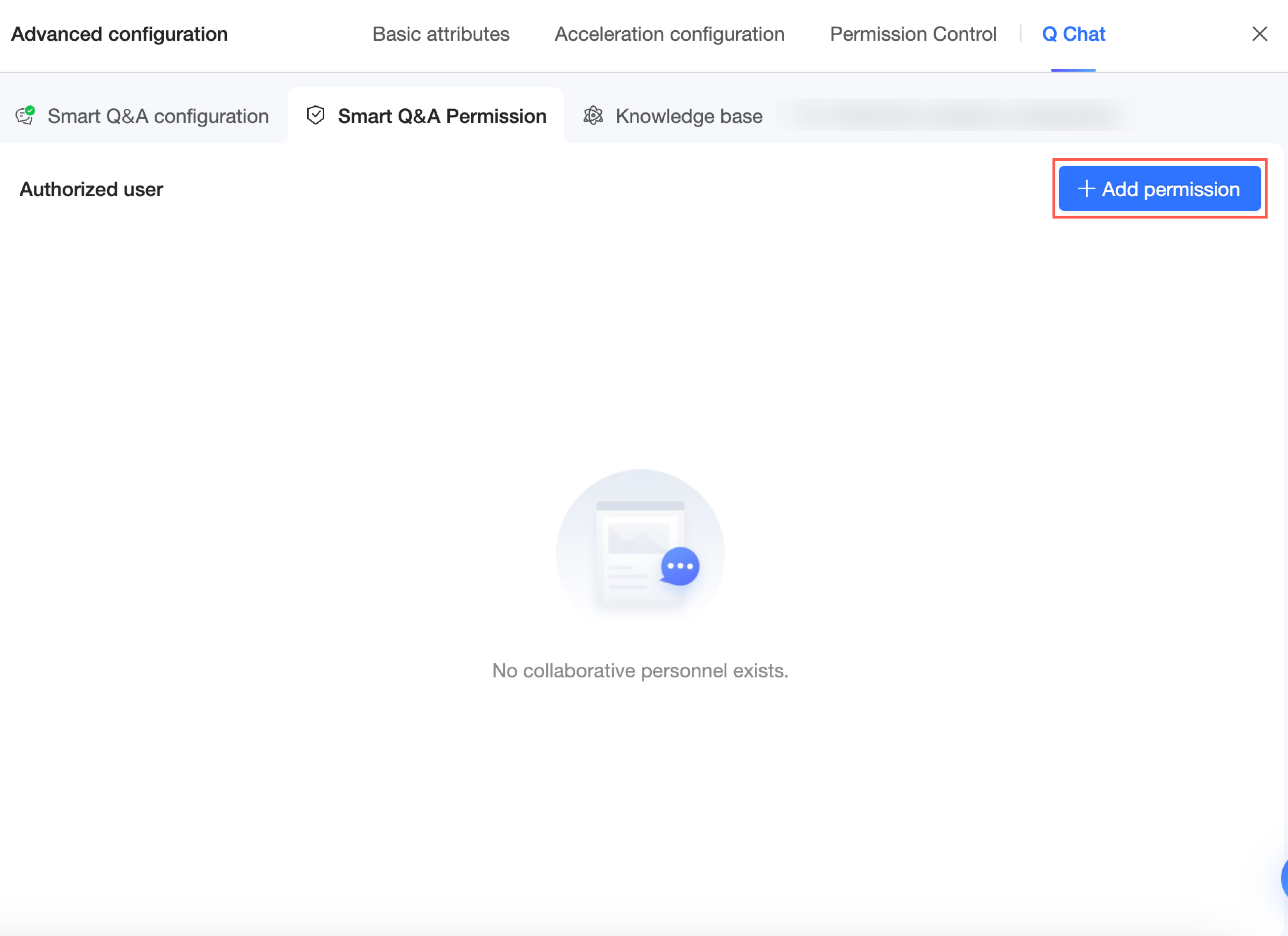
Atau, Anda juga dapat mengklik Add Authorization di halaman konfigurasi Q Chat dari langkah sebelumnya.
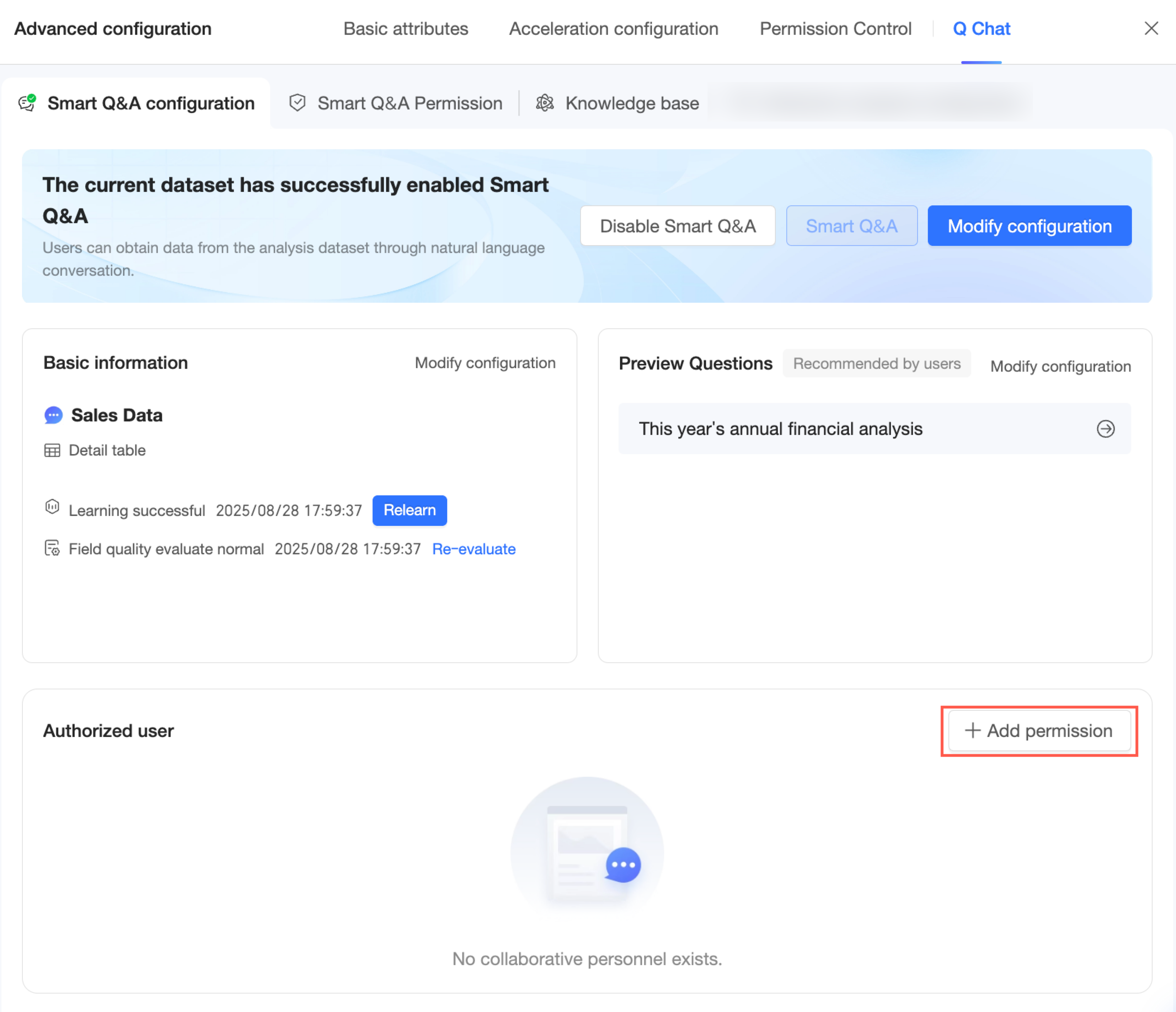
Pilih pengguna yang ingin Anda otorisasi. Anda juga dapat menetapkan tanggal kedaluwarsa untuk akses tersebut.
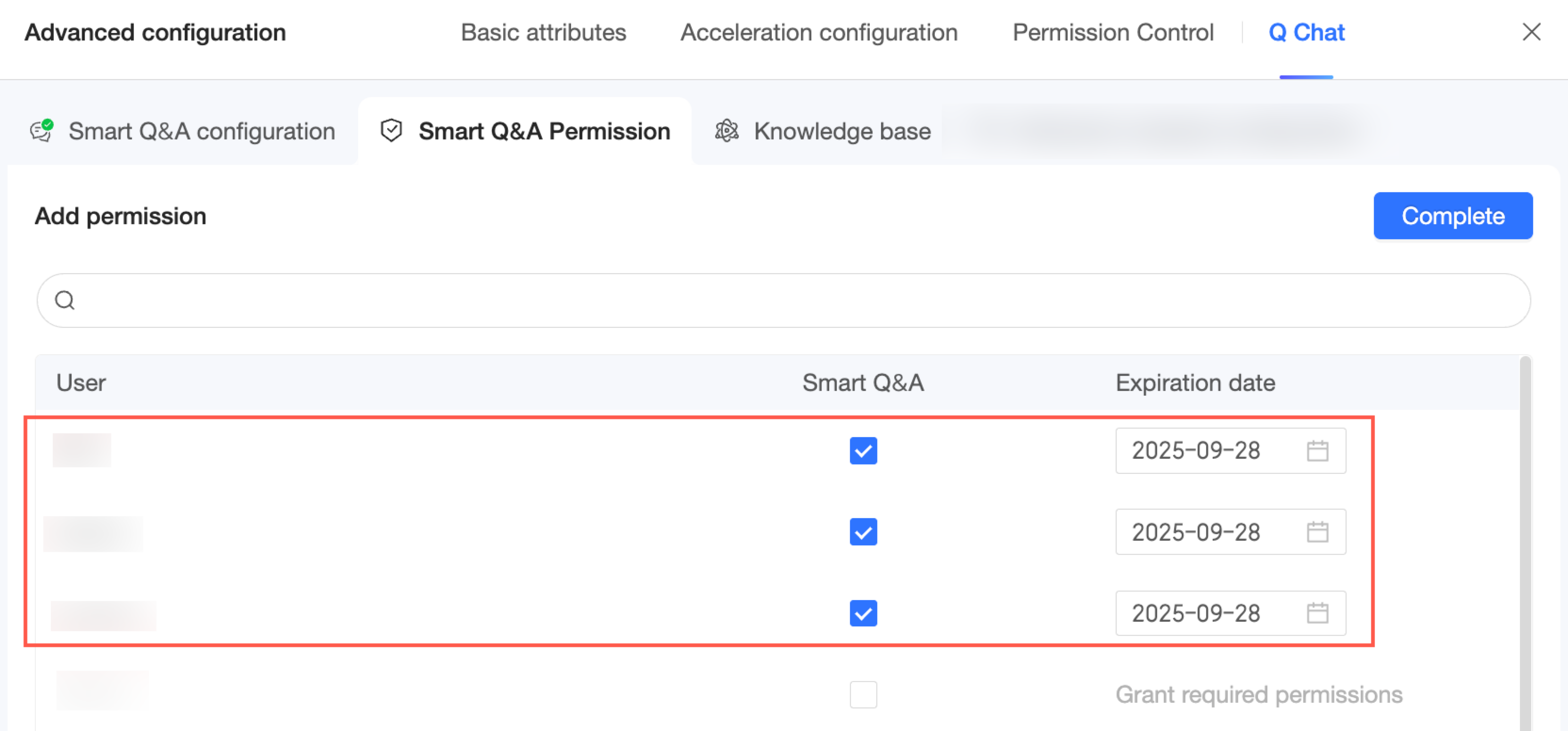
Klik Done. Anda sekarang dapat melihat dan mengelola daftar pengguna yang telah diotorisasi untuk dataset yang diaktifkan Q Chat ini.
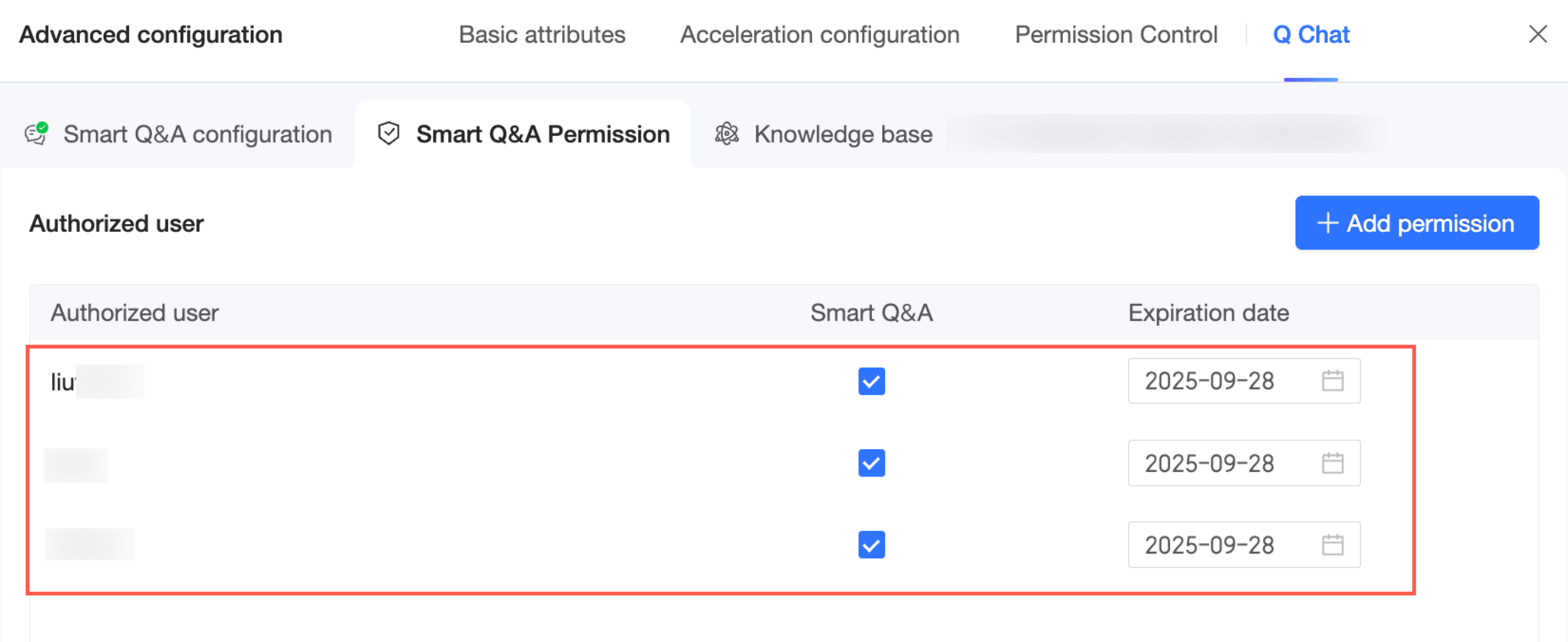
Jika Anda memiliki izin centralized management, Anda juga dapat mengelola izin di halaman Quick BI -> Permission Management. Untuk informasi lebih lanjut, lihat Permission Management.
Knowledge base
Basis pengetahuan menyimpan pengetahuan spesifik perusahaan dan preferensi kosakata. Setelah dikonfigurasi, model mempelajari informasi ini dan menggunakannya untuk pengambilan data dan analisis. Anda dapat mengelola basis pengetahuan dari halaman pengeditan dataset, tempat Anda dapat mengonfigurasi aturan Business Logic dan Regex Matching.
Basis pengetahuan dataset memiliki prioritas lebih tinggi daripada basis pengetahuan perusahaan. Untuk informasi lebih lanjut tentang pengelolaan basis pengetahuan perusahaan, lihat Q Chat Knowledge Management.
Access
Buka halaman Knowledge Base Management.
Business logic
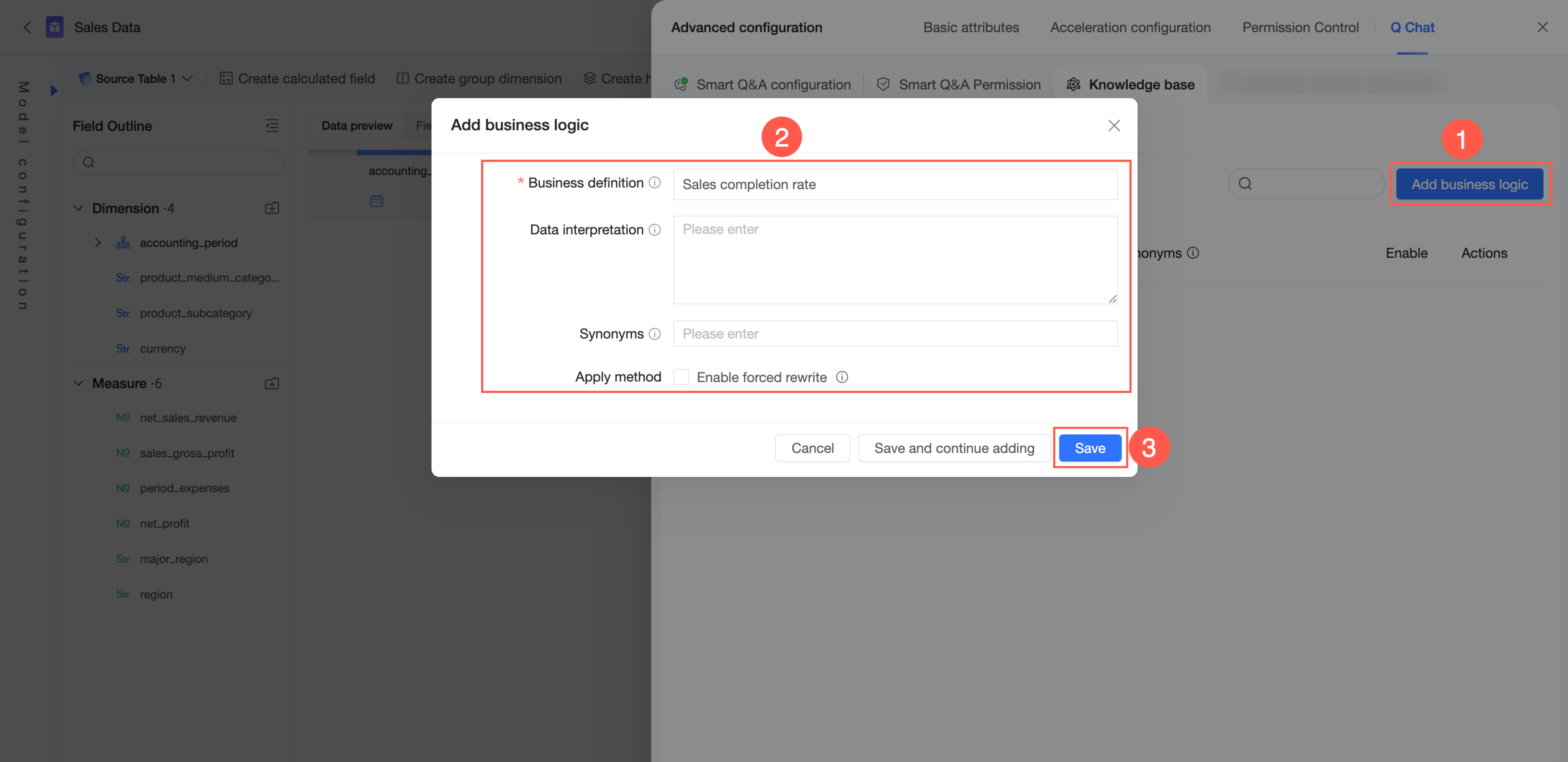
Di tab Knowledge Base Management -> From Current Dataset -> Business Logic, Anda dapat add business logic.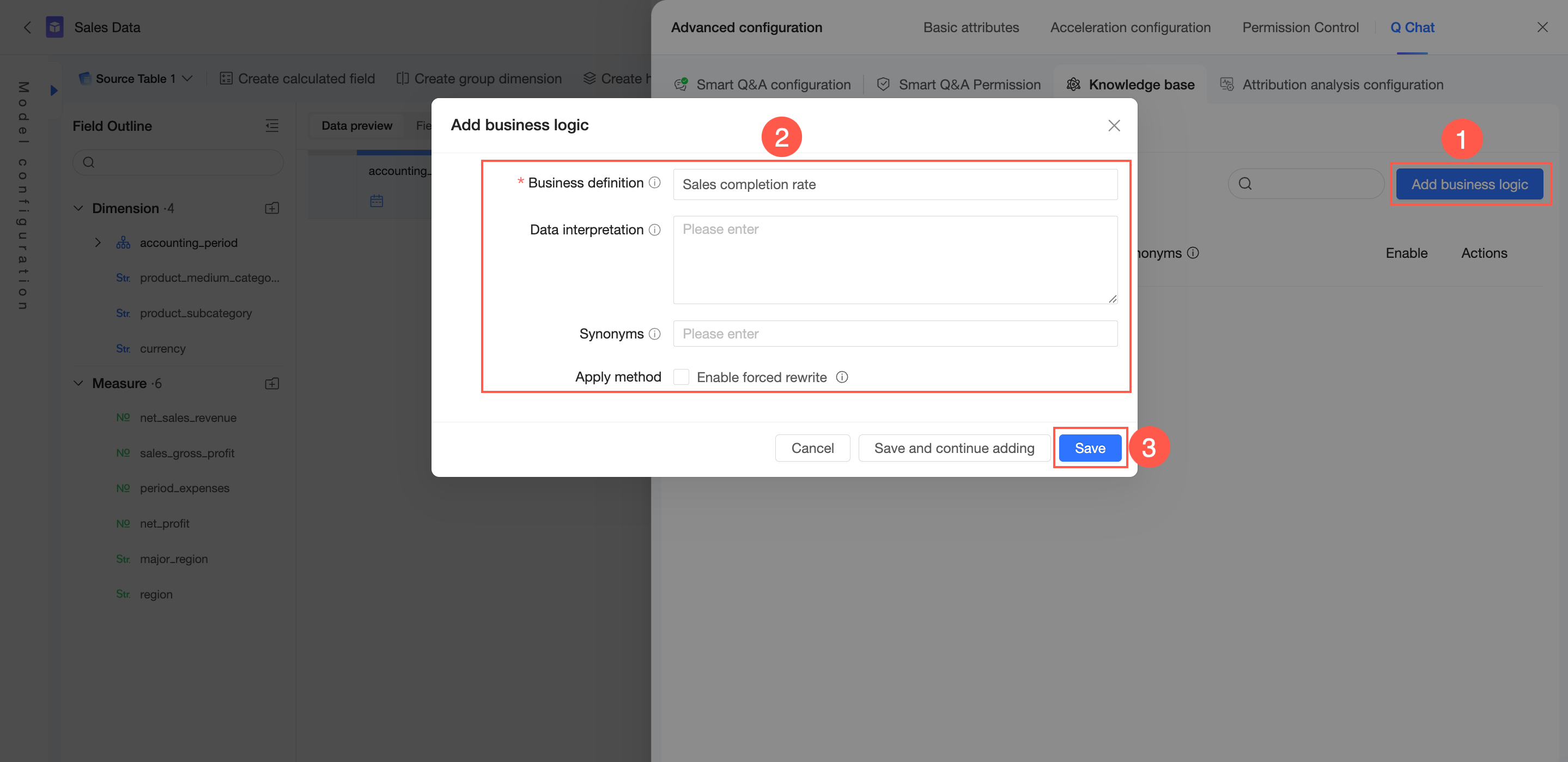
Di pojok kanan atas, klik Add Business Logic.
Konfigurasikan Business Definition, Data Interpretation, dan Synonyms. Di pengaturan lainnya, pilih apakah akan Enable Forced Rewriting.
Business definition: Mendefinisikan konsep bisnis umum dalam organisasi Anda, seperti "sales progress" atau "fiscal year". Bidang ini harus unik secara global dan memiliki panjang maksimum 100 karakter. Anda dapat memasukkan istilah kueri yang sering digunakan di sini.
Data interpretation: Memberikan penjelasan rinci tentang definisi bisnis dan mengaitkannya dengan ukuran data, membantu model mengidentifikasi dan memahami ukuran terkait. Panjang maksimum adalah 3.000 karakter.
Synonyms: Mendefinisikan nama alternatif untuk istilah bisnis yang digunakan dalam perusahaan Anda, memungkinkan model mengenali berbagai cara mengajukan pertanyaan yang sama.
Enable forced rewriting: Jika diaktifkan, setiap kueri pengguna yang sesuai dengan Business definition atau Synonyms-nya akan ditulis ulang menjadi konten di bidang Data interpretation. Gunakan opsi ini dengan hati-hati.
Klik Save.
Untuk menambahkan entri lain, klik Save and Continue Adding.
Regex matching
Pada tab Knowledge Base Management → From Current Dataset → Regex Matching, Anda dapat menambahkan aturan pencocokan regex.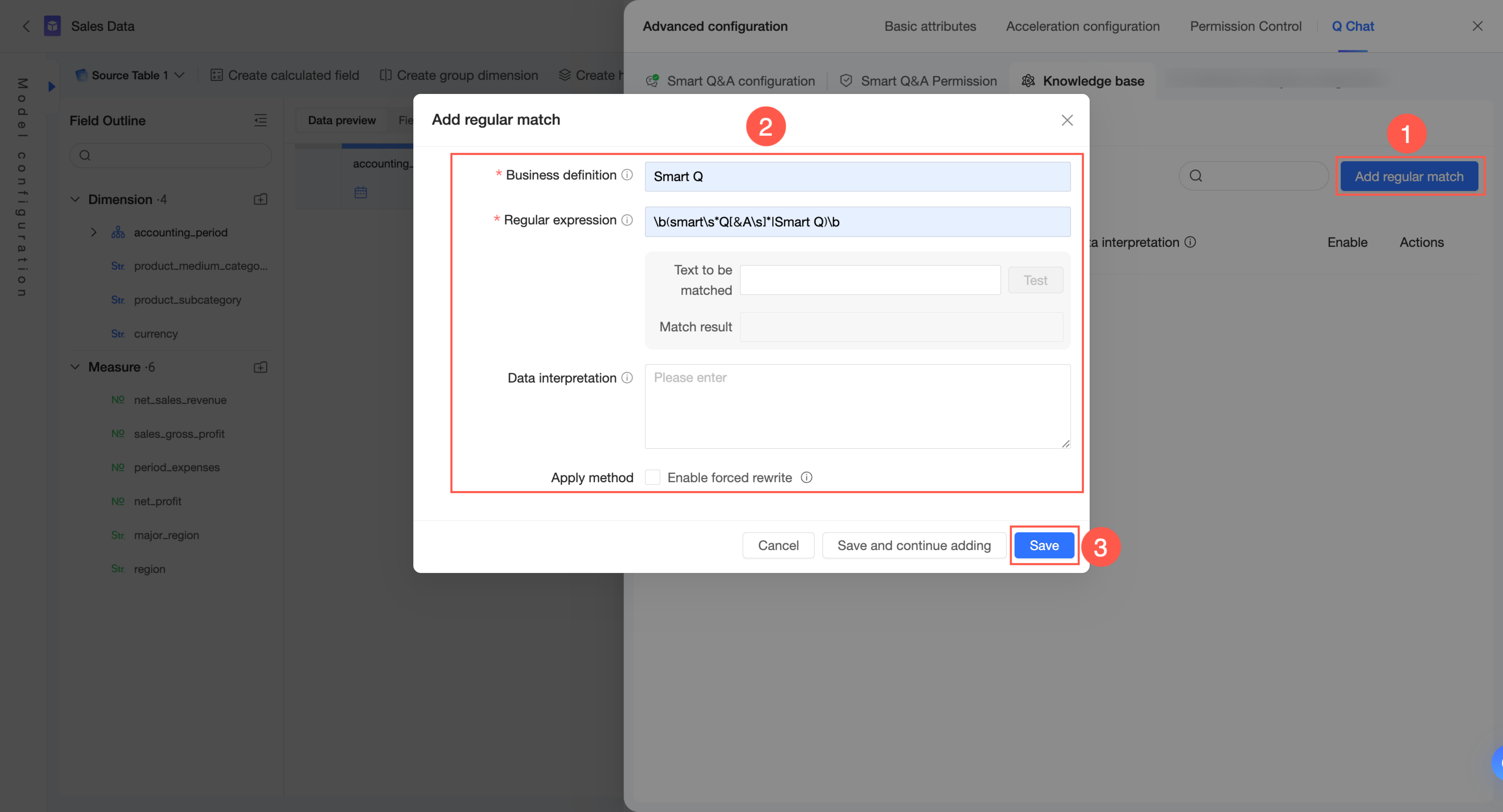
Di pojok kanan atas, klik Add Regex Matching.
Konfigurasikan Business Definition, Regular Expression, dan Data Interpretation. Di metode aplikasi, pilih apakah akan Enable Forced Rewriting.
Business definition: Hanya digunakan untuk memberi nama ekspresi reguler demi identifikasi dan tidak digunakan untuk mencocokkan pertanyaan pengguna. Nama ini harus unik dalam dataset dan memiliki panjang maksimum 100 karakter.
Regular expression: Digunakan untuk mengidentifikasi pola dalam pertanyaan pengguna dan melakukan aksi berdasarkan metode aplikasi. Tulis ekspresi dalam gaya Python, dengan panjang maksimum 100 karakter.
Anda dapat memasukkan teks yang cocok untuk menguji ekspresi dan melihat hasil kecocokan.
Data interpretation: Memberikan penjelasan spesifik untuk konten yang dicocokkan oleh ekspresi reguler. Konten ini dapat digunakan untuk menjelaskan atau menulis ulang konten yang dicocokkan, tergantung pada metode aplikasi.
Enable forced rewriting: Jika diaktifkan, bagian mana pun dari kueri pengguna yang cocok dengan Regular expression akan ditulis ulang menjadi konten di bidang Data interpretation. Gunakan opsi ini dengan hati-hati.
Klik Save.
Untuk menambahkan aturan lain, klik Save and Continue Adding.
Entry management
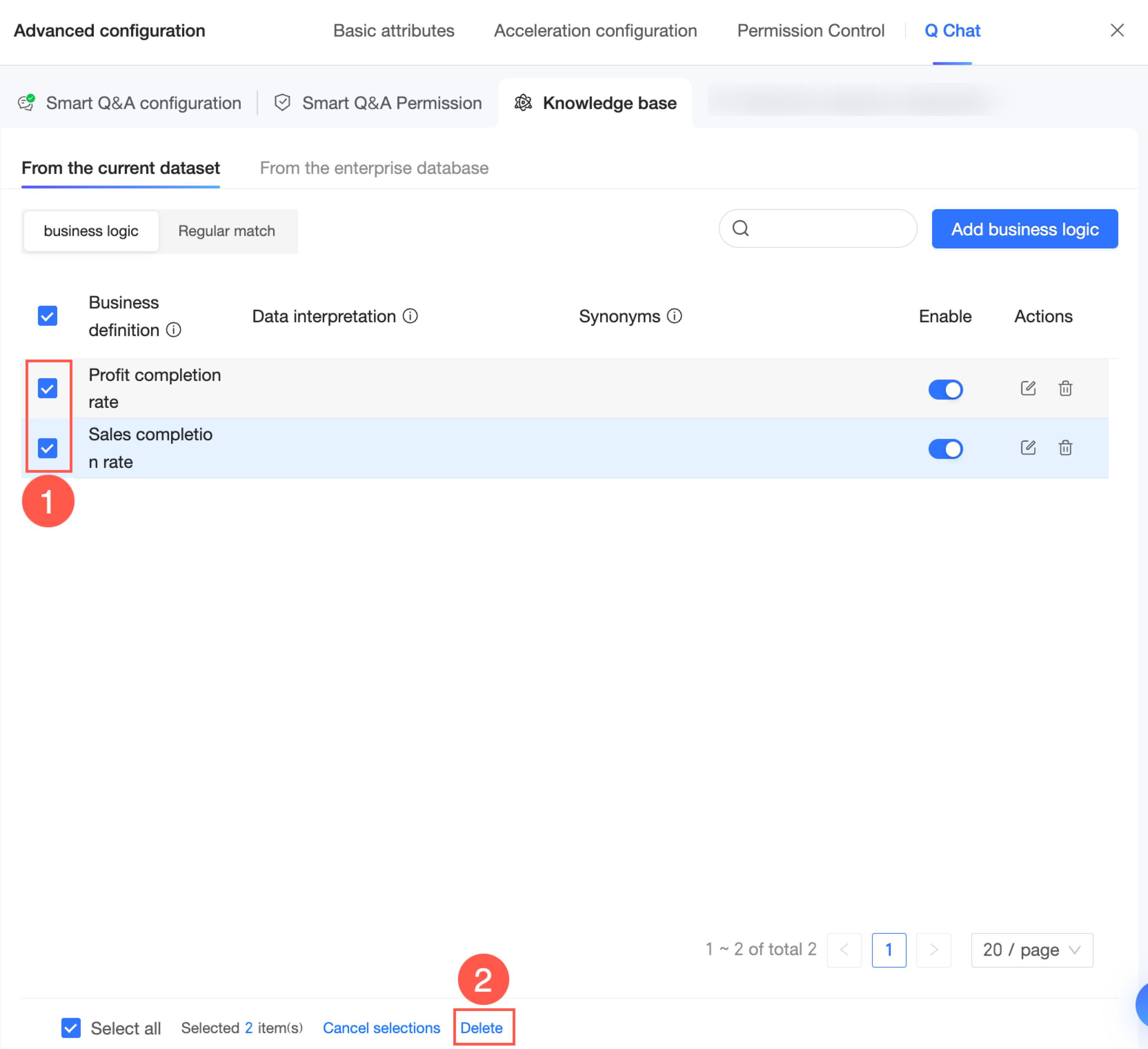
Di halaman Knowledge Base Management → From Current Dataset, Anda dapat mengelola basis pengetahuan.
Anda dapat melihat status aktif setiap entri di kolom Enabled.
Saat ikon entri berupa
 , entri tersebut aktif. Anda dapat mengklik ikon tersebut untuk menonaktifkannya.
, entri tersebut aktif. Anda dapat mengklik ikon tersebut untuk menonaktifkannya.Saat ikon entri berupa
 , entri tersebut nonaktif. Anda dapat mengklik ikon tersebut untuk mengaktifkannya.
, entri tersebut nonaktif. Anda dapat mengklik ikon tersebut untuk mengaktifkannya.
Klik ikon
 di sebelah kanan entri untuk mengeditnya.
di sebelah kanan entri untuk mengeditnya.Klik ikon
 di sebelah kanan entri untuk menghapusnya.
di sebelah kanan entri untuk menghapusnya.Anda juga dapat memilih beberapa entri dan menghapusnya secara batch.
Klik From Corporate Knowledge Base untuk melihat entri pengetahuan yang ditambahkan di basis pengetahuan perusahaan dan berlaku untuk dataset ini.
Quick BI insight
Di halaman pengeditan dataset, klik advanced settings dan pilih Quick BI insight untuk membuka halaman konfigurasi Quick BI insight.
Untuk petunjuk lengkap, lihat Quick BI insight.
Konfigurasi Dataset
Untuk atribut dimensi yang dapat dihitung, tetapkan metode agregasi default ke average. Hal ini mencegah perhitungan salah di kemudian hari.
Untuk atribut seperti harga, tinggi, dan lebar model mobil, yang mungkin melibatkan perhitungan agregat seperti maksimum, minimum, atau rata-rata, kami menyarankan memperlakukannya sebagai ukuran. Untuk mencegahnya secara otomatis dijumlahkan dalam kueri, menetapkan metode agregasi default ke average lebih logis. Contohnya: "Berapa jumlah penjualan untuk model mobil dengan harga di atas 300.000 dari masing-masing merek?"
Sertakan satuan dalam nama atau deskripsi bidang data untuk memastikan penyaringan yang benar.
Untuk kueri seperti "Berapa penjualan untuk merek dengan harga di atas 100.000?", jika satuan bidang harga adalah "sepuluh ribu", perhitungan backend akan menggunakan filter >10 alih-alih >100000.
Tambahkan bidang terhitung untuk dimensi yang sering dihitung. Versi saat ini tidak mendukung penghitungan langsung bidang dimensi sebagai ukuran.
Untuk kueri seperti "Pada tahun 2020, berapa banyak pelanggan yang memiliki penjualan di atas 10.000 di setiap provinsi?", membuat bidang terhitung dalam dataset memungkinkan jawaban yang benar. Sistem akan secara otomatis melakukan penghitungan distinct count berdasarkan kondisi perhitungan.
Ikuti prinsip dasar berikut untuk mengonfigurasi nama dan deskripsi bidang dataset.
Nama bidang:
Nama bidang harus jelas, terstandarisasi, dan mencerminkan cara pengguna mengajukan pertanyaan. Hindari nama bidang yang duplikat.
Jangan gunakan nama bahasa Inggris mentah dari sumber data dasar, dan hapus komentar yang tidak perlu.
Hindari memasukkan informasi waktu spesifik seperti "1 hari terakhir" dalam nama, karena dapat menyebabkan ambiguitas.
Jenis bidang: Untuk data tanggal/waktu, ubah jenis bidang menjadi jenis tanggal di dataset. Jika tidak, data tersebut tidak akan dikenali dengan benar. Jenis bidang lainnya, seperti dimensi geografis, juga harus diatur dengan benar.
Metode agregasi bidang: Untuk ukuran, pilih metode agregasi default yang sesuai. Ketika kueri pengguna tidak menentukan agregasi, model akan menggunakan pengaturan ini (misalnya, untuk "conversion rate", Anda dapat menetapkan default ke average berdasarkan semantik bisnis; untuk "cumulative XX", tetapkan default ke average atau maximum alih-alih sum).