Machine Learning Designer menyediakan berbagai komponen model untuk membantu Anda membangun dan men-debug model secara fleksibel dan terlihat. Topik ini menjelaskan cara membangun dan men-debug model menggunakan pipeline di Machine Learning Designer. Contoh yang digunakan adalah model prediksi penyakit jantung.
Prasyarat
Pipeline telah dibuat. Untuk informasi lebih lanjut, lihat Buat Pipeline.
Membangun Model
Model terdiri dari beberapa node tugas (komponen). Anda dapat mengatur node tugas menggunakan pipeline untuk membangun model sesuai kebutuhan bisnis. Sebelum membangun model, disarankan untuk merencanakan struktur model dan tugas node. Gunakan satu node untuk setiap tugas sederhana. Berikut adalah langkah-langkah membangun model:
Di halaman detail pipeline, temukan komponen yang diinginkan di daftar komponen di sebelah kiri dan seret komponen tersebut ke kanvas.
Komponen Alink memiliki tanda ungu, seperti komponen Read CSV File pada gambar berikut. Komponen Alink dapat berfungsi sebagai unit mandiri dan digabungkan menjadi grup. Mengonfigurasi sumber daya untuk grup meningkatkan efisiensi eksekusi dan pemanfaatan sumber daya. Untuk informasi lebih lanjut, lihat Komponen Alink.
Di sebelah kanan halaman, klik node yang diinginkan dan konfigurasikan parameter komponen.
Gambar garis antara node untuk membentuk hubungan hulu dan hilir. Proses ini menciptakan pipeline.
Setiap node memiliki satu atau lebih port input atau output. Gerakkan pointer di atas port komponen untuk melihat tipe data port dan gambar garis antara komponen berdasarkan tipe data port.
Saat menjalankan pipeline, node pipeline dijalankan secara berurutan. Node hilir hanya dapat dijalankan setelah semua node hulu selesai dijalankan.
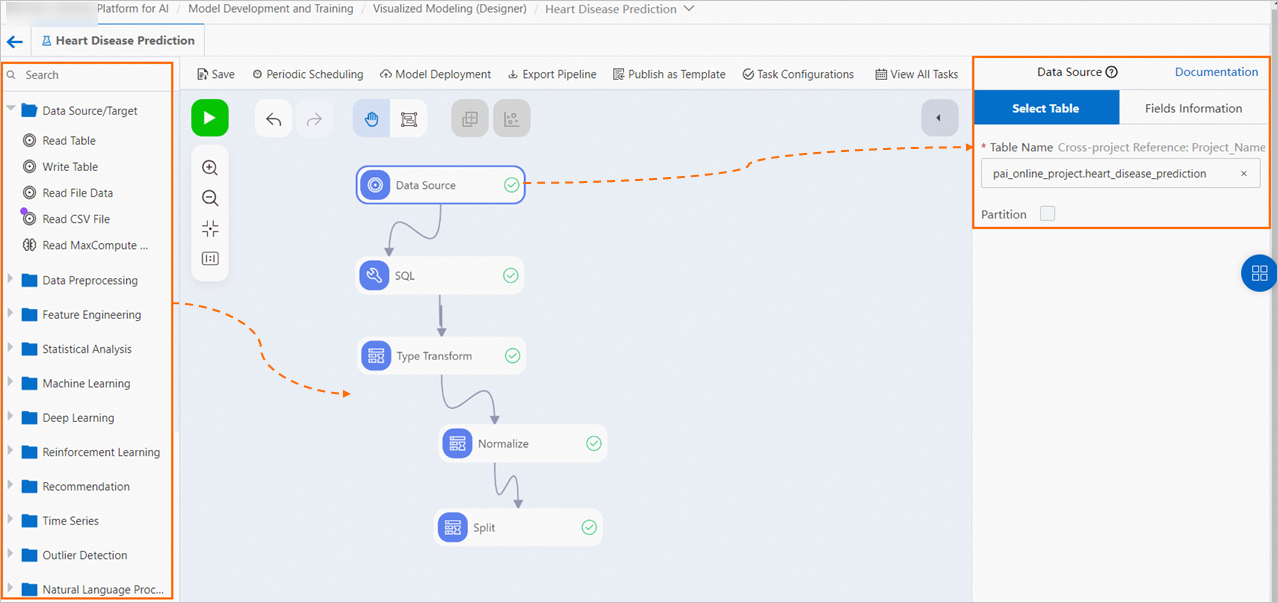
Secara umum, model mencakup modul berikut:
Baca Data
Tambahkan komponen sumber data atau tujuan ke pipeline untuk membaca data dari tabel MaxCompute atau bucket Object Storage Service (OSS). Untuk informasi lebih lanjut, lihat Referensi Komponen: Sumber Data atau Tujuan. Dalam contoh ini, data MaxCompute digunakan sebagai sumber data.
Buat tabel MaxCompute dan impor data ke dalam tabel. Untuk informasi lebih lanjut, lihat Buat dan Kelola Tabel MaxCompute.
Dalam contoh ini, tabel heartdisease dibuat di proyek uji dan data uji diimpor.
-- Buat tabel. CREATE TABLE IF NOT EXISTS heartdisease( age STRING COMMENT 'Usia pasien. ', sex STRING COMMENT 'Jenis kelamin pasien. Nilai valid: female dan male. ', Jenis nyeri dada pasien. Nilai valid: typical, atypical, non-anginal, dan asymptomatic. ', trestbps STRING COMMENT 'Tingkat tekanan darah istirahat pasien. ', chol STRING COMMENT 'Tingkat kolesterol serum pasien. ', fbs STRING COMMENT 'Tingkat gula darah puasa pasien. Jika tingkat gula darah puasa lebih besar dari 120 mg/dl, nilainya disetel ke true. Jika tidak, nilainya disetel ke false. ', restecg STRING COMMENT 'Hasil elektrokardiogram (ECG) istirahat pasien. Nilai valid: norm dan hyp. ', thalach STRING COMMENT ‘Jumlah maksimum detak jantung. ', exang STRING COMMENT ’Menentukan apakah pasien memiliki angina yang diinduksi oleh olahraga. Nilai valid: true dan false. ', oldpeak STRING COMMENT 'Depresi ST yang diinduksi oleh olahraga relatif terhadap istirahat. ', slop STRING COMMENT 'Kemiringan segmen ST latihan puncak. Nilai valid: down, flat, dan up. ', ca STRING COMMENT 'Jumlah pembuluh utama yang diwarnai menggunakan fluoroskopi. ', thal STRING COMMENT 'Jenis cacat pasien. Nilai valid: norm, fix, dan rev. ', `status` STRING COMMENT 'Keberadaan penyakit jantung pada pasien. Nilai valid: buff (sehat) dan sick (tidak sehat). ', style STRING); -- Ini hanya contoh. Anda dapat langsung mengimpor data uji publik dari PAI. INSERT INTO heartdisease select * from pai_online_project.heart_disease_prediction;Seret komponen Read Table ke kanvas di sebelah kanan untuk membaca data dari tabel MaxCompute.
Node bernama Read Table-1 secara otomatis dibuat di kanvas. Angka dalam nama mengikuti urutan komponen yang sama diseret ke kanvas.
Di halaman konfigurasi node, tentukan nama untuk tabel sumber. Untuk informasi lebih lanjut, lihat Read Table.
Di kanvas, klik komponen Read Table-1. Di halaman konfigurasi node di sebelah kanan, tentukan nama untuk tabel MaxCompute di bidang Table Name. Dalam contoh ini, masukkan
heartdisease.CatatanUntuk membaca data dari tabel lintas proyek MaxCompute, masukkan nama tabel dalam format
Nama proyek.Nama tabel. Contoh: as test2.heartdisease. Pastikan Anda memiliki izin proyek.Di sebelah kanan kanvas, klik tab Fields Information untuk melihat detail kolom dalam data publik.
Praproses Data
Setelah data dibaca, praproses data diperlukan untuk memenuhi persyaratan input untuk pelatihan atau prediksi model. Machine Learning Designer menyediakan berbagai komponen praproses data dan praproses data model besar.
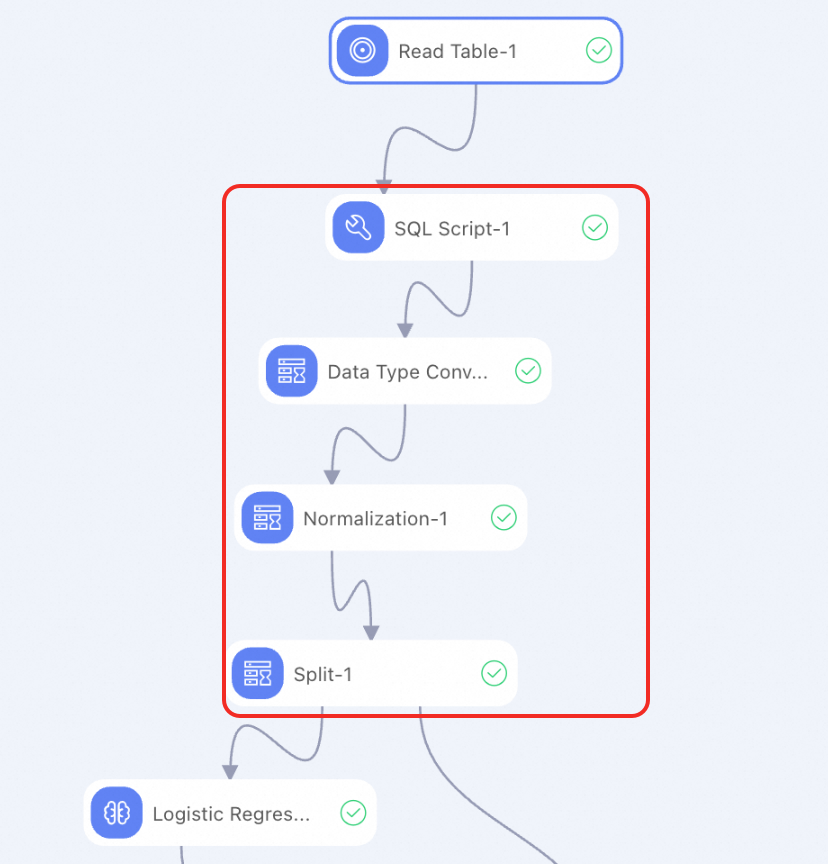
Anda juga dapat menggunakan komponen SQL Script untuk menyiapkan skrip SQL kustom yang digunakan untuk mengimplementasikan fitur. Skrip berikut menunjukkan contoh cara mengonversi tipe data untuk fitur input:
select age,
(case sex when 'male' then 1 else 0 end) as sex,
(case cp when 'angina' then 0 when 'notang' then 1 else 2 end) as cp,
trestbps,
chol,
(case fbs when 'true' then 1 else 0 end) as fbs,
(case restecg when 'norm' then 0 when 'abn' then 1 else 2 end) as restecg,
thalach,
(case exang when 'true' then 1 else 0 end) as exang,
oldpeak,
(case slop when 'up' then 0 when 'flat' then 1 else 2 end) as slop,
ca,
(case thal when 'norm' then 0 when 'fix' then 1 else 2 end) as thal,
(case status when 'sick' then 1 else 0 end) as ifHealth
from ${t1};Pelatihan Model
Komponen model menerima data yang telah dipraproses di hulu dan menghubungkan komponen, seperti komponen prediksi atau inferensi, di hilir. Komponen model mungkin memiliki satu atau lebih port input atau output. Gerakkan pointer di atas port komponen untuk melihat tipe data port dan gambar garis antara komponen berdasarkan tipe data port.
Dalam contoh ini, komponen Logistic Regression for Binary Classification digunakan. Komponen ini memiliki dua port output.
Model regresi logistik: Port output model yang dilatih dapat digunakan sebagai input hasil model komponen prediksi.
PMML: Penyebaran model bergantung pada model Predictive Model Markup Language (PMML). Misalnya, jika Anda ingin menyebarkan model yang dihasilkan menggunakan prosesor bawaan seperti Prosesor PMML, Anda harus memilih Whether To Generate PMML dalam konfigurasi parameter komponen model sebelum menjalankan komponen.

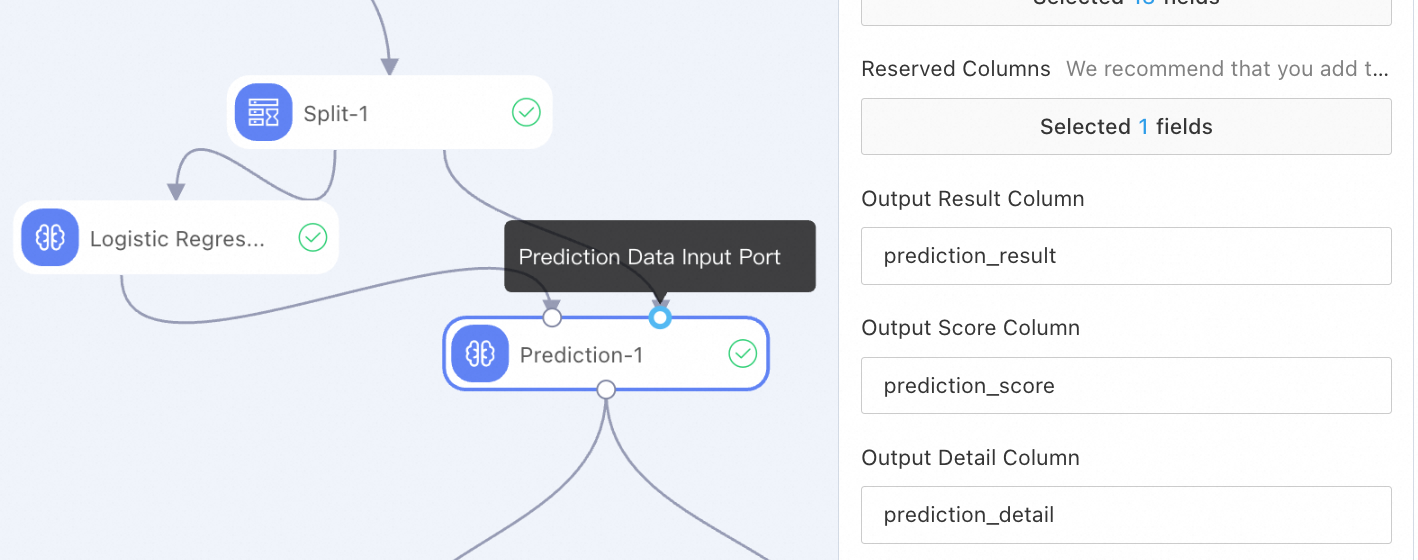
Lakukan Prediksi atau Inferensi Model
Setelah melatih model, hubungkan komponen prediksi atau inferensi untuk menguji kinerja model.
Dalam contoh ini, komponen prediksi digunakan. Komponen prediksi memiliki dua port input.
Input hasil model: Model yang dilatih digunakan sebagai input.
Input data prediksi: Data uji yang telah dipraproses digunakan sebagai input.
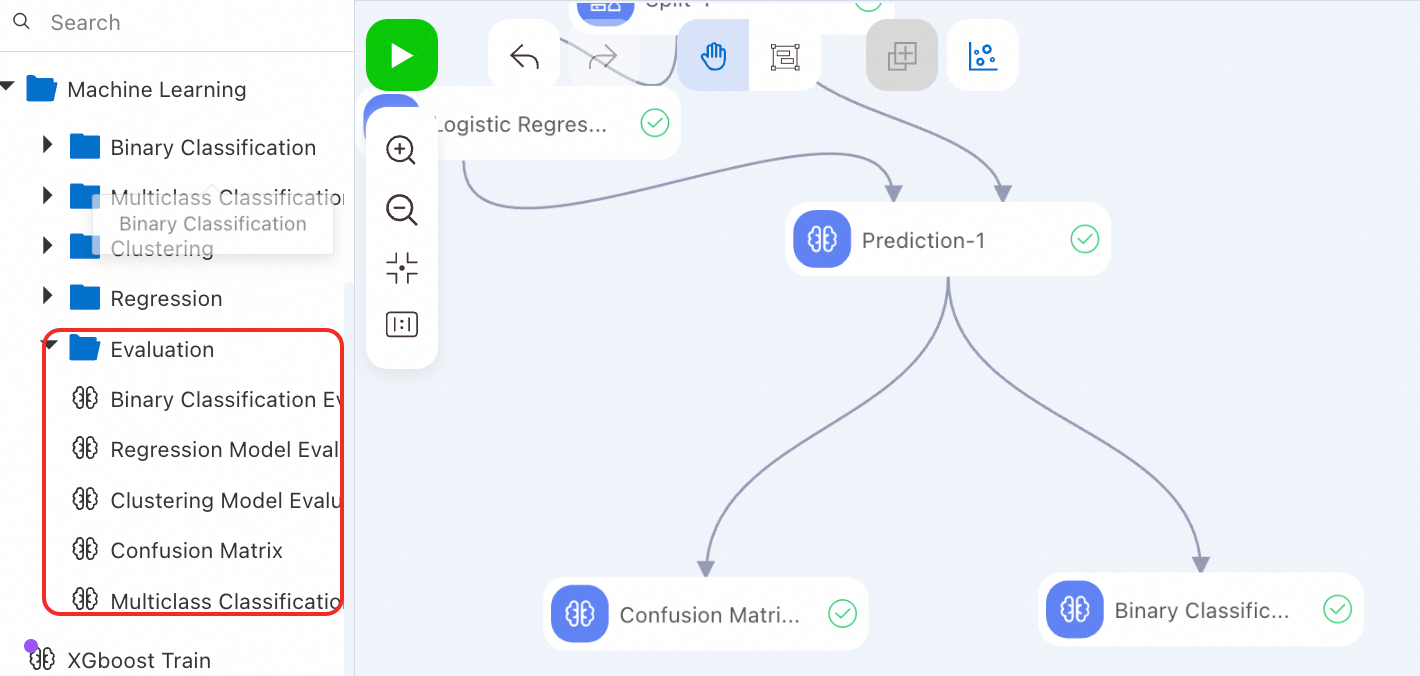
Evaluasi Model
Model tertentu menyediakan komponen evaluasi. Anda dapat menggunakan komponen evaluasi yang sesuai untuk menganalisis kinerja model menggunakan metrik terkait.
Sebagai contoh, Machine Learning menyediakan komponen evaluasi berikut, yang dapat Anda gunakan sebagai komponen hilir komponen prediksi:
Debug Model
Debug Berjalan
Pipeline: Klik ikon
 di sudut kiri atas kanvas untuk langsung menjalankan pipeline. Jika pipeline kompleks, disarankan untuk menjalankan satu atau lebih node per modul untuk memudahkan debugging.
di sudut kiri atas kanvas untuk langsung menjalankan pipeline. Jika pipeline kompleks, disarankan untuk menjalankan satu atau lebih node per modul untuk memudahkan debugging.Satu atau beberapa komponen: Klik kanan komponen yang diinginkan untuk menjalankan satu atau lebih komponen. Beberapa metode menjalankan didukung.
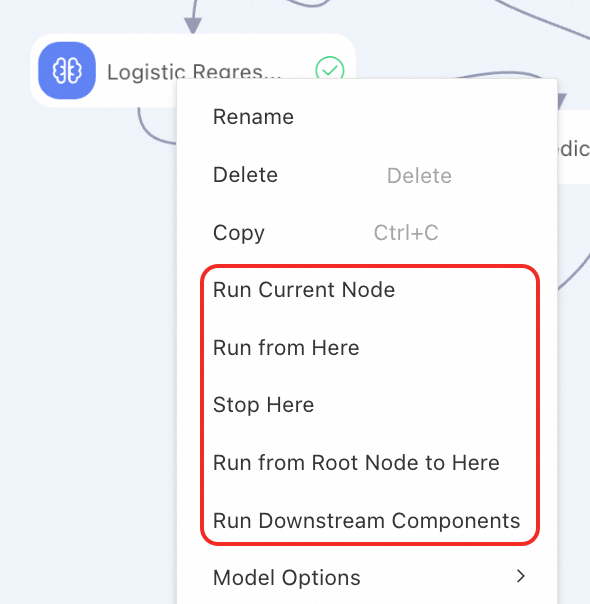
Jika komponen berjalan sesuai harapan, ikon ![]() muncul. Jika komponen gagal berjalan, ikon
muncul. Jika komponen gagal berjalan, ikon ![]() muncul. Anda dapat klik kanan komponen untuk melihat log dan hasil.
muncul. Anda dapat klik kanan komponen untuk melihat log dan hasil.
Lihat Log dan Hasil
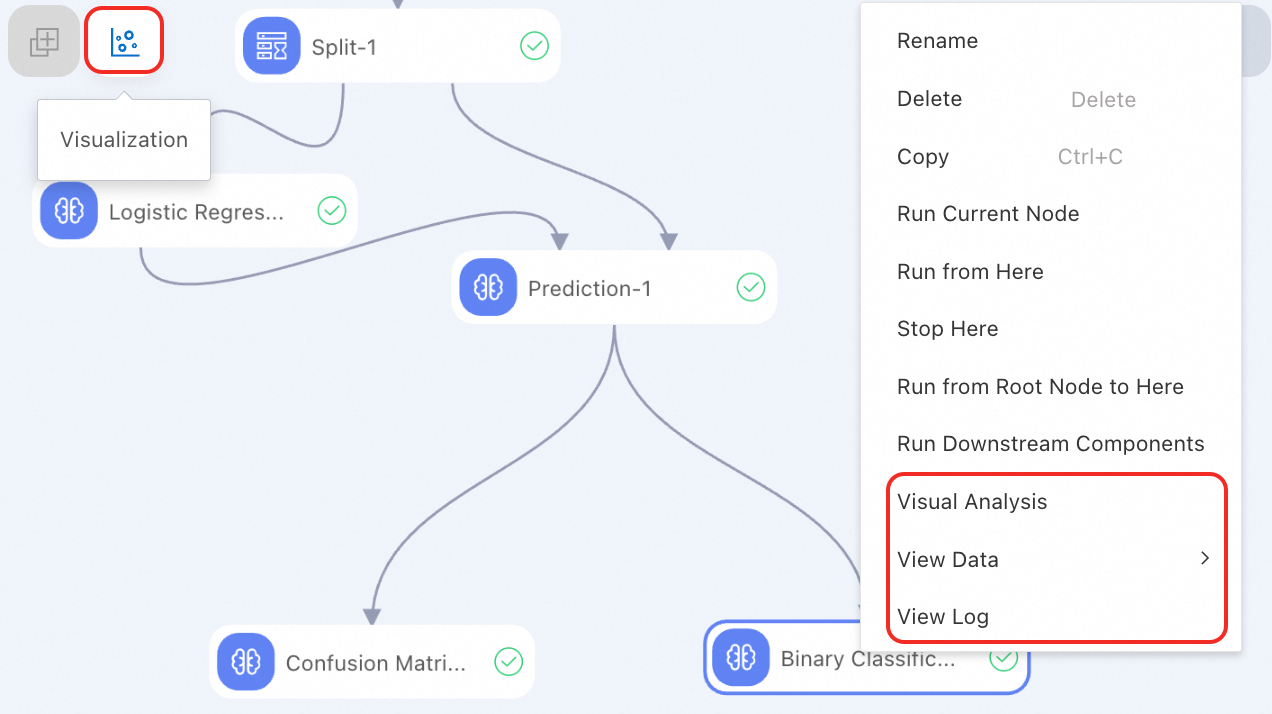
Lihat data dan analisis visual:
Setelah komponen berjalan, Anda dapat klik kanan komponen dan pilih View Data untuk melihat data yang dihasilkan.
Untuk komponen tertentu, Machine Learning Designer memungkinkan Anda mengonversi data menjadi grafik dan bagan untuk menampilkan data dan hasil analisis yang kompleks secara intuitif dan mudah dipahami. Ini membantu Anda dengan cepat mendapatkan informasi penting dan mengidentifikasi tren dan pola untuk analisis dan pengambilan keputusan yang lebih efisien. Untuk menganalisis data secara visual, Anda dapat klik kanan komponen dan pilih Visual Analysis atau klik ikon visualisasi di bagian atas kanvas. Untuk informasi lebih lanjut, lihat Analisis Terlihat.
Lihat log: Jika komponen gagal berjalan, Anda dapat klik kanan komponen dan pilih View Log untuk memecahkan masalah kegagalan.
Lihat Tugas Berjalan
Di sudut kanan atas kanvas, klik View All Tasks untuk melihat detail berjalan dari semua tugas historis. Setiap run dicatat sebagai tugas historis selama pemodelan. Setiap tugas historis mencatat node yang terlibat dalam run, konfigurasi node, dan data yang dihasilkan.
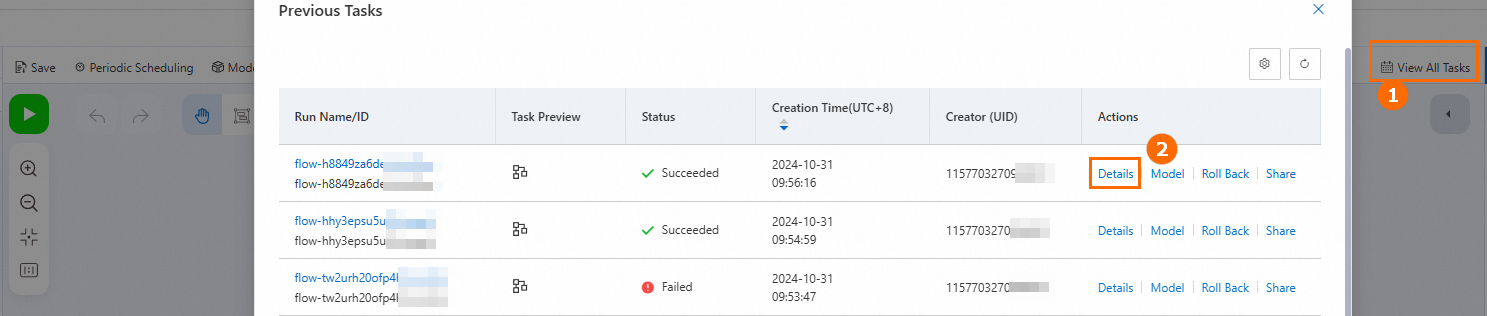
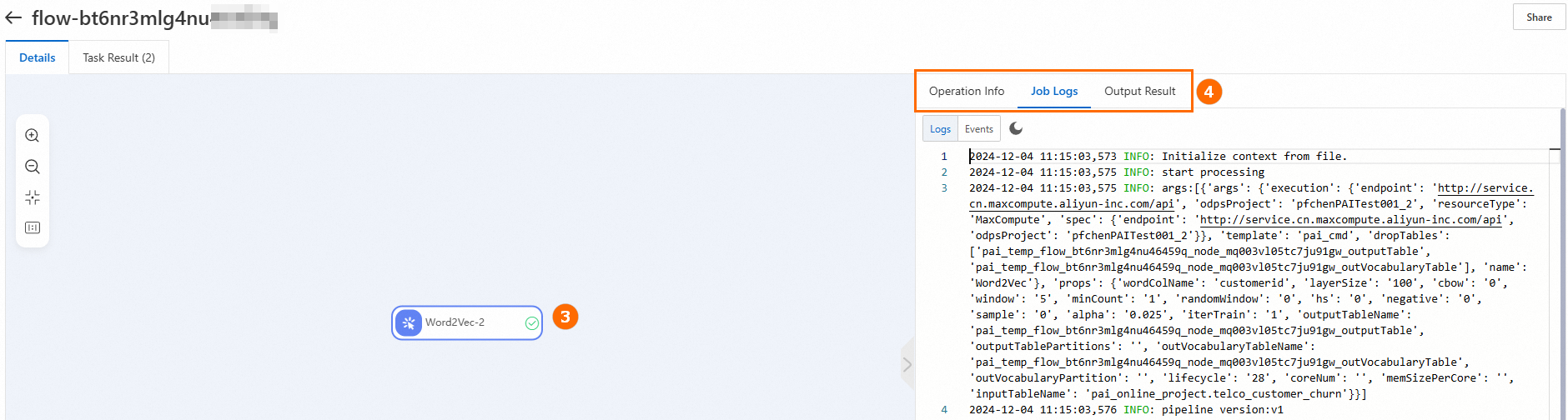
Sebelum melakukan rollback versi, disarankan untuk melihat detail tugas historis dan memeriksa apakah versinya benar. Kami juga menyarankan Anda menyimpan dan menjalankan pipeline model sebelum melakukan rollback. Ini menghasilkan catatan tugas yang berisi status terbaru. Jika pengecualian terjadi selama rollback, Anda dapat rollback pipeline model ke status terbaru.
Referensi
Setelah debug model, Anda dapat mendaftarkan model yang telah dilatih sebagai model baru dan mengelola model. Untuk informasi lebih lanjut, lihat Daftarkan dan Kelola Model.
Setelah debug model, Anda dapat menyebarkan model dan melakukan prediksi model online. Untuk informasi lebih lanjut, lihat Prediksi dan Penyebaran Model.
Setelah menyebarkan layanan model, Anda dapat menggunakan komponen Update EAS Service (Beta) yang disediakan oleh Machine Learning Designer untuk memperbarui layanan model secara berkala. Untuk informasi lebih lanjut, lihat Perbarui Layanan Model Online Secara Berkala.
DataWorks memungkinkan Anda menjadwalkan alur kerja offline dan memperbarui model secara berkala. Untuk informasi lebih lanjut, lihat Gunakan Tugas DataWorks untuk Menjadwalkan Pipeline di Machine Learning Designer.
Untuk informasi tentang komponen lainnya, lihat Ikhtisar Komponen Designer.
Untuk informasi tentang penagihan Machine Learning Designer, lihat Penagihan Machine Learning Designer.