Komponen Prediction menerapkan model yang telah dilatih ke data baru dan menuliskan hasilnya ke tabel output. Gunakan komponen ini jika model Anda dilatih menggunakan komponen penambangan data tradisional yang tidak memiliki komponen prediksi berpasangan.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
Model yang telah dilatih di Machine Learning Designer
Tabel input dengan kolom fitur yang sesuai dengan yang diharapkan oleh model
Konfigurasi komponen
Metode 1: Konfigurasi di Machine Learning Designer
Pada kanvas pipeline di Konsol Machine Learning Platform for AI (PAI), pilih komponen Prediction dan konfigurasikan parameter berikut.
Fields Setting tab
| Parameter | Deskripsi |
|---|---|
| Feature columns | Kolom fitur yang dipilih dari tabel input. Secara default, semua kolom dipilih. |
| Reserved columns | Kolom yang diteruskan ke tabel output. Sertakan kolom label untuk mempermudah evaluasi di tahap selanjutnya. |
| Output result column | Kolom output yang berisi hasil prediksi utama. |
| Output score column | Kolom output yang berisi probabilitas dari hasil prediksi utama. |
| Output detail column | Kolom output yang berisi semua hasil yang mungkin beserta probabilitasnya. |
| Sparse matrix | Aktifkan jika data input dalam format sparse (pasangan kunci-nilai). |
| KV delimiter | Pembatas antara kunci dan nilai pada data sparse. Default: titik dua (:). |
| KV pair delimiter | Pembatas antara pasangan kunci-nilai pada data sparse. Default: koma (,). |
Tuning tab
| Parameter | Deskripsi |
|---|---|
| Cores | Jumlah core. Harus berupa bilangan bulat positif. Gunakan bersama dengan Memory size per core. |
| Memory size per core | Memori per core, dalam MB. Gunakan bersama dengan Cores. |
Metode 2: Jalankan perintah PAI
Jalankan perintah berikut menggunakan komponen SQL Script:
pai -name prediction
-DmodelName=nb_model
-DinputTableName=wpbc
-DoutputTableName=wpbc_pred
-DappendColNames=label;Parameter
| Parameter | Wajib | Deskripsi | Default |
|---|---|---|---|
inputTableName | Ya | Nama tabel input. | — |
modelName | Ya | Nama model yang telah dilatih. | — |
outputTableName | Ya | Nama tabel output. | — |
featureColNames | Tidak | Kolom fitur dari tabel input, dipisahkan dengan koma. | Semua kolom |
appendColNames | Tidak | Kolom input yang ditambahkan ke tabel output. | Tidak ada |
inputTablePartitions | Tidak | Partisi yang dibaca dari tabel input. Format yang didukung: partition_name=value untuk satu partisi, name1=value1/name2=value2 untuk partisi multi-level. Pisahkan beberapa partisi dengan koma. | Seluruh tabel |
outputTablePartition | Tidak | Partisi tempat hasil ditulis di tabel output. | Tidak ada |
resultColName | Tidak | Kolom output untuk hasil prediksi utama. | prediction_result |
scoreColName | Tidak | Kolom output untuk probabilitas hasil prediksi utama. | prediction_score |
detailColName | Tidak | Kolom output untuk semua hasil yang mungkin beserta probabilitasnya. | prediction_detail |
enableSparse | Tidak | Apakah data input berformat sparse. Nilai yang valid: true, false. | false |
itemDelimiter | Tidak | Pembatas antara pasangan kunci-nilai sparse. | , |
kvDelimiter | Tidak | Pembatas antara kunci dan nilai sparse. | : |
lifecycle | Tidak | Siklus hidup tabel output. | Tidak ada |
coreNum | Tidak | Jumlah core. | Dialokasikan secara otomatis |
memSizePerCore | Tidak | Memori per core, dalam MB. | Dialokasikan secara otomatis |
Contoh
Contoh ini membangun klasifikasi random forest dan menjalankan Prediction pada data yang sama.
Buat tabel input uji coba:
create table pai_rf_test_input as select * from ( select 1 as f0,2 as f1, "good" as class union all select 1 as f0,3 as f1, "good" as class union all select 1 as f0,4 as f1, "bad" as class union all select 0 as f0,3 as f1, "good" as class union all select 0 as f0,4 as f1, "bad" as class )tmp;Lakukan pelatihan model menggunakan algoritma random forest:
PAI -name randomforests -project algo_public -DinputTableName="pai_rf_test_input" -DmodelName="pai_rf_test_model" -DforceCategorical="f1" -DlabelColName="class" -DfeatureColNames="f0,f1" -DmaxRecordSize="100000" -DminNumPer="0" -DminNumObj="2" -DtreeNum="3";Jalankan Prediction terhadap model yang telah dilatih:
PAI -name prediction -project algo_public -DinputTableName=pai_rf_test_input -DmodelName=pai_rf_test_model -DresultColName=prediction_result -DscoreColName=prediction_score -DdetailColName=prediction_detail -DoutputTableName=pai_temp_2283_76333_1Lihat tabel output
pai_temp_2283_76333_1: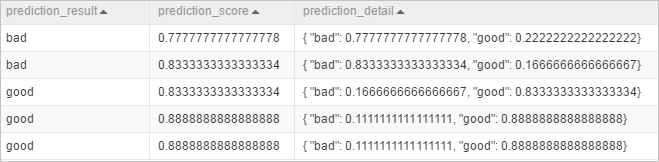
Tabel output berisi tiga kolom:
prediction_result: hasil prediksi utama (kelas dengan probabilitas tertinggi). Pada contoh ini, nilainya adalahgoodataubad.prediction_score: probabilitas dari hasil prediksi utama. Pada contoh ini, hasil prediksi berupa good atau bad, tergantung pada probabilitas mana yang lebih tinggi;prediction_scoreberisi probabilitas tertinggi tersebut.prediction_detail: semua hasil yang mungkin beserta probabilitasnya.