Topik ini memperkenalkan indeks utama dalam Hologres—seperti kunci distribusi, kolom waktu event (kunci segmen), dan kunci pengelompokan—untuk membantu Anda memulai penggunaan indeks dan meningkatkan performa kueri selama pengembangan dengan Hologres.
Cara kerja Hologres
Hologres adalah gudang data terdistribusi yang menggunakan komputasi paralel dan vektor untuk memberikan tanggapan kueri dalam hitungan detik. Karena arsitektur ini, distribusi data sangat penting bagi performa, mencakup cara data diseimbangkan di seluruh node terdistribusi—yang diatur oleh distribution key—serta cara data diurutkan dalam file pada satu node, yang diatur oleh event time column (juga dikenal sebagai segment key). Hologres secara default menggunakan format penyimpanan kolom (columnar) untuk skenario pemrosesan analitik daring (OLAP), sehingga urutan data dalam file—yang diatur oleh clustering key—juga sangat penting. Menguasai ketiga konsep ini merupakan kunci untuk mengoptimalkan performa. Karena properti tata letak data ini ditetapkan saat data ditulis dan mahal untuk diubah, kami menyarankan Anda merancang tabel dengan ketiga atribut tersebut sejak awal. Atribut yang tidak secara langsung memengaruhi tata letak data, seperti bitmap indexes dan dictionary encoding, dapat disesuaikan nanti sesuai kebutuhan.
Hologres menggunakan struktur metadata tiga tingkat: Database > Schema > Tabel. Untuk menghindari kueri lintas database, kami menyarankan mengelompokkan tabel-tabel yang terkait secara logis dalam satu schema yang sama. Database merupakan unit dasar untuk isolasi metadata, bukan isolasi sumber daya.
Dasar-dasar optimasi SQL
Merancang tabel dengan strategi distribusi data yang tepat memungkinkan kueri SQL menemukan data dengan cepat, mengurangi I/O, mengonsumsi lebih sedikit sumber daya komputasi, dan mencapai performa kueri yang lebih tinggi. Distribusi data yang seimbang juga memastikan sumber daya konkuren digunakan secara efisien serta menghindari bottleneck pada satu titik. Diagram berikut mengilustrasikan cara kueri SQL mengambil data dan bagaimana I/O dikurangi.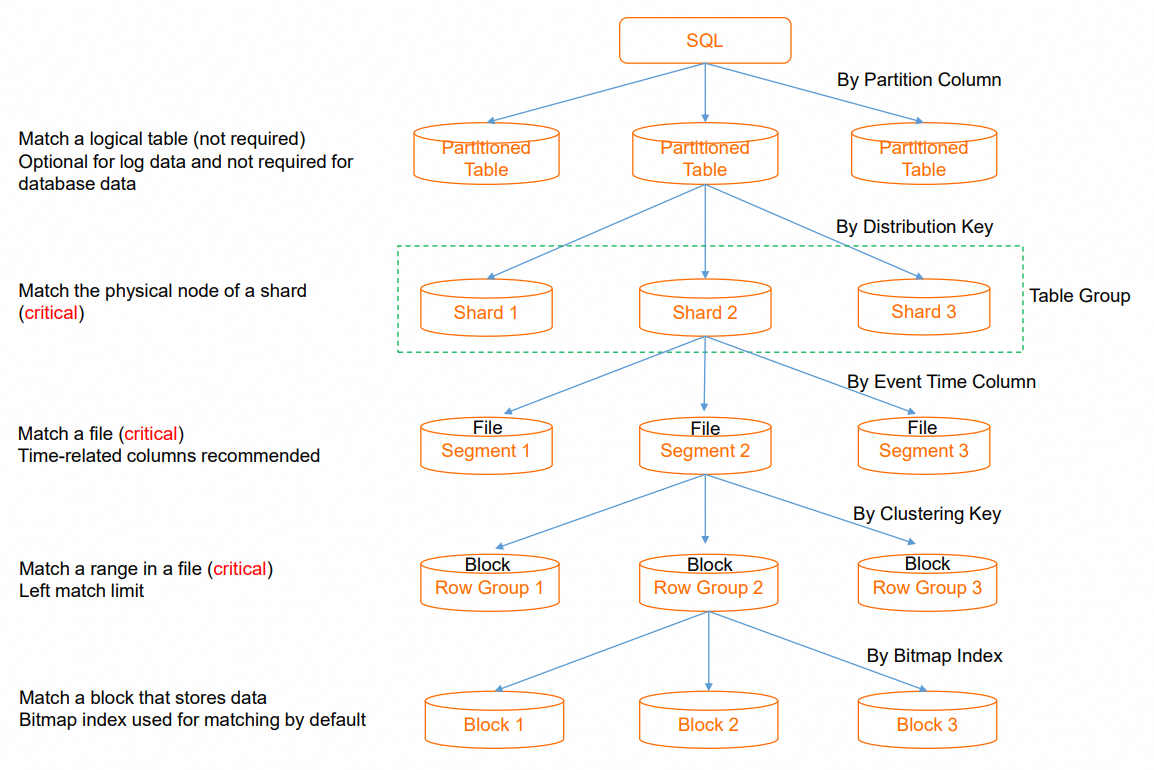
-
Pemangkasan partisi (Partition pruning): Saat kueri SQL menargetkan tabel partisi, pengoptimal kueri menggunakan pemangkasan partisi untuk menemukan partisi yang relevan. Jika kondisi filter kueri tidak mencakup kunci partisi, kueri harus memindai semua partisi, yang menyebabkan I/O berlebihan. Sebagai aturan umum, partisi berdasarkan hari merupakan praktik yang baik. Pemangkasan partisi dilewati untuk tabel non-partisi.
-
Pemangkasan shard (Shard pruning): Gunakan distribution key untuk menemukan shard data yang berisi data yang dibutuhkan secara cepat. Hal ini mengurangi konsumsi sumber daya untuk satu kueri dan mendukung throughput yang lebih tinggi untuk kueri konkuren. Jika shard tertentu tidak dapat ditemukan, framework terdistribusi menjadwalkan semua shard untuk berpartisipasi dalam komputasi. Hal ini meningkatkan paralelisme untuk satu kueri tetapi menggunakan lebih banyak sumber daya dan menurunkan konkurensi keseluruhan. Beberapa operator yang memerlukan eksekusi terpusat juga dapat menimbulkan overhead pengacakan tambahan. Sebagai praktik terbaik, pilih kolom dengan distribusi data yang merata, seperti ID pesanan, ID pengguna, atau ID event, sebagai distribution key. Jika beberapa tabel yang perlu digabungkan memiliki distribution key yang sama, data terkait akan ditempatkan bersama (co-located) pada shard yang sama, memungkinkan operasi penggabungan lokal yang efisien.
-
Pemangkasan kunci segmen (Segment key pruning): Gunakan segment key (event time column) untuk menemukan file data spesifik dalam satu node, sehingga menghindari akses ke file yang tidak diperlukan. Jika data tidak dapat difilter pada tingkat ini, semua file harus dipindai.
-
Pemangkasan kunci pengelompokan (Clustering key pruning): Gunakan clustering key untuk menemukan segmen data dalam satu file secara cepat. Hal ini meningkatkan efisiensi kueri rentang (range queries) dan pengurutan kolom.
Optimasi SQL dalam praktik
Bagian ini menggunakan kueri TPC-H untuk menunjukkan cara mengatur indeks Hologres guna meningkatkan performa kueri. Untuk informasi lebih lanjut tentang TPC-H, lihat Ikhtisar rencana pengujian.
Referensi SQL TPC-H
Kueri TPC-H Q1
Kueri TPC-H Q1 melakukan agregasi dan pemfilteran pada kolom-kolom tertentu dari tabel lineitem. Kueri ini mencakup kondisi berikut:
l_shipdate <=: Ini adalah kondisi filter. Untuk mendukung pemfilteran rentang yang efisien dan mengambil data yang diperlukan secara cepat, Anda harus menentukan indeks yang sesuai.
--TPC-H Q1
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM
lineitem
WHERE
l_shipdate <= DATE '1998-12-01' - INTERVAL '120' DAY
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;Kueri TPC-H Q4
Kueri TPC-H Q4 terutama menggabungkan tabel lineitem dan orders. Kueri ini mencakup kondisi berikut:
-
o_orderdate >= DATE '1996-07-01': Ini adalah kondisi filter. Untuk mendukung pemfilteran rentang yang efisien dan mengambil data yang diperlukan secara cepat, Anda harus menentukan indeks yang sesuai. -
l_orderkey = o_orderkey: Ini adalah kondisi penggabungan antara kedua tabel. Untuk performa terbaik, gunakan indeks yang sama pada kedua tabel agar memungkinkan penggabungan lokal (local join), yang mengurangi pengacakan data selama operasi.--TPC-H Q4 Query SELECT o_orderpriority, COUNT(*) AS order_count FROM orders WHERE o_orderdate >= DATE '1996-07-01' AND o_orderdate < DATE '1996-07-01' + INTERVAL '3' MONTH AND EXISTS ( SELECT * FROM lineitem WHERE l_orderkey = o_orderkey AND l_commitdate < l_receiptdate ) GROUP BY o_orderpriority ORDER BY o_orderpriority;
Rekomendasi pembuatan tabel
Kueri Q1 dan Q4 melibatkan tabel lineitem dan orders.
hologres_dataset_tpch_100g.lineitem
Baik kueri Q1 maupun Q4 melibatkan tabel lineitem, tetapi menggunakan kolom dan kondisi yang berbeda.
-
Untuk kueri Q1: Kueri terutama menggunakan
l_shipdateuntuk pemfilteran rentang. Clustering key mempercepat pemindaian rentang dengan memanfaatkan urutan data yang diurutkan dalam file. Oleh karena itu, tetapkanl_shipdatesebagai clustering key. Segment key (event time column) mempertahankan urutan antar file. Untuk kolom tanggal yang nilainya meningkat atau menurun secara monoton, menetapkannya sebagai segment key memungkinkan pemangkasan kunci segmen yang efektif. Oleh karena itu, Anda juga dapat menetapkanl_shipdatesebagai segment key. -
Untuk kueri Q4: Kueri menggabungkan tabel
lineitemdengan tabelorderspada koloml_orderkeydano_orderkey. Distribution key menentukan strategi distribusi data. Sistem menempatkan data dengan nilai kunci yang sama pada shard yang sama. Jika dua tabel berada dalam kelompok tabel yang sama dan digabungkan berdasarkan kolom distribution key-nya, sistem secara otomatis mendistribusikan catatan yang cocok ke shard yang sama saat data ditulis. Ketika tabel-tabel ini digabungkan, sistem melakukan penggabungan lokal pada setiap node tanpa mengacak data melalui jaringan. Hal ini menghindari pengacakan dan redistribusi data saat runtime, sehingga secara signifikan meningkatkan efisiensi eksekusi. Oleh karena itu, tetapkanl_orderkeysebagai distribution key. -
Struktur tabel akhir untuk
lineitemadalah sebagai berikut:BEGIN; CREATE TABLE hologres_dataset_tpch_100g.lineitem ( l_ORDERKEY BIGINT NOT NULL, L_PARTKEY INT NOT NULL, L_SUPPKEY INT NOT NULL, L_LINENUMBER INT NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG TEXT NOT NULL, L_LINESTATUS TEXT NOT NULL, L_SHIPDATE TIMESTAMPTZ NOT NULL, L_COMMITDATE TIMESTAMPTZ NOT NULL, L_RECEIPTDATE TIMESTAMPTZ NOT NULL, L_SHIPINSTRUCT TEXT NOT NULL, L_SHIPMODE TEXT NOT NULL, L_COMMENT TEXT NOT NULL, PRIMARY KEY (L_ORDERKEY,L_LINENUMBER) ) WITH ( distribution_key = 'L_ORDERKEY',--Enables local join. clustering_key = 'L_SHIPDATE',--Accelerates range filtering. event_time_column = 'L_SHIPDATE'--Accelerates segment key pruning. ); COMMIT;
hologres_dataset_tpch_100g.orders
Dalam contoh ini, tabel orders digunakan dalam kueri Q4.
-
Tetapkan kolom
o_orderkeypada tabelorderssebagai distribution key untuk memanfaatkan kemampuan penggabungan lokal dan meningkatkan efisiensi kueri penggabungan. -
Kolom
o_orderdateterutama digunakan untuk pemfilteran berdasarkan tanggal. Tetapkan sebagai segment key untuk mempercepat pemangkasan kunci segmen. -
Struktur tabel akhir untuk
ordersadalah sebagai berikut:BEGIN; CREATE TABLE hologres_dataset_tpch_100g.orders ( O_ORDERKEY BIGINT NOT NULL PRIMARY KEY, O_CUSTKEY INT NOT NULL, O_ORDERSTATUS TEXT NOT NULL, O_TOTALPRICE DECIMAL(15,2) NOT NULL, O_ORDERDATE timestamptz NOT NULL, O_ORDERPRIORITY TEXT NOT NULL, O_CLERK TEXT NOT NULL, O_SHIPPRIORITY INT NOT NULL, O_COMMENT TEXT NOT NULL ) WITH ( distribution_key = 'O_ORDERKEY',--Enables local join. event_time_column = 'O_ORDERDATE'--Accelerates segment key pruning. ); COMMIT;
Impor data sampel
Anda dapat dengan cepat mengimpor data TPC-H sebesar 100 GB ke instans Hologres Anda menggunakan fitur Import public datasets with a few clicks di HoloWeb. Di HoloWeb, pilih Data Solutions dari bilah navigasi atas, lalu klik Import public datasets with a few clicks di panel navigasi kiri. Pada halaman konfigurasi, pilih Instance Name (misalnya, holo_test) dan Database. Kemudian, pilih tpch_100g dari daftar Public Dataset Name. Sistem secara otomatis menghasilkan skrip SQL yang tidak dapat diedit di bagian bawah halaman. Skrip ini mencakup pernyataan untuk membuat skema hologres_foreign_dataset_tpch_100g dan hologres_dataset_tpch_100g, serta mengimpor data secara berurutan ke tabel eksternal seperti customer, lineitem, nation, orders, part, partsupp, region, dan supplier.
Hasil pengujian performa
Bagian ini membandingkan performa kueri sebelum dan sesudah menetapkan properti tabel yang direkomendasikan (indeks).
-
Lingkungan pengujian
-
Spesifikasi instans: 32-core
-
Jenis jaringan: VPC
-
Jalankan setiap kueri dua kali menggunakan klien PSQL dan catat latensi eksekusi kedua.
-
-
Kesimpulan
-
Untuk kueri yang difilter pada satu tabel, menetapkan kolom filter sebagai clustering key secara efektif mempercepat kueri.
-
Untuk kueri penggabungan multi-tabel, menetapkan kolom penggabungan sebagai distribution key secara signifikan meningkatkan efisiensi penggabungan.
Kueri
Latensi dengan indeks
Latensi tanpa indeks
Q1
48,293 ms
59,483 ms
Q4
822,389 ms
3027,957 ms
-
Referensi
Informasi lebih lanjut
Prinsip teknis
Pelajari lebih dalam prinsip teknis inti Hologres (arsitektur, mesin penyimpanan, dan mesin komputasi): Teknologi Inti Gudang Data Real-time Cloud-native Alibaba Cloud.
Aktivasi layanan
-
Pemilihan spesifikasi: Manajemen instans.
-
Otorisasi pengguna RAM: Panduan cepat otorisasi pengguna RAM.
Impor data
-
Penulisan real-time dan kueri tabel dimensi dengan Flink: Realtime Compute for Apache Flink.
-
Sinkronisasi penuh real-time dari database seperti MySQL, Oracle, dan PolarDB: Konfigurasi sumber data MySQL.
-
Impor data dari OSS: Percepat akses ke data lake OSS menggunakan DLF.
-
Gunakan Fixed Plan untuk meningkatkan efisiensi penulisan dan pembaruan data hingga 10 kali lipat. Untuk informasi lebih lanjut, lihat Percepat eksekusi SQL menggunakan Fixed Plan.
Kueri data
-
Rekomendasi pembuatan tabel untuk berbagai kasus penggunaan: Panduan penyetelan tabel berbasis skenario.
-
Sebelum membuat tabel, pahami parameter kunci seperti
distribution_key,clustering_key,event_time_column, danbitmap_index. Menggunakan sintaksis dan indeks yang tepat untuk menentukan struktur tabel yang optimal secara signifikan meningkatkan performa. Untuk informasi lebih lanjut, lihat CREATE TABLE. -
Penyetelan performa tabel internal: Optimalkan performa kueri.
-
Akselerasi MaxCompute: Percepat kueri data MaxCompute menggunakan tabel eksternal.
O&M dan pemantauan
-
Kueri aktif (pemecahan masalah kueri yang sedang berjalan, dan pemeriksaan lock yang ada atau potensial): Kelola kueri.
-
Kueri lambat (pemecahan masalah kueri gagal atau berjalan lama): Dapatkan dan analisis log kueri lambat.
-
Pemisahan baca/tulis dan isolasi beban: Terapkan pemisahan baca/tulis untuk instans primary dan secondary (penyimpanan bersama).
Kasus penggunaan dan praktik terbaik
Praktik dan kasus penggunaan: Praktik terbaik dan kasus penggunaan pelanggan klasik untuk skenario industri khas.