Topik ini menjelaskan praktik terbaik untuk menyetel performa tabel internal Hologres.
Perbarui statistik
Statistik sangat penting untuk menghasilkan rencana eksekusi yang optimal. Hologres mengumpulkan statistik sampel tentang data, seperti distribusi data, statistik tabel dan kolom, jumlah baris, jumlah kolom, lebar bidang, kardinalitas, frekuensi, nilai maksimum dan minimum, nilai kunci panjang, serta fitur distribusi bucketing. Informasi ini membantu pengoptimal memperkirakan biaya eksekusi operator, memangkas ruang pencarian, menentukan urutan join optimal, memperkirakan overhead memori, dan menentukan tingkat paralelisme guna menghasilkan rencana eksekusi yang lebih baik. Untuk informasi selengkapnya tentang statistik, lihat Using EXPLAIN.
Proses pengumpulan statistik memiliki keterbatasan karena tidak berjalan secara real-time dan hanya dipicu secara manual atau berkala. Akibatnya, statistik yang dihasilkan mungkin tidak mencerminkan kondisi data terkini. Anda harus memeriksa output EXPLAIN terlebih dahulu untuk memverifikasi keakuratan statistik. Dalam output EXPLAIN, nilai rows dan width untuk setiap operator merepresentasikan perkiraan jumlah baris dan lebar operator tersebut.
Periksa apakah statistik akurat
Lihat rencana eksekusi:
Statistik yang kedaluwarsa dapat menyebabkan rencana eksekusi yang buruk. Contohnya:
Tabel tmp1 memiliki 10 juta baris, sedangkan tabel tmp memiliki 1.000 baris. Jumlah baris default dalam statistik Hologres adalah 1.000. Jika Anda menjalankan pernyataan SQL EXPLAIN, hasilnya menunjukkan bahwa jumlah baris untuk tabel tmp1 tidak sesuai dengan jumlah sebenarnya. Hal ini menunjukkan bahwa statistiknya kedaluwarsa.
Seq Scan on tmp1 (cost=0.00..5.01 rows=1000 width=1)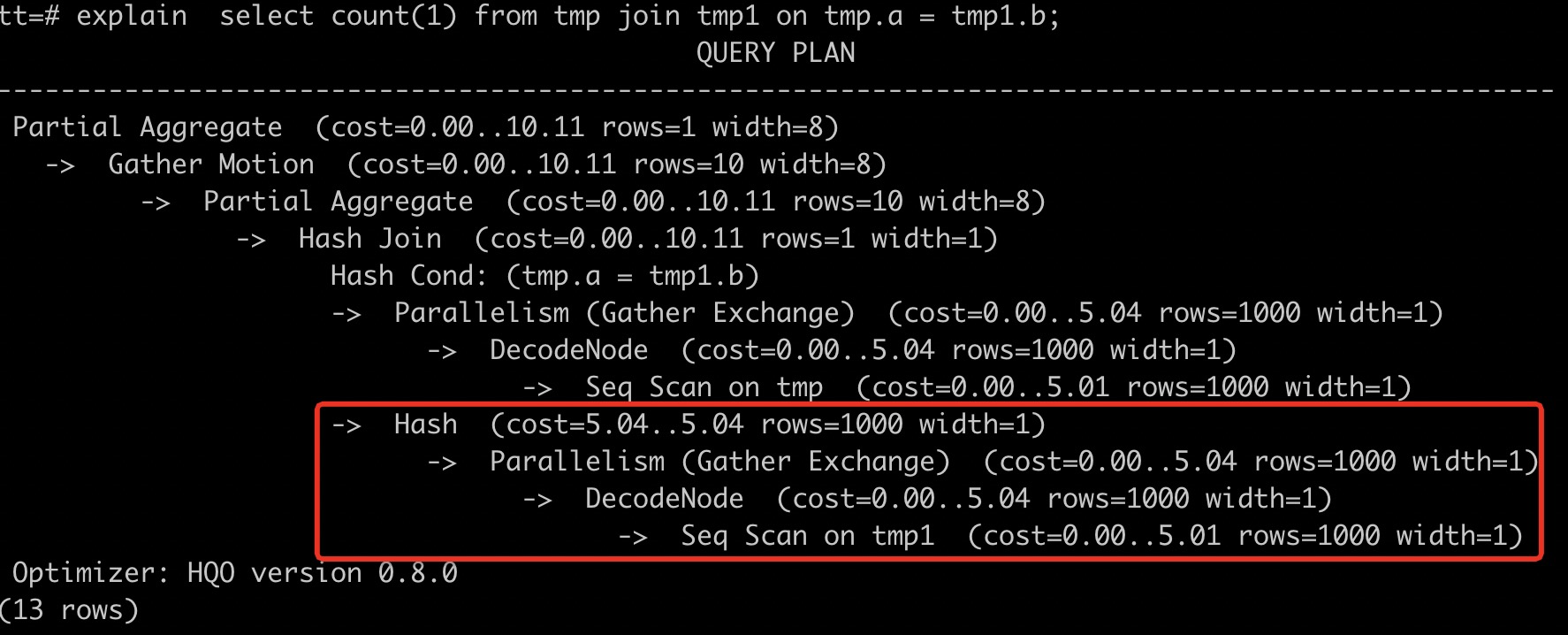
Perbarui statistik
Saat melakukan join antara tabel tmp1 dan tmp, rencana eksekusi yang benar seharusnya menggunakan tabel yang lebih kecil (tmp) untuk membangun tabel hash pada hash join. Karena statistik tabel tmp1 kedaluwarsa, Hologres salah memilih tabel tmp1 yang lebih besar untuk membuat tabel hash. Proses ini tidak efisien dan dapat menyebabkan error out-of-memory (OOM). Untuk mengatasi hal ini, jalankan perintah ANALYZE pada kedua tabel untuk mengumpulkan statistik terbaru. Pernyataannya sebagai berikut.
analyze tmp;
analyze tmp1;Setelah menjalankan perintah ANALYZE, urutan join menjadi benar. Tabel tmp yang lebih kecil digunakan untuk membangun tabel hash, seperti yang ditunjukkan pada gambar berikut. Output EXPLAIN untuk tabel tmp1 kini menunjukkan 10 juta baris, yang mengindikasikan bahwa statistik telah diperbarui.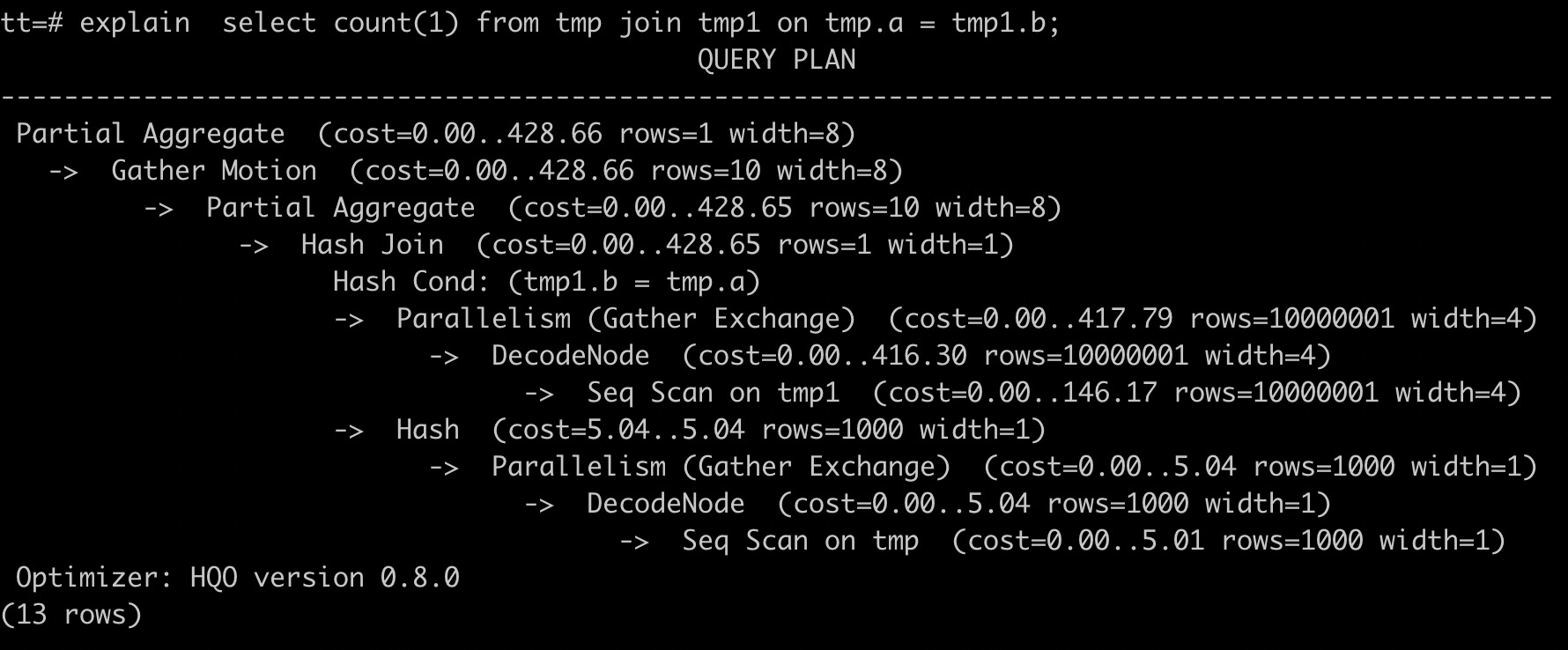
Jika hasil EXPLAIN mengembalikan rows=1000 untuk tabel besar, hal ini menunjukkan bahwa statistik hilang atau kedaluwarsa. Performa buruk sering kali disebabkan oleh kurangnya statistik akurat pada pengoptimal. Anda dapat menjalankan ANALYZE <tablename> untuk memperbarui statistik, yang merupakan cara cepat dan mudah untuk mengoptimalkan performa kueri.
Kapan memperbarui statistik
Anda harus menjalankan perintah ANALYZE <tablename> dalam skenario berikut.
-
Setelah mengimpor data.
-
Setelah melakukan banyak operasi `INSERT`, `UPDATE`, atau `DELETE`.
-
Anda harus menjalankan ANALYZE pada tabel internal maupun tabel eksternal.
-
Untuk tabel partisi, jalankan `ANALYZE` pada tabel induk.
-
Jika mengalami masalah berikut, jalankan
ANALYZE <tablename>untuk mengoptimalkan performa.-
Error OOM saat melakukan join multi-tabel.
Umumnya menghasilkan error
Query executor exceeded total memory limitation xxxxx: yyyy bytes used. -
Efisiensi impor rendah.
Kueri atau tugas impor berjalan lambat dan membutuhkan waktu lama untuk diselesaikan.
-
Tetapkan jumlah shard yang sesuai
Jumlah shard menentukan tingkat paralelisme eksekusi kueri dan sangat penting bagi performa kueri. Terlalu sedikit shard dapat menyebabkan paralelisme tidak mencukupi, sedangkan terlalu banyak shard meningkatkan overhead startup kueri, mengurangi efisiensi kueri, menghasilkan terlalu banyak file kecil, dan mengonsumsi lebih banyak memori untuk manajemen metadata. Menetapkan jumlah shard yang sesuai dengan spesifikasi instans dapat meningkatkan efisiensi kueri dan mengurangi overhead memori.
Hologres menetapkan jumlah shard default untuk setiap instans, yang kira-kira sama dengan jumlah core yang tersedia untuk kueri. Jumlah core kueri sedikit lebih sedikit daripada total core yang dibeli karena beberapa core dialokasikan ke node lain, seperti node akses, kontrol, dan penjadwalan. Untuk jumlah shard default berbagai spesifikasi instans, lihat Manajemen instans. Saat instans diperluas kapasitasnya (scale-out), jumlah shard default untuk database yang sudah ada tidak diperbarui secara otomatis. Anda harus mengubah jumlah shard secara manual jika diperlukan. Database baru yang dibuat setelah scale-out akan menggunakan jumlah shard default sesuai spesifikasi baru. Jumlah shard default dirancang untuk mengakomodasi beberapa tingkat scaling. Jika Anda memperluas sumber daya lebih dari lima kali lipat, pertimbangkan untuk mengatur ulang jumlah shard. Jika scale-out kurang dari lima kali lipat, Anda tidak perlu mengubah jumlah shard. Untuk informasi selengkapnya, lihat Praktik terbaik untuk pengaturan Table Group.
Anda harus mengubah jumlah shard dalam skenario berikut:
-
Setelah scale-out, jika bisnis Anda berkembang dan Anda perlu meningkatkan efisiensi kueri, buat Table Group baru dengan jumlah shard yang lebih besar. Tabel dan data asli tetap berada di Table Group lama. Anda harus mengimpor ulang data ke Table Group baru untuk menyelesaikan proses resharding.
-
Setelah scale-out, jika Anda ingin meluncurkan bisnis baru sementara bisnis yang ada tetap tidak berubah, buat Table Group baru dengan jumlah shard yang sesuai. Anda tidak perlu menyesuaikan struktur tabel asli.
Anda dapat membuat beberapa Table Group dalam satu database. Namun, jumlah total shard untuk semua Table Group tidak boleh melebihi jumlah shard default yang direkomendasikan oleh Hologres agar pemanfaatan sumber daya CPU tetap optimal.
Optimalkan skenario JOIN
Saat melakukan join dua atau lebih tabel, Anda dapat menggunakan metode berikut untuk meningkatkan performa join.
Perbarui statistik
Sebagaimana disebutkan sebelumnya, jika statistik tabel dalam join kedaluwarsa, pengoptimal mungkin menggunakan tabel yang lebih besar untuk membangun tabel hash, yang mengurangi efisiensi join. Oleh karena itu, Anda harus memperbarui statistik tabel untuk meningkatkan performa SQL.
analyze <tablename>;Pilih kunci distribusi yang sesuai
Kunci distribusi digunakan untuk mempartisi data di beberapa shard. Distribusi data yang merata mencegah kesenjangan data (data skew). Jika Anda merancang tabel terkait dengan kunci distribusi yang sama, join lokal dapat dipercepat. Saat membuat tabel, pilih kunci distribusi yang sesuai berdasarkan prinsip berikut:
-
Rekomendasi kunci distribusi
-
Pilih kolom yang digunakan dalam kondisi join sebagai kunci distribusi.
-
Pilih kolom `GROUP BY` yang sering digunakan sebagai kunci distribusi.
-
Pilih kolom dengan distribusi data yang merata dan diskret sebagai kunci distribusi.
-
Untuk informasi selengkapnya tentang prinsip dan penggunaan kunci distribusi, lihat Distribution Key.
-
-
Contoh penetapan kunci distribusi
Misalnya, saat melakukan join tabel tmp dan tmp1, jika rencana eksekusi menunjukkan Redistribution Motion, artinya data didistribusikan ulang alih-alih di-join secara lokal. Hal ini menyebabkan efisiensi kueri rendah. Untuk menghindari overhead redistribusi data saat join multi-tabel, Anda harus membuat ulang tabel dan menetapkan kunci join sebagai kunci distribusi.
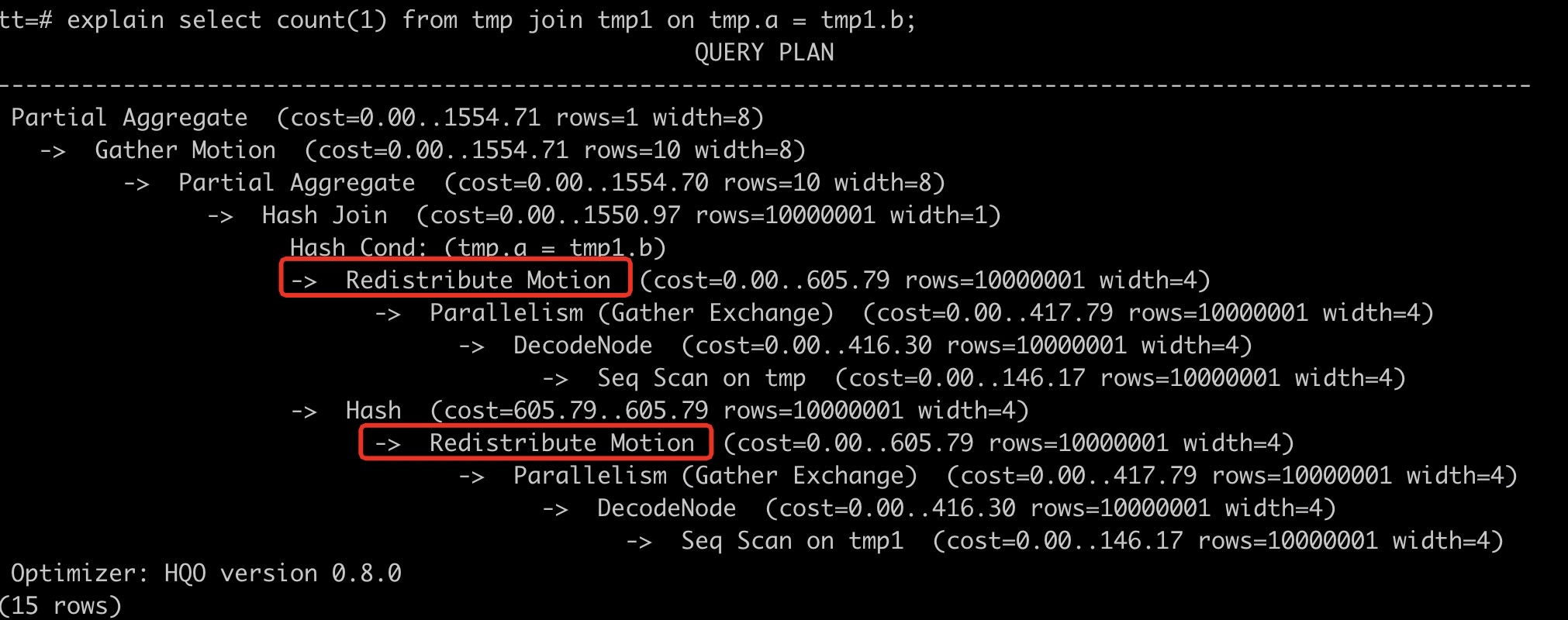 Berikut adalah pernyataan DDL untuk tabel yang dibuat ulang.
Berikut adalah pernyataan DDL untuk tabel yang dibuat ulang.begin; create table tmp(a int, b int, c int); call set_table_property('tmp', 'distribution_key', 'a'); commit; begin; create table tmp1(a int, b int, c int); call set_table_property('tmp1', 'distribution_key', 'b'); commit; -- Tetapkan kunci distribusi ke kunci join. select count(1) from tmp join tmp1 on tmp.a = tmp1.b ;Setelah Anda mengatur ulang kunci distribusi dan menjalankan pernyataan SQL EXPLAIN lagi, Anda dapat melihat bahwa operator Motion tidak lagi ada dalam rencana eksekusi. Data di kedua tabel kini didistribusikan di antara shard berdasarkan kunci hash yang sama. Karena distribusi datanya sama, operator Motion tidak lagi diperlukan. Hal ini menunjukkan bahwa data tidak didistribusikan ulang, sehingga menghindari overhead jaringan yang berlebihan.
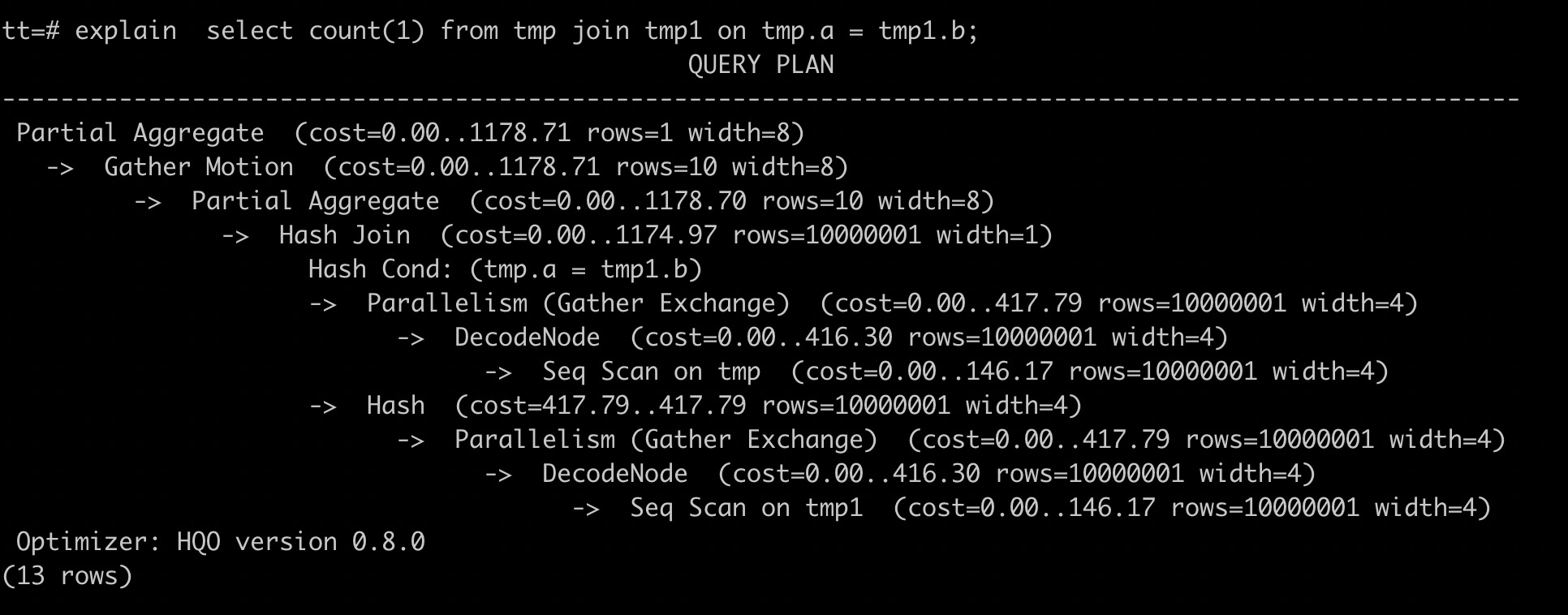
Gunakan Runtime Filter
Mulai dari V2.0, Hologres mendukung Runtime Filter. Fitur ini biasanya digunakan dalam join multi-tabel, terutama dalam skenario di mana tabel besar di-join dengan tabel kecil. Anda tidak perlu mengonfigurasinya secara manual. Pengoptimal dan mesin eksekusi secara otomatis menerapkan optimasi ini saat kueri dijalankan. Hal ini mengurangi jumlah data yang dipindai, menurunkan overhead I/O, dan meningkatkan performa kueri join. Untuk informasi selengkapnya, lihat Runtime Filter.
Optimalkan algoritma urutan Join
-
Saat kueri SQL memiliki hubungan join yang kompleks atau melakukan join banyak tabel, pengoptimal kueri (QO) menghabiskan lebih banyak waktu untuk memilih urutan join optimal. Dalam skenario tertentu, Anda dapat menyesuaikan kebijakan urutan join untuk mengurangi waktu yang dihabiskan untuk optimasi kueri. Sintaks untuk mengatur algoritma urutan join adalah sebagai berikut.
set optimizer_join_order = '<value>'; -
Deskripsi parameter
Parameter
Deskripsi
value
Algoritma urutan join untuk pengoptimal. Nilai yang tersedia sebagai berikut.
-
exhaustive2 (default untuk V2.2 dan versi setelahnya): Algoritma pemrograman dinamis yang ditingkatkan dan dioptimalkan.
-
exhaustive (default untuk versi sebelumnya): Menggunakan algoritma pemrograman dinamis untuk transformasi urutan join. Menghasilkan rencana eksekusi optimal tetapi memiliki overhead pengoptimal tertinggi.
-
query: Tidak melakukan transformasi urutan join. Menjalankan join sesuai urutan yang ditulis dalam pernyataan SQL dan memiliki overhead pengoptimal terendah.
-
greedy: Menggunakan algoritma greedy untuk mengeksplorasi urutan join. Memiliki overhead pengoptimal moderat.
-
-
Informasi tambahan
Algoritma exhaustive2 default dapat mengeksplorasi rencana eksekusi optimal secara global. Namun, untuk join dengan banyak tabel, misalnya lebih dari 10, waktu optimasi bisa sangat tinggi. Menggunakan algoritma `query` atau `greedy` dapat mengurangi waktu pengoptimal, tetapi mungkin tidak menghasilkan rencana eksekusi optimal.
Optimalkan operator Motion seperti Broadcast
Hologres memiliki empat jenis node Motion, yang sesuai dengan empat skenario redistribusi data, seperti yang ditunjukkan pada tabel berikut.
|
Tipe |
Deskripsi |
|
Redistribute Motion |
Menyusun ulang data ke satu atau beberapa shard menggunakan distribusi hash atau acak. |
|
Broadcast Motion |
Menyalin data ke semua shard. Broadcast Motion hanya menguntungkan jika jumlah shard dan jumlah tabel broadcast kecil. |
|
Gather Motion |
Meringkas data ke satu shard tunggal. |
|
Forward Motion |
Digunakan untuk skenario query terfederasi. Sumber data eksternal atau mesin eksekusi mentransfer data ke mesin eksekusi Hologres. |
Berdasarkan hasil pernyataan SQL EXPLAIN, pertimbangkan hal berikut:
-
Jika operator Motion memakan waktu lama, Anda harus mendesain ulang kunci distribusi.
-
Jika statistik yang salah menyebabkan pembentukan Gather Motion atau Broadcast Motion, jalankan perintah
ANALYZE <tablename>. Hal ini dapat membantu pengoptimal memilih Redistribute Motion yang lebih efisien. -
Broadcast Motion hanya menguntungkan dalam skenario dengan jumlah shard kecil dan untuk tabel broadcast. Oleh karena itu, untuk skenario broadcast tabel kecil, Anda dapat mengurangi jumlah shard untuk tabel tersebut guna meningkatkan efisiensi kueri. Usahakan agar jumlah shard sebanding dengan jumlah worker. Untuk informasi selengkapnya tentang jumlah shard, lihat Shard Count.
Nonaktifkan Dictionary Encoding
Untuk kueri pada tipe karakter, seperti Text, Char, dan Varchar, Dictionary Encoding dapat mengurangi waktu yang diperlukan untuk perbandingan string tetapi menimbulkan overhead Decode atau Encode yang signifikan.
Secara default, Hologres membuat encoding kamus untuk semua kolom tipe karakter. Anda dapat mengatur `dictionary_encoding_columns` menjadi kosong atau menonaktifkan fitur encoding kamus otomatis untuk kolom tertentu. Perlu diperhatikan bahwa mengubah pengaturan encoding kamus menyebabkan file data di-encode ulang dan disimpan kembali. Proses ini mengonsumsi sumber daya CPU dan memori untuk periode waktu tertentu, sehingga perubahan ini sebaiknya dilakukan pada jam sepi.
Jika operator Decode memakan waktu lama, Anda dapat menonaktifkan fitur dictionary encoding untuk meningkatkan performa.
Jika sebuah tabel memiliki banyak bidang tipe karakter, pilih kolom untuk dictionary encoding sesuai kebutuhan. Anda tidak perlu menambahkan semua tipe karakter ke `dictionary_encoding_columns`. Berikut adalah contoh pernyataannya:
begin;
create table tbl (a int not null, b text not null, c int not null, d int);
call set_table_property('tbl', 'dictionary_encoding_columns', '');
commit;Metode penyetelan performa umum
Anda dapat mengoptimalkan pernyataan SQL untuk meningkatkan efisiensi kueri.
Gunakan Fixed Plan
Fixed Plan cocok untuk skenario throughput tinggi. Fixed Plan menggunakan jalur eksekusi yang disederhanakan untuk mencapai performa dan throughput yang jauh lebih tinggi. Untuk informasi selengkapnya tentang cara mengonfigurasi dan menggunakan Fixed Plan, lihat Mempercepat eksekusi SQL dengan Fixed Plan.
Tulis ulang operator PQE
Hologres memiliki beberapa mesin eksekusi dasar, termasuk Hologres Query Engine (HQE) native, mesin vektor, dan Postgres Query Engine (PQE), yaitu mesin Postgres terdistribusi. Jika pernyataan SQL berisi operator yang tidak didukung HQE, sistem akan mengirim operator tersebut ke PQE untuk dieksekusi. Dalam kasus ini, performa kueri tidak sepenuhnya dioptimalkan, dan Anda mungkin perlu menulis ulang pernyataan kueri.
Saat Anda memeriksa rencana eksekusi menggunakan kueri SQL EXPLAIN, jika rencana tersebut berisi External SQL (Postgres), artinya bagian SQL tersebut dieksekusi di PQE.
Misalnya, HQE tidak mendukung NOT IN. Oleh karena itu, operasi NOT IN dikirim ke mesin kueri eksternal PQE untuk dieksekusi. Anda dapat menulis ulang NOT IN menjadi NOT EXISTS. Berikut adalah pernyataan SQL sebelum optimasi.
explain select * from tmp where a not in (select a from tmp1);Operator External mengeksekusi bagian pernyataan SQL ini pada mesin PostgreSQL eksternal.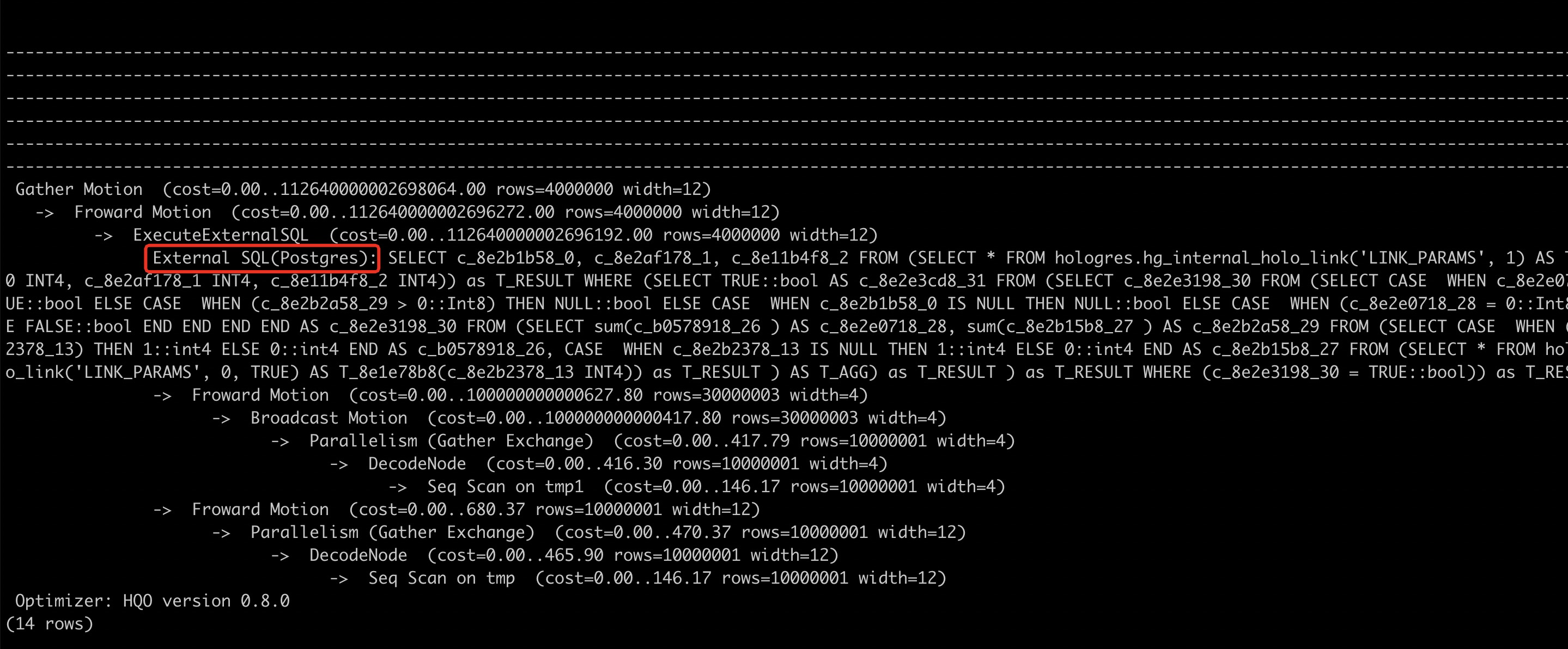
Contoh berikut menunjukkan pernyataan SQL yang telah dioptimalkan. Mesin kueri eksternal tidak lagi digunakan.
explain select * from tmp where not exists (select a from tmp1 where a = tmp.a);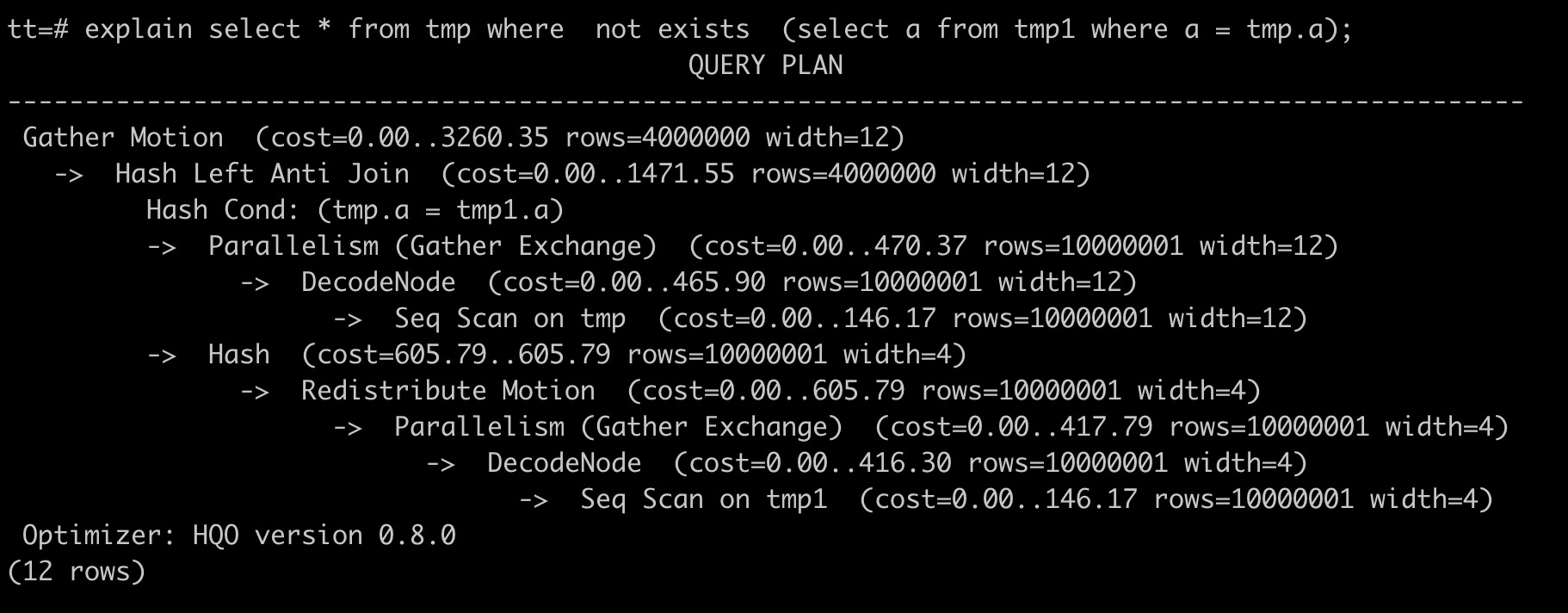
Anda dapat menulis ulang fungsi untuk memastikan operator berjalan di mesin HQE. Berikut adalah beberapa saran penulisan ulang fungsi. Setiap versi Hologres mendorong lebih banyak fungsi dari PQE ke HQE. Jika suatu fungsi sudah didukung oleh HQE di versi yang lebih baru, Anda dapat menyelesaikan masalah tersebut dengan melakukan upgrade instans. Untuk informasi selengkapnya, lihat Catatan rilis fungsi.
|
Fungsi tidak didukung oleh HQE |
Saran penulisan ulang |
Contoh |
Catatan |
|
not in |
not exists |
|
Tidak berlaku. |
|
regexp_split_to_table(string text, pattern text) |
unnest(string_to_array) |
|
regexp_split_to_table mendukung ekspresi reguler. Mulai dari Hologres V2.0.4, HQE mendukung regexp_split_to_table. Anda harus menjalankan perintah berikut untuk mengaktifkan GUC: set hg_experimental_enable_hqe_table_function = on; |
|
substring |
extract(hour from to_timestamp(c1, 'YYYYMMDD HH24:MI:SS')) |
Tulis ulang sebagai: |
Beberapa versi Hologres V0.10 dan sebelumnya tidak mendukung substring. Di versi V1.3 dan setelahnya, HQE mendukung parameter input non-ekspresi reguler untuk fungsi substring. |
|
regexp_replace |
replace |
Tulis ulang sebagai: |
replace tidak mendukung ekspresi reguler. |
|
at time zone 'utc' |
Hapus at time zone 'utc' |
Tulis ulang sebagai: |
Tidak berlaku. |
|
cast(text as timestamp) |
to_timestamp |
Tulis ulang sebagai: |
HQE telah mendukung ini sejak Hologres V2.0. |
|
timestamp::text |
to_char |
Tulis ulang sebagai: |
HQE telah mendukung ini sejak Hologres V2.0. |
Hindari kueri fuzzy
Kueri fuzzy, seperti operasi `LIKE` dengan wildcard di awal, tidak menggunakan indeks.
Dampak cache hasil terhadap kueri
Secara default, Hologres menyimpan cache hasil kueri atau subkueri yang identik. Eksekusi berulang kueri yang sama akan mengenai cache. Anda dapat menjalankan perintah berikut untuk menonaktifkan cache saat pengujian performa:
set hg_experimental_enable_result_cache = off;Metode optimasi untuk OOM
Error OOM biasanya terjadi ketika instans memiliki memori komputasi yang tidak mencukupi. Berikut adalah pesan error umum. Error OOM dapat disebabkan oleh berbagai faktor, seperti perhitungan kompleks atau konkurensi tinggi. Anda dapat melakukan optimasi yang ditargetkan berdasarkan penyebab spesifik untuk mengurangi error OOM. Untuk informasi selengkapnya, lihat Panduan pemecahan masalah untuk isu OOM.
Total memory used by all existing queries exceeded memory limitation.
memory usage for existing queries=(2031xxxx,184yy)(2021yyyy,85yy)(1021121xxxx,6yy)(2021xxx,18yy)(202xxxx,14yy); Used/Limit: xy1/xy2 quota/sum_quota: zz/100Optimalkan skenario Order By Limit
Pada versi Hologres sebelum V1.3, operator Merge Sort tidak didukung untuk skenario `ORDER BY ... LIMIT`. Rencana eksekusi mencakup pengurutan tambahan pada output akhir, yang mengakibatkan performa buruk. Mulai dari V1.3, mesin mengoptimalkan skenario ini dengan mendukung operator Merge Sort. Hal ini memungkinkan pengurutan gabungan multi-arah dan menghilangkan kebutuhan pengurutan tambahan, sehingga meningkatkan performa kueri.
Berikut adalah contoh optimasi.
-
DDL Tabel
begin;
create table test_use_sort_1
(
uuid text not null,
gpackagename text not null,
recv_timestamp text not null
);
call set_table_property('test_use_sort_1', 'orientation', 'column');
call set_table_property('test_use_sort_1', 'distribution_key', 'uuid');
call set_table_property('test_use_sort_1', 'clustering_key', 'uuid:asc,gpackagename:asc,recv_timestamp:desc');
commit;
--Masukkan data
insert into test_use_sort_1 select i::text, i::text, '20210814' from generate_series(1, 10000) as s(i);
--Perbarui statistik
analyze test_use_sort_1;Perintah kueri
set hg_experimental_enable_reserve_gather_exchange_order =on
set hg_experimental_enable_reserve_gather_motion_order =on
select uuid from test_use_sort_1 order by uuid limit 5;Perbandingan rencana eksekusi
-
Rencana eksekusi untuk versi Hologres sebelum V1.3 (V1.1) sebagai berikut.

-
Rencana eksekusi untuk Hologres V1.3 sebagai berikut.

Perbandingan rencana eksekusi menunjukkan bahwa Hologres V1.3 memiliki satu operasi pengurutan lebih sedikit pada output akhir. Penggabungan multi-arah dilakukan secara langsung, yang meningkatkan performa kueri.
Optimalkan Count Distinct
-
Tulis ulang sebagai APPROX_COUNT_DISTINCT
`COUNT DISTINCT` melakukan deduplikasi presisi. Operasi ini perlu mengacak catatan dengan kunci yang sama ke node yang sama untuk deduplikasi, yang bersifat intensif sumber daya. Hologres menyediakan fungsi ekstensi `APPROX_COUNT_DISTINCT`, yang menggunakan estimasi kardinalitas HyperLogLog untuk perhitungan `COUNT DISTINCT` perkiraan guna meningkatkan performa kueri. Tingkat kesalahan rata-rata dapat dikontrol dalam rentang 0,1% hingga 1%. Anda dapat menulis ulang fungsi sesuai kebutuhan. Untuk informasi selengkapnya, lihat APPROX_COUNT_DISTINCT.
-
Gunakan fungsi UNIQ
Mulai dari V1.3, Hologres mendukung fungsi `UNIQ` untuk deduplikasi presisi. Saat kardinalitas kunci `GROUP BY` tinggi, `UNIQ` berperforma lebih baik dan menghemat lebih banyak memori dibandingkan `COUNT DISTINCT`. Jika Anda mengalami error OOM saat menggunakan `COUNT DISTINCT`, Anda dapat menggantinya dengan `UNIQ`. Untuk informasi selengkapnya, lihat UNIQ.
-
Tetapkan kunci distribusi yang sesuai
Jika Anda memiliki beberapa operasi `COUNT DISTINCT` pada kunci yang sama dan datanya diskret serta terdistribusi merata, Anda dapat menetapkan kunci `COUNT DISTINCT` sebagai kunci distribusi. Hal ini memastikan bahwa data dengan kunci yang sama didistribusikan ke shard yang sama, sehingga menghindari pengacakan data.
-
Optimasi Count Distinct
Mulai dari V2.1, Hologres mencakup banyak optimasi performa untuk skenario `COUNT DISTINCT`, termasuk `COUNT DISTINCT` tunggal, `COUNT DISTINCT` ganda, kesenjangan data, dan SQL tanpa bidang `GROUP BY`. Anda tidak perlu menulis ulang `COUNT DISTINCT` menjadi `UNIQ` secara manual untuk mencapai performa yang lebih baik. Untuk meningkatkan performa `COUNT DISTINCT`, upgrade instans Hologres Anda ke V2.1 atau versi yang lebih baru.
Optimalkan Group By
Kunci `GROUP BY` menyebabkan data didistribusikan ulang berdasarkan kunci kolom pengelompokan selama komputasi. Jika operasi `GROUP BY` memakan waktu lama, Anda dapat menetapkan kolom `GROUP BY` sebagai kunci distribusi.
-- Jika data didistribusikan berdasarkan nilai pada kolom a, redistribusi data runtime berkurang, dan kemampuan komputasi paralel shard dimanfaatkan secara penuh.
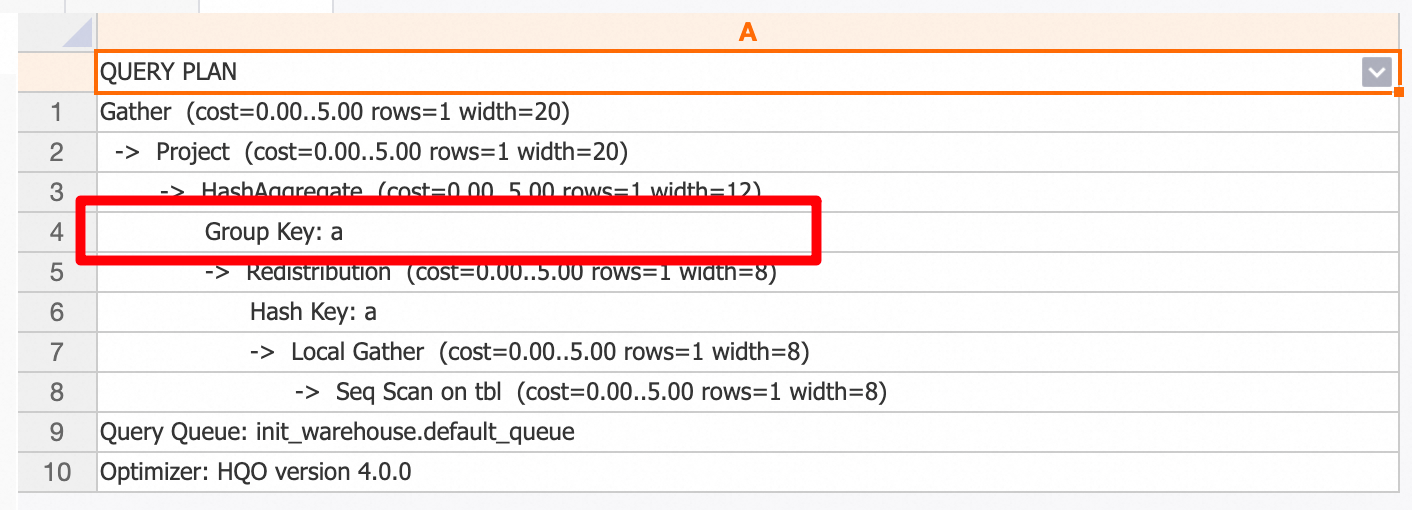
select a, count(1) from t1 group by a; Mulai dari V4.0, optimasi penggabungan tersedia. Optimasi ini mengurangi jumlah kolom pengelompokan saat Anda melakukan `GROUP BY` pada beberapa kolom ekuivalen. Misalnya, kueri dengan GROUP BY COL_A, ((COL_A + 1)), ((COL_A + 2)) ditulis ulang menjadi ekuivalen GROUP BY COL_A. Untuk mengelola biaya eksplorasi, pencarian dilakukan hingga maksimal lima lapisan. Contohnya:
CREATE TABLE tbl (
a int,
b int,
c int
);
-- Kueri
SELECT
a,
a + 1 as a1,
a + 2 as a2,
sum(b)
FROM tbl
GROUP BY
a,
a1,
a2;Rencana eksekusi ditunjukkan pada gambar berikut. Anda dapat melihat bahwa penulisan ulang kueri telah dilakukan, dan klausa GROUP BY hanya berisi kolom `a`.
Anda dapat menonaktifkan fitur ini menggunakan parameter GUC berikut:
-- Nonaktifkan fitur pada tingkat sesi.
SET hg_experimental_remove_related_group_by_key = off;
-- Nonaktifkan fitur pada tingkat database.
ALTER DATABASE <database_name> SET hg_experimental_remove_related_group_by_key = off; Atasi kesenjangan data
Distribusi data yang tidak merata di beberapa shard dapat memperlambat kueri. Anda dapat menjalankan pernyataan berikut untuk menentukan apakah distribusi data miring. Untuk informasi selengkapnya, lihat Lihat hubungan kemiringan worker.
-- hg_shard_id adalah kolom tersembunyi bawaan di setiap tabel yang menjelaskan shard tempat baris data terkait berada.
select hg_shard_id, count(1) from t1 group by hg_shard_id;-
Jika terdapat kesenjangan data yang signifikan, ubah `distribution_key` menjadi kolom dengan distribusi data yang merata dan diskret.
CatatanMengubah `distribution_key` mengharuskan Anda membuat ulang tabel dan mengimpor ulang data.
-
Jika data itu sendiri miring, terlepas dari `distribution_key`, Anda harus mengoptimalkan data dari perspektif bisnis untuk menghindari kemiringan.
Optimalkan dengan ekspresi
Hologres kompatibel dengan PostgreSQL dan mendukung Common Table Expressions (CTEs). CTE sering digunakan dalam kueri rekursif WITH. Seperti PostgreSQL, Hologres mengimplementasikan CTE menggunakan inlining, yang menyebabkan komputasi berulang saat CTE dirujuk beberapa kali. Di Hologres V1.3 dan versi setelahnya, Anda dapat mengaktifkan CTE Reuse menggunakan parameter GUC. Hal ini memungkinkan CTE dihitung hanya sekali dan dirujuk beberapa kali, yang menghemat sumber daya komputasi dan meningkatkan performa kueri. Jika instans Hologres Anda sebelum V1.3, Anda harus melakukan upgrade instans untuk menggunakan fitur ini.
set optimizer_cte_inlining=off;-
Fitur ini tidak diaktifkan secara default. Secara default, semua CTE di-inline dan dihitung ulang. Anda harus mengatur parameter GUC secara manual untuk mengaktifkannya.
-
Setelah CTE Reuse diaktifkan, fitur ini bergantung pada fitur spill pada tahap shuffle. Karena operator downstream mengonsumsi CTE dengan laju berbeda, performa mungkin terpengaruh saat volume data besar.
-
Contoh
create table cte_reuse_test_t ( a integer not null, b text, primary key (a) ); insert into cte_reuse_test_t values(1, 'a'),(2, 'b'), (3, 'c'), (4, 'b'), (5, 'c'), (6, ''), (7, null); set optimizer_cte_inlining=off; explain with c as (select b, max(a) as a from cte_reuse_test_t group by b) select a1.a,a2.a,a1.b, a2.b from c a1, c a2 where a1.b = a2.b order by a1.b limit 100; -
Perbandingan rencana eksekusi
-
Rencana eksekusi untuk versi Hologres sebelum V1.3 (V1.1) sebagai berikut.

-
Rencana eksekusi untuk Hologres V1.3 sebagai berikut.

Perbandingan rencana eksekusi menunjukkan bahwa pada versi sebelum V1.3, beberapa komputasi `AGG` (HashAggregate) dilakukan. Di Hologres V1.3, hasil dihitung hanya sekali lalu digunakan kembali, yang meningkatkan performa.
-
Optimalkan Agg satu tahap menjadi Agg multi-tahap
Jika operator Agg memakan waktu lama, periksa apakah pra-agregasi tingkat shard lokal dilakukan.
Menjalankan operasi Agg lokal dalam setiap shard terlebih dahulu dapat mengurangi jumlah data yang diperlukan untuk operasi agregasi akhir dan meningkatkan performa. Rinciannya sebagai berikut:
-
Agregasi tiga tahap: Data pertama kali diagregasi pada tingkat file, kemudian dalam setiap shard, dan akhirnya hasil dari semua shard dirangkum.
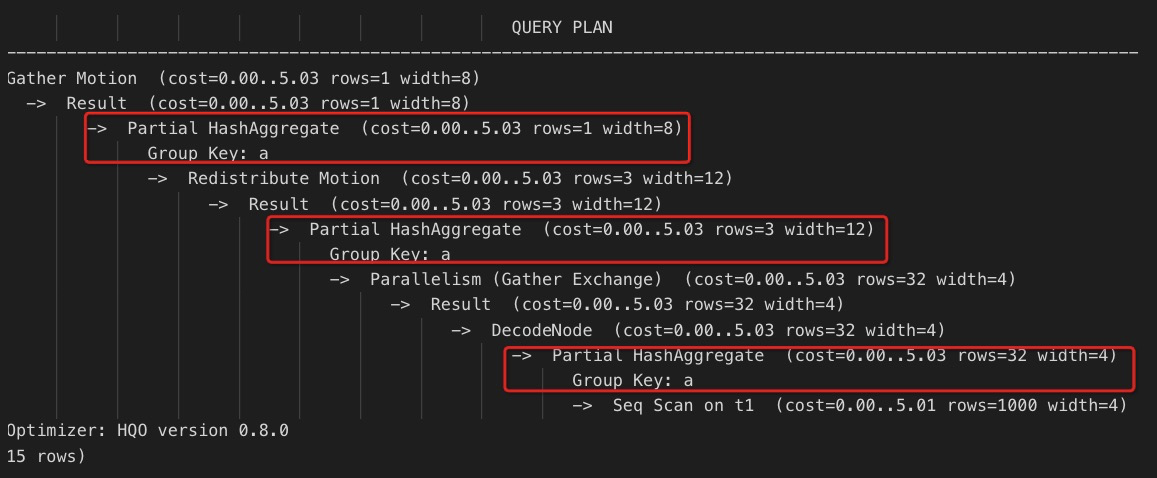
-
Agregasi dua tahap: Data pertama kali diagregasi dalam setiap shard, dan kemudian hasil dari semua shard dirangkum.
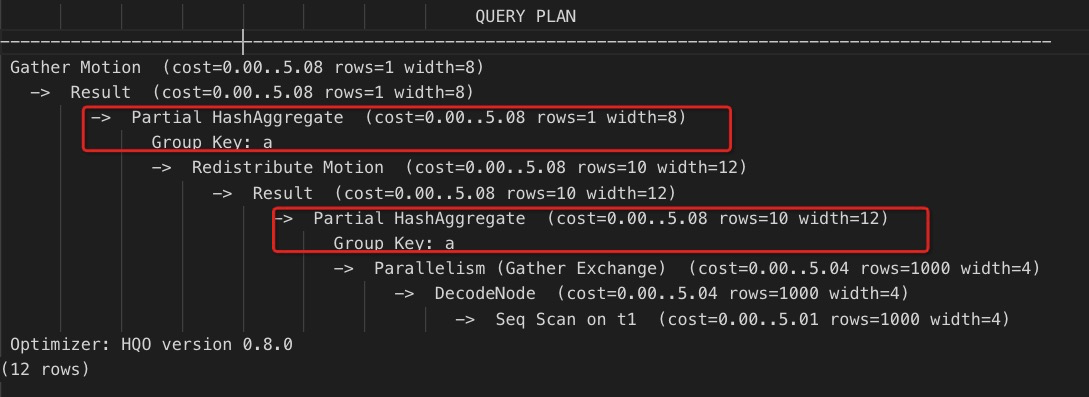
Anda dapat memaksa Hologres melakukan operasi agregasi multi-tahap menggunakan pernyataan berikut.
set optimizer_force_multistage_agg = on;Optimalkan beberapa fungsi agregat dengan nama yang sama
Dalam skenario produksi, pernyataan SQL mungkin berisi beberapa fungsi agregat identik yang mengagregasi kolom yang sama. Mulai dari V4.0, Hologres mendukung penulisan ulang ekuivalen untuk mengurangi jumlah perhitungan dan meningkatkan performa kueri. Berikut adalah contoh penggunaannya:
-
Persiapkan data
-- Buat tabel uji. CREATE TABLE tbl(x int4, y int4); -- Masukkan data uji. INSERT INTO tbl VALUES (1,2), (null,200), (1000,null), (10000,20000); -
Kueri contoh
SELECT sum(x + 1), sum(x + 2), sum(x - 3), sum(x - 4) FROM tbl; -
Rencana eksekusi ditunjukkan pada gambar berikut. Anda dapat melihat bahwa penulisan ulang kueri telah dilakukan, dan data hanya dikelompokkan berdasarkan kolom `a`.
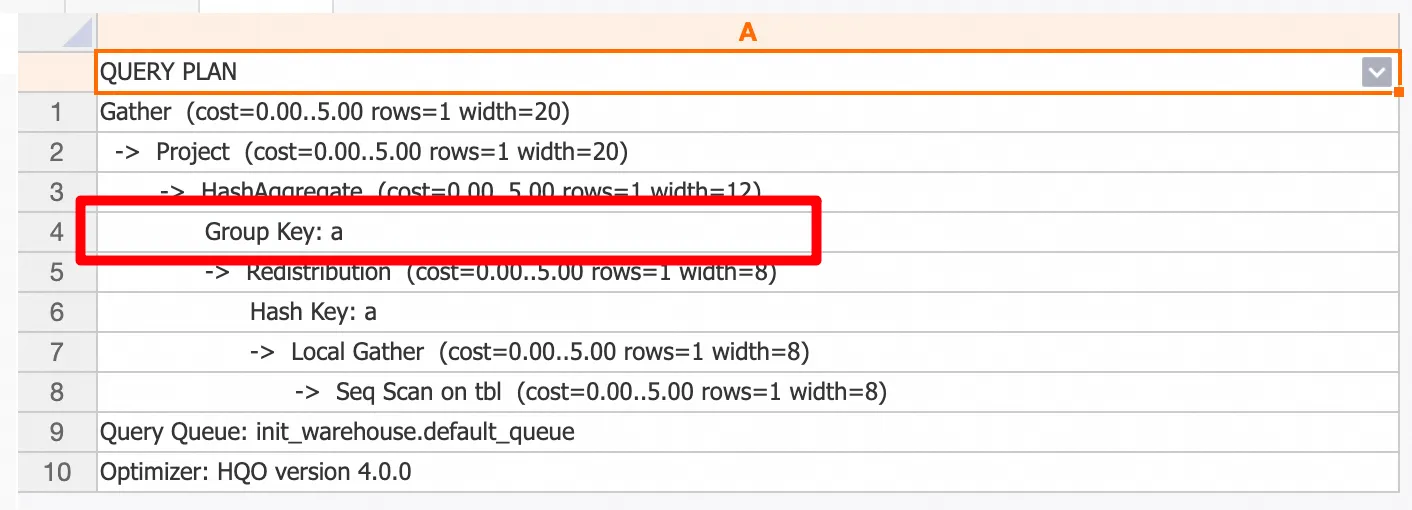
-
Anda dapat menonaktifkan fitur ini menggunakan parameter GUC berikut:
-- Nonaktifkan fitur pada tingkat sesi. SET hg_experimental_remove_related_group_by_key = off; -- Nonaktifkan fitur pada tingkat database. ALTER DATABASE <database_name> SET hg_experimental_remove_related_group_by_key = off;
Optimalkan fungsi jendela pengurutan dalam skenario analisis Top-N
-
Dalam skenario OLAP, mengambil N catatan teratas dalam suatu kelompok merupakan kebutuhan umum. Misalnya, kueri SQL berikut mengambil dua catatan teratas dari tabel
tdalam setiap partisib, diurutkan berdasarkana:CREATE TABLE t ( a int, b int ); INSERT INTO t VALUES (2, 1), (3, 1), (4, 1), (5, 2), (6, 2); SELECT * FROM ( SELECT a, b, row_number() OVER (PARTITION BY b ORDER BY a) AS rn FROM t) t1 WHERE rn <= 2;Hasil eksekusi sebagai berikut:
a b rn 5 2 1 6 2 2 2 1 1 3 1 2 -
Dalam skenario ini, mulai dari Hologres V4.1, operator
Partition Sortdidukung. Operator ini mendukung pengurutan aliran dan mendorong klausaLIMITke dalamPartition. Hal ini memfilter data lebih awal selama pengurutan, yang mengurangi konsumsi memori fungsi jendela pengurutan, sepertirow_numberdanrank, dalam skenario Top-N dan menurunkan probabilitas error OOM kueri. Fitur ini diaktifkan secara default. Anda dapat menonaktifkannya menggunakan parameter GUC berikut:-- Nonaktifkan fitur pada tingkat sesi. SET hg_experimental_enable_hash_partitioned_sort_v2 = off; -- Nonaktifkan fitur pada tingkat database. ALTER DATABASE <database_name> SET hg_experimental_enable_hash_partitioned_sort_v2 = off;
Optimalkan properti tabel
Pilih tipe penyimpanan
Hologres mendukung penyimpanan baris, kolom, dan hybrid baris-kolom. Anda dapat memilih tipe penyimpanan yang sesuai berdasarkan skenario bisnis Anda, seperti yang ditunjukkan pada tabel berikut.
|
Tipe |
Skenario |
Kekurangan |
|
Row store |
|
Performa buruk untuk kueri rentang besar, pemindaian tabel penuh, dan operasi agregasi. |
|
Column store |
Cocok untuk skenario analitik data seperti kueri rentang multi-kolom, agregasi tabel tunggal, dan join multi-tabel. |
Operasi UPDATE dan DELETE serta kueri titik tanpa indeks lebih lambat dibandingkan row store. |
|
Hybrid row-columnar store |
Menggabungkan kasus penggunaan penyimpanan baris dan kolom. |
Overhead penyimpanan lebih tinggi. |
Pilih tipe data
Hologres mendukung berbagai tipe data. Anda dapat memilih tipe data yang sesuai berdasarkan skenario dan kebutuhan bisnis Anda dengan mengikuti prinsip berikut:
-
Gunakan tipe yang menempati ruang penyimpanan lebih sedikit.
-
Gunakan tipe `INT` alih-alih tipe `BIGINT` bila memungkinkan.
-
Gunakan tipe `DECIMAL`/`NUMERIC` presisi. Tentukan presisi numerik (`PRECISION`, `SCALE`) dan pertahankan presisi sekecil mungkin. Kurangi penggunaan tipe non-presisi, seperti `FLOAT` atau `DOUBLE PRECISION`, untuk menghindari kesalahan dalam ringkasan statistik.
-
Jangan gunakan tipe non-presisi, seperti `FLOAT` atau `DOUBLE`, untuk kolom `GROUP BY`.
-
Gunakan tipe `TEXT` karena fleksibilitasnya. Saat menggunakan
VARCHAR(N)atauCHAR(N), pertahankan nilai N sekecil mungkin. -
Gunakan `TIMESTAMPTZ` dan `DATE` untuk tipe tanggal. Hindari penggunaan `TEXT`.
-
-
Gunakan tipe data yang konsisten untuk kondisi join.
Saat melakukan join multi-tabel, gunakan tipe data yang sama untuk kolom join bila memungkinkan. Hal ini menghindari overhead tambahan akibat konversi tipe implisit.
-
Hindari penggunaan tipe non-presisi, seperti `FLOAT` atau `DOUBLE`, untuk operasi seperti `UNION` atau `GROUP BY`.
Operasi seperti `UNION` atau `GROUP BY` tidak mendukung tipe data `DOUBLE PRECISION` dan `FLOAT`. Anda harus menggunakan tipe `DECIMAL` sebagai gantinya.
Pilih kunci primer
Kunci primer terutama digunakan untuk memastikan keunikan data dan cocok untuk skenario impor data yang mungkin berisi kunci primer duplikat. Anda dapat mengatur option untuk memilih metode deduplikasi saat mengimpor data:
-
ignore: Mengabaikan data baru.
-
update: Menimpa data lama dengan data baru.
Menetapkan kunci primer dengan benar dapat membantu pengoptimal menghasilkan rencana eksekusi yang lebih baik dalam beberapa skenario, seperti kueri dengan GROUP BY pk,a,b,c.
Namun, untuk tabel berorientasi kolom, menetapkan kunci primer berdampak signifikan pada performa penulisan data. Biasanya, performa penulisan tabel tanpa kunci primer tiga kali lebih tinggi dibandingkan tabel dengan kunci primer.
Pilih tabel partisi
Hologres saat ini hanya mendukung tabel partisi tingkat tunggal. Menetapkan partisi dengan benar dapat mempercepat performa kueri. Namun, pengaturan yang tidak tepat, seperti membuat terlalu banyak partisi, dapat menghasilkan terlalu banyak file kecil dan secara signifikan menurunkan performa kueri.
Untuk data yang diimpor secara inkremental setiap hari, Anda dapat membuat tabel partisi harian. Datanya disimpan terpisah, sehingga kueri hanya perlu mengakses data hari ini jika diperlukan.
Berikut adalah skenario di mana partisi berlaku:
-
Menghapus seluruh partisi tabel anak tidak memengaruhi data di partisi lain. Pernyataan `DROP` dan `TRUNCATE` berperforma lebih baik daripada pernyataan `DELETE`.
-
Untuk kueri di mana kolom kunci partisi berada dalam kondisi predikat, pengoptimal dapat langsung memindai partisi anak yang sesuai. Hal ini dikenal sebagai pemangkasan partisi dan membuat kueri lebih efisien.
-
Tabel partisi cocok untuk data real-time yang diimpor secara periodik. Misalnya, jika data baru diimpor setiap hari, Anda dapat menggunakan tanggal sebagai kunci partisi dan mengimpor data ke partisi anak baru setiap hari. Berikut adalah contoh pernyataannya.
begin;
create table insert_partition(c1 bigint not null, c2 boolean, c3 float not null, c4 text, c5 timestamptz not null) partition by list(c4);
call set_table_property('insert_partition', 'orientation', 'column');
commit;
create table insert_partition_child1 partition of insert_partition for values in('20190707');
create table insert_partition_child2 partition of insert_partition for values in('20190708');
create table insert_partition_child3 partition of insert_partition for values in('20190709');
select * from insert_partition where c4 >= '20190708';
select * from insert_partition_child3;Pilih indeks
Hologres mendukung berbagai jenis indeks, dan setiap tipe indeks memiliki fungsi berbeda. Anda dapat memilih indeks yang sesuai berdasarkan skenario bisnis untuk meningkatkan performa kueri. Oleh karena itu, Anda harus merancang skema tabel dan indeks berdasarkan skenario bisnis sebelum menulis data. Jenis indeks ditunjukkan pada tabel berikut.
|
Tipe |
Nama |
Deskripsi |
Saran penggunaan |
Kueri contoh |
|
clustering_key |
Clustering key |
Indeks terkluster dalam file. Data dalam file diurutkan berdasarkan indeks ini. Untuk beberapa kueri rentang, Hologres dapat langsung memfilter data berdasarkan properti terurut dari indeks terkluster. |
Tetapkan kolom kueri rentang atau kueri filter sebagai clustering key. Penyaringan indeks mengikuti prinsip pencocokan prefiks paling kiri. Disarankan menetapkan tidak lebih dari dua kolom. |
|
|
bitmap_columns |
Bitmap columns |
Indeks bitmap dalam file. Bitmap dibuat untuk data dalam file berdasarkan kolom indeks ini. Untuk kueri kesetaraan, Hologres dapat meng-encode data setiap baris berdasarkan nilainya dan menggunakan manipulasi bit untuk mengindeks baris yang sesuai dengan cepat. Kompleksitas waktunya adalah O(1). |
Tetapkan kolom kueri kesetaraan sebagai kolom bitmap. |
|
|
segment_key (juga dikenal sebagai event_time_column) |
Segmentation column |
Indeks file. Data ditulis ke file secara append-only, lalu file kecil digabung berdasarkan kunci indeks ini. segment_key mengidentifikasi rentang batas file. Anda dapat menggunakan segment key untuk mengindeks file objek dengan cepat. segment_key dirancang untuk skenario data berbasis rentang yang terurut seperti timestamp dan tanggal, sehingga sangat berkorelasi dengan waktu penulisan data. |
Pertama, lakukan filter cepat menggunakan segment_key, lalu lakukan kueri rentang atau kesetaraan dalam file menggunakan indeks bitmap atau cluster. Mengikuti prinsip pencocokan prefiks paling kiri dan biasanya hanya memiliki satu kolom. Tetapkan bidang timestamp pertama yang tidak kosong sebagai segment_key. |
|
`clustering_key` dan `segment_key` harus mengikuti prinsip pencocokan prefiks paling kiri database tradisional, seperti MySQL. Artinya, pengindeksan dilakukan berdasarkan urutan kolom yang ditentukan dalam definisi indeks. Jika nilai pada kolom paling kiri sama, kolom kedua dari kiri digunakan untuk pengurutan, dan seterusnya. Berikut adalah contohnya.
call set_table_property('tmp', 'clustering_key', 'a,b,c');
select * from tmp where a > 1 ; --Indeks cluster dapat digunakan.
select * from tmp where a > 1 and c > 2 ; --Hanya a yang dapat menggunakan indeks cluster.
select * from tmp where a > 1 and b > 2 ; --Baik a maupun b dapat menggunakan indeks cluster.
select * from tmp where a > 1 and b > 2 and c > 3 ; --a, b, dan c semuanya dapat menggunakan indeks cluster.
select * from tmp where b > 1 and c > 2 ; --Baik b maupun c tidak dapat menggunakan indeks cluster.Indeks bitmap mendukung kueri `AND` atau `OR` pada beberapa kolom. Berikut adalah contohnya.
call set_table_property('tmp', 'bitmap_columns', 'a,b,c');
select * from tmp where a = 1 and b = 2 ; -- Indeks bitmap dapat digunakan.
select * from tmp where a = 1 or b = 2 ; -- Indeks bitmap dapat digunakan.`bitmap_columns` dapat ditambahkan setelah tabel dibuat. `clustering_key` dan `segment_key` harus ditentukan saat tabel dibuat dan tidak dapat ditambahkan kemudian.
Periksa penggunaan indeks
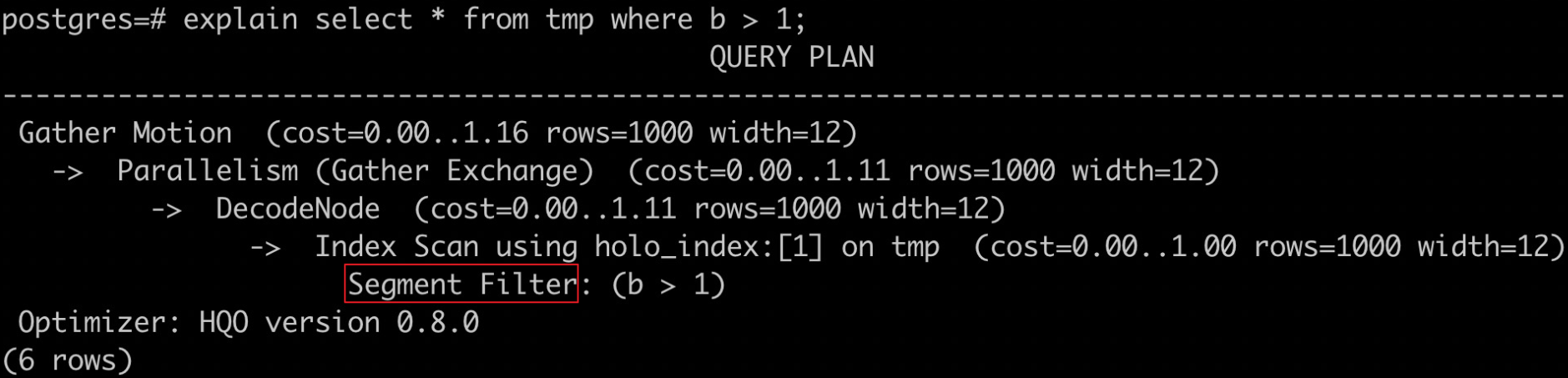
Buat tabel tmp dan tentukan bidang indeks menggunakan pernyataan berikut.
begin;
create table tmp(a int not null, b int not null, c int not null);
call set_table_property('tmp', 'clustering_key', 'a');
call set_table_property('tmp', 'segment_key', 'b');
call set_table_property('tmp', 'bitmap_columns', 'a,b,c');
commit;-
Periksa apakah indeks cluster digunakan menggunakan pernyataan berikut.
explain select * from tmp where a > 1;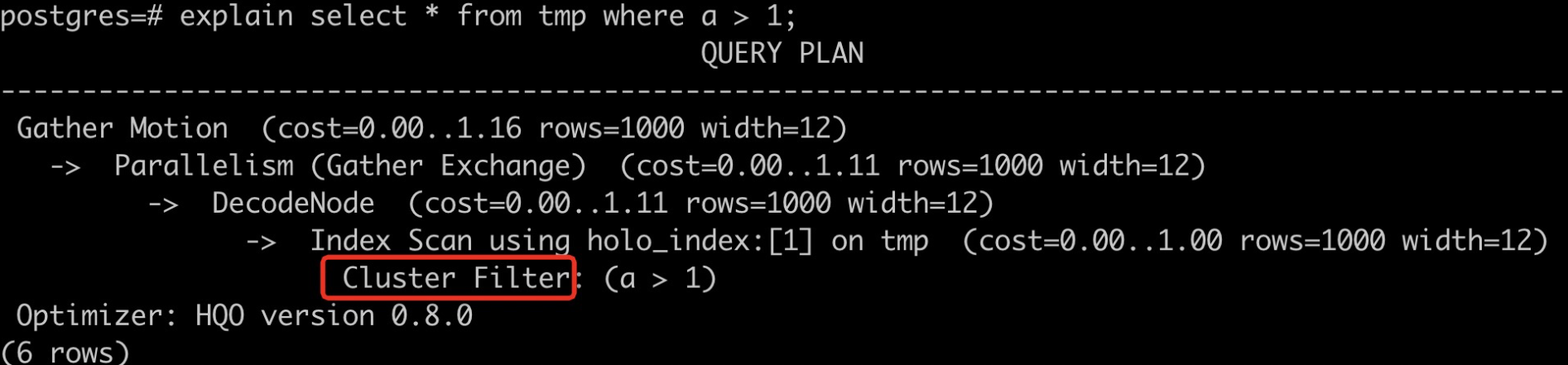
-
Periksa apakah indeks bitmap digunakan menggunakan pernyataan berikut.
explain select * from tmp where c = 1;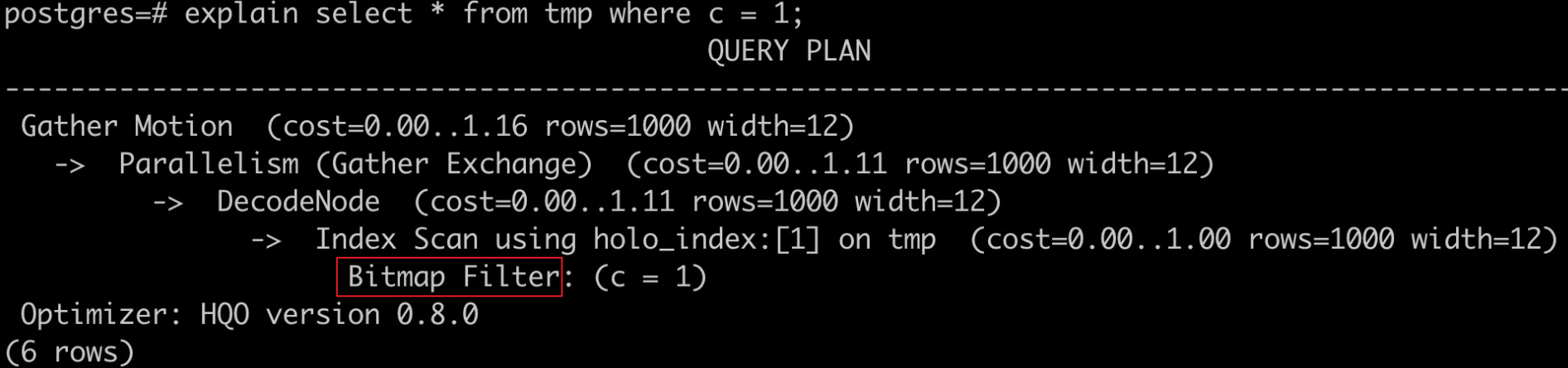
-
Periksa apakah segment key digunakan menggunakan pernyataan berikut.
explain select * from tmp where b > 1;