Topik ini menjelaskan cara menggunakan Clustering Key di Hologres.
Pengenalan Clustering Key
Hologres mengurutkan data dalam file berdasarkan Clustering Key. Penetapan Clustering Key dapat mempercepat kueri rentang (range) dan filter pada kolom yang diindeks. Anda dapat menggunakan sintaks berikut untuk menetapkan Clustering Key saat membuat tabel.
-- Sintaks yang didukung di Hologres V2.1 dan versi lebih baru
CREATE TABLE <table_name> (...) WITH (clustering_key = '[<columnName>[,...]]');
-- Sintaks yang didukung di semua versi
BEGIN;
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'clustering_key', '[<columnName>{:asc} [,...]]');
COMMIT;Deskripsi parameter:
Parameter | Deskripsi |
table_name | Nama tabel tempat Anda ingin menetapkan Clustering Key. |
columnName | Nama bidang yang akan digunakan sebagai Clustering Key. |
Rekomendasi penggunaan
Clustering Key ideal untuk kueri titik (point queries) dan kueri rentang (range queries). Fitur ini secara signifikan meningkatkan performa operasi filter, seperti kueri dengan
where a = 1atauwhere a > 1 and a < 5. Anda dapat menetapkan Clustering Key dan Bitmap Column sekaligus untuk mencapai performa optimal pada kueri titik.Clustering Key mengikuti prinsip pencocokan awalan kiri (left-prefix matching). Oleh karena itu, hindari menetapkan lebih dari dua bidang sebagai Clustering Key agar tidak membatasi skenario penerapannya. Karena Clustering Key digunakan untuk pengurutan, urutan kolom dalam key tersebut sangat penting—kolom yang disebut lebih awal memiliki prioritas pengurutan yang lebih tinggi.
Saat menentukan bidang Clustering Key, Anda dapat menambahkan
:ascsetelah nama bidang untuk menetapkan arah pengurutan saat pembuatan indeks. Arah pengurutan default adalahasc, yang berarti urutan menaik. Pada versi Hologres sebelum V2.1, Anda tidak dapat menetapkan arah pengurutan menjadi menurun (desc). Jika Anda menetapkan arah pengurutan ke menurun, Clustering Key tidak akan terpakai, sehingga menyebabkan performa kueri buruk. Mulai dari Hologres V2.1, Anda dapat menetapkan Clustering Key kedescsetelah mengaktifkan parameter Grand Unified Configuration (GUC) berikut. Namun, fitur ini hanya didukung untuk bidang dengan tipe data seperti Text, Char, Varchar, Bytea, dan Int. Bidang dengan tipe data lain saat ini tidak mendukung penyetelan Clustering Key kedesc.set hg_experimental_optimizer_enable_variable_length_desc_ck_filter = on;Untuk tabel berorientasi baris (row-oriented tables), Clustering Key secara default menggunakan primary key. Pada versi Hologres sebelum V0.9, tidak ada nilai default yang ditetapkan. Jika Anda menetapkan Clustering Key yang berbeda dari primary key, Hologres akan membuat dua urutan pengurutan untuk tabel tersebut (satu untuk primary key dan satu untuk Clustering Key), yang menyebabkan redundansi data.
Batasan
Untuk mengubah Clustering Key, Anda harus membuat ulang tabel dan mengimpor data kembali.
Clustering Key harus berupa kolom `NOT NULL` atau kombinasi kolom `NOT NULL`. Versi Hologres dari V1.3.20 hingga V1.3.27 mendukung Clustering Key yang nullable. Mulai dari V1.3.28, Clustering Key nullable tidak lagi didukung karena dapat memengaruhi kebenaran data. Jika bisnis Anda memerlukan Clustering Key yang nullable, Anda dapat menambahkan parameter berikut sebelum pernyataan SQL Anda.
set hg_experimental_enable_nullable_clustering_key = true;Tipe data berikut tidak didukung untuk Clustering Key: Float, Float4, Float8, Double, Decimal(Numeric), Json, Jsonb, Bit, Varbit, Money, Time With Time Zone, dan tipe data kompleks lainnya.
Versi Hologres sebelum V2.1 tidak mendukung penyetelan arah pengurutan ke menurun (
desc) saat pembuatan indeks. Menetapkan arah pengurutan ke menurun mencegah Clustering Key terpakai dan mengakibatkan performa kueri buruk. Mulai dari V2.1, Anda dapat menetapkan Clustering Key kedescsetelah mengaktifkan parameter GUC berikut. Namun, fitur ini hanya didukung untuk bidang dengan tipe data seperti Text, Char, Varchar, Bytea, dan Int. Bidang dengan tipe data lain saat ini tidak mendukung penyetelan Clustering Key kedesc.set hg_experimental_optimizer_enable_variable_length_desc_ck_filter = on;Untuk tabel berorientasi kolom (column-oriented tables), Clustering Key secara default kosong. Anda harus menentukannya secara eksplisit sesuai skenario bisnis Anda.
Di Hologres, Anda hanya dapat menetapkan satu Clustering Key untuk setiap tabel. Artinya, Anda hanya dapat menggunakan perintah
callsatu kali saat membuat tabel. Anda tidak dapat menjalankan perintah tersebut beberapa kali. Lihat contoh berikut:Sintaks yang didukung di V2.1 dan versi lebih baru:
--Contoh yang benar CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a,b' ); --Contoh yang salah CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a', clustering_key = 'b' );Sintaks yang didukung di semua versi:
--Contoh yang benar BEGIN; CREATE TABLE tbl (a int NOT NULL, b text NOT NULL); CALL set_table_property('tbl', 'clustering_key', 'a,b'); COMMIT; --Contoh yang salah BEGIN; CREATE TABLE tbl (a int NOT NULL, b text NOT NULL); CALL set_table_property('tbl', 'clustering_key', 'a'); CALL set_table_property('tbl', 'clustering_key', 'b'); COMMIT;
Prinsip teknis
Dari segi penyimpanan fisik, Clustering Key mengurutkan data dalam file. Urutan default adalah menaik (asc). Bagian berikut mengilustrasikan konsep tata letak Clustering Key.
Tata Letak Logis
Kueri Clustering Key mengikuti prinsip pencocokan awalan kiri (left-prefix matching). Jika suatu kueri tidak cocok dengan awalan tersebut, kueri tersebut tidak dapat menggunakan Clustering Key untuk percepatan. Skenario berikut mengilustrasikan tata letak logis Clustering Key di Hologres.
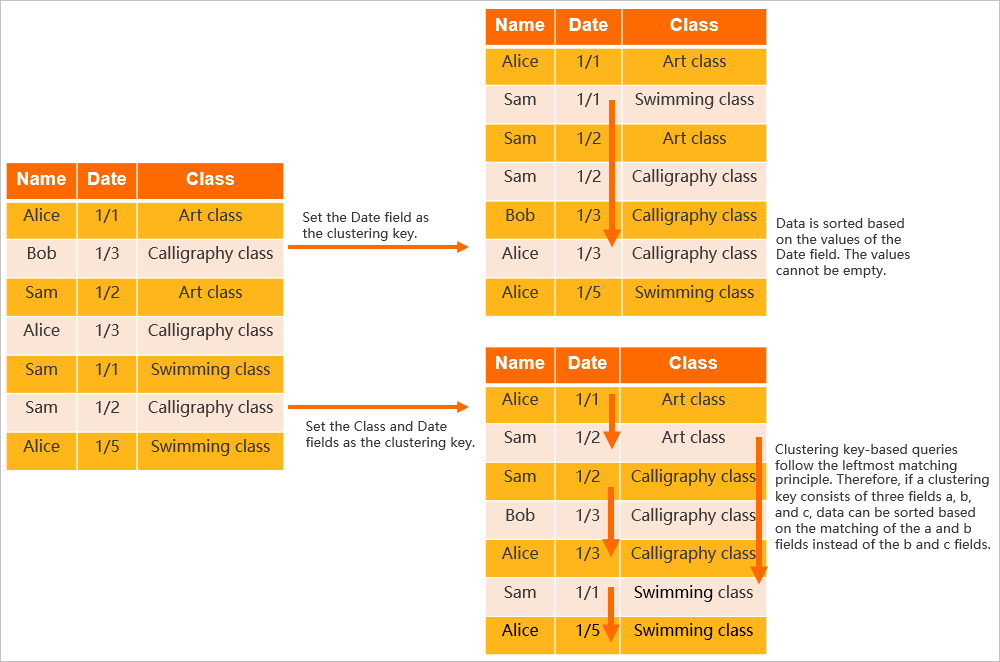
Pertimbangkan sebuah tabel dengan bidang Name, Date, dan Class.
Jika Anda menetapkan Date sebagai Clustering Key, data dalam tabel diurutkan berdasarkan tanggal.
Jika Anda menetapkan Class dan Date sebagai Clustering Key, data diurutkan terlebih dahulu berdasarkan kelas lalu berdasarkan tanggal.
Penetapan bidang yang berbeda sebagai Clustering Key menghasilkan tata letak data yang berbeda, seperti yang ditunjukkan pada gambar berikut.
Tata Letak Penyimpanan Fisik
Tata letak penyimpanan fisik Clustering Key ditunjukkan pada gambar berikut.
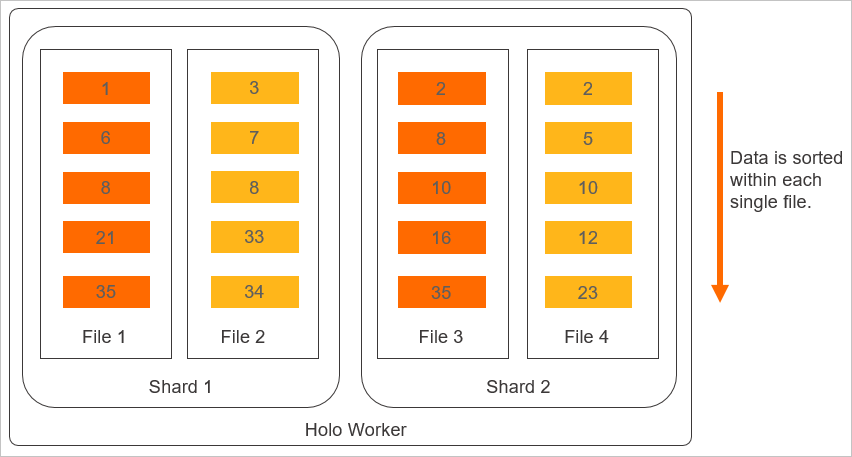
Prinsip tata letak Clustering Key menunjukkan bahwa:
Clustering Key sangat cocok untuk skenario filtering rentang karena secara signifikan meningkatkan performa kueri dengan kondisi seperti
where date= 1/1atauwhere a > 1/1 and a < 1/5.Kueri Clustering Key mengikuti prinsip pencocokan awalan kiri. Jika suatu kueri tidak cocok dengan awalan tersebut, kueri tersebut tidak dapat menggunakan Clustering Key untuk percepatan. Misalnya, jika Anda menetapkan kolom
a,b,csebagai Clustering Key, kueri padaa,b,cataua,bdapat memanfaatkan Clustering Key. Jika Anda melakukan kueri padaa,c, hanyaayang dapat memanfaatkan Clustering Key. Jika Anda melakukan kueri padab,c, Clustering Key tidak dapat dimanfaatkan.
Pada contoh berikut, kolom uid,class,date ditetapkan sebagai Clustering Key.
Sintaks yang didukung di V2.1 dan versi lebih baru:
CREATE TABLE clustering_test ( uid int NOT NULL, name text NOT NULL, class text NOT NULL, date text NOT NULL, PRIMARY KEY (uid) ) WITH ( clustering_key = 'uid,class,date' ); INSERT INTO clustering_test VALUES (1,'Zhang San','1','2022-10-19'), (2,'Li Si','3','2022-10-19'), (3,'Wang Wu','2','2022-10-20'), (4,'Zhao Liu','2','2022-10-20'), (5,'Sun Qi','2','2022-10-18'), (6,'Zhou Ba','3','2022-10-17'), (7,'Wu Jiu','3','2022-10-20');Sintaks yang didukung di semua versi:
BEGIN; CREATE TABLE clustering_test ( uid int NOT NULL, name text NOT NULL, class text NOT NULL, date text NOT NULL, PRIMARY KEY (uid) ); CALL set_table_property('clustering_test', 'clustering_key', 'uid,class,date'); COMMIT; INSERT INTO clustering_test VALUES (1,'Zhang San','1','2022-10-19'), (2,'Li Si','3','2022-10-19'), (3,'Wang Wu','2','2022-10-20'), (4,'Zhao Liu','2','2022-10-20'), (5,'Sun Qi','2','2022-10-18'), (6,'Zhou Ba','3','2022-10-17'), (7,'Wu Jiu','3','2022-10-20');
Kueri hanya pada kolom
uiddapat memanfaatkan Clustering Key.SELECT * FROM clustering_test WHERE uid > '3';Jika Anda melihat rencana eksekusi (explain SQL), rencana tersebut berisi operator
Cluster Filter. Ini menunjukkan bahwa Clustering Key dimanfaatkan dan kueri dipercepat.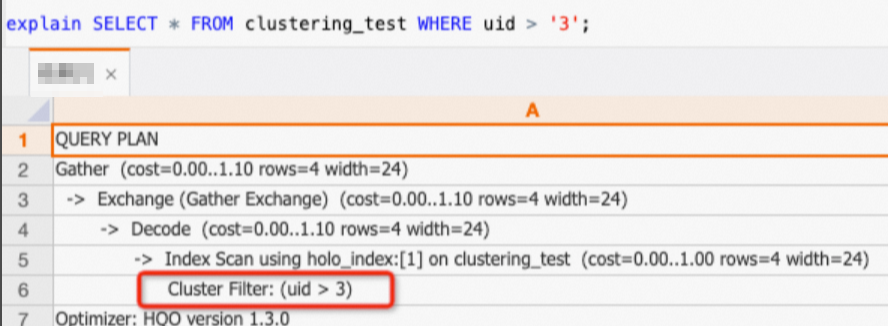
Kueri pada kolom
uid,classdapat memanfaatkan Clustering Key.SELECT * FROM clustering_test WHERE uid = '3' AND class >'1' ;Jika Anda melihat rencana eksekusi (explain SQL), rencana tersebut berisi operator
Cluster Filter. Ini menunjukkan bahwa Clustering Key dimanfaatkan dan kueri dipercepat.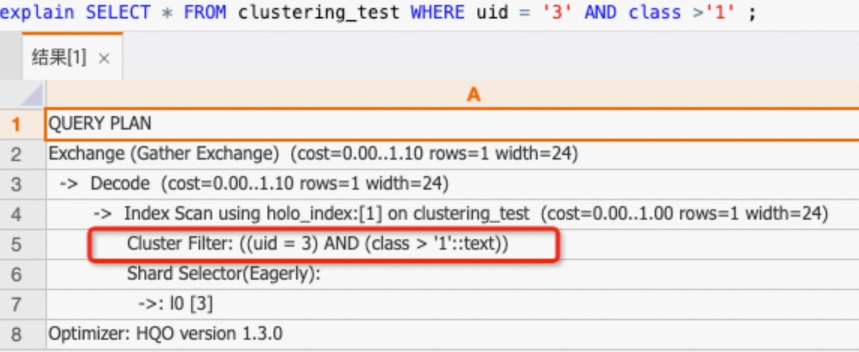
Kueri pada kolom
uid,class,datedapat memanfaatkan Clustering Key.SELECT * FROM clustering_test WHERE uid = '3' AND class ='2' AND date > '2022-10-17';Jika Anda melihat rencana eksekusi (explain SQL), rencana tersebut berisi operator
Cluster Filter. Ini menunjukkan bahwa Clustering Key dimanfaatkan dan kueri dipercepat.
Kueri pada kolom
uid,datetidak mengikuti prinsip pencocokan awalan kiri. Oleh karena itu, hanyauidyang dapat memanfaatkan Clustering Key. Kolomdatediproses dengan filter biasa.SELECT * FROM clustering_test WHERE uid = '3' AND date > '2022-10-17';Jika Anda melihat rencana eksekusi (explain SQL), rencana tersebut menunjukkan bahwa hanya kolom uid yang memiliki operator
Cluster Filter.
Kueri hanya pada kolom
class,datetidak dapat memanfaatkan Clustering Key karena tidak mengikuti prinsip pencocokan awalan paling kiri.SELECT * FROM clustering_test WHERE class ='2' AND date > '2022-10-17';Jika Anda melihat rencana eksekusi (explain SQL), Anda dapat melihat bahwa rencana tersebut tidak berisi operator
Cluster Filter. Ini menunjukkan bahwa Clustering Key tidak dimanfaatkan.
Contoh penggunaan
Contoh 1: Skenario di mana Clustering Key dimanfaatkan.
Sintaks yang didukung di V2.1 dan versi lebih baru:
CREATE TABLE table1 ( col1 int NOT NULL, col2 text NOT NULL, col3 text NOT NULL, col4 text NOT NULL ) WITH ( clustering_key = 'col1,col2' ); --Untuk tabel yang dibuat dengan pernyataan SQL di atas, kueri berikut dapat dipercepat: -- Dapat dipercepat select * from table1 where col1='abc'; -- Dapat dipercepat select * from table1 where col1>'xxx' and col1<'abc'; -- Dapat dipercepat select * from table1 where col1 in ('abc','def'); -- Dapat dipercepat select * from table1 where col1='abc' and col2='def'; -- Tidak dapat dipercepat select col1,col4 from table1 where col2='def';Sintaks yang didukung di semua versi:
begin; create table table1 ( col1 int not null, col2 text not null, col3 text not null, col4 text not null ); call set_table_property('table1', 'clustering_key', 'col1,col2'); commit; --Untuk tabel yang dibuat dengan pernyataan SQL di atas, kueri berikut dapat dipercepat: -- Dapat dipercepat select * from table1 where col1='abc'; -- Dapat dipercepat select * from table1 where col1>'xxx' and col1<'abc'; -- Dapat dipercepat select * from table1 where col1 in ('abc','def'); -- Dapat dipercepat select * from table1 where col1='abc' and col2='def'; -- Tidak dapat dipercepat select col1,col4 from table1 where col2='def';
Contoh 2: Menetapkan Clustering Key ke asc/desc.
Sintaks yang didukung di V2.1 dan versi lebih baru:
CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a:desc,b:asc' );Sintaks yang didukung di semua versi:
BEGIN; CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ); CALL set_table_property('tbl', 'clustering_key', 'a:desc,b:asc'); COMMIT;
Metode tuning lanjutan
Berbeda dengan clustered indexes di database tradisional seperti MySQL atau SQL Server, Hologres hanya mengurutkan data dalam file, bukan di seluruh tabel. Oleh karena itu, menjalankan operasi order by pada Clustering Key tetap memiliki overhead tertentu.
Hologres V1.3 dan versi lebih baru mencakup banyak optimasi performa untuk skenario Clustering Key guna memberikan performa yang lebih baik. Optimasi utama difokuskan pada dua skenario berikut. Jika Anda menggunakan versi sebelum 1.3, Anda dapat mengirimkan masukan Anda. Untuk informasi selengkapnya, lihat Kegagalan persiapan upgrade umum. Anda juga dapat bergabung dengan grup DingTalk Hologres untuk memberikan masukan. Untuk informasi selengkapnya, lihat Bagaimana cara mendapatkan dukungan online lebih lanjut?.
Skenario Order By pada Clustering Keys
Di Hologres, data dalam file diurutkan sesuai definisi Clustering Key. Sebelum V1.3, pengoptimal (optimizer) tidak dapat menggunakan urutan terurut ini untuk menghasilkan rencana eksekusi yang optimal. Selain itu, data yang melewati node Shuffle tidak dijamin tetap terurut (multi-way merge). Hal ini sering menyebabkan komputasi yang lebih tinggi dan waktu kueri yang lebih lama. Hologres V1.3 mengoptimalkan proses ini. Fitur ini memastikan bahwa rencana eksekusi yang dihasilkan dapat memanfaatkan urutan terurut Clustering Key dan mempertahankan urutan tersebut di seluruh node Shuffle, sehingga meningkatkan performa kueri. Perhatikan hal berikut:
Saat tabel tidak difilter berdasarkan Clustering Keys, sistem secara default melakukan SeqScan, bukan IndexScan. Hanya IndexScan yang memanfaatkan properti terurut Clustering Keys.
Pengoptimal tidak selalu menghasilkan rencana eksekusi berdasarkan urutan terurut Clustering Keys. Hal ini karena penggunaan urutan terurut memiliki overhead tertentu. Data diurutkan dalam file tetapi memerlukan pengurutan tambahan di memori.
Berikut adalah contohnya.
DDL tabel adalah sebagai berikut.
Sintaks yang didukung di V2.1 dan versi lebih baru:
DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys; CREATE TABLE test_use_sort_info_of_clustering_keys ( a int NOT NULL, b int NOT NULL, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys SELECT i%500, i%100, i::text FROM generate_series(1, 1000) as s(i); ANALYZE test_use_sort_info_of_clustering_keys;Sintaks yang didukung di semua versi:
DROP TABLE jika ada test_use_sort_info_of_clustering_keys; BEGIN; CREATE TABLE test_use_sort_info_of_clustering_keys ( a int NOT NULL, b int NOT NULL, c text ); CALL set_table_property('test_use_sort_info_of_clustering_keys', 'distribution_key', 'a'); CALL set_table_property('test_use_sort_info_of_clustering_keys', 'clustering_key', 'a,b'); COMMIT; INSERT INTO test_use_sort_info_of_clustering_keys SELECT i%500, i%100, i::text FROM generate_series(1, 1000) as s(i); ANALYZE test_use_sort_info_of_clustering_keys;Pernyataan kueri.
explain select * from test_use_sort_info_of_clustering_keys where a > 100 order by a, b;Perbandingan rencana eksekusi
Rencana eksekusi untuk versi sebelum V1.3 (V1.1) adalah sebagai berikut. Anda dapat menjalankan pernyataan
explainSQL.Sort (cost=0.00..0.00 rows=797 width=11) -> Gather (cost=0.00..2.48 rows=797 width=11) Sort Key: a, b -> Sort (cost=0.00..2.44 rows=797 width=11) Sort Key: a, b -> Exchange (Gather Exchange) (cost=0.00..1.11 rows=797 width=11) -> Decode (cost=0.00..1.11 rows=797 width=11) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys (cost=0.00..1.00 rows=797 width=11) Cluster Filter: (a > 100)Rencana eksekusi untuk V1.3 adalah sebagai berikut.
Gather (cost=0.00..1.15 rows=797 width=11) Merge Key: a, b -> Exchange (Gather Exchange) (cost=0.00..1.11 rows=797 width=11) Merge Key: a, b -> Decode (cost=0.00..1.11 rows=797 width=11) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys (cost=0.00..1.01 rows=797 width=11) Order by: a, b Cluster Filter: (a > 100)
Dibandingkan dengan rencana di versi sebelumnya, rencana eksekusi di V1.3 memanfaatkan urutan terurut Clustering Key tabel untuk langsung melakukan output merge. Hal ini memungkinkan seluruh eksekusi berjalan secara pipelined dan mencegah pengurutan lambat saat menangani data dalam jumlah besar. Perbandingan rencana eksekusi menunjukkan bahwa V1.3 menghasilkan Groupagg, yang lebih sederhana dan berperforma lebih baik daripada Hashagg.
Skenario Join pada Clustering Keys (Beta)
Hologres V1.3 memperkenalkan jenis join SortMergeJoin. Jenis join ini memastikan bahwa rencana eksekusi dapat memanfaatkan urutan terurut Clustering Key untuk mengurangi komputasi dan meningkatkan performa. Perhatikan hal berikut:
Fitur ini masih dalam status Beta dan dinonaktifkan secara default. Untuk mengaktifkannya, Anda dapat menambahkan parameter berikut sebelum kueri Anda.
-- Aktifkan merge join set hg_experimental_enable_sort_merge_join=on;Saat tabel tidak difilter berdasarkan Clustering Keys, sistem secara default melakukan SeqScan, bukan IndexScan. Hanya IndexScan yang memanfaatkan properti terurut Clustering Keys.
Pengoptimal tidak selalu menghasilkan rencana eksekusi berdasarkan urutan terurut Clustering Keys. Hal ini karena penggunaan urutan terurut memiliki overhead tertentu. Data diurutkan dalam file tetapi memerlukan pengurutan tambahan di memori.
Berikut adalah contohnya.
DDL tabel adalah sebagai berikut.
Sintaks yang didukung di V2.1 dan versi lebih baru:
DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys1; CREATE TABLE test_use_sort_info_of_clustering_keys1 ( a int, b int, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys1 SELECT i % 500, i % 100, i::text FROM generate_series(1, 10000) AS s(i); ANALYZE test_use_sort_info_of_clustering_keys1; DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys2; CREATE TABLE test_use_sort_info_of_clustering_keys2 ( a int, b int, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys2 SELECT i % 600, i % 200, i::text FROM generate_series(1, 10000) AS s(i); ANALYZE test_use_sort_info_of_clustering_keys2;Sintaks yang didukung di semua versi:
drop table if exists test_use_sort_info_of_clustering_keys1; begin; create table test_use_sort_info_of_clustering_keys1 ( a int, b int, c text ); call set_table_property('test_use_sort_info_of_clustering_keys1', 'distribution_key', 'a'); call set_table_property('test_use_sort_info_of_clustering_keys1', 'clustering_key', 'a,b'); commit; insert into test_use_sort_info_of_clustering_keys1 select i%500, i%100, i::text from generate_series(1, 10000) as s(i); analyze test_use_sort_info_of_clustering_keys1; drop table if exists test_use_sort_info_of_clustering_keys2; begin; create table test_use_sort_info_of_clustering_keys2 ( a int, b int, c text ); call set_table_property('test_use_sort_info_of_clustering_keys2', 'distribution_key', 'a'); call set_table_property('test_use_sort_info_of_clustering_keys2', 'clustering_key', 'a,b'); commit; insert into test_use_sort_info_of_clustering_keys2 select i%600, i%200, i::text from generate_series(1, 10000) as s(i); analyze test_use_sort_info_of_clustering_keys2;Pernyataan kueri adalah sebagai berikut.
explain select * from test_use_sort_info_of_clustering_keys1 a join test_use_sort_info_of_clustering_keys2 b on a.a = b.a and a.b=b.b where a.a > 100 and b.a < 300;Perbandingan rencana eksekusi
Rencana eksekusi untuk versi sebelum V1.3 (V1.1) adalah sebagai berikut.
Gather (cost=0.00..3.09 rows=4762 width=24) -> Hash Join (cost=0.00..2.67 rows=4762 width=24) Hash Cond: ((test_use_sort_info_of_clustering_keys1.a = test_use_sort_info_of_clustering_keys2.a) AND (test_use_sort_info_of_clustering_keys1.b = test_use_sort_info_of_clustering_keys2.b)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3993 width=12) -> Decode (cost=0.00..1.14 rows=3993 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys1 (cost=0.00..1.01 rows=3993 width=12) Cluster Filter: ((a > 100) AND (a < 300)) -> Hash (cost=1.13..1.13 rows=3386 width=12) -> Exchange (Gather Exchange) (cost=0.00..1.13 rows=3386 width=12) -> Decode (cost=0.00..1.13 rows=3386 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys2 (cost=0.00..1.01 rows=3386 width=12) Cluster Filter: ((a > 100) AND (a < 300))Rencana eksekusi untuk V1.3 adalah sebagai berikut.
Gather (cost=0.00..2.88 rows=4762 width=24) -> Merge Join (cost=0.00..2.46 rows=4762 width=24) Merge Cond: ((test_use_sort_info_of_clustering_keys2.a = test_use_sort_info_of_clustering_keys1.a) AND (test_use_sort_info_of_clustering_keys2.b = test_use_sort_info_of_clustering_keys1.b)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3386 width=12) Merge Key: test_use_sort_info_of_clustering_keys2.a, test_use_sort_info_of_clustering_keys2.b -> Decode (cost=0.00..1.14 rows=3386 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys2 (cost=0.00..1.01 rows=3386 width=12) Order by: test_use_sort_info_of_clustering_keys2.a, test_use_sort_info_of_clustering_keys2.b Cluster Filter: ((a > 100) AND (a < 300)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3993 width=12) Merge Key: test_use_sort_info_of_clustering_keys1.a, test_use_sort_info_of_clustering_keys1.b -> Decode (cost=0.00..1.14 rows=3993 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys1 (cost=0.00..1.01 rows=3993 width=12) Order by: test_use_sort_info_of_clustering_keys1.a, test_use_sort_info_of_clustering_keys1.b Cluster Filter: ((a > 100) AND (a < 300))
Dibandingkan dengan rencana di versi sebelumnya, rencana eksekusi di V1.3 memanfaatkan urutan terurut Clustering Key. Fitur ini melakukan pengurutan gabungan (merge sort) dalam setiap shard lalu langsung menjalankan SortMergeJoin. Hal ini memungkinkan seluruh eksekusi berjalan secara pipelined. Fitur ini juga menghindari masalah kehabisan memori (OOM) yang dapat terjadi pada HashJoin ketika sisi hash terlalu besar untuk dimuat ke dalam memori.
Referensi
Untuk informasi selengkapnya tentang pernyataan Data Definition Language (DDL) untuk tabel internal Hologres, lihat topik berikut: