Topik ini menjelaskan cara melakukan migrasi kluster ClickHouse yang dikelola sendiri ke ApsaraDB for ClickHouse Enterprise Edition menggunakan konsol atau secara manual.
Prasyarat
Kluster yang dikelola sendiri: Anda telah membuat akun database dan kata sandi. Akun tersebut harus memiliki izin baca pada database dan tabel serta hak istimewa untuk mengeksekusi perintah SYSTEM. Jika Anda perlu melakukan migrasi tabel eksternal yang mencakup kredensial akun, akun tersebut juga harus memiliki hak istimewa
displaySecretsInShowAndSelect.Kluster target: Anda telah membuat akun database dan kata sandi serta memastikan bahwa akun tersebut memiliki hak istimewa tertinggi.
Konektivitas jaringan
Jika kluster yang dikelola sendiri dan kluster target berada dalam VPC yang sama, tambahkan alamat IP semua node di kluster target dan blok CIDR IPv4 dari switch node tersebut ke daftar putih kluster yang dikelola sendiri.
Untuk mengetahui cara mengonfigurasi daftar putih untuk kluster ApsaraDB for ClickHouse, lihat Konfigurasi daftar putih.
Untuk mengonfigurasi daftar putih kluster yang dikelola sendiri, lihat dokumentasi produknya.
Jalankan perintah
SELECT * FROM system.clusters WHERE internal_replication = 1;untuk mengkueri alamat IP semua node di kluster ApsaraDB for ClickHouse.
Jika kluster yang dikelola sendiri dan kluster target berada dalam VPC yang berbeda, atau jika kluster yang dikelola sendiri berada di pusat data lokal (on-premises IDC) atau dihosting oleh penyedia cloud lain, terlebih dahulu selesaikan masalah konektivitas jaringan. Untuk informasi lebih lanjut, lihat Menetapkan konektivitas jaringan antara kluster target dan sumber data.
CatatanDalam skenario ini, Anda dapat menggunakan pemetaan IP untuk mencegah konflik blok CIDR antar-VPC yang berbeda. Jika Anda menggunakan pemetaan IP, Anda juga harus menambahkan alamat IP yang dipetakan ke daftar putih kedua kluster.
Validasi migrasi
Sebelum memulai migrasi data, kami sangat menyarankan untuk membuat lingkungan pengujian guna memvalidasi kompatibilitas, performa, dan kelayakan migrasi. Lakukan migrasi data di lingkungan produksi hanya setelah validasi ini selesai. Langkah ini sangat penting karena membantu Anda mengidentifikasi dan menyelesaikan potensi masalah lebih awal, sehingga memastikan migrasi berjalan lancar dan melindungi lingkungan produksi Anda.
Buat tugas migrasi untuk melakukan migrasi data.
Analisis bottleneck performa dan verifikasi kelayakan migrasi.
Untuk memvalidasi kompatibilitas cloud, gunakan salah satu metode berikut:
Validasi manual: Lihat Analisis dan Penyelesaian Kompatibilitas.
Validasi konsol: Lihat (Opsional) Periksa kompatibilitas SQL.
Metode migrasi
Metode migrasi | Kelebihan | Kekurangan | Kasus penggunaan |
migrasi konsol | Menyediakan alur kerja visual yang mengotomatiskan migrasi metadata. | Hanya mendukung migrasi penuh dan inkremental seluruh kluster; tidak mendukung migrasi database dan tabel tertentu atau subset data historis. | Migrasi seluruh kluster. |
migrasi manual | Memberikan kontrol granular atas database dan tabel mana yang akan dimigrasikan. | Melibatkan prosedur kompleks dan memerlukan migrasi metadata secara manual. |
|
Prosedur
Migrasi konsol
Pertimbangan
Selama migrasi
Proses merge dijeda pada kluster tujuan untuk database dan tabel yang sedang dimigrasikan, tetapi tetap berjalan di kluster yang dikelola sendiri.
CatatanJika tugas migrasi berjalan terlalu lama, jumlah metadata yang menumpuk di kluster tujuan bisa menjadi berlebihan. Durasi yang direkomendasikan untuk tugas migrasi adalah tidak lebih dari 5 hari. Sistem secara otomatis membatalkan tugas yang melebihi batas ini.
Kluster tujuan harus menggunakan kluster
default. Jika kluster yang dikelola sendiri menggunakan nama berbeda, sistem secara otomatis mengonversi definisi kluster pada tabel terdistribusi apa pun menjadidefault.
Konten yang didukung
Proses migrasi mengonversi struktur database dan tabel untuk beberapa mesin. Untuk detail tentang konversi mesin, lihat tabel di bawah ini.
Struktur database: Tabel berikut mencantumkan tipe mesin database yang didukung.
Nama mesin
Deskripsi konversi
AtomicDiganti dengan mesin
ReplicatedReplicatedTidak berubah
OrdinaryDiganti dengan mesin
ReplicatedStruktur tabel: Tabel berikut mencantumkan tipe mesin tabel yang didukung.
Nama mesin
Deskripsi konversi
MaterializedViewTidak berubah
ViewGenerateRandomBufferURLNullMergeSharedMergeTreeSharedVersionedCollapsingMergeTreeSharedSummingMergeTreeSharedReplacingMergeTreeSharedAggregatingMergeTreeSharedCollapsingMergeTreeSharedGraphiteMergeTreeMergeTreeDiganti dengan
SharedMergeTreeReplicatedMergeTreeVersionedCollapsingMergeTreeDiganti dengan
SharedVersionedCollapsingMergeTreeReplicatedVersionedCollapsingMergeTreeSummingMergeTreeDiganti dengan
SharedSummingMergeTreeReplicatedSummingMergeTreeReplacingMergeTreeDiganti dengan
SharedReplacingMergeTreeReplicatedReplacingMergeTreeAggregatingMergeTreeDiganti dengan
SharedAggregatingMergeTreeReplicatedAggregatingMergeTreeReplicatedCollapsingMergeTreeDiganti dengan
SharedCollapsingMergeTreeCollapsingMergeTreeGraphiteMergeTreeDiganti dengan
SharedGraphiteMergeTreeReplicatedGraphiteMergeTreeData: Migrasi inkremental didukung untuk data dalam tabel keluarga
MergeTree.
Sistem dapat secara otomatis memigrasikan struktur database dan tabel yang tercantum di atas. Struktur lainnya harus ditangani secara manual berdasarkan peringatan dan error yang muncul selama migrasi.
Jika data Anda tidak memenuhi kondisi ini, Anda dapat melakukan migrasi manual.
Dampak pada kluster
Kluster yang dikelola sendiri
Membaca data dari kluster yang dikelola sendiri meningkatkan penggunaan CPU dan memori.
Operasi DDL tidak diizinkan.
Kluster tujuan
Menulis data ke kluster tujuan meningkatkan penggunaan CPU dan memori.
Operasi DDL tidak diizinkan pada database dan tabel yang termasuk dalam migrasi. Pembatasan ini tidak berlaku untuk database dan tabel yang tidak termasuk dalam migrasi.
Proses merge dijeda untuk tabel dan database yang sedang dimigrasikan. Hal ini tidak memengaruhi tabel dan database lainnya.
Setelah migrasi selesai, kluster melakukan operasi merge secara intensif selama periode tertentu. Hal ini meningkatkan pemanfaatan I/O dan dapat menyebabkan latensi lebih tinggi pada permintaan bisnis. Untuk mengurangi dampak potensial, Hitung Waktu Merge Setelah Migrasi dan rencanakan sesuai kebutuhan.
Langkah 1: Periksa kluster dan aktifkan tabel sistem
Sebelum memulai migrasi data, konfigurasikan file config.xml pada kluster yang dikelola sendiri untuk mengaktifkan migrasi inkremental. Konfigurasi bergantung pada apakah tabel sistem system.part_log dan system.query_log sudah diaktifkan atau belum.
Jika tabel sistem belum diaktifkan
Jika Anda belum mengaktifkan system.part_log dan system.query_log, tambahkan konfigurasi berikut ke file config.xml.
system.part_log
<part_log>
<database>system</database>
<table>part_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>system.query_log
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>Jika tabel sistem sudah diaktifkan
-
Pastikan konfigurasi
system.part_logdansystem.query_logdalam file config.xml sesuai dengan konten berikut. Ketidaksesuaian dapat menyebabkan migrasi data gagal atau berjalan lambat.system.part_log
<part_log> <database>system</database> <table>part_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </part_log>system.query_log
<query_log> <database>system</database> <table>query_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </query_log> -
Setelah mengubah konfigurasi, jalankan pernyataan
drop table system.part_logdandrop table system.query_log. Memasukkan data ke tabel bisnis secara otomatis membuat ulang tabelsystem.part_logdansystem.query_log.
Langkah 2: Konfigurasi kompatibilitas kluster
Untuk memastikan kluster target sekompatibel mungkin dengan kluster yang dikelola sendiri, hubungkan ke kluster target dan ubah parameter compatibility agar sesuai dengan versi kluster yang dikelola sendiri.
Mengatur compatibility ke versi yang lebih lama akan menonaktifkan beberapa fitur baru, seperti ParallelReplica.
Contoh:
SELECT currentProfiles(); // Dapatkan nama profil saat ini.
SELECT
profile_name,
setting_name,
value
FROM system.settings_profile_elements
WHERE (setting_name = 'compatibility') AND (profile_name = 'xxxx'); // Periksa nilai pengaturan compatibility.
ALTER PROFILE XXXX SETTINGS compatibility = '23.8'; // Atur nilai compatibility.Langkah 3: Buat tugas migrasi
Masuk ke Konsol ApsaraDB for ClickHouse. Pada halaman Clusters, pilih Enterprise Edition Clusters, lalu klik ID kluster target.
Pada panel navigasi, pilih .
Klik Create Migration Task.
Pilih instance sumber dan target.
Parameter
Deskripsi
Contoh
Task Name
Nama unik yang tidak peka huruf besar/kecil untuk tugas migrasi. Nama hanya boleh berisi huruf dan angka.
MigrationTask1229
Source Cluster Name
Jalankan
SELECT * FROM system.clusters;untuk mendapatkan nama kluster kluster yang dikelola sendiri.default
VPC IP Address
Alamat IP dan port untuk setiap shard dalam kluster, dipisahkan koma. Format:
IP:PORT,IP:PORT,....Anda dapat menggunakan pernyataan SQL berikut untuk mendapatkan alamat IP dan port kluster yang dikelola sendiri:
SELECT shard_num, replica_num, host_address as ip, port FROM system.clusters WHERE cluster = '<cluster_name>' and replica_num = 1;Deskripsi parameter:
cluster_name: Nama kluster yang dikelola sendiri.
replica_num=1 memilih set replika pertama. Anda juga dapat memilih set replika lain atau memilih satu replika dari setiap shard secara manual.
PentingAnda tidak dapat menggunakan nama domain VPC atau alamat SLB kluster ClickHouse.
Jika Anda menggunakan NAT untuk memetakan alamat IP dan port ke Alibaba Cloud, Anda harus mengonfigurasi alamat IP dan port yang dipetakan sesuai dengan pengaturan jaringan Anda.
192.168.0.5:9000,192.168.0.6:9000
Database Account
Akun database untuk kluster yang dikelola sendiri.
test
Database Password
Password untuk akun database kluster yang dikelola sendiri.
test******
Source Instance Kernel Version
Klik Get Version.
22.8.5.29
Berdasarkan versi instans sumber, lakukan langkah berikut:
Jika versi instans sumber 22.10 atau lebih baru: Klik Next.
Jika versi instans sumber lebih lama dari 22.10: Masukkan Destination Instance Information seperti diminta, lalu klik Next.
Jika pengambilan versi gagal: Hal ini dapat terjadi jika informasi instans sumber salah atau jaringan terputus. Ikuti petunjuk untuk menyelesaikan masalah, lalu klik Get Version lagi.
CatatanKarena ketidakcocokan parameter antara edisi komunitas versi lama dan Edisi Perusahaan, jika versi instans sumber lebih lama dari 22.10, Anda harus menyinkronkan data dengan mendorongnya dari sumber ke target. Dalam skenario ini, Anda harus memetakan alamat IP instans target ke jaringan yang dikelola sendiri. Jika jaringan yang dikelola sendiri dan instans Edisi Perusahaan berada dalam VPC yang sama, atau terhubung melalui VPC Peering Connection, Anda dapat menggunakan alamat IP asli untuk koneksi.
Periksa konektivitas dan konfigurasi.
Klik Start Check.
Selama pemeriksaan, Anda dapat mengklik ikon
 di pojok kanan atas untuk melihat progres real-time.
di pojok kanan atas untuk melihat progres real-time.Setelah pemeriksaan selesai, lanjutkan berdasarkan hasilnya.
Anda dapat memilih Result level dan item pemeriksaan, lalu klik ikon
untuk melihat hasil yang sesuai. Level hasil dijelaskan di bawah ini.Success: Jika semua pemeriksaan lolos, klik Next untuk melanjutkan.
Warning: Ini adalah item non-blocking. Anda harus mengonfirmasi secara manual apakah peringatan tersebut memengaruhi workload atau tugas migrasi Anda. Anda dapat mengabaikan peringatan atau menyelesaikan masalah tersebut lalu mengklik Start Check lagi.
Error: Ini adalah item blocking. Anda harus menyelesaikan error menggunakan informasi yang disediakan, lalu mengklik Start Check lagi.
Untuk informasi tentang pesan error dan solusinya, lihat FAQ.
Periksa Struktur Database dan Tabel.
Setelah pemeriksaan konektivitas dan konfigurasi lolos, lanjutkan untuk memeriksa struktur database dan tabel. Langkah ini terdiri dari tiga sub-langkah: Select databases to migrate, Select tables to migrate, dan Check database and table structures.
PentingSub-langkah Select databases to migrate dan Select tables to migrate bersifat opsional. Jika Anda ingin memigrasikan semua database dan tabel dari instans sumber, Anda dapat melewati dua sub-langkah ini dan langsung melanjutkan ke sub-langkah 3 (Check database and table structures).
Sub-langkah 1: Pilih database yang akan dimigrasikan (Opsional)
Klik Query Source. Sistem secara otomatis mengkueri semua database pada instans sumber.
Selama kueri, Anda dapat mengklik Query Results untuk melihat hasil real-time.
Setelah kueri selesai, pilih database yang akan dimigrasikan sesuai kebutuhan bisnis Anda. Setelah pemilihan selesai, klik Confirm.
Sub-langkah 2: Select tables to migrate (Opsional)
Setelah Anda memilih database, antarmuka untuk memilih tabel akan ditampilkan. Klik Query Source. Sistem secara otomatis mengkueri semua tabel dalam database yang dipilih.
Selama kueri, Anda dapat mengklik Query Results untuk melihat hasil real-time.
Setelah kueri selesai, pilih tabel yang akan dimigrasikan sesuai kebutuhan bisnis Anda. Setelah pemilihan selesai, klik Confirm.
CatatanSecara default, semua tabel dipilih. Jika Anda hanya perlu memigrasikan tabel tertentu, hapus centang pada kotak pilih-semua untuk database yang sesuai, buka daftar dropdown, lalu pilih tabel yang Anda butuhkan.
Sub-langkah 3: Check database and table structures
Klik Start Check. Sistem memeriksa struktur database, struktur tabel, dan UDF untuk mengidentifikasi ketidakcocokan antara instans sumber dan target.
Selama pemeriksaan, Anda dapat memfilter berdasarkan Result Level dan Check Item, lalu mengklik ikon Refresh untuk melihat hasil real-time.
Hasil pemeriksaan diklasifikasikan ke dalam tiga level: success, warning, dan error.
Pemeriksaan berhasil: Klik Next untuk melanjutkan migrasi.
Peringatan muncul selama pemeriksaan
Atur level hasil ke Warning dan temukan item pemeriksaan yang sesuai untuk meninjau detail peringatan.
PentingItem pemeriksaan level Warning bersifat non-blocking. Anda harus mengonfirmasi apakah peringatan tersebut memengaruhi workload atau tugas migrasi Anda. Setelah konfirmasi, Anda memiliki dua opsi:
Abaikan peringatan dan klik Next untuk melanjutkan migrasi.
Selesaikan peringatan berdasarkan detail yang disediakan, lalu klik Start Check untuk memeriksa ulang struktur database dan tabel. Untuk informasi tentang pesan peringatan dan solusinya, lihat bagian FAQ topik ini.
Pemeriksaan gagal
Atur level hasil ke Error dan temukan item pemeriksaan yang sesuai untuk meninjau detail error.
PentingItem pemeriksaan level Error bersifat blocking. Anda harus menyelesaikan error berdasarkan detail yang disediakan, lalu klik Start Check untuk memeriksa ulang struktur database dan tabel. Untuk informasi tentang pesan error dan solusinya, lihat bagian FAQ topik ini.
Migrasi Struktur Database dan Tabel.
Klik Start Migration.
Selama migrasi, Anda dapat mengklik ikon
di pojok kanan atas untuk melihat progres real-time.Setelah migrasi selesai, lanjutkan berdasarkan hasilnya.
Untuk informasi tentang hasilnya, lihat Langkah 5.
(Opsional) Periksa kompatibilitas SQL.
Pemeriksaan kompatibilitas SQL memutar ulang pernyataan SQL dari instans yang dikelola sendiri pada instans target untuk memverifikasi kompatibilitas sintaks antar versi kernel yang berbeda.
Untuk melewati langkah ini, klik skip.
Untuk melakukan pemeriksaan ini, pilih Request replay time lalu klik Start Check. Jika pemeriksaan lolos, klik Next. Jika pemeriksaan gagal, lihat Langkah 5 untuk solusinya.
PentingDatabase dan tabel instans tidak berisi data, sehingga pemeriksaan ini hanya memvalidasi kompatibilitas sintaks. Untuk menguji dengan data, Anda dapat memigrasikan beberapa data pada langkah berikutnya.
Ketidaksesuaian antara versi klien yang digunakan untuk pemutaran ulang SQL dan instans target dapat menyebabkan false positive. Jika terjadi error, jalankan pernyataan SQL secara manual untuk memverifikasi hasilnya.
Catat dan bersihkan tabel mesin Kafka/RabbitMQ.
Sebelum memulai sinkronisasi, catat definisi tabel mesin Kafka/RabbitMQ dan materialized view downstream-nya pada kluster yang dikelola sendiri, tangani tabel implisit, lalu hapus tabel-tabel tersebut untuk menghindari exception migrasi.
Login ke kluster yang dikelola sendiri dan kueri semua tabel mesin Kafka dan RabbitMQ beserta dependensi downstream-nya.
/* create_table_query: definisi tabel dependencies_database: database dari tabel dependen downstream dependencies_table: nama tabel dependen downstream Dari dependencies_database dan dependencies_table, Anda dapat mengidentifikasi materialized view yang bergantung pada tabel Kafka/RabbitMQ. */ SELECT * FROM system.tables WHERE engine IN ('RabbitMQ', 'Kafka');Lihat definisi materialized view dan periksa apakah tabel targetnya adalah tabel implisit.
/* Lihat definisi materialized view. Jika tabel target materialized view adalah tabel implisit, perhatikan hal berikut: Menghapus materialized view juga akan menghapus tabel implisit, yang menyebabkan kehilangan data. Contoh: Dalam CREATE MATERIALIZED VIEW [db.]table_name [TO[db.]name], jika TO tidak ditentukan, sistem secara otomatis membuat tabel implisit, yang mungkin dalam format '.inner_id.<TABLE_UUID>' atau '.inner.<TABLE>'. */ SELECT * FROM system.tables WHERE database='<DATABASE>' AND name = '<MATERIALIZED_VIEW_NAME>';Jika tabel target materialized view adalah tabel implisit, ganti namanya menjadi nama baru untuk mencegah kehilangan data saat materialized view dihapus nanti.
-- Ganti nama tabel target implisit untuk mempertahankan data RENAME TABLE <DATABASE>.`.inner_id.<TABLE_UUID>` TO <DATABASE>.<new_target_table_name>;Hapus tabel mesin Kafka/RabbitMQ dan materialized view downstream-nya.
-- Hapus materialized view terlebih dahulu DROP TABLE <DATABASE>.<MATERIALIZED_VIEW_NAME>; -- Lalu hapus tabel mesin Kafka/RabbitMQ DROP TABLE <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME>;
PentingPastikan untuk menyimpan semua pernyataan DDL yang dicatat. Anda akan membutuhkannya untuk membuat ulang tabel-tabel ini di kluster yang dikelola sendiri dan kluster target nanti. Jika Anda melakukan operasi RENAME, gunakan klausa TO untuk mengarahkan ke tabel target yang diganti namanya saat membuat ulang materialized view.
Mulai Sinkronisasi.
Klik Start Sync.
Selama sinkronisasi, Anda dapat mengklik ikon
di pojok kanan atas untuk melihat progres real-time.Pada kluster yang dikelola sendiri, gunakan pernyataan DDL yang disimpan sebelumnya untuk membuat ulang tabel mesin Kafka/RabbitMQ dan materialized view downstream-nya. Setelah dibuat ulang, data inkremental akan kembali mengalir dan secara otomatis disinkronkan ke kluster target.
PentingJika sebelumnya Anda melakukan operasi RENAME pada tabel target implisit, gunakan klausa TO untuk mengarahkan ke tabel target yang diganti namanya saat membuat ulang materialized view. Untuk informasi lebih lanjut, lihat CREATE MATERIALIZED VIEW.
CREATE MATERIALIZED VIEW [db.]table_name [TO[db.]name].
-- Buat ulang tabel mesin Kafka/RabbitMQ di kluster yang dikelola sendiri CREATE TABLE <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME> (...) ENGINE = Kafka/RabbitMQ SETTINGS ...; -- Buat ulang materialized view (mengarah ke tabel target yang diganti namanya) CREATE MATERIALIZED VIEW <DATABASE>.<MATERIALIZED_VIEW_NAME> TO <DATABASE>.<new_target_table_name> AS SELECT ... FROM <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME>;Saat proses mencapai tahap Migrate data, beralihlah ke tab Migrate data dan klik ikon
untuk melihat Migration Progress dan Estimated remaining time.PentingAnda harus memantau secara ketat Migration Progress. Berdasarkan Estimated remaining time, Anda perlu secara proaktif menghentikan penulisan ke kluster yang dikelola sendiri dan menangani tabel yang menggunakan mesin Kafka dan RabbitMQ.
Proses latar belakang secara otomatis membatalkan tugas apa pun yang berjalan lebih dari 5 hari. Jika tugas migrasi Anda memerlukan waktu lebih lama, kirim tiket untuk meminta penyesuaian ambang batas.
Saat Migration Progress mencapai 100% dan Anda memastikan bahwa penulisan ke instans sumber telah dihentikan, klik Stop untuk mengakhiri migrasi data dan melanjutkan ke langkah berikutnya.
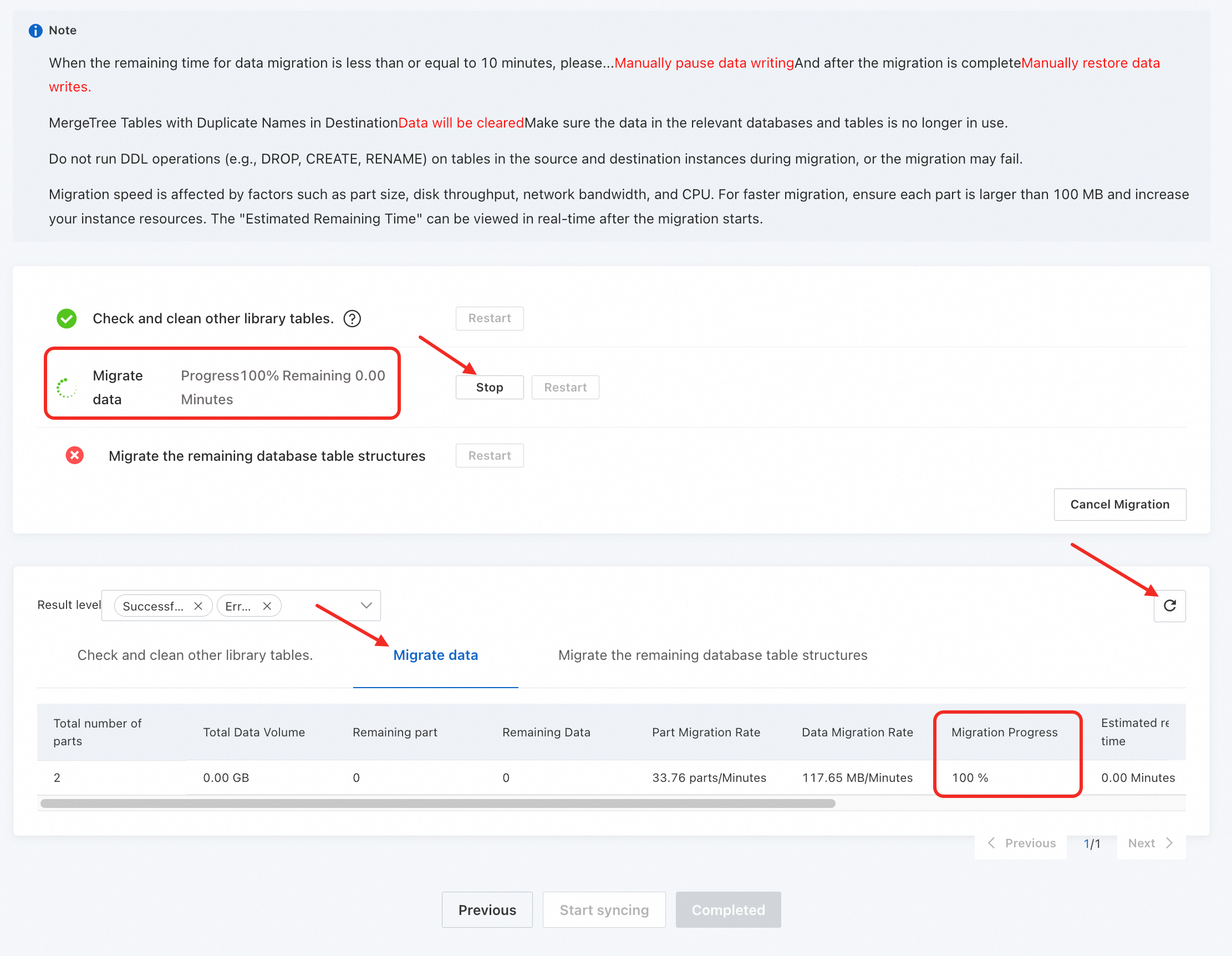
Setelah sinkronisasi selesai, klik Completed.
PentingSetelah langkah Start Synchronization selesai, tugas migrasi terkunci, dan Anda tidak dapat memodifikasi proses migrasi. Anda masih dapat menggunakan tombol Previous, Next, atau Refresh untuk melihat hasil langkah yang telah selesai.
Langkah 4: Migrasi data untuk tabel non-MergeTree
Selama tugas migrasi, tabel non-MergeTree hanya mendukung migrasi struktur tabel (misalnya, tabel MySQL) atau tidak mendukung migrasi sama sekali (misalnya, tabel Log). Oleh karena itu, setelah tugas migrasi selesai, kluster target mungkin berisi tabel dengan struktur tetapi tanpa data bisnis. Anda harus memigrasikan data bisnis secara manual sebagai berikut:
Login ke kluster self-built dan identifikasi tabel non-MergeTree yang memerlukan migrasi data.
SELECT `database` AS database_name, `name` AS table_name, `engine` FROM `system`.`tables` WHERE (`engine` NOT LIKE '%MergeTree%') AND (`engine` != 'Distributed') AND (`engine` != 'MaterializedView') AND (`engine` NOT IN ('Kafka', 'RabbitMQ')) AND (`database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema')) AND (`database` NOT IN ( SELECT `name` FROM `system`.`databases` WHERE `engine` IN ('MySQL', 'MaterializedMySQL', 'MaterializeMySQL', 'Lazy', 'PostgreSQL', 'MaterializedPostgreSQL', 'SQLite') ))Login ke kluster target dan gunakan fungsi remote untuk memigrasikan data.
Migrasi manual
Migrasi dari ClickHouse yang dikelola sendiri ke Edisi Perusahaan
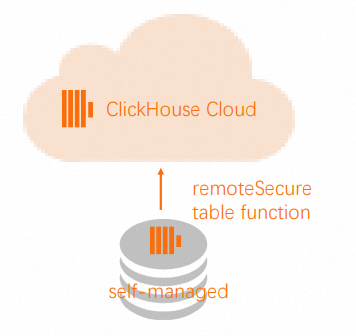
Di ApsaraDB for ClickHouse Enterprise Edition, Anda hanya perlu membuat tabel target yang sesuai, terlepas dari apakah tabel sumber Anda memiliki shard atau replika. Sistem secara otomatis menggunakan mesin tabel SharedMergeTree, sehingga Anda dapat menghilangkan parameter mesin yang kompleks dalam definisi tabel target. Kluster ApsaraDB for ClickHouse Enterprise Edition secara otomatis menangani skalabilitas vertikal dan horizontal, sehingga Anda tidak perlu khawatir tentang detail implementasi replikasi dan sharding.
Ikhtisar
Prosedur berikut menjelaskan cara melakukan migrasi dari kluster ClickHouse yang dikelola sendiri ke kluster ApsaraDB for ClickHouse Enterprise Edition.
Tambahkan pengguna read-only ke kluster sumber.
Replikasi struktur tabel sumber di kluster target.
Jika kluster sumber dapat diakses dari jaringan eksternal, tarik data dari kluster sumber ke kluster target. Jika tidak, dorong data dari kluster sumber ke kluster target.
(Opsional) Hapus alamat IP kluster sumber dari daftar izin kluster target.
Hapus pengguna read-only dari kluster sumber.
Prosedur
Lakukan operasi berikut pada kluster sumber. Prosedur ini mengasumsikan bahwa tabel sumber sudah berisi data.
Tambahkan pengguna read-only untuk tabel
db.table.CREATE USER exporter IDENTIFIED WITH SHA256_PASSWORD BY 'password-here' SETTINGS readonly = 1;GRANT SELECT ON db.table TO exporter;Salin struktur tabel sumber.
SELECT create_table_query FROM system.tables WHERE database = 'db' and table = 'table'
Lakukan operasi berikut pada kluster target.
Buat database.
CREATE DATABASE dbGunakan pernyataan
CREATE TABLEtabel sumber untuk membuat tabel target.CatatanSaat menjalankan pernyataan
CREATE TABLE, ubahENGINEmenjadiSharedMergeTreedan hilangkan parameter apa pun. Kluster ApsaraDB for ClickHouse Enterprise Edition selalu mereplikasi tabel dan menyediakan parameter yang benar. KlausulORDER BY,PRIMARY KEY,PARTITION BY,SAMPLE BY,TTL, danSETTINGSmendefinisikan struktur dan metadata tabel. Pertahankan klausul ini untuk memastikan tabel dibuat dengan benar di kluster target ApsaraDB for ClickHouse Enterprise Edition.CREATE TABLE db.table ...Gunakan fungsi
Remoteuntuk menarik atau mendorong data.CatatanJika server ClickHouse sumber tidak dapat diakses dari jaringan eksternal, dorong data dari kluster sumber daripada menariknya dari kluster target. Fungsi
Remotemendukung operasiSELECT(pull) danINSERT(push).Di kluster target, gunakan fungsi
Remoteuntuk menarik data dari tabel sumber.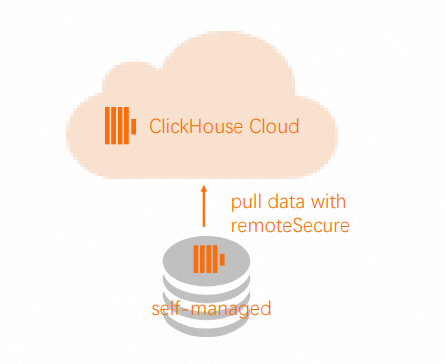
INSERT INTO db.table SELECT * FROM remote('source-hostname:9000', db, table, 'exporter', 'password-here')Di kluster sumber, gunakan fungsi
Remoteuntuk mendorong data ke kluster target.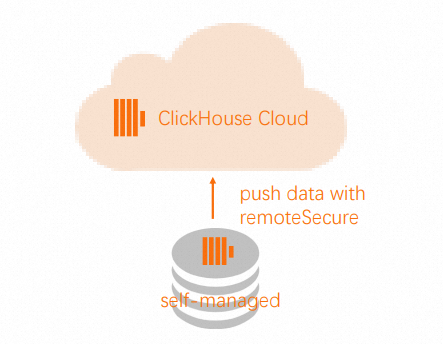 Catatan
CatatanTambahkan alamat IP kluster sumber ke daftar izin kluster target untuk mengaktifkan fungsi
Remoteagar dapat terhubung ke kluster ApsaraDB for ClickHouse Enterprise Edition Anda. Untuk informasi lebih lanjut, lihat Konfigurasi daftar izin.INSERT INTO FUNCTION remote('target-hostname:9000', 'db.table', 'default', 'PASS') SELECT * FROM db.table
FAQ
Error konektivitas dan konfigurasi
Pesan error | Deskripsi | Solusi |
| Koneksi jaringan ke kluster self-built mengalami timeout. | Gunakan pesan error untuk memecahkan masalah jaringan. |
| Kluster yang ditentukan dalam konfigurasi tugas migrasi tidak ditemukan di kluster self-built. | Kueri kluster self-built untuk mendapatkan nama kluster yang benar menggunakan SQL, lalu perbarui konfigurasi tugas migrasi. |
| Satu atau beberapa tabel sistem berikut tidak ada di kluster self-built: | Buat tabel sistem yang hilang di kluster self-built. |
| Zona waktu kluster self-built tidak sesuai dengan zona waktu kluster target. | Selaraskan pengaturan zona waktu kluster. |
| Pengaturan | Sesuaikan pengaturan Penting Mengatur compatibility ke versi yang lebih lama akan menonaktifkan fitur seperti ParallelReplica. |
Error skema database dan tabel
Pesan error | Deskripsi | Solusi |
| Skema database dan tabel tidak konsisten di seluruh node kluster self-built. | Periksa skema di setiap node kluster self-built dan selesaikan ketidaksesuaian apa pun. |
| Password dalam skema database dan tabel disembunyikan. | Atur parameter Catatan: Operasi ini memerlukan izin akun displaySecretsInShowAndSelect. |
| Proses migrasi tidak mendukung mesin database kluster self-built. | Ubah mesin database ke salah satu yang didukung oleh instans target. |
| Mesin database kluster self-built tidak didukung untuk migrasi. | Untuk melewati exception migrasi, sistem secara otomatis mengganti mesin dengan database Replicated. |
| Mesin database kluster self-built tidak didukung untuk migrasi. | Gunakan Data Transmission Service (DTS) untuk menyinkronkan data, atau buat database dengan nama yang sama di instans target untuk melewati exception migrasi. |
| Migrasi tidak didukung untuk tabel yang menggunakan mesin tertentu. | Proses migrasi secara otomatis mengabaikan mesin ini. |
| Menggunakan mesin tabel terdistribusi tidak disarankan di ApsaraDB for ClickHouse Enterprise Edition. | Hapus tabel terdistribusi di kluster self-built. Setelah migrasi, kueri tabel MergeTree dasarnya secara langsung. |
| Peringatan ini menandai alamat IP yang berpotensi tidak dapat dijangkau tetapi tidak mengonfirmasi adanya masalah aksesibilitas. | Pastikan instans target dapat menjangkau alamat IP yang dirujuk. Jika tidak, tetapkan konektivitas dan tambahkan alamat IP ke daftar izin. |
| Untuk tabel yang menggunakan mesin tertentu, hanya skema yang dimigrasikan; migrasi data tidak didukung. | Migrasi data secara manual, misalnya menggunakan fungsi remote. |
| Migrasi tidak didukung untuk tabel yang menggunakan mesin tertentu. | Buat tabel MergeTree dengan nama yang sama di instans target dan migrasi data secara manual. |
| Migrasi tidak didukung untuk tabel yang menggunakan mesin tertentu. | Lihat Langkah 4 di bagian Prosedur. |
| Agar pemeriksaan skema berhasil, tabel yang sesuai di instans target harus kosong. | Hapus data dari tabel yang sesuai di instans target. |
| Hanya Fungsi yang didefinisikan pengguna dengan | Buat fungsi yang diperlukan secara manual di instans target. |
Lainnya
Untuk solusi masalah migrasi lainnya, lihat FAQ.