Kluster ClickHouse yang dikelola sendiri sering mengalami ketidakstabilan, skalabilitas terbatas, kesulitan dalam peningkatan versi, dan kemampuan pemulihan bencana yang lemah. Akibatnya, semakin banyak pelanggan memigrasikan kluster ClickHouse yang mereka kelola sendiri ke layanan PaaS cloud. Topik ini menjelaskan cara melakukan migrasi dari kluster ClickHouse yang dikelola sendiri ke kluster edisi kompatibel komunitas ApsaraDB for ClickHouse.
Prasyarat
-
Kluster target:
-
Kluster tersebut merupakan Edisi Kompatibel Komunitas.
-
Anda memerlukan akun database dan kata sandi. Untuk membuat akun ClickHouse, lihat Mengelola akun untuk kluster Edisi Kompatibel Komunitas.
-
Akun tersebut harus memiliki izin tingkat tertinggi. Untuk memberikan izin, lihat Mengubah izin.
-
-
Kluster yang dikelola sendiri:
-
Anda memerlukan akun database dan kata sandi.
-
Akun tersebut harus memiliki izin baca pada database dan tabel, serta izin untuk mengeksekusi perintah SYSTEM.
-
-
Kluster target dan kluster yang dikelola sendiri harus dapat berkomunikasi melalui jaringan.
Jika kluster yang dikelola sendiri dan kluster target berada dalam VPC yang sama, Anda juga harus menambahkan alamat IP semua node di kluster target dan Blok CIDR IPv4 vSwitch-nya ke daftar putih kluster yang dikelola sendiri.
-
Untuk mengonfigurasi daftar putih kluster ApsaraDB for ClickHouse, lihat Mengonfigurasi daftar putih.
-
Untuk mengonfigurasi daftar putih di kluster yang dikelola sendiri, lihat dokumentasi produk terkait.
-
Untuk melihat alamat IP semua node di kluster ApsaraDB for ClickHouse, jalankan
SELECT * FROM system.clusters;. -
Untuk mendapatkan Blok CIDR IPv4 vSwitch kluster ApsaraDB for ClickHouse Anda, ikuti langkah-langkah berikut:
-
Di Konsol ApsaraDB for ClickHouse, buka halaman Cluster Information kluster target. Di bagian Network Information, dapatkan VSwitch ID.
-
Di daftar vSwitch, gunakan Instance ID untuk menemukan vSwitch target dan dapatkan IPv4 CIDR-nya.
-
Jika kluster yang dikelola sendiri dan kluster target berada di VPC berbeda, atau jika kluster yang dikelola sendiri berada di pusat data lokal atau platform cloud lain, Anda harus terlebih dahulu menetapkan konektivitas jaringan. Untuk informasi lebih lanjut, lihat Bagaimana cara menetapkan koneksi jaringan antara kluster target dan sumber data?.
-
Validasi migrasi
Sebelum memulai migrasi data, kami sangat menyarankan membuat lingkungan pengujian untuk memvalidasi kompatibilitas bisnis, kinerja, dan rencana migrasi. Setelah validasi selesai, Anda dapat melakukan migrasi data di lingkungan produksi. Langkah penting ini membantu Anda mengidentifikasi dan menyelesaikan potensi masalah lebih awal, memastikan migrasi berjalan lancar dan mencegah gangguan pada lingkungan produksi.
-
Buat tugas migrasi untuk memindahkan data. Untuk langkah-langkah detail, lihat topik ini.
-
Untuk informasi tentang kompatibilitas migrasi cloud, analisis bottleneck kinerja, dan memastikan keberhasilan migrasi, lihat Analisis dan Solusi untuk Kompatibilitas dan Bottleneck Kinerja dalam Migrasi ClickHouse yang Dikelola Sendiri ke Cloud.
Pilih solusi
|
Solusi migrasi |
Kelebihan |
Kekurangan |
Kasus penggunaan |
|
Menyediakan antarmuka visual. Anda tidak perlu memigrasikan metadata secara manual. |
Hanya mendukung migrasi penuh dan inkremental seluruh kluster. Anda tidak dapat memigrasikan database, tabel, atau data historis tertentu. |
Memigrasikan seluruh kluster. |
|
|
Memungkinkan Anda mengontrol database dan tabel mana yang akan dimigrasikan. |
Melibatkan langkah-langkah kompleks dan migrasi metadata manual. |
|
Prosedur
Migrasi konsol
Batasan
Kluster tujuan harus menjalankan versi 21.8 atau lebih baru.
Catatan
Selama migrasi
-
Selama migrasi, proses merge dijeda di kluster tujuan tetapi berlanjut di kluster yang dikelola sendiri.
CatatanJika tugas migrasi berjalan lama, metadata berlebih dapat menumpuk di kluster tujuan. Kami menyarankan agar durasi tugas migrasi tidak melebihi 5 hari. Tugas yang melebihi 5 hari akan dibatalkan secara otomatis.
-
Kluster tujuan harus merupakan kluster
default. Jika kluster yang dikelola sendiri menggunakan nama berbeda, layanan secara otomatis mengonversi definisiclusterdi tabel terdistribusi menjadidefault.
Lingkup migrasi
-
Objek yang didukung
-
Database, kamus data, dan tampilan yang di-materialisasi.
-
Layanan ini mendukung migrasi kamus data yang dibuat dengan SQL, tetapi tidak yang dibuat dengan XML.
Untuk memverifikasi hal ini, jalankan pernyataan berikut:
SELECT * FROM system.dictionaries WHERE (database = '') OR isNull(database);. Jika pernyataan tersebut mengembalikan baris apa pun, ini menunjukkan Anda memiliki kamus data yang dibuat menggunakan XML. -
Saat kamus data mengakses layanan eksternal, pastikan layanan eksternal tersebut tersedia dan kluster ditambahkan ke daftar izinnya. Jika sumber data untuk kamus data adalah tabel internal di kluster ClickHouse saat ini dan parameter
HOSTdalam definisinya adalah alamat IP, akses ke kamus tersebut mungkin gagal setelah migrasi karena perubahan alamat IP. Anda harus mengonfirmasi ulangHOSTkluster ClickHouse saat ini dan membuat kamus data secara manual.
-
-
Skema tabel: Semua skema tabel kecuali tabel engine Kafka dan RabbitMQ.
-
Data: Migrasi inkremental data dari tabel keluarga MergeTree.
-
-
Objek dan data yang tidak didukung
-
Tabel engine Kafka dan RabbitMQ, serta datanya.
-
Data dari tabel non-MergeTree, seperti tabel eksternal dan tabel Log.
PentingAnda harus memigrasikan item yang tidak didukung di atas secara manual.
-
-
Batasan volume data
-
Data dingin: Migrasi data dingin lambat. Untuk mencegah kegagalan akibat waktu migrasi yang lama, kami menyarankan membersihkan data dingin dari kluster yang dikelola sendiri agar volume total tidak melebihi 1 TB.
-
Data panas: Jika volume data panas melebihi 10 TB, tugas migrasi kemungkinan besar akan gagal.
Jika volume data Anda melebihi batasan ini, pertimbangkan untuk menggunakan solusi migrasi manual.
-
Dampak pada kluster
-
Kluster yang dikelola sendiri:
-
Membaca data dari kluster yang dikelola sendiri meningkatkan penggunaan CPU dan memori.
-
Operasi DDL tidak diizinkan.
-
-
Kluster tujuan:
-
Menulis data ke kluster tujuan meningkatkan penggunaan CPU dan memori.
-
Operasi DDL tidak diizinkan pada database dan tabel yang sedang dimigrasikan.
-
Pembatasan ini tidak berlaku untuk database dan tabel lainnya.
-
Proses merge hanya dihentikan untuk database dan tabel yang sedang dimigrasikan.
-
Kluster melakukan restart sebelum tugas migrasi dimulai.
-
Setelah migrasi selesai, kluster melakukan operasi merge secara intensif. Hal ini meningkatkan penggunaan I/O dan dapat menyebabkan latensi permintaan bisnis yang lebih tinggi. Rencanakan dampak potensial dari peningkatan latensi ini. Anda harus menghitung durasi spesifik operasi merge. Untuk petunjuknya, lihat Menghitung waktu merge setelah migrasi.
-
Prosedur
Langkah 1: Periksa kluster dan aktifkan tabel sistem
Sebelum memigrasikan data, modifikasi file config.xml di kluster yang dikelola sendiri untuk mengaktifkan migrasi inkremental. Modifikasi yang diperlukan bergantung pada apakah tabel system.part_log dan system.query_log diaktifkan.
Jika tabel sistem tidak diaktifkan
Jika Anda belum mengaktifkan system.part_log dan system.query_log, tambahkan konfigurasi berikut ke file config.xml.
system.part_log
<part_log>
<database>system</database>
<table>part_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>system.query_log
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>Jika tabel sistem diaktifkan
-
Pastikan konfigurasi
system.part_logdansystem.query_logdalam file config.xml sesuai dengan konten berikut. Ketidaksesuaian dapat menyebabkan migrasi data gagal atau berjalan lambat.system.part_log
<part_log> <database>system</database> <table>part_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </part_log>system.query_log
<query_log> <database>system</database> <table>query_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </query_log> -
Setelah memodifikasi konfigurasi, jalankan pernyataan
drop table system.part_logdandrop table system.query_log. Menyisipkan data ke tabel bisnis secara otomatis membuat ulang tabelsystem.part_logdansystem.query_log.
Langkah 2: Konfigurasi kompatibilitas kluster tujuan
Konfigurasikan kluster tujuan agar kompatibel dengan kluster yang dikelola sendiri. Langkah ini meminimalkan perubahan aplikasi yang diperlukan setelah migrasi.
-
Dapatkan dan bandingkan nomor versi kluster tujuan dan kluster yang dikelola sendiri.
Login ke kluster tujuan dan kluster yang dikelola sendiri, lalu jalankan pernyataan berikut pada masing-masing untuk mendapatkan nomor versinya. Untuk informasi lebih lanjut tentang cara login ke ApsaraDB for ClickHouse, lihat Menghubungkan ke database.
SELECT version(); -
Jika versinya berbeda, login ke kluster tujuan dan atur parameter kompatibilitas agar sesuai dengan versi kluster yang dikelola sendiri. Hal ini memastikan fitur-fiturnya konsisten sebisa mungkin. Berikut contohnya:
SET GLOBAL compatibility = '22.8';
Langkah 3: (Opsional) Aktifkan engine MaterializedMySQL
Jika kluster yang dikelola sendiri Anda berisi tabel yang menggunakan engine MaterializedMySQL, jalankan pernyataan berikut untuk mengaktifkan engine ini.
SET GLOBAL allow_experimental_database_materialized_mysql = 1;Komunitas ClickHouse tidak lagi memelihara engine MaterializedMySQL. Setelah migrasi ke cloud, kami menyarankan menggunakan Data Transmission Service (DTS) untuk menyinkronkan data MySQL.
Karena engine MaterializedMySQL tidak lagi dipelihara, Data Transmission Service (DTS) menggunakan tabel ReplacingMergeTree sebagai ganti tabel MaterializedMySQL saat menyinkronkan data MySQL ke ApsaraDB for ClickHouse. Untuk informasi lebih lanjut, lihat Kompatibilitas MaterializedMySQL.
Untuk informasi lebih lanjut tentang penggunaan DTS untuk memigrasikan data MySQL ke ApsaraDB for ClickHouse, lihat topik-topik berikut:
Langkah 4: Catat dan bersihkan tabel engine Kafka/RabbitMQ
Sebelum memulai migrasi, catat definisi semua tabel engine Kafka/RabbitMQ dan tampilan materialisasi downstream-nya di kluster yang dikelola sendiri, tangani tabel implisit, lalu hapus tabel-tabel ini untuk menghindari kesalahan migrasi.
-
Login ke kluster yang dikelola sendiri dan kueri semua tabel engine Kafka dan RabbitMQ beserta dependensi downstream-nya.
/* create_table_query: definisi tabel dependencies_database: database tabel yang bergantung pada tabel ini dependencies_table: tabel yang bergantung pada tabel ini Dari dependencies_database dan dependencies_table, Anda dapat mengidentifikasi tampilan materialisasi yang bergantung pada tabel Kafka/RabbitMQ */ SELECT * FROM system.tables WHERE engine IN ('RabbitMQ', 'Kafka'); -
Lihat definisi tampilan materialisasi untuk memeriksa apakah tabel targetnya adalah tabel implisit.
/* Lihat definisi tampilan materialisasi. Jika tabel target tampilan materialisasi adalah tabel implisit, beri perhatian khusus: Menghapus tampilan materialisasi juga akan menghapus tabel implisit, menyebabkan kehilangan data. Contoh: Jika CREATE MATERIALIZED VIEW [db.]table_name [TO[db.]name] tidak menentukan TO, sistem secara otomatis membuat tabel implisit, mungkin dalam format '.inner_id.<TABLE_UUID>' atau '.inner.<TABLE>' */ SELECT * FROM system.tables WHERE database='<DATABASE>' AND name = '<MATERIALIZED_VIEW_NAME>'; -
Jika tabel target tampilan materialisasi adalah tabel implisit, RENAME tabel target ke nama baru untuk mencegah kehilangan data saat tampilan materialisasi di-drop nanti.
-- Ganti nama tabel target implisit ke nama baru untuk melindungi data RENAME TABLE <DATABASE>.`.inner_id.<TABLE_UUID>` TO <DATABASE>.<new_target_table_name>; -
Hapus tabel engine Kafka/RabbitMQ dan tampilan materialisasi downstream-nya.
-- Drop tampilan materialisasi terlebih dahulu DROP TABLE <DATABASE>.<MATERIALIZED_VIEW_NAME>; -- Lalu drop tabel engine Kafka/RabbitMQ DROP TABLE <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME>;
Pastikan untuk menyimpan semua pernyataan DDL yang dicatat. Anda akan membutuhkannya untuk membangun ulang tabel-tabel ini di kluster yang dikelola sendiri dan kluster tujuan nanti. Jika Anda melakukan operasi RENAME, gunakan klausa TO yang mengarah ke tabel target yang diganti namanya saat membangun ulang tampilan materialisasi. Untuk informasi lebih lanjut, lihat CREATE MATERIALIZED VIEW.
Langkah 5: Buat tugas migrasi data
-
Login ke Konsol ApsaraDB for ClickHouse.
-
Di halaman Clusters, pilih Clusters of Community-compatible Edition dan klik ID kluster tujuan.
-
Di panel navigasi kiri, pilih .
-
Di halaman tugas migrasi, klik Create Migration Task.
-
Konfigurasikan instans sumber dan tujuan.
Konfigurasikan pengaturan berikut dan klik Test Connectivity and Proceed.
CatatanJika pengujian koneksi berhasil, lanjutkan ke langkah berikutnya. Jika pengujian koneksi gagal, konfigurasi ulang instans sumber dan tujuan berdasarkan petunjuk.
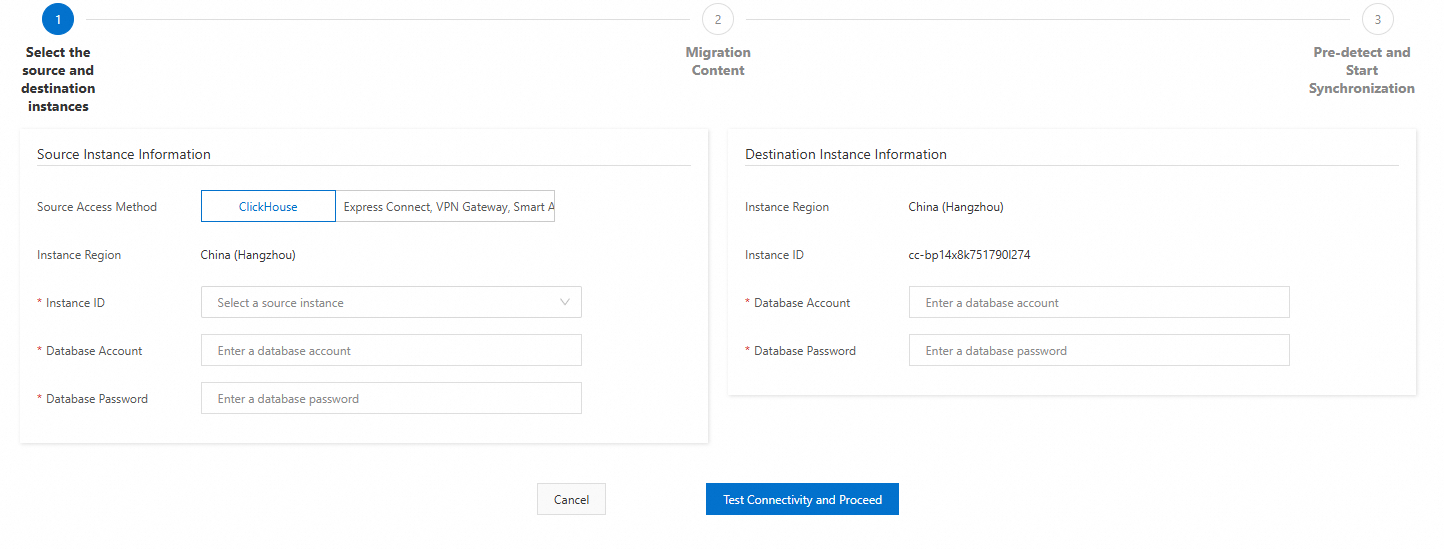
Parameter kluster sumber
Parameter
Deskripsi
Contoh
Source Access Method
Pilih Express Connect, VPN Gateway, Smart Access Gateway, or Self-managed ClickHouse Clusters on an ECS Instance.
Express Connect, VPN Gateway, Smart Access Gateway, or Self-managed ClickHouse Clusters on an ECS Instance
Cluster Name
Nama kluster sumber.
Nama hanya boleh berisi angka dan huruf kecil.
source
Source Cluster Name
Jalankan
SELECT * FROM system.clusters;untuk mendapatkan Source Cluster Name.default
VPC IP Address
Alamat IP dan PORT (alamat TCP) setiap shard di kluster, dipisahkan koma.
PentingAnda tidak dapat menggunakan nama domain VPC atau alamat SLB kluster ApsaraDB for ClickHouse.
Format:
IP:PORT,IP:PORT,......Metode untuk mendapatkan alamat IP dan PORT kluster bervariasi tergantung skenario migrasi data.
Migrasi lintas akun atau lintas wilayah
Anda dapat menggunakan pernyataan SQL berikut untuk mendapatkan alamat IP dan PORT kluster yang dikelola sendiri:
SELECT shard_num, replica_num, host_address as ip, port FROM system.clusters WHERE cluster = 'default' and replica_num = 1;Di sini,
replica_num=1memilih set replika pertama. Anda juga dapat memilih set replika lain atau memilih satu replika dari setiap shard.Migrasi ClickHouse non-Alibaba Cloud
Jika alamat IP tidak dapat dengan mudah dipetakan ke Alibaba Cloud, Anda dapat menggunakan pernyataan SQL berikut untuk mendapatkan alamat IP dan PORT kluster yang dikelola sendiri:
SELECT shard_num, replica_num, host_address as ip, port FROM system.clusters WHERE cluster = '<cluster_name>' and replica_num = 1;Parameter dijelaskan sebagai berikut:
-
cluster_name: nama kluster tujuan.
-
replica_num=1memilih set replika pertama. Anda juga dapat memilih set replika lain atau memilih satu replika dari setiap shard.
Jika alamat IP dan port dipetakan ke Alibaba Cloud melalui terjemahan jaringan, Anda harus mengonfigurasi alamat IP dan port yang dipetakan sesuai.
192.168.0.5:9000,192.168.0.6:9000
Database Account
Akun database kluster sumber.
test
Database Password
Kata sandi untuk akun database kluster sumber.
test******
Parameter kluster tujuan
Parameter
Deskripsi
Contoh
Database Account
Akun database kluster tujuan.
test
Database Password
Kata sandi untuk akun database kluster tujuan.
test******
-
-
Konfirmasi konten migrasi.
Tinjau dengan cermat informasi tentang data yang akan dimigrasikan di halaman, lalu klik Next: Pre-detect and Start Synchronization.
-
Sistem menjalankan pemeriksaan awal pada tautan migrasi di latar belakang dan memulai tugas.
Sistem menjalankan Instance Status Detection, Storage Space Detection, dan Local Table and Distributed Table Detection pada kluster sumber dan tujuan.
-
Jika pemeriksaan awal berhasil:
Gambar berikut menunjukkan halaman yang muncul setelah pemeriksaan awal berhasil.
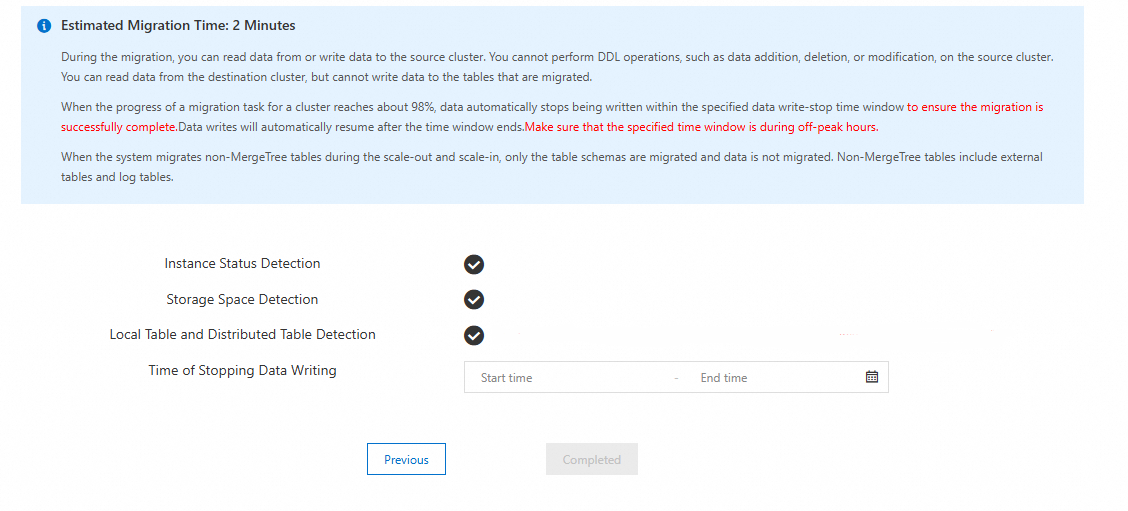
-
Tinjau dengan cermat bagaimana proses migrasi data memengaruhi instans.
-
Klik Completed.
Penting-
Setelah Anda mengklik Selesai, sistem membuat dan memulai tugas, dan statusnya berubah menjadi Running. Anda dapat melihat tugas di daftar tugas.
-
Setelah membuat tugas, Anda harus memantaunya. Di tahap akhir migrasi, Anda harus menghentikan operasi tulis ke kluster yang dikelola sendiri dan memigrasikan skema database dan tabel yang tersisa. Untuk informasi lebih lanjut, lihat Pantau tugas migrasi dan hentikan tulis ke kluster yang dikelola sendiri.
-
-
-
Jika pemeriksaan awal gagal: Ikuti petunjuk dalam pesan kesalahan dan jalankan kembali tugas migrasi data. Tabel berikut menjelaskan item pemeriksaan awal dan persyaratannya. Untuk informasi lebih lanjut tentang pesan kesalahan pemeriksaan awal dan solusinya, lihat Kesalahan pemeriksaan awal migrasi dan solusi.
Item pemeriksaan
Persyaratan
Instance Status Detection
Tugas migrasi data tidak dapat dimulai jika tugas manajemen (seperti scale-out, upgrade, atau downgrade) sedang berjalan di kluster sumber atau tujuan.
Storage Space Detection
Ruang penyimpanan yang tersedia di kluster tujuan harus minimal 1,2 kali ruang penyimpanan yang digunakan di kluster yang dikelola sendiri.
Local Table and Distributed Table Detection
Jika tabel lokal di kluster yang dikelola sendiri tidak memiliki tabel terdistribusi yang sesuai atau memiliki lebih dari satu tabel terdistribusi, pemeriksaan gagal. Untuk mengatasinya, hapus tabel terdistribusi yang berlebih atau buat satu tabel terdistribusi unik untuk tabel lokal tersebut.
-
-
Langkah 6: Evaluasi kelayakan migrasi
Jika kecepatan tulis kluster sumber kurang dari 20 MB/detik, Anda dapat melewati langkah ini.
Jika kecepatan tulis kluster sumber lebih dari 20 MB/detik, Anda harus memeriksa kecepatan tulis aktual kluster tujuan untuk mengevaluasi kelayakan migrasi. Migrasi yang berhasil memerlukan kecepatan tulis kluster tujuan yang sebanding dengan kluster sumber. Ikuti langkah-langkah berikut:
-
Lihat TairPDBShardingIOBandwidth kluster tujuan untuk menentukan kecepatan tulis aktualnya. Untuk informasi tentang cara melihat TairPDBShardingIOBandwidth, lihat Melihat data pemantauan kluster.
-
Bandingkan kecepatan tulis kluster tujuan dan sumber.
-
Jika kecepatan tulis kluster tujuan lebih besar dari kluster sumber: Migrasi kemungkinan besar akan berhasil. Lanjutkan ke Langkah 7.
-
Jika kecepatan tulis kluster tujuan kurang dari kluster sumber: Migrasi kemungkinan besar akan gagal. Kami menyarankan Anda membatalkan tugas migrasi dan menggunakan migrasi manual.
-
Langkah 7: Pantau migrasi dan hentikan tulis
-
Login ke Konsol ApsaraDB for ClickHouse.
-
Di daftar Instans Edisi Komunitas, klik ID kluster tujuan.
-
Di panel navigasi, klik .
-
Di halaman daftar migrasi instans, Anda dapat:
-
Menampilkan status dan tahap berjalan tugas migrasi.
Penting-
Saat tahap berjalan mencapai Data Migration (yaitu, migrasi skema tabel selesai), segera lanjutkan ke Langkah 8 untuk membangun ulang tabel engine Kafka/RabbitMQ di kluster yang dikelola sendiri dan melanjutkan injeksi data inkremental.
-
Pantau dengan cermat Running Information tugas target. Berdasarkan perkiraan waktu tersisa di kolom Running Information, ikuti Langkah 9 untuk menghentikan tulis ke kluster yang dikelola sendiri dan menangani tabel Kafka dan RabbitMQ.
-
-
Di kolom Tindakan, klik View Details untuk membuka halaman detail tugas. Halaman detail tugas berisi informasi berikut:
CatatanJika tugas migrasi selesai (statusnya Completed atau Canceled), konten di halaman Lihat Detail dihapus. Anda dapat melihat daftar skema tabel yang dimigrasikan di kluster tujuan dengan menjalankan pernyataan SQL berikut:
SELECT `database`, `name`, `engine_full` FROM `system`.`tables` WHERE `database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema');-
Semua skema tabel yang dimigrasikan dan status migrasinya.
-
Semua skema database yang dimigrasikan dan status migrasinya.
-
Semua pesan kesalahan untuk migrasi database dan tabel yang gagal.
-
Tabel berikut menjelaskan status tugas migrasi.
Status tugas
Deskripsi
Running
Menyiapkan lingkungan dan resource untuk migrasi.
Initializing
Menginisialisasi tugas migrasi.
Configuration Migration
Memigrasikan konfigurasi kluster.
Schema Migration
Memigrasikan semua database, tabel keluarga MergeTree, dan tabel Distributed.
Data Migration
Memigrasikan data inkremental dari tabel keluarga MergeTree.
Other Schema Migration
Memigrasikan skema tampilan materialisasi dan tabel non-MergeTree.
Data Check
Memeriksa apakah volume data tabel yang selesai di kluster tujuan konsisten dengan volume data di kluster yang dikelola sendiri. Jika tidak konsisten, tugas mungkin gagal. Kami menyarankan Anda memulai ulang migrasi.
Post-migration Configuration
Mengonfigurasi pengaturan sistem untuk kluster tujuan, seperti membersihkan resource migrasi dan mengaktifkan kembali tulis ke instans sumber.
Completed
Tugas migrasi selesai.
Canceled
Tugas migrasi dibatalkan.
-
Langkah 8: Bangun ulang tabel engine Kafka/RabbitMQ di kluster yang dikelola sendiri
Setelah tugas migrasi memasuki fase migrasi data (yaitu, migrasi skema tabel selesai), gunakan pernyataan DDL yang disimpan sebelumnya untuk membangun ulang tabel engine Kafka/RabbitMQ dan tampilan materialisasi downstream-nya di kluster yang dikelola sendiri. Setelah dibangun ulang, data inkremental kembali mengalir dan secara otomatis disinkronkan ke kluster tujuan.
Jika Anda melakukan operasi RENAME pada tabel target implisit sebelumnya, gunakan klausa TO yang mengarah ke tabel target yang diganti namanya saat membangun ulang tampilan materialisasi.
-- Bangun ulang tabel engine Kafka/RabbitMQ di kluster yang dikelola sendiri
CREATE TABLE <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME> (...)
ENGINE = Kafka/RabbitMQ
SETTINGS ...;-- Bangun ulang tampilan materialisasi (mengarah ke tabel target yang diganti namanya)
CREATE MATERIALIZED VIEW <DATABASE>.<MATERIALIZED_VIEW_NAME> TO <DATABASE>.<new_target_table_name>
AS SELECT ... FROM <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME>;Langkah 9: Hentikan penulisan dan lakukan peralihan
Saat perkiraan waktu migrasi tersisa kurang dari 10 menit atau progres migrasi mencapai 99%, lakukan langkah cutover berikut:
-
Hentikan tulis bisnis. Di kluster yang dikelola sendiri, hapus tabel engine Kafka/RabbitMQ yang dibangun ulang sebelumnya dan tampilan materialisasi downstream-nya.
-- Drop tampilan materialisasi terlebih dahulu DROP TABLE <DATABASE>.<MATERIALIZED_VIEW_NAME>; -- Lalu drop tabel engine Kafka/RabbitMQ DROP TABLE <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME>; -
Tunggu hingga progres migrasi mencapai 100% dan migrasi selesai sepenuhnya.
-
Hubungkan ke kluster tujuan dan gunakan pernyataan DDL yang disimpan sebelumnya untuk membangun ulang tabel engine Kafka/RabbitMQ dan tampilan materialisasi downstream-nya.
PentingJika Anda melakukan operasi RENAME pada tabel target implisit sebelumnya, gunakan klausa TO yang mengarah ke tabel target yang diganti namanya saat membangun ulang tampilan materialisasi.
-- Bangun ulang tabel engine Kafka/RabbitMQ di kluster tujuan CREATE TABLE <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME> (...) ENGINE = Kafka/RabbitMQ SETTINGS ...;-- Bangun ulang tampilan materialisasi (mengarah ke tabel target yang diganti namanya) CREATE MATERIALIZED VIEW <DATABASE>.<MATERIALIZED_VIEW_NAME> TO <DATABASE>.<new_target_table_name> AS SELECT ... FROM <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME>; -
Verifikasi bahwa pipa data di kluster tujuan berfungsi dengan baik dan data mengalir secara normal.
Langkah 10: Selesaikan migrasi
Setelah menghentikan penulisan ke kluster yang dikelola sendiri, Anda dapat Complete the task. Langkah ini memigrasikan data yang tersisa, melakukan pemeriksaan volume data, serta memigrasikan skema database dan tabel yang belum diproses. Anda dapat melihat konten yang telah dimigrasikan di detail tugas.
-
Jika pemeriksaan data gagal, tugas migrasi tetap berada di fase pemeriksaan volume data. Kami menyarankan membatalkan migrasi dan membuat tugas migrasi baru. Untuk informasi lebih lanjut tentang pembatalan tugas migrasi, lihat Operasi lainnya.
-
Migrasi data yang lama dapat menyebabkan akumulasi metadata berlebih di kluster tujuan. Kami menyarankan agar durasi tugas migrasi tidak melebihi 5 hari. Tugas yang melebihi 5 hari akan dibatalkan secara otomatis.
-
Login ke Konsol ApsaraDB for ClickHouse.
-
Di halaman Clusters, pilih Clusters of Community-compatible Edition, dan klik ID kluster tujuan.
-
Di panel navigasi kiri, klik .
-
Untuk tugas migrasi target, klik Complete Migration di kolom Actions.
-
Di kotak dialog Complete Migration, klik OK.
Langkah 11: Migrasikan data untuk tabel non-MergeTree
Tugas migrasi hanya memigrasikan skema tabel non-MergeTree (seperti tabel eksternal dan tabel Log), membuatnya di kluster tujuan tanpa data bisnis apa pun. Anda harus memigrasikan data bisnis secara manual. Ikuti langkah-langkah berikut:
-
Login ke kluster yang dikelola sendiri dan jalankan pernyataan berikut untuk mengidentifikasi tabel non-MergeTree yang memerlukan migrasi data.
SELECT `database` AS database_name, `name` AS table_name, `engine` FROM `system`.`tables` WHERE (`engine` NOT LIKE '%MergeTree%') AND (`engine` != 'Distributed') AND (`engine` != 'MaterializedView') AND (`engine` NOT IN ('Kafka', 'RabbitMQ')) AND (`database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema')) AND (`database` NOT IN ( SELECT `name` FROM `system`.`databases` WHERE `engine` IN ('MySQL', 'MaterializedMySQL', 'MaterializeMySQL', 'Lazy', 'PostgreSQL', 'MaterializedPostgreSQL', 'SQLite') )) -
Login ke kluster tujuan dan gunakan fungsi
remoteuntuk memigrasikan data tabel. Untuk petunjuk detail, lihat Migrasi data menggunakan fungsi remote.
Operasi lainnya
Saat tugas migrasi selesai, Migration Status berubah menjadi Completed. Daftar tugas tidak segera diperbarui, jadi segarkan halaman secara berkala untuk melihat status terbaru.
|
Tindakan |
Deskripsi |
Dampak |
Skenario |
|
Cancel Migration |
Membatalkan tugas secara paksa dan melewati pemeriksaan volume data, tanpa memigrasikan skema database dan tabel yang tersisa. |
|
Gunakan opsi ini ketika migrasi berdampak buruk pada kluster yang dikelola sendiri dan Anda perlu segera mengembalikan operasi tulis. |
|
Stop Migration |
Menghentikan migrasi data segera tetapi menyelesaikan migrasi skema database dan tabel yang tersisa. Pemeriksaan volume data dilewati. |
Migrasi data akan tidak lengkap, tetapi skema database dan tabel di instans tujuan akan lengkap. |
Gunakan opsi ini untuk menguji dataset yang sebagian dimigrasikan tanpa mengganggu operasi tulis ke kluster yang dikelola sendiri. |
Hentikan migrasi
-
Login ke Konsol ApsaraDB for ClickHouse.
-
Di halaman Clusters, pilih Clusters of Community-compatible Edition, lalu klik ID kluster target.
-
Di panel navigasi kiri, pilih .
-
Di kolom Actions untuk tugas migrasi target, klik Stop Migration.
-
Di kotak dialog Stop Migration, klik OK.
Batalkan migrasi
-
Login ke Konsol ApsaraDB for ClickHouse.
-
Di halaman Clusters, pilih Clusters of Community-compatible Edition, lalu klik ID kluster target.
-
Di panel navigasi kiri, pilih .
-
Di kolom Actions untuk tugas migrasi target, klik Cancel Migration.
-
Di kotak dialog Cancel Migration, klik OK.
Migrasi manual
Metode 1: Gunakan perintah BACKUP dan RESTORE
Untuk informasi lebih lanjut, lihat Gunakan perintah BACKUP dan RESTORE untuk mencadangkan dan memulihkan data.
Metode 2: Gunakan pernyataan INSERT FROM SELECT
Langkah 1: Migrasi metadata
Migrasi metadata ClickHouse terutama tentang migrasi DDL pembuatan tabel.
Jika Anda perlu menginstal tool clickhouse-client, pastikan versinya sesuai dengan instans ApsaraDB for ClickHouse tujuan. Anda dapat menemukan tautan unduhan di clickhouse-client.
-
Lihat daftar database di kluster yang dikelola sendiri.
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="SHOW databases" > database.listParameter:
Parameter
Deskripsi
old host
Alamat kluster yang dikelola sendiri.
old port
Port kluster yang dikelola sendiri.
old user name
Akun yang digunakan untuk login ke kluster yang dikelola sendiri. Akun harus memiliki izin baca/tulis DML, izin pengaturan, dan izin DDL.
old password
Kata sandi untuk akun tersebut.
CatatanDatabase
systemadalah database sistem dan tidak perlu dimigrasikan. Filter database ini. -
Lihat daftar tabel di kluster yang dikelola sendiri.
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="SHOW tables from <database_name>" > table.listParameter:
Parameter
Deskripsi
database_name
Nama database.
Atau, Anda dapat langsung mengkueri semua nama database dan tabel dari tabel sistem.
SELECT DISTINCT database, name FROM system.tables WHERE database != 'system';CatatanJika nama tabel yang dikueri diawali dengan
.inner., itu adalah representasi internal tampilan materialisasi dan tidak perlu dimigrasikan. Filter tabel ini. -
Ekspor DDL pembuatan tabel untuk semua tabel di database tertentu dari kluster yang dikelola sendiri.
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="SELECT concat(create_table_query, ';') FROM system.tables WHERE database='<database_name>' FORMAT TabSeparatedRaw" > tables.sql -
Impor DDL pembuatan tabel ke instans ApsaraDB for ClickHouse tujuan.
CatatanSebelum mengimpor DDL pembuatan tabel, Anda harus membuat database yang sesuai di instans ApsaraDB for ClickHouse.
clickhouse-client --host="<new host>" --port="<new port>" --user="<new user name>" --password="<new password>" -d '<database_name>' --multiquery < tables.sqlParameter:
Parameter
Deskripsi
new host
Alamat instans ApsaraDB for ClickHouse tujuan.
new port
Port instans ApsaraDB for ClickHouse tujuan.
new user name
Akun yang digunakan untuk login ke instans ApsaraDB for ClickHouse tujuan. Akun harus memiliki izin baca/tulis DML, izin pengaturan, dan izin DDL.
new password
Kata sandi untuk akun tersebut.
Langkah 2: Migrasi data
fungsi jarak jauh
-
-
Di instans ApsaraDB for ClickHouse tujuan, jalankan pernyataan SQL berikut untuk memigrasikan data.
INSERT INTO <new_database>.<new_table> SELECT * FROM remote('<old_endpoint>', <old_database>.<old_table>, '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0, max_result_rows = 0, min_insert_block_size_rows = 4294967296, min_insert_block_size_bytes = 1073741824;CatatanUntuk versi 20.8, pertama-tama gunakan fungsi
remoteRawuntuk migrasi data. Jika migrasi gagal, Anda dapat meminta peningkatan versi minor.INSERT INTO <new_database>.<new_table> SELECT * FROM remoteRaw('<old_endpoint>', <old_database>.<old_table>, '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0, max_result_rows = 0, min_insert_block_size_rows = 4294967296, min_insert_block_size_bytes = 1073741824;Parameter:
PentingGunakan parameter
_partition_iduntuk memfilter data. Ini mengurangi penggunaan resource.Parameter
Deskripsi
new_database
Nama database di instans ApsaraDB for ClickHouse tujuan.
new_table
Nama tabel di instans ApsaraDB for ClickHouse tujuan.
old_endpoint
Titik akhir instans sumber.
ClickHouse yang dikelola sendiri
Format titik akhir:
Alamat IP node instans sumber:port.PentingPort harus merupakan port TCP.
ApsaraDB for ClickHouse
Gunakan titik akhir internal VPC instans sumber, bukan titik akhir publik.
PentingPort 3306 dan 9000 adalah nilai tetap.
-
Instans Edisi Komunitas:
-
Format titik akhir:
Alamat internal VPC:3306. -
Contoh:
cc-2zeqhh5v7y6q*****.clickhouse.ads.aliyuncs.com:3306
-
-
Instans Perusahaan:
-
Format titik akhir:
Alamat internal VPC:9000. -
Contoh:
cc-bp1anv7jo84ta*****clickhouse.clickhouseserver.rds.aliyuncs.com:9000
-
old_database
Nama database kluster yang dikelola sendiri.
old_table
Nama tabel kluster yang dikelola sendiri.
username
Akun untuk kluster yang dikelola sendiri.
password
Kata sandi untuk akun kluster yang dikelola sendiri.
max_execution_time
Waktu eksekusi maksimum untuk kueri. Atur ke 0 untuk tanpa batas waktu.
max_bytes_to_read
Jumlah byte maksimum yang dapat dibaca kueri dari data sumber. Atur ke 0 untuk tanpa batas.
log_query_threads
Menentukan apakah akan mencatat informasi thread selama eksekusi kueri. Atur ke 0 untuk menonaktifkan pencatatan.
max_result_rows
Jumlah baris maksimum dalam hasil kueri. Atur ke 0 untuk tanpa batas.
min_insert_block_size_rows
Jumlah baris minimum per bagian data dalam satu penulisan. Atur ke 4294967296 (maksimum) untuk menonaktifkan batas baris. Pengaturan ini bekerja bersama min_insert_block_size_bytes untuk mencegah part kecil berlebihan.
min_insert_block_size_bytes
Ukuran minimum dalam byte per bagian data dalam satu penulisan. Atur ke 1073741824 (1 GB) untuk mencegah part kecil berlebihan dan menghindari kesalahan "Too many partitions for a single INSERT block".
_partition_id
ID partisi data.
-
Ekspor dan impor file
Ekspor data dari database kluster yang dikelola sendiri ke file, lalu impor file tersebut ke instans ApsaraDB for ClickHouse tujuan.
-
Ekspor dan impor CSV
-
Ekspor data dari database kluster yang dikelola sendiri ke file CSV.
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="select * from <database_name>.<table_name> FORMAT CSV" > table.csv -
Impor file CSV ke instans ApsaraDB for ClickHouse tujuan.
clickhouse-client --host="<new host>" --port="<new port>" --user="<new user name>" --password="<new password>" --query="insert into <database_name>.<table_name> FORMAT CSV" < table.csv
-
-
Stream dengan pipe Linux
clickhouse-client --host="<old host>" --port="<old port>" --user="<user name>" --password="<password>" --query="select * from <database_name>.<table_name> FORMAT CSV" | clickhouse-client --host="<new host>" --port="<new port>" --user="<user name>" --password="<password>" --query="INSERT INTO <database_name>.<table_name> FORMAT CSV"
Galat pemeriksaan migrasi dan solusinya
|
Pesan galat |
Deskripsi |
Solusi |
|
Missing unique distributed table or sharding_key not set. |
Tabel |
Buat |
|
The corresponding distributed table is not unique. |
|
Hapus |
|
MergeTree table on a multi-replica cluster. |
|
|
|
Data reserved table on destination cluster. |
Tabel yang akan dimigrasikan sudah ada dan berisi data di |
Hapus tabel yang bersangkutan dari |
|
Columns of distributed table and local table conflict |
Kolom pada |
Buat ulang |
|
Insufficient storage space. |
|
Tingkatkan |
|
Missing system table. |
|
Ubah file konfigurasi |
|
The table is incomplete across different nodes. |
Tabel tidak tersedia di beberapa |
Buat tabel dengan nama yang sama di |
Menghitung waktu merge pasca-migrasi
Setelah migrasi, kluster tujuan sementara melakukan operasi merge secara intensif. Hal ini meningkatkan penggunaan I/O dan dapat menyebabkan latensi yang lebih tinggi pada permintaan layanan. Jika layanan Anda sensitif terhadap latensi baca dan tulis, pertimbangkan untuk meningkatkan tipe instans dan tingkat performa ESSD guna memperpendek periode penggunaan I/O tinggi ini. Untuk informasi selengkapnya, lihat Vertical scaling, scale-out, dan scale-in kluster yang kompatibel dengan komunitas.
Gunakan rumus berikut untuk menghitung waktu merge setelah migrasi:
Rumus ini berlaku baik untuk kluster single-replica maupun master-replica.
-
Perkiraan total waktu operasi merge intensif =
MAX(hot data merge time, cold data merge time)-
Waktu merge hot data =
jumlah hot data pada satu node * 2 / MIN(instance type bandwidth, disk bandwidth * n) -
Waktu merge cold data =
(jumlah cold data / jumlah node) / MIN(instance type bandwidth, OSS read bandwidth) + (jumlah cold data / jumlah node) / MIN(instance type bandwidth, OSS write bandwidth)
-
Daftar berikut menjelaskan parameter yang digunakan dalam rumus tersebut:
-
Jumlah hot data pada satu node: Anda dapat melihat nilai ini pada baris Disk Usage - Single-Node Statistics. Untuk informasi selengkapnya, lihat Melihat informasi pemantauan kluster.
-
Instance type bandwidth
CatatanNilai bandwidth ini tidak mutlak dan bervariasi tergantung pada tipe mesin yang digunakan oleh backend ApsaraDB for ClickHouse. Nilai yang diberikan merupakan nilai minimum dan hanya sebagai referensi.
Spesifikasi
Bandwidth (MB/s)
Standard 8-core 32 GB
250
Standard 16-core 64 GB
375
Standard 24-core 96 GB
500
Standard 32-core 128 GB
625
Standard 64-core 256 GB
1250
Standard 80-core 384 GB
2000
Standard 104-core 384 GB
2000
-
Disk bandwidth: Temukan nilai ini pada baris Maximum throughput per disk (MB/s) dalam tabel ESSD performance level.
-
n: Jumlah disk pada satu node. Jalankan perintah berikut untuk mendapatkan nilai ini:
SELECT count() FROM system.disks WHERE type = 'local'; -
Jumlah cold data: Anda dapat melihat nilai ini pada baris clickhouse_cold_storage_data. Untuk informasi selengkapnya, lihat Melihat informasi pemantauan kluster.
-
Jumlah node: Jumlah node dalam kluster. Jalankan perintah berikut untuk mendapatkan nilai ini:
SELECT count() FROM system.clusters WHERE cluster = 'default' and replica_num=1; -
OSS read bandwidth: Temukan nilai ini pada kolom Total Intranet and Internet Download Bandwidth dalam tabel OSS bandwidth.
-
OSS write bandwidth: Temukan nilai ini pada kolom Total Intranet and Internet Upload Bandwidth dalam tabel OSS bandwidth.
FAQ
-
T: Bagaimana cara mengatasi error "Too many partitions for single INSERT block (more than 100)"?
J: Error ini terjadi karena operasi INSERT tunggal melebihi batas max_partitions_per_insert_block, yang secara default bernilai 100. Di ClickHouse, setiap operasi penulisan membuat satu data part, dan satu partisi dapat berisi satu atau lebih data part. Jika operasi INSERT tunggal menulis data ke terlalu banyak partisi, jumlah data part yang dihasilkan menjadi berlebihan. Hal ini dapat menurunkan performa merge dan kueri secara signifikan. ClickHouse menerapkan batas ini untuk mencegah degradasi performa.
Untuk mengatasi masalah ini, Anda dapat menyesuaikan jumlah partisi atau mengubah parameter max_partitions_per_insert_block.
-
Sesuaikan skema tabel dan metode partisi, atau hindari memasukkan data ke terlalu banyak partisi berbeda dalam satu operasi.
-
Jika Anda harus memasukkan data ke banyak partisi sekaligus, Anda dapat menaikkan batas tersebut dengan mengubah parameter max_partitions_per_insert_block. Sintaksnya adalah sebagai berikut:
SET GLOBAL ON cluster DEFAULT max_partitions_per_insert_block = XXX;CatatanKomunitas ClickHouse merekomendasikan penggunaan nilai default 100. Jangan mengatur nilai ini terlalu tinggi karena dapat menurunkan performa. Setelah impor data batch selesai, kami menyarankan agar Anda mengembalikan nilai tersebut ke nilai default-nya.
-
-
T: Mengapa koneksi dari instans ApsaraDB for ClickHouse tujuan saya ke database ClickHouse yang dikelola sendiri gagal?
J: Masalah ini terjadi jika database ClickHouse yang dikelola sendiri berada di balik firewall atau menggunakan daftar putih. Untuk mengatasinya, tambahkan Blok CIDR IPv4 dari vSwitch untuk kluster ApsaraDB for ClickHouse ke daftar putih database yang dikelola sendiri. Informasi tentang cara memperoleh Blok CIDR IPv4 dari vSwitch untuk kluster ApsaraDB for ClickHouse tersedia di View IPv4 CIDR block.
-
T: Saat melakukan scaling atau migrasi instans multi-replika, mengapa tabel non-Replicated tidak diizinkan? Jika sudah ada, bagaimana cara mengatasinya?
J: Alasan pembatasan ini dan solusinya adalah sebagai berikut:
-
Alasan: Instans multi-replika memerlukan tabel Replicated untuk menyinkronkan data antar replika. Tanpa tabel Replicated, konfigurasi multi-replika menjadi tidak efektif. Tool migrasi memilih satu replika secara acak sebagai sumber data dan memigrasikan datanya ke instans tujuan.
Jika terdapat tabel non-Replicated, data tidak disinkronkan antar replika, sehingga setiap replika menyimpan data yang terisolasi. Karena tool migrasi hanya mengambil data dari satu replika, proses ini menyebabkan kehilangan data. Sebagai contoh, seperti yang ditunjukkan pada gambar berikut, tabel MergeTree pada replika 0 (r0) berisi data 1, 2, dan 3. Tabel MergeTree pada replika 1 (r1) berisi data 4 dan 5. Jika tool migrasi memilih r0 sebagai sumber, hanya data 1, 2, dan 3 yang dimigrasikan ke instans tujuan.
-
Solusi: Jika memungkinkan, hapus tabel non-Replicated di instans sumber. Jika tidak, Anda harus mengganti tabel non-Replicated tersebut dengan tabel Replicated. Ikuti langkah-langkah berikut:
-
Login ke instans sumber.
-
Buat tabel Replicated. Skema tabel harus identik dengan tabel non-Replicated yang ingin Anda ganti, kecuali mesin (engine)-nya.
-
Migrasikan data secara manual dari tabel non-Replicated ke tabel Replicated yang baru. Pernyataan migrasinya adalah sebagai berikut:
PentingAnda harus melakukan migrasi ini pada setiap replika. Misalnya, Anda harus menjalankan pernyataan tersebut baik di r0 maupun r1.
Anda dapat memperoleh alamat IP node untuk pernyataan tersebut dengan menjalankan
SELECT * FROM system.clusters;.INSERT INTO <destination_database>.<new_replicated_table> SELECT * FROM remote('<node_IP_address>:3003', '<source_database>', '<non_replicated_table_to_replace>', '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0, min_insert_block_size_rows = 4294967296, min_insert_block_size_bytes = 1073741824; -
Tukar nama tabel non-Replicated dan tabel Replicated.
EXCHANGE TABLES <source_database>.<non_replicated_table_to_replace> AND <destination_database>.<new_replicated_table> ON CLUSTER default; -
-