Setelah memigrasikan data dari kluster ClickHouse yang dikelola sendiri ke cloud, Anda mungkin mengalami masalah kompatibilitas dan kinerja. Untuk memastikan migrasi berjalan lancar tanpa memengaruhi lingkungan produksi, kami menyarankan agar Anda terlebih dahulu melakukan migrasi di lingkungan pengujian. Hal ini memungkinkan Anda menganalisis dan menyelesaikan bottleneck kompatibilitas serta kinerja sebelum migrasi penuh.
Informasi latar belakang
Pada tahap awal operasi bisnis, Anda mungkin telah men-deploy kluster ClickHouse yang dikelola sendiri. Seiring pertumbuhan bisnis, Anda mungkin ingin memigrasikan data dari kluster tersebut ke cloud guna meningkatkan stabilitas, mengurangi biaya O&M, dan memperkuat kemampuan pemulihan bencana. Setelah migrasi, Anda mungkin menghadapi masalah berikut:
Masalah kompatibilitas versi.
Masalah kompatibilitas mesin MaterializedMySQL.
Masalah kompatibilitas SQL.
Setelah memigrasikan bisnis ke ApsaraDB for ClickHouse, Anda mungkin menemukan bahwa sumber daya CPU habis dan memori tidak mencukupi.
Untuk mengatasi masalah ini, fokuslah pada aspek kompatibilitas dan kinerja selama proses migrasi.
Analisis kompatibilitas dan resolusi
Kompatibilitas parameter
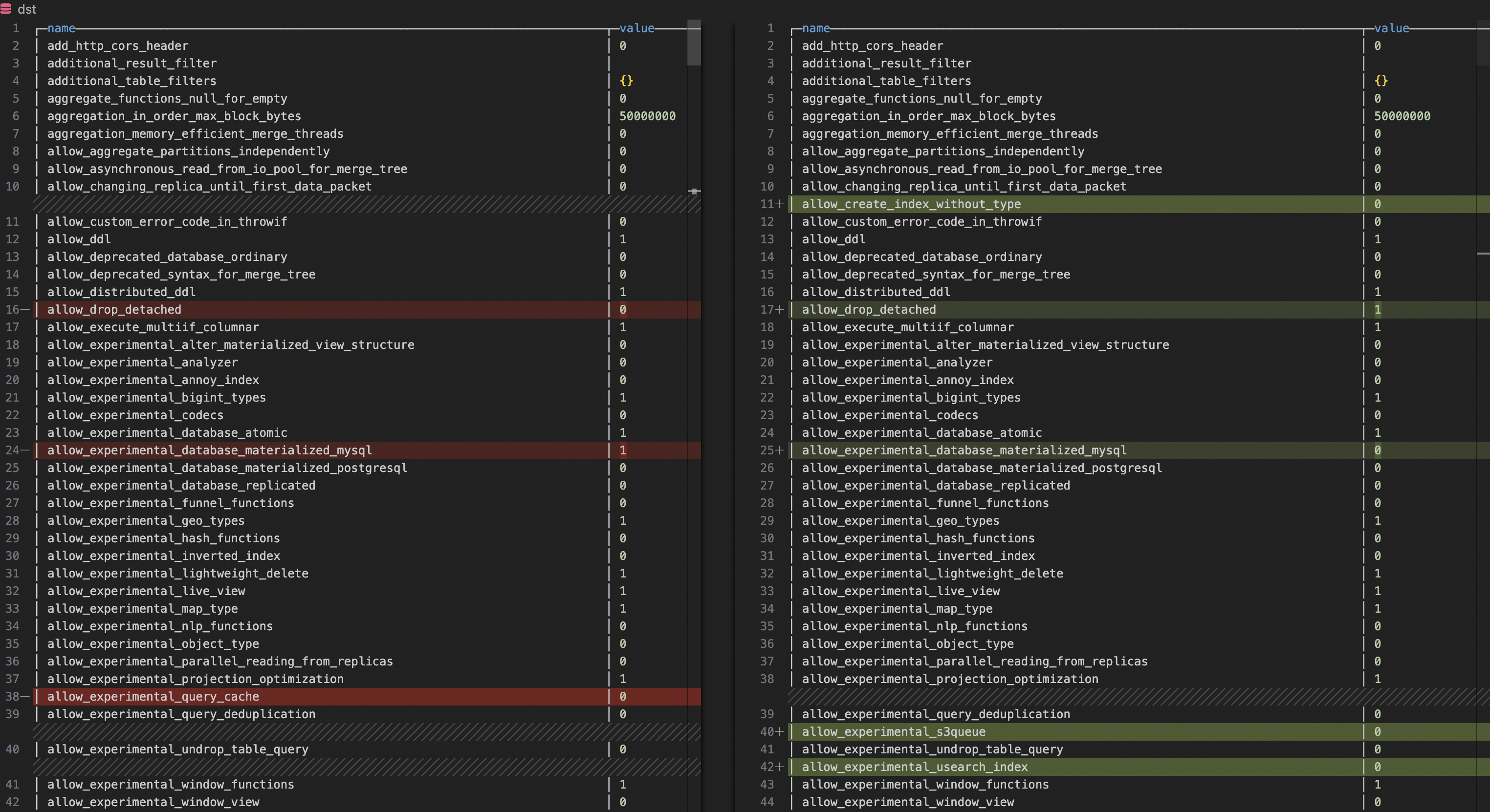
Anda dapat mengambil parameter konfigurasi dari kluster ClickHouse yang dikelola sendiri dan kluster ApsaraDB for ClickHouse.
SELECT name, groupArrayDistinct(value) AS value FROM clusterAllReplicas(`default`, system.settings) GROUP BY name ORDER BY name ASCGunakan alat perbandingan teks seperti VS Code untuk membandingkan parameter kedua kluster tersebut. Jika ditemukan ketidakkonsistenan, sesuaikan parameter kluster ApsaraDB for ClickHouse agar selaras dengan kluster ClickHouse yang dikelola sendiri.
Parameter umum yang memengaruhi kompatibilitas: `compatibility`, `prefer_global_in_and_join`, dan `distributed_product_mode`.
Parameter umum yang memengaruhi kinerja: `max_threads`, `max_bytes_to_merge_at_max_space_in_pool`, dan `prefer_global_in_and_join`.
Kompatibilitas MaterializedMySQL
Jika kluster ClickHouse yang dikelola sendiri menyinkronkan data dari database MySQL, kluster ApsaraDB for ClickHouse harus tetap menyinkronkan data dari database MySQL setelah migrasi. Oleh karena itu, perhatikan kompatibilitas mesin MaterializedMySQL.
Mesin MaterializedMySQL membuat tabel `ReplacingMergeTree` di setiap node, dan setiap node menyimpan data yang sama. Namun, versi komunitas mesin MaterializedMySQL tidak lagi dipelihara. Metode utama untuk menyinkronkan data MySQL ke ApsaraDB for ClickHouse adalah menggunakan DTS. Karena versi komunitas MaterializedMySQL tidak lagi didukung, DTS menggunakan tabel `ReplacingMergeTree` sebagai pengganti tabel `MaterializedMySQL` saat menyinkronkan data MySQL ke ApsaraDB for ClickHouse. Implementasi ini membuat tabel terdistribusi dan tabel lokal `ReplacingMergeTree` di setiap node kluster ApsaraDB for ClickHouse. ApsaraDB for ClickHouse kemudian mendistribusikan data ke setiap node melalui tabel terdistribusi. Pendekatan ini dapat menyebabkan masalah kompatibilitas yang berpotensi memengaruhi bisnis saat bermigrasi dari kluster ClickHouse yang dikelola sendiri ke ApsaraDB for ClickHouse. Masalah paling umum adalah sebagai berikut:
Masalah 1: Di kluster ClickHouse yang dikelola sendiri, MaterializedMySQL menyinkronkan data ke setiap shard. Setelah migrasi ke cloud menggunakan DTS, tabel `ReplacingMergeTree` menggantikan tabel `MaterializedMySQL`, dan data didistribusikan ke setiap node melalui tabel terdistribusi. Perubahan ini memengaruhi kueri `IN` dan `JOIN` yang melibatkan tabel terdistribusi. Untuk informasi lebih lanjut, lihat Apa yang harus saya lakukan jika terjadi kesalahan saat menggunakan subkueri pada tabel terdistribusi?.
Masalah 2: Setelah migrasi ke cloud dan mengganti tabel `MaterializedMySQL` dengan tabel `ReplacingMergeTree`, kecepatan penggabungan data pada tabel `ReplacingMergeTree` mungkin tidak cukup cepat. Hal ini dapat menghasilkan lebih banyak data duplikat dalam hasil kueri dibandingkan dengan hasil dari kluster yang dikelola sendiri. Solusi berikut dapat digunakan untuk mengatasi masalah ini:
Solusi 1: Di ApsaraDB for ClickHouse, jalankan perintah
SET global final=1untuk menggabungkan data selama kueri. Parameter ini memastikan hasil kueri bebas duplikasi, tetapi mengonsumsi lebih banyak CPU dan memori.Solusi 2: Di ApsaraDB for ClickHouse, modifikasi parameter `min_age_to_force_merge_seconds` dan `min_age_to_force_merge_on_partition_only` pada tabel target `ReplacingMergeTree`. Hal ini memicu penggabungan data lebih sering dan mencegah akumulasi data duplikat berlebihan. Contohnya:
ALTER TABLE <AIM_TABLE> MODIFY SETTING min_age_to_force_merge_on_partition_only = 1, min_age_to_force_merge_seconds = 60;min_age_to_force_merge_on_partition_only
Deskripsi: Parameter ini mengontrol kebijakan penggabungan mesin tabel MergeTree. Jika diatur ke 1, penggabungan paksa dalam partisi diaktifkan.
Nilai default: 0 (Dinonaktifkan)
min_age_to_force_merge_seconds
Deskripsi: Interval waktu untuk memaksa penggabungan bagian-bagian data.
Nilai default: 3600
Unit: detik
Verifikasi kompatibilitas SQL
Instal lingkungan Python.
Verifikasi ini memerlukan lingkungan dasar Python 3. Disarankan menggunakan instance ECS Alibaba Cloud berbasis Linux karena sudah mencakup lingkungan Python 3. Untuk informasi lebih lanjut tentang cara membeli instance ECS, lihat Beli instance.
Jika tidak menggunakan lingkungan ECS Alibaba Cloud, Anda perlu menginstal lingkungan Python secara manual. Untuk informasi lebih lanjut, kunjungi situs resmi Python.
Instal library klien Python untuk ClickHouse.
Jalankan perintah berikut di terminal atau prompt perintah.
pip3 install clickhouse_driverPastikan server verifikasi dapat berkomunikasi melalui jaringan dengan kluster ApsaraDB for ClickHouse dan kluster ClickHouse yang dikelola sendiri.
Untuk informasi lebih lanjut tentang penyelesaian masalah konektivitas jaringan antara server verifikasi dan kluster ApsaraDB for ClickHouse, lihat Bagaimana cara menyelesaikan masalah konektivitas jaringan antara kluster target dan sumber data?
Jalankan skrip Python untuk mengekstrak permintaan SELECT dari kluster ClickHouse yang dikelola sendiri dan eksekusikan di kluster ApsaraDB for ClickHouse guna memverifikasi kompatibilitas SQL-nya dengan ApsaraDB for ClickHouse. Skrip tersebut adalah sebagai berikut:
from clickhouse_driver import connect import datetime import logging # pip3 install clickhouse_driver is required. # Titik akhir VPC dari instance yang dikelola sendiri. host_old='HOST_OLD' # Port TCP dari instance yang dikelola sendiri. port_old=TCP_PORT_OLD # Nama pengguna dari instance yang dikelola sendiri. user_old='USER_OLD' # Kata sandi untuk pengguna instance yang dikelola sendiri. password_old='PASSWORD_OLD' # Titik akhir VPC dari kluster ApsaraDB for ClickHouse. host_new='HOST_NEW' # Port TCP dari kluster ApsaraDB for ClickHouse. port_new=TCP_PORT_NEW # Nama pengguna dari kluster ApsaraDB for ClickHouse. user_new='USER_NEW' # Kata sandi untuk pengguna kluster ApsaraDB for ClickHouse. password_new='PASSWORD_NEW' # Konfigurasi log. logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s') def create_connection(host, port, user, password): """Membuat koneksi ke ClickHouse.""" return connect(host=host, port=port, user=user, password=password) def get_query_hashes(cursor): """Menanyakan daftar query_hash dua hari terakhir.""" get_queryhash_sql = ''' select distinct normalized_query_hash from system.query_log where type='QueryFinish' and `is_initial_query`=1 and `user` not in ('default', 'aurora') and lower(`query`) not like 'select 1%' and lower(`query`) not like 'select timezone()%' and lower(`query`) not like '%dms-websql%' and lower(`query`) like 'select%' and `event_time` > now() - INTERVAL 2 DAY; ''' cursor.execute(get_queryhash_sql) return cursor.fetchall() def get_sql_info(cursor, queryhash): """Menanyakan informasi SQL untuk query_hash tertentu dalam 2 hari terakhir (rentang pencarian 3 hari).""" get_sqlinfo_sql = f''' select `event_time`, `query_duration_ms`, `read_rows`, `read_bytes`, `memory_usage`, `databases`, `tables`, `current_database`, `query` from system.query_log where `event_time` > now() - INTERVAL 3 DAY and `type`='QueryFinish' and `normalized_query_hash`='{queryhash}' limit 1 ''' cursor.execute(get_sqlinfo_sql) sql_info = cursor.fetchone() if sql_info: return [info.strftime('%Y-%m-%d %H:%M:%S') if isinstance(info, datetime.datetime) else info for info in sql_info[:-1]],sql_info[-1] return None def execute_sql_on_new_db(cursor, current_database, query_sql, execute_failed_sql): """Menjalankan kueri SQL di node baru dan mencatat kueri SQL yang gagal.""" try: cursor.execute(f"USE {current_database};") cursor.execute(query_sql) except Exception as error: logging.error(f'query_sql execute in new db failed: {query_sql}') execute_failed_sql[query_sql] = error def main(): # Membuat koneksi. conn_old = create_connection( host=host_old, port=port_old, user=user_old, password=password_old ) conn_new = create_connection( host=host_new, port=port_new, user=user_new, password=password_new ) # Membuat kursor. cursor_old = conn_old.cursor() cursor_new = conn_new.cursor() # Mendapatkan daftar query_hash dari node lama. old_query_hashes = get_query_hashes(cursor_old) # Mendapatkan informasi eksekusi SQL dari node lama. old_db_execute_dir = {} for queryhash in old_query_hashes: sql_info,query = get_sql_info(cursor_old, queryhash[0]) if sql_info: old_db_execute_dir[query] = sql_info # Menutup kursor dan koneksi ke node lama. cursor_old.close() conn_old.close() # Menjalankan kueri SQL di node baru. Ini adalah langkah verifikasi paling penting. execute_failed_sql = {} keys_list = list(old_db_execute_dir.keys()) for query_sql in old_db_execute_dir: position = keys_list.index(query_sql) current_database = old_db_execute_dir[query_sql][-1] logging.info(f"new db test the {position + 1}th/{len(old_db_execute_dir)}, running sql: {query_sql}\n") execute_sql_on_new_db(cursor_new, current_database, query_sql, execute_failed_sql) # Mendapatkan daftar query_hash dari node baru. new_query_hashes = get_query_hashes(cursor_new) new_db_execute_dir = {} for queryhash in new_query_hashes: sql_info,query = get_sql_info(cursor_new, queryhash[0]) if sql_info: new_db_execute_dir[query] = sql_info # Menutup kursor dan koneksi ke node baru. cursor_new.close() conn_new.close() # Mencetak informasi eksekusi SQL untuk node versi lama dan baru. for query_sql in new_db_execute_dir: if query_sql in old_db_execute_dir: logging.info(f'succeed sql: {query_sql}') logging.info(f'old sql info: {old_db_execute_dir[query_sql]}') logging.info(f'new sql info: {new_db_execute_dir[query_sql]}\n') # Mencetak kueri SQL yang gagal dieksekusi. for query_sql in execute_failed_sql: logging.error('\033[31m{}\033[0m'.format(f'failed sql: {query_sql}')) logging.error('\033[31m{}\033[0m'.format(f'failed error: {execute_failed_sql[query_sql]}\n')) if __name__ == "__main__": main()Verifikasi hasil dan selesaikan masalah yang muncul.
Verifikasi kompatibilitas SQL bersifat kompleks. Jika terjadi kesalahan, lakukan pemecahan masalah berdasarkan pesan kesalahan spesifik.
Analisis kinerja dan optimasi
Karena kluster yang dikelola sendiri telah menjalankan layanan, pengujian migrasi cloud bertahap dan optimasi kinerja menjadi sulit dilakukan. Setelah layanan dialihkan ke ApsaraDB for ClickHouse, instans mungkin mengalami masalah seperti pemanfaatan CPU penuh dan kekurangan memori. Jika kinerja instans ApsaraDB for ClickHouse menurun setelah beralih ke layanan ApsaraDB for ClickHouse, gunakan metode berikut untuk mengidentifikasi tabel atau kueri bermasalah serta bottleneck kinerja. Jika Anda sudah mengetahui tabel atau kueri penyebab kinerja buruk di instans tujuan, langsung menuju Langkah 3: Analisis kinerja SQL.
Langkah 1: Identifikasi tabel kunci yang menyebabkan bottleneck kinerja secara keseluruhan
Graf nyala (flame graphs) dan analisis `query_log` merupakan dua metode untuk mengidentifikasi tabel kunci penyebab masalah kinerja. Pembuatan graf nyala lebih kompleks namun memberikan informasi yang lebih intuitif, sedangkan analisis tabel `query_log` lebih sederhana dan tidak memerlukan alat eksternal, meskipun membutuhkan analisis manual. Kedua metode ini dapat digunakan secara bersamaan.
Buat grafik nyala api
Ekspor `trace_log`.
Gunakan `clickhouse-client` untuk masuk ke instans ApsaraDB for ClickHouse. Untuk informasi lebih lanjut tentang cara masuk, lihat Terhubung ke kluster ClickHouse menggunakan Antarmuka baris perintah.
Jalankan perintah berikut untuk mengekspor `trace_log` dan menghasilkan
cpu_trace_log.txt.-- trace_type = 'CPU' menunjukkan pelacakan CPU. -- trace_type = 'Real' menunjukkan pelacakan real-time. /clickhouse/bin/clickhouse-client -h <IP> --port <port> -q "SELECT arrayStringConcat(arrayReverse(arrayMap(x -> concat( addressToLine(x), '#', demangle(addressToSymbol(x)) ), trace)), ';') AS stack, count() AS samples FROM system.trace_log WHERE trace_type = 'CPU' and event_time >= '2025-01-08 19:31:00' and event_time < '2025-01-08 19:33:00' group by trace order by samples desc FORMAT TabSeparated settings allow_introspection_functions=1" > cpu_trace_log.txtTabel berikut menjelaskan parameter-parameter tersebut.
Parameter
Deskripsi
IP
Titik akhir VPC dari ApsaraDB for ClickHouse.
port
Port TCP dari ApsaraDB for ClickHouse.
Selain parameter di atas, konfigurasikan juga `event_time` untuk mendapatkan log jejak pada periode waktu target.
Gunakan `clickhouse-flamegraph` untuk membuat graf nyala.
Instal `clickhouse-flamegraph`. Untuk informasi lebih lanjut tentang cara mengunduh dan menginstalnya, lihat clickhouse-flamegraph.
Jalankan perintah berikut untuk menghasilkan dan menganalisis graf nyala.
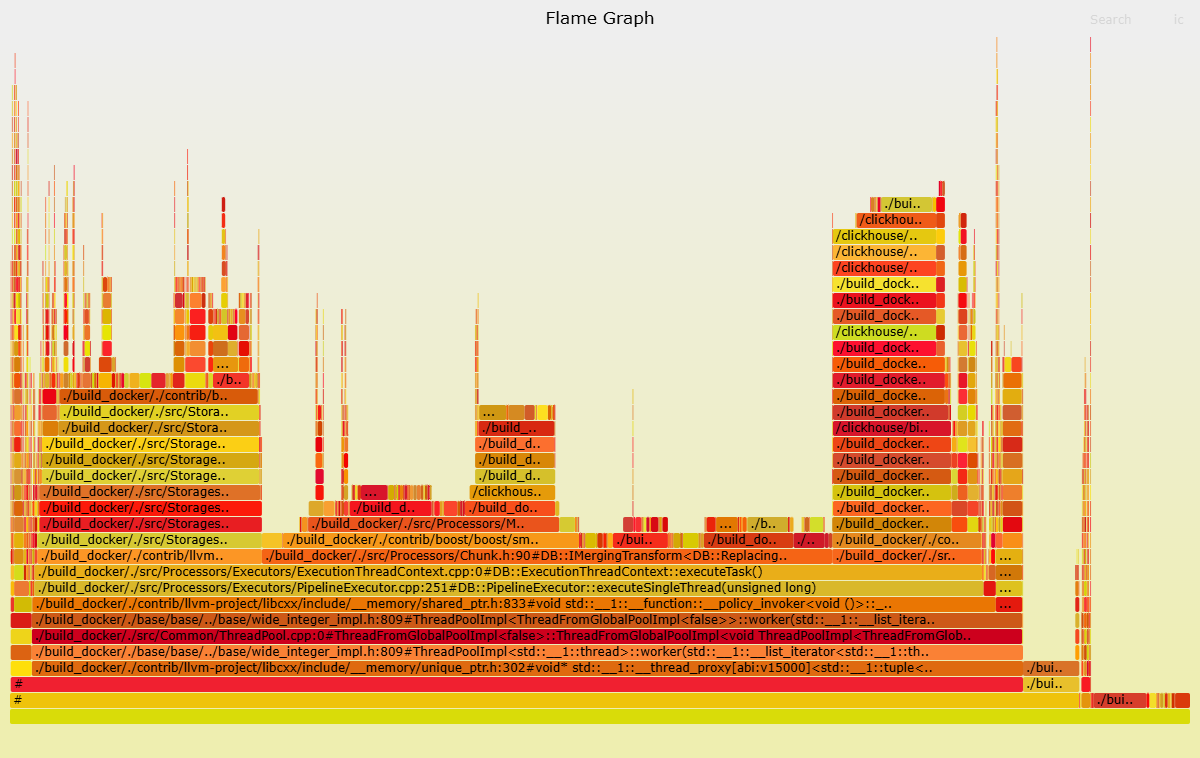
cat cpu_trace_log.txt | flamegraph.pl > cpu_trace_log.svgDalam graf nyala berikut, amati fungsi-fungsi yang mengonsumsi banyak sumber daya CPU di instans tujuan, seperti fungsi `ReplacingSortedMerge`. Fokuslah pada kueri SQL yang melibatkan tabel `ReplacingMergeTree`.
Analisis query_log
Tabel dengan permintaan `SELECT` yang mengonsumsi banyak CPU dan memori belum tentu menunjukkan kinerja keseluruhan yang buruk—hanya menunjukkan probabilitas lebih tinggi menyebabkan penggunaan CPU dan memori tinggi. Oleh karena itu, jalankan perintah terkait secara bersamaan pada kluster ClickHouse yang dikelola sendiri dan kluster ApsaraDB for ClickHouse untuk melakukan perbandingan TOP N. Setelah mengidentifikasi tabel dengan perbedaan signifikan, temukan pernyataan `SELECT` terkait. Contoh berikut menunjukkan cara menemukan tabel dengan penggunaan CPU atau memori tinggi.
Temukan tabel dengan masalah CPU
SELECT
tables,
first_value(query),
count() AS cnt,
groupArrayDistinct(normalizedQueryHash(query)) AS normalized_query_hash,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS sum_user_cpu,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS sum_system_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS avg_user_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS avg_system_cpu,
sum(memory_usage) as sum_memory_usage,
avg(memory_usage) as avg_memory_usage
FROM clusterAllReplicas(default, system.query_log)
WHERE (event_time > '2025-01-08 19:30:00') AND (event_time < '2025-01-08 20:30:00') AND (query_kind = 'Select')
GROUP BY tables
ORDER BY sum_user_cpu DESC
LIMIT 5Temukan tabel dengan masalah memori
SELECT
tables,
first_value(query),
count() AS cnt,
groupArrayDistinct(normalizedQueryHash(query)) AS normalized_query_hash,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS sum_user_cpu,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS sum_system_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS avg_user_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS avg_system_cpu,
sum(memory_usage) as sum_memory_usage,
avg(memory_usage) as avg_memory_usage
FROM clusterAllReplicas(default, system.query_log)
WHERE (event_time > '2025-01-08 19:30:00') AND (event_time < '2025-01-08 20:30:00') AND (query_kind = 'Select')
GROUP BY tables
ORDER BY sum_memory_usage
LIMIT 5Langkah 2: Identifikasi kueri SQL kunci yang menyebabkan bottleneck kinerja
Setelah mengidentifikasi tabel penyebab bottleneck kinerja pada langkah sebelumnya, temukan kueri SQL spesifik yang menjadi akar masalah. Berikut contohnya.
Temukan kueri SQL yang menyebabkan masalah CPU
SELECT
tables,
first_value(query),
count() AS cnt,
normalizedQueryHash(query) AS normalized_query_hash,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS sum_user_cpu,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS sum_system_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS avg_user_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS avg_system_cpu,
sum(memory_usage) as sum_memory_usage,
avg(memory_usage) as avg_memory_usage
FROM clusterAllReplicas(default, system.query_log)
WHERE (event_time > '2025-01-08 19:30:00') AND (event_time < '2025-01-08 20:30:00') AND (query_kind = 'Select') AND has(tables, '<AIM_TABLE>')
GROUP BY
tables,
normalized_query_hash
ORDER BY sum_user_cpu DESC
LIMIT 5Temukan kueri SQL yang menyebabkan masalah memori
SELECT
tables,
first_value(query),
count() AS cnt,
normalizedQueryHash(query) AS normalized_query_hash,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS sum_user_cpu,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS sum_system_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS avg_user_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS avg_system_cpu,
sum(memory_usage) as sum_memory_usage,
avg(memory_usage) as avg_memory_usage
FROM clusterAllReplicas(default, system.query_log)
WHERE (event_time > '2025-01-08 19:30:00') AND (event_time < '2025-01-08 20:30:00') AND (query_kind = 'Select') AND has(tables, 'AIM_TABLE')
GROUP BY
tables,
normalized_query_hash
ORDER BY sum_memory_usage
LIMIT 5Tabel berikut menjelaskan parameter tersebut:
`AIM_TABLE`: Tabel yang ingin Anda analisis masalah kinerjanya.
Selain parameter di atas, konfigurasikan juga `event_time` untuk mendapatkan data pada periode waktu target.
Langkah 3: Analisis kinerja SQL
Gunakan pernyataan `EXPLAIN` dan tabel `system.query_log` untuk menganalisis pernyataan target.
Gunakan `EXPLAIN` untuk menganalisis SQL target. Untuk informasi lebih lanjut tentang arti setiap bidang dalam keluaran `EXPLAIN`, lihat EXPLAIN.
EXPLAIN PIPELINE <SQL with performance issues>Gunakan tabel `system.query_log` untuk menganalisis SQL target.
SELECT hostname () AS host, * FROM clusterAllReplicas (`default`, system.query_log) WHERE event_time > '2025-01-18 00:00:00' AND event_time < '2025-01-18 03:00:00' AND initial_query_id = '<INITIAL_QUERY_ID>' AND type = 'QueryFinish' ORDER BY query_start_time_microsecondsTabel berikut menjelaskan parameter tersebut.
`INITIAL_QUERY_ID`: ID kueri dari pernyataan pencarian target.
Selain parameter di atas, konfigurasikan juga `event_time` untuk mendapatkan data pada periode waktu target.
Perhatikan bidang-bidang berikut dalam hasil yang dikembalikan:
ProfileEvents: Bidang ini menyediakan penghitung kejadian eksekusi kueri terperinci dan statistik untuk membantu menganalisis kinerja serta penggunaan sumber daya kueri guna perbandingan metrik. Untuk informasi lebih lanjut tentang kejadian kueri, lihat events.
Settings: Bidang ini menyediakan berbagai parameter konfigurasi yang digunakan selama eksekusi kueri. Parameter ini dapat memengaruhi perilaku dan kinerja kueri. Dengan memeriksa bidang ini, Anda dapat lebih memahami dan mengoptimalkan SQL target. Untuk informasi lebih lanjut tentang parameter kueri, lihat settings.
query_duration_ms: Bidang ini menunjukkan total waktu eksekusi kueri. Jika subkueri sangat lambat, gunakan `query_id` subkueri tersebut untuk menemukan detail eksekusinya dalam file log. Untuk informasi lebih lanjut tentang cara memodifikasi tingkat log, lihat Konfigurasi parameter config.xml.
Jika metode di atas tidak membantu mengidentifikasi penyebab degradasi kinerja pernyataan target, ambil informasi terkait pernyataan tersebut dari kluster ClickHouse yang dikelola sendiri. Kemudian, bandingkan informasi ini dengan informasi pernyataan di ApsaraDB for ClickHouse untuk menganalisis alasan penurunan kinerja setelah migrasi ke cloud.
Langkah 4: Optimalkan SQL
Setelah mengidentifikasi SQL penyebab masalah kinerja, lakukan optimasi sesuai kebutuhan. Bagian berikut menyajikan beberapa strategi optimasi. Penanganan spesifik harus disesuaikan dengan situasi aktual.
Optimasi indeks: Analisis pernyataan target, identifikasi kolom yang sering digunakan untuk penyaringan, lalu buat indeks untuk kolom tersebut.
Tipe data: Penggunaan tipe data yang tepat dapat mengurangi ruang penyimpanan dan meningkatkan kinerja kueri.
Optimasi Kueri:
Optimasi kolom kueri: Hindari penggunaan `SELECT *` dan pilih hanya kolom yang diperlukan untuk mengurangi I/O dan transmisi jaringan.
Optimasi klausa WHERE: Gunakan kunci primer dan bidang indeks dalam klausa `WHERE`.
Gunakan PREWHERE: Untuk kondisi filter yang kompleks, gunakan klausa
PREWHEREuntuk menyaring data terlebih dahulu dan mengurangi volume data yang diproses selanjutnya.Optimasi JOIN: Untuk tabel terdistribusi, gunakan `GLOBAL JOIN` untuk meningkatkan kinerja operasi `JOIN`.
Optimasi pengaturan parameter: Sesuaikan pengaturan kueri untuk meningkatkan kinerja. Misalnya, menambah nilai
max_threadsdapat memanfaatkan lebih banyak core CPU, tetapi hindari konfigurasi berlebihan yang dapat menyebabkan konflik sumber daya. Untuk informasi lebih lanjut tentang parameter kueri, lihat settings. Untuk informasi lebih lanjut tentang cara melihat pengaturan parameter dalam kueri, lihat Langkah 3: Analisis kinerja SQL.Tampilan yang di-materialisasi: Untuk kueri kompleks yang sering dieksekusi, buat tampilan yang di-materialisasi untuk menghitung hasil sebelumnya dan meningkatkan kinerja kueri.
Kompresi data: ClickHouse mengaktifkan kompresi data secara default. Anda dapat lebih mengoptimalkan penyimpanan dan kinerja kueri dengan menyesuaikan algoritma dan tingkat kompresi.
Konfigurasikan cache yang lebih besar: Untuk kueri yang sering dieksekusi dengan hasil yang jarang berubah, ApsaraDB for ClickHouse menggunakan cache kueri untuk meningkatkan kinerja. Jika cache saat ini tidak mencukupi, modifikasi parameter `uncompressed_cache_size` untuk mengalokasikan ruang cache yang lebih besar. Untuk informasi lebih lanjut tentang cara memodifikasi parameter, lihat Konfigurasi parameter config.xml.