Topik ini menggunakan model Qwen3-32B sebagai contoh untuk menunjukkan cara menyebarkan layanan inferensi model di kluster Container Service for Kubernetes (ACK) menggunakan mesin inferensi SGLang dengan arsitektur disagregasi prefill-decode (PD).
Latar Belakang
Qwen3-32B
Qwen3-32B merupakan evolusi terbaru dalam seri Qwen, yang menampilkan arsitektur padat berparameter 32,8 miliar yang dioptimalkan untuk efisiensi penalaran dan kelancaran percakapan.
Fitur utama:
Kinerja mode ganda: Unggul dalam tugas kompleks seperti penalaran logis, matematika, dan pembuatan kode, sekaligus tetap sangat efisien untuk generasi teks umum.
Kemampuan lanjutan: Menunjukkan kinerja luar biasa dalam mengikuti instruksi, dialog multi-turn, penulisan kreatif, serta penggunaan alat terbaik untuk tugas agen AI.
Jendela konteks besar: Secara native menangani hingga 32.000 token konteks, yang dapat diperluas menjadi 131.000 token menggunakan teknologi YaRN.
Dukungan multibahasa: Memahami dan menerjemahkan lebih dari 100 bahasa, menjadikannya ideal untuk aplikasi global.
Untuk informasi selengkapnya, lihat blog, GitHub, dan dokumentasi.
SGLang
SGLang adalah mesin inferensi yang menggabungkan backend berkinerja tinggi dengan frontend fleksibel, dirancang untuk beban kerja model bahasa besar (LLM) dan multimodal.
Backend berkinerja tinggi:
Peng-cache-an lanjutan: Menghadirkan RadixAttention (cache awalan yang efisien) dan PagedAttention untuk memaksimalkan throughput selama tugas inferensi kompleks.
Eksekusi efisien: Menggunakan continuous batching, speculative decoding, pemisahan PD, dan multi-LoRA batching untuk melayani banyak pengguna dan model fine-tuned secara efisien.
Paralelisme dan kuantisasi penuh: Mendukung paralelisme TP, PP, DP, dan EP, serta berbagai metode kuantisasi (FP8, INT4, AWQ, GPTQ).
Frontend fleksibel:
Antarmuka pemrograman kuat: Memungkinkan pengembang dengan mudah membangun aplikasi kompleks dengan fitur seperti chained generation, control flow, dan pemrosesan paralel.
Interaksi multimodal dan eksternal: Secara native mendukung input multimodal (seperti teks dan gambar) serta memungkinkan interaksi dengan alat eksternal, menjadikannya ideal untuk alur kerja agen lanjutan.
Dukungan model luas: Mendukung model generatif (Qwen, DeepSeek, Llama), model penyematan (E5-Mistral), dan model hadiah (Skywork).
Untuk informasi selengkapnya, lihat SGLang GitHub.
PD disagregasi
Arsitektur disagregasi PD merupakan teknik optimasi terkemuka untuk inferensi LLM. Teknik ini menyelesaikan konflik permintaan sumber daya dari dua tahap inti inferensi:
Tahap Prefill (pemrosesan prompt): Ini adalah proses yang terikat komputasi yang menangani seluruh prompt input secara paralel untuk menghasilkan cache key-value (KV) awal. Proses ini intensif komputasi namun hanya dijalankan sekali di awal permintaan.
Tahap Decode (generasi token): Ini adalah proses autoregresif yang terikat memori di mana token baru dihasilkan satu per satu. Setiap langkah memiliki beban komputasi kecil namun memerlukan akses berulang dan berkecepatan tinggi ke bobot model besar dan cache KV di Memori GPU.
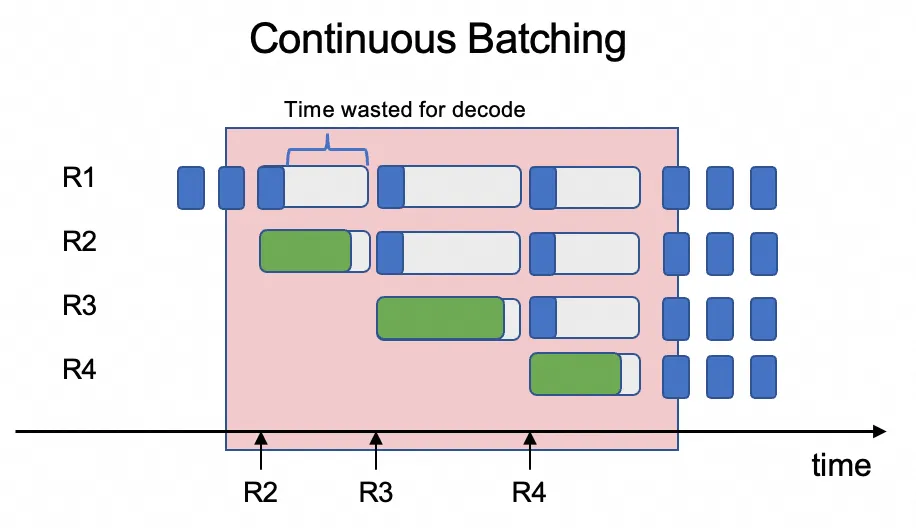
Masalah utama: Penjadwalan beban kerja campuran yang tidak efisien
Tantangannya adalah menjadwalkan dua jenis beban kerja yang berbeda ini pada GPU yang sama sangatlah tidak efisien. Mesin inferensi biasanya menggunakan continuous batching untuk memproses beberapa permintaan pengguna secara konkuren, mencampur tahap prefill dan decode dari permintaan berbeda dalam batch yang sama. Hal ini menciptakan konflik sumber daya: tahap prefill yang intensif komputasi (memproses seluruh prompt) mendominasi sumber daya GPU, menyebabkan tahap decode yang jauh lebih ringan (menghasilkan satu token) harus menunggu. Konflik sumber daya ini meningkatkan latensi tahap decode, yang pada gilirannya meningkatkan latensi sistem secara keseluruhan dan sangat menurunkan throughput.
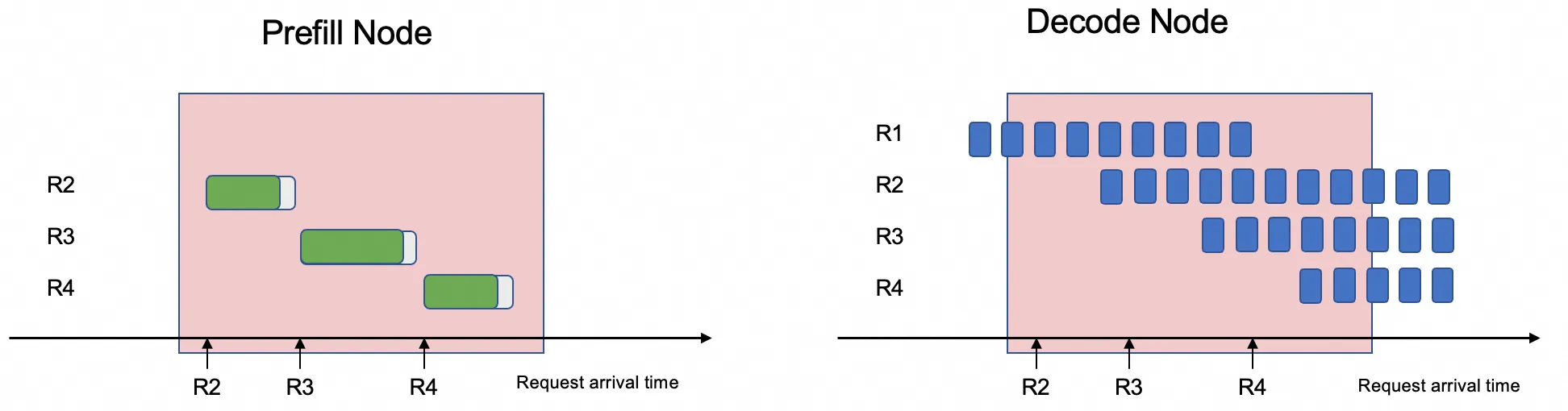
Arsitektur disagregasi PD mengatasi konflik ini dengan menguraikan kedua tahap tersebut dan menyebarkannya pada GPU khusus yang berbeda.
Pemisahan ini memungkinkan sistem mengoptimalkan penjadwalan untuk setiap beban kerja secara independen. Dengan mendedikasikan GPU tertentu untuk tugas prefill dan yang lain untuk tugas decode, konflik sumber daya dihilangkan. Hal ini mengarah pada pengurangan signifikan rata-rata Time Per Output Token (TPOT) dan peningkatan substansial throughput sistem secara keseluruhan.
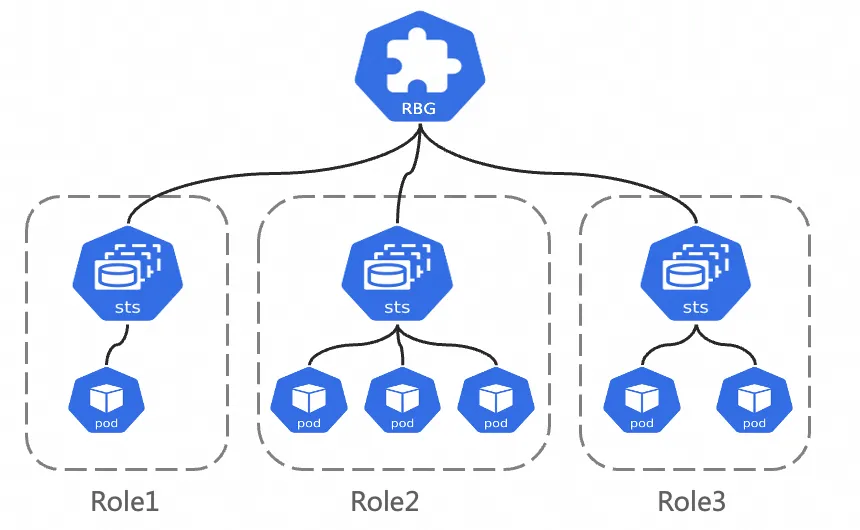
RoleBasedGroup
RoleBasedGroup (RBG) adalah beban kerja Kubernetes baru yang dirancang oleh tim ACK untuk menyederhanakan penyebaran skala besar dan O&M arsitektur kompleks seperti disagregasi PD. Untuk informasi selengkapnya, lihat Proyek GitHub RBG.
RBG didefinisikan oleh sekelompok peran, di mana setiap peran dapat dibangun berdasarkan StatefulSet, Deployment, atau jenis beban kerja lainnya. Fitur utama:
Definisi multi-peran fleksibel: RBG memungkinkan Anda mendefinisikan sejumlah peran dengan nama apa pun. Anda dapat menentukan dependensi startup di antara mereka, serta menskalakan setiap peran secara independen.
Manajemen runtime tingkat grup: Menyediakan penemuan layanan otomatis dalam grup, mendukung berbagai kebijakan restart, pembaruan bergulir, dan penjadwalan gang.
Prasyarat
Kluster ACK yang dikelola menjalankan Kubernetes 1.22 atau lebih baru dengan minimal 6 GPU, di mana setiap GPU memiliki memori minimal 32 GB. Untuk informasi selengkapnya, lihat Buat kluster ACK yang dikelola dan Tambahkan node yang dipercepat GPU ke kluster.
Node harus mendukung elastic RDMA (eRDMA) untuk GPU Direct RDMA, yang diperlukan oleh arsitektur SGLang PD. Tipe instans
ecs.ebmgn8is.32xlargedirekomendasikan. Untuk informasi selengkapnya, lihat Tipe Instans ECS Bare Metal.
Sistem operasi node harus berupa citra dengan tumpukan perangkat lunak eRDMA yang telah dipra-instal, seperti Alibaba Cloud Linux 3 64-bit (dengan eRDMA). Untuk menggunakan eRDMA, Anda memerlukan tumpukan perangkat lunak eRDMA. Saat membuat kelompok node, kami menyarankan memilih citra Alibaba Cloud Linux 3 64-bit dari Alibaba Cloud Marketplace, yang telah dilengkapi tumpukan perangkat lunak yang diperlukan. Untuk informasi selengkapnya, lihat Tambahkan node eRDMA di ACK.
Instal dan konfigurasikan ACK eRDMA Controller di kluster. Untuk informasi selengkapnya, lihat Gunakan eRDMA untuk mempercepat jaringan kontainer.
Komponen ack-rbgs telah diinstal di kluster Anda. Anda dapat melakukan langkah-langkah berikut untuk menginstal komponen tersebut.
Masuk ke Konsol Manajemen Container Service. Di panel navigasi sebelah kiri, pilih Clusters. Klik nama kluster target. Di halaman detail kluster, instal komponen ack-rbgs menggunakan Helm. Anda tidak perlu mengonfigurasi Application Name atau Namespace untuk komponen tersebut. Setelah Anda mengklik Next, kotak dialog Please Confirm muncul. Klik Ya untuk menerima nama aplikasi default (ack-rbgs) dan namespace (rbgs-system). Kemudian, pilih versi Chart terbaru dan klik OK untuk menyelesaikan instalasi.
Penyebaran model
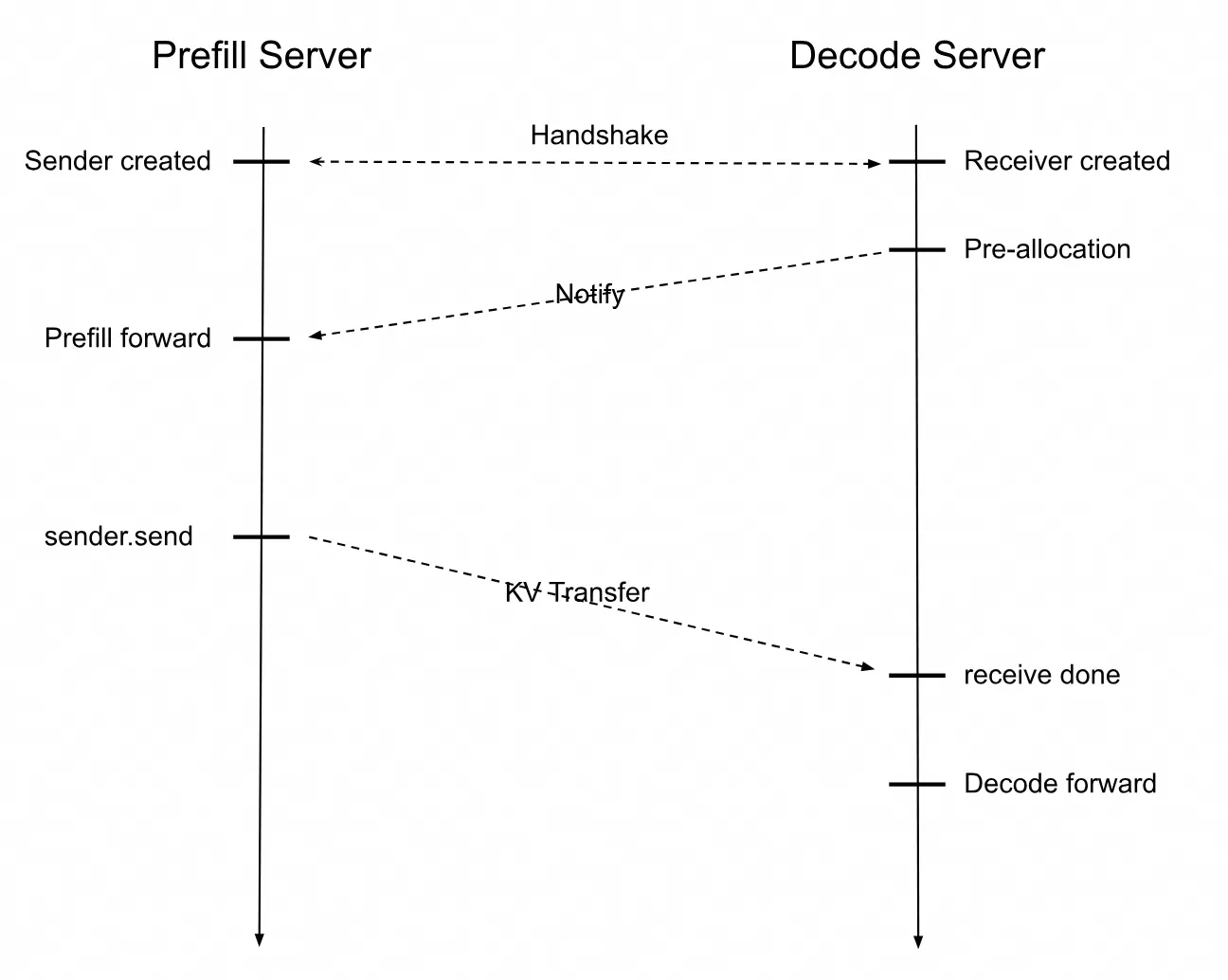
Sebarkan layanan inferensi dengan arsitektur pemisahan Prefill/Decode. Grafik deret waktu berikut menunjukkan interaksi antara SGLang Prefill Server dan Decode Server.
Saat permintaan inferensi pengguna diterima, Prefill Server membuat objek Sender, dan Decode Server membuat objek Receiver.
Server Prefill dan Decode membentuk koneksi melalui handshake. Decode Server pertama kali mengalokasikan alamat memori GPU untuk menerima cache KV. Setelah Prefill Server menyelesaikan komputasinya, ia mengirim cache KV ke Decode Server. Decode Server kemudian melanjutkan komputasi token berikutnya hingga permintaan inferensi pengguna selesai.
Langkah 1: Siapkan file model Qwen3-32B
Jalankan perintah berikut untuk mengunduh model Qwen3-32B dari ModelScope.
Jika plugin
git-lfsbelum diinstal, jalankanyum install git-lfsatauapt-get install git-lfsuntuk menginstalnya. Untuk metode instalasi lainnya, lihat Menginstal Git Large File Storage.git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/Qwen/Qwen3-32B.git cd Qwen3-32B/ git lfs pullMasuk ke Konsol OSS dan catat nama bucket Anda. Jika Anda belum membuatnya, lihat Buat bucket. Buat direktori di Object Storage Service (OSS) dan unggah model ke dalamnya.
Untuk informasi selengkapnya tentang cara menginstal dan menggunakan ossutil, lihat Instal ossutil.
ossutil mkdir oss://<your-bucket-name>/Qwen3-32B ossutil cp -r ./Qwen3-32B oss://<your-bucket-name>/Qwen3-32BBuat volume persisten (PV) bernama
llm-modeldan klaim volume persisten (PVC) untuk kluster Anda. Untuk petunjuk terperinci, lihat Buat PV dan PVC.Contoh menggunakan konsol
Buat PV
Masuk ke Konsol ACK. Di panel navigasi kiri, klik Clusters.
Di halaman Clusters, temukan kluster yang Anda inginkan dan klik namanya. Di panel navigasi kiri, pilih .
Di halaman Volumes, klik Create di pojok kanan atas.
Di kotak dialog Create Volume, konfigurasikan parameter.
Tabel berikut menjelaskan konfigurasi dasar PV contoh:
Parameter
Deskripsi
PV Type
Dalam contoh ini, pilih OSS.
Volume Name
Dalam contoh ini, masukkan llm-model.
Access Certificate
Konfigurasikan ID AccessKey dan Rahasia AccessKey yang digunakan untuk mengakses bucket OSS.
Bucket ID
Pilih bucket OSS yang Anda buat pada langkah sebelumnya.
OSS Path
Masukkan path tempat model berada, seperti
/Qwen3-32B.
Buat PVC
Di halaman Clusters, temukan kluster yang Anda inginkan dan klik namanya. Di panel navigasi kiri, pilih .
Di halaman PersistentVolumeClaims, klik Create di pojok kanan atas.
Di halaman Create PersistentVolumeClaim, konfigurasikan parameter.
Tabel berikut menjelaskan konfigurasi dasar PVC contoh.
Item Konfigurasi
Deskripsi
PVC Type
Dalam contoh ini, pilih OSS.
Name
Dalam contoh ini, masukkan llm-model.
Allocation Mode
Dalam contoh ini, pilih Existing Volumes.
Existing Volumes
Klik hyperlink Select PV dan pilih PV yang telah Anda buat.
Contoh menggunakan kubectl
Gunakan templat YAML berikut untuk membuat file bernama
llm-model.yaml, berisi konfigurasi untuk Secret, PV statis, dan PVC statis.apiVersion: v1 kind: Secret metadata: name: oss-secret stringData: akId: <your-oss-ak> # ID AccessKey yang digunakan untuk mengakses bucket OSS. akSecret: <your-oss-sk> # Rahasia AccessKey yang digunakan untuk mengakses bucket OSS. --- apiVersion: v1 kind: PersistentVolume metadata: name: llm-model labels: alicloud-pvname: llm-model spec: capacity: storage: 30Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: llm-model nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: <your-bucket-name> # Nama bucket. url: <your-bucket-endpoint> # Titik akhir, seperti oss-cn-hangzhou-internal.aliyuncs.com. otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: <your-model-path> # Dalam contoh ini, path-nya adalah /Qwen3-32B/. --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: llm-model spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gi selector: matchLabels: alicloud-pvname: llm-modelBuat Secret, PV statis, dan PVC statis.
kubectl create -f llm-model.yaml
Langkah 2: Sebarkan layanan inferensi SGLang dengan pemisahan Prefill/Decode
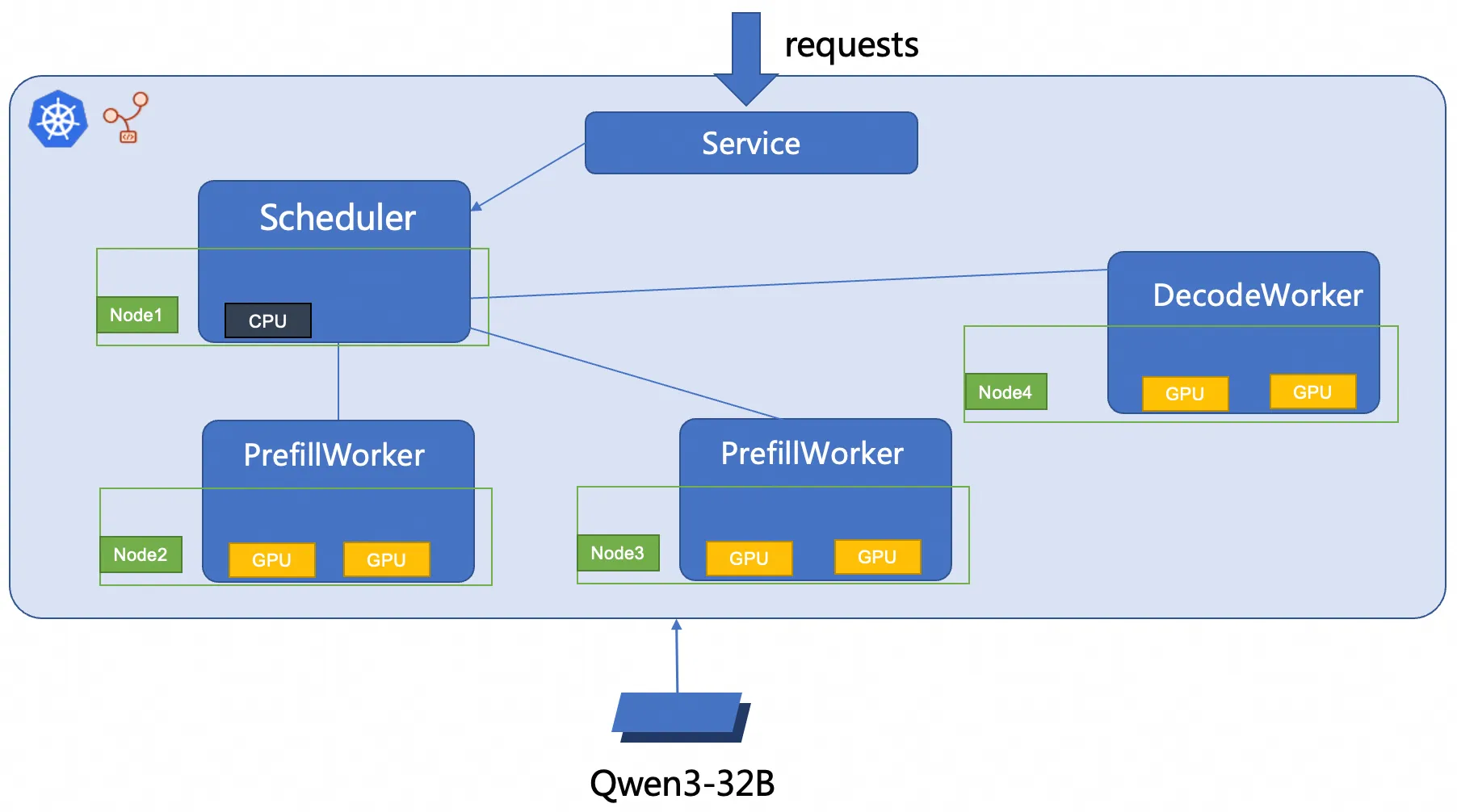
Topik ini menggunakan RBG untuk menyebarkan layanan inferensi SGLang 2P1D. Arsitektur penyebarannya ditunjukkan pada gambar berikut.
Buat file
sglang_pd.yaml.Sebarkan layanan inferensi SGLang dengan pemisahan Prefill/Decode.
kubectl create -f sglang_pd.yaml
Langkah 3: Verifikasi layanan inferensi
Jalankan perintah berikut untuk membuat penerusan port antara layanan inferensi dan lingkungan lokal Anda.
PentingPenerusan port yang dibuat oleh
kubectl port-forwardtidak memiliki keandalan, keamanan, dan skalabilitas tingkat produksi. Ini hanya cocok untuk tujuan pengembangan dan debugging, dan tidak boleh digunakan di lingkungan produksi. Untuk solusi jaringan siap produksi di kluster Kubernetes, lihat Manajemen Ingress.kubectl port-forward svc/sglang-pd 8000:8000Output yang diharapkan:
Forwarding from 127.0.0.1:8000 -> 8000 Forwarding from [::1]:8000 -> 8000Anda dapat menjalankan perintah berikut untuk mengirim permintaan inferensi contoh ke layanan inferensi model.
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "/models/Qwen3-32B", "messages": [{"role": "user", "content": "test"}], "max_tokens": 30, "temperature": 0.7, "top_p": 0.9, "seed": 10}'Output yang diharapkan:
{"id":"29f3fdac693540bfa7808fc1a8701758","object":"chat.completion","created":1753695366,"model":"/models/Qwen3-32B","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\nOkay, the user wants me to do a test. I need to first confirm their specific needs. Maybe they want to test my functions, such as answering questions or generating content.","reasoning_content":null,"tool_calls":null},"logprobs":null,"finish_reason":"length","matched_stop":null}],"usage":{"prompt_tokens":10,"total_tokens":40,"completion_tokens":30,"prompt_tokens_details":null}}Output tersebut menunjukkan bahwa model dapat menghasilkan tanggapan berdasarkan pesan uji input.
Referensi
Konfigurasikan pemantauan Prometheus untuk layanan inferensi LLM
Di lingkungan produksi, memantau kesehatan dan kinerja layanan LLM Anda sangat penting untuk menjaga stabilitas. Dengan mengintegrasikan Managed Service for Prometheus, Anda dapat mengumpulkan metrik terperinci untuk:
Mendeteksi kegagalan dan bottleneck kinerja.
Memecahkan masalah dengan data real-time.
Menganalisis tren kinerja jangka panjang untuk mengoptimalkan alokasi sumber daya.
Percepat pemuatan model dengan caching terdistribusi Fluid
File model besar (>10 GB) yang disimpan di layanan seperti OSS atau File Storage NAS dapat menyebabkan startup pod lambat (cold start) karena waktu unduh yang lama. Fluid mengatasi masalah ini dengan membuat lapisan caching terdistribusi di seluruh node kluster Anda. Hal ini secara signifikan mempercepat pemuatan model dalam dua cara utama:
Throughput data yang dipercepat: Fluid menggabungkan kapasitas penyimpanan dan lebar pita jaringan semua node di kluster. Hal ini menciptakan lapisan data paralel berkecepatan tinggi yang mengatasi bottleneck saat menarik file besar dari satu sumber jarak jauh.
Latensi I/O yang berkurang: Dengan menyimpan cache file model langsung di node komputasi tempat file tersebut dibutuhkan, Fluid memberikan akses lokal dan hampir instan ke data bagi aplikasi. Mekanisme baca yang dioptimalkan ini menghilangkan penundaan panjang yang terkait dengan I/O jaringan.
ACK Gateway dengan Inference Extension adalah controller ingress kuat yang dibangun di atas Kubernetes Gateway API untuk menyederhanakan dan mengoptimalkan perutean untuk beban kerja AI/ML. Fitur utama meliputi:
Load balancing sadar model: Menyediakan kebijakan load balancing yang dioptimalkan untuk memastikan distribusi permintaan inferensi yang efisien.
Perutean model cerdas: Mengarahkan lalu lintas berdasarkan nama model dalam muatan permintaan. Ini ideal untuk mengelola beberapa model fine-tuned (misalnya, varian LoRA berbeda) di balik satu titik akhir tunggal atau untuk menerapkan pemisahan lalu lintas untuk rilis canary.
Prioritisasi permintaan: Menetapkan tingkat prioritas ke model berbeda, memastikan permintaan ke model paling kritis Anda diproses terlebih dahulu, sehingga menjamin kualitas layanan.