Observabilitas sangat penting dalam mengelola layanan inferensi model bahasa besar (LLM) di lingkungan produksi. Dengan memantau metrik kinerja utama dari layanan, pod, dan GPU terkait, Anda dapat secara efektif mengidentifikasi hambatan kinerja serta mendiagnosis kegagalan. Topik ini menjelaskan cara mengonfigurasi pemantauan untuk layanan inferensi LLM.
Prasyarat
Managed Service for Prometheus harus diaktifkan di kluster Container Service for Kubernetes (ACK) Anda.
Penagihan
Saat mengaktifkan pemantauan untuk layanan inferensi LLM, metrik dikirim ke Managed Service for Prometheus sebagai metrik kustom.
Penggunaan metrik kustom akan menimbulkan biaya tambahan. Biaya dapat bervariasi berdasarkan faktor-faktor seperti ukuran kluster, jumlah aplikasi, dan volume data. Anda dapat memantau dan mengelola konsumsi sumber daya melalui kueri penggunaan.
Langkah 1: Akses dasbor pemantauan layanan inferensi LLM
Masuk ke Konsol ARMS.
Di panel navigasi sebelah kiri, klik Integration Center. Di bagian AI, klik kartu Cloud-Native AI Suite LLM Inference.
Di panel Cloud-Native AI Suite LLM Inference, pilih kluster target.
Jika komponen sudah terinstal, lewati langkah ini.
Di bagian Configuration Information, konfigurasikan parameter yang diperlukan dan klik OK untuk menghubungkan komponen.
Parameter
Deskripsi
Nama Akses
Nama unik untuk pemantauan layanan inferensi LLM saat ini. Parameter ini opsional.
Namespace
Namespace dari mana metrik akan dikumpulkan. Parameter ini opsional. Jika dibiarkan kosong, metrik akan dikumpulkan dari semua namespace yang memenuhi kriteria.
Pod Port
Nama port pada pod layanan inferensi LLM. Port ini akan digunakan untuk pengumpulan metrik. Nilai default:
http.Path Pengumpulan Metrik
Path HTTP pada pod layanan inferensi LLM yang mengekspos metrik dalam format Prometheus. Nilai default:
/metrics.Interval Pengumpulan (detik)
Interval waktu pengumpulan data pemantauan.
Anda dapat melihat semua komponen terintegrasi di halaman Integration Management Konsol ARMS.
Untuk detail lebih lanjut tentang Pusat Integrasi, lihat Panduan Integrasi.
Langkah 2: Terapkan layanan inferensi dengan pengumpulan metrik diaktifkan
Untuk mengaktifkan pengumpulan metrik untuk layanan inferensi LLM Anda, tambahkan label berikut ke spesifikasi pod di manifes penyebaran:
...
spec:
template:
metadata:
labels:
alibabacloud.com/inference-workload: <workload_name>
alibabacloud.com/inference-backend: <backend>Label | Tujuan | Deskripsi |
| Pengenal unik untuk layanan inferensi dalam sebuah namespace. | Nilai yang direkomendasikan: Nama sumber daya beban kerja (seperti StatefulSet, Deployment, dan RoleBasedGroup) yang mengelola pod. Saat label ini ada, pod akan ditambahkan ke target pengumpulan metrik ARMS. |
| Mesin inferensi yang digunakan oleh layanan. | Nilai yang didukung meliputi:
|
Potongan kode di atas menunjukkan cara mengaktifkan pengumpulan metrik untuk pod layanan inferensi LLM. Untuk contoh penyebaran lengkap, lihat topik berikut:
Langkah 3: Lihat dasbor pemantauan layanan inferensi
Masuk ke Konsol ACK.
Di panel navigasi sebelah kiri, klik Clusters.
Di halaman Clusters, klik kluster ACK atau Alibaba Cloud Container Compute Service (ACS) target. Di panel navigasi sebelah kiri, pilih .
Di halaman Prometheus Monitoring, pilih untuk melihat data performa rinci.
Gunakan filter dasbor untuk memilih
namespace,workload_name, danmodel_nameyang ingin Anda periksa. Untuk penjelasan rinci setiap panel, lihat Deskripsi Panel Dasbor.
Metrik Referensi
Dasbor pemantauan menggabungkan metrik dari sumber-sumber berikut:
Metrik vLLM: Lihat daftar resmi daftar metrik vLLM.
Metrik SGLang: Lihat daftar resmi daftar metrik SGLang.
Deskripsi panel dasbor
Dasbor layanan inferensi LLM dirancang untuk memberikan tampilan hierarkis performa layanan Anda. Dasbor ini mengasumsikan bahwa beban kerja Kubernetes menyebarkan layanan inferensi. Layanan inferensi dapat mencakup beberapa instans, di mana satu instans dapat terdiri dari satu atau lebih pod. Setiap instans layanan inferensi dapat menyediakan kemampuan inferensi LLM untuk satu atau lebih model, seperti model dasar yang digabungkan dengan adaptor LoRA.
Dasbor ini terorganisir menjadi tiga bagian utama:
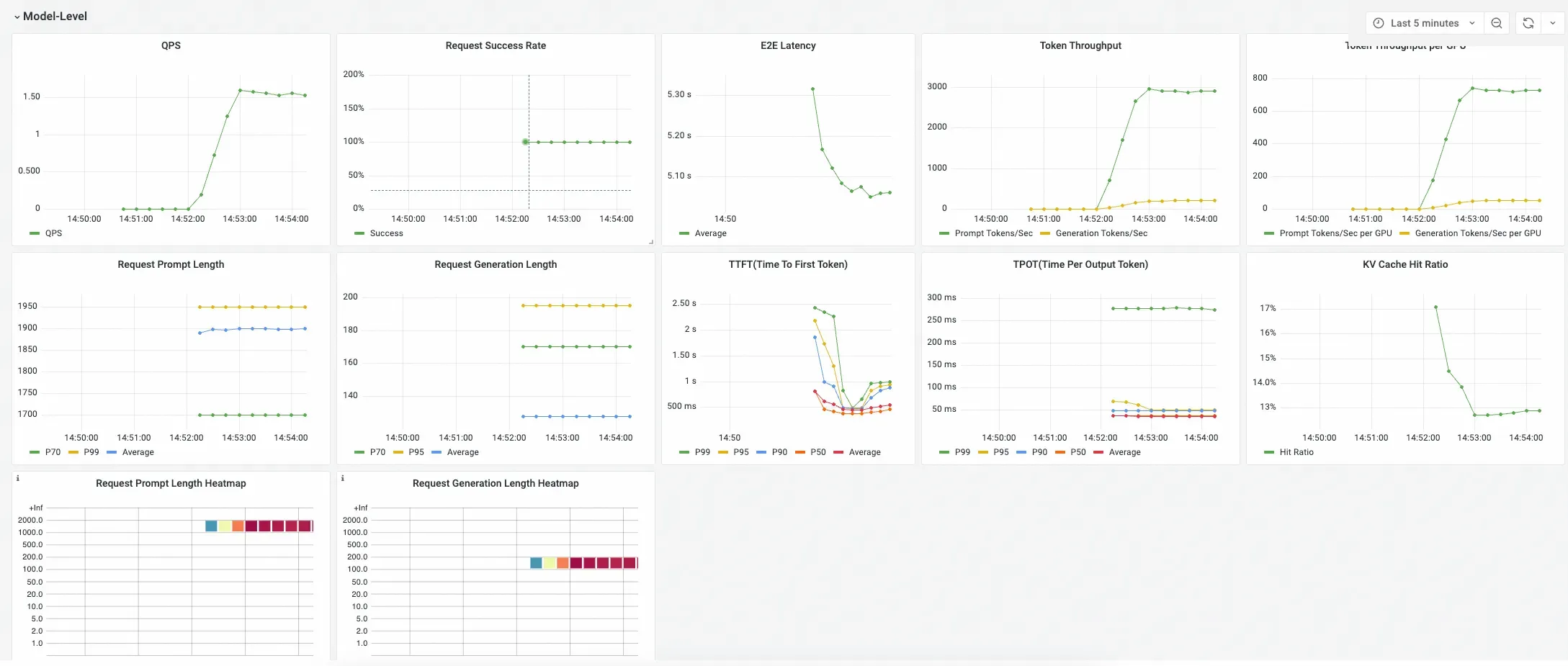
Tingkat Model
Berisi metrik agregat untuk model tertentu di seluruh layanan inferensinya. Gunakan panel ini untuk menilai performa keseluruhan dan kesehatan layanan model.
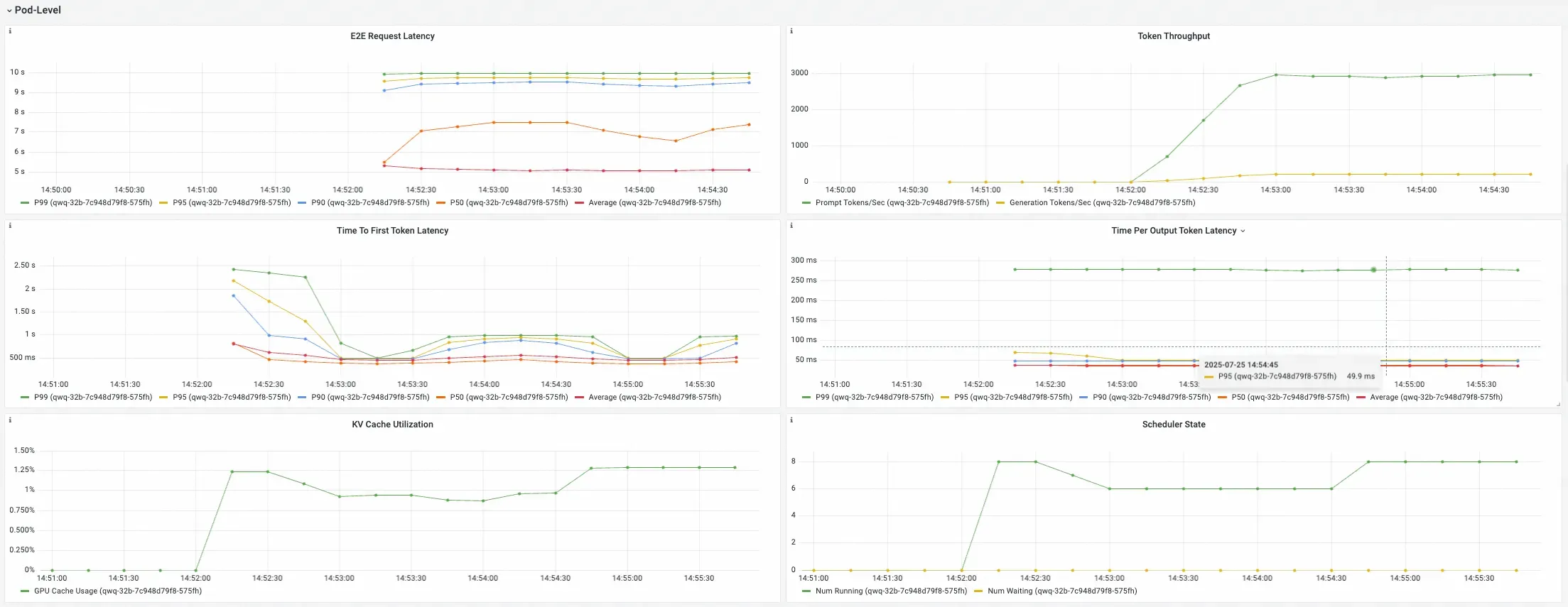
Tingkat Pod
Menyediakan pemecahan metrik performa berdasarkan pod individu. Gunakan panel ini untuk menganalisis distribusi beban dan mengidentifikasi variasi performa antara pod layanan.
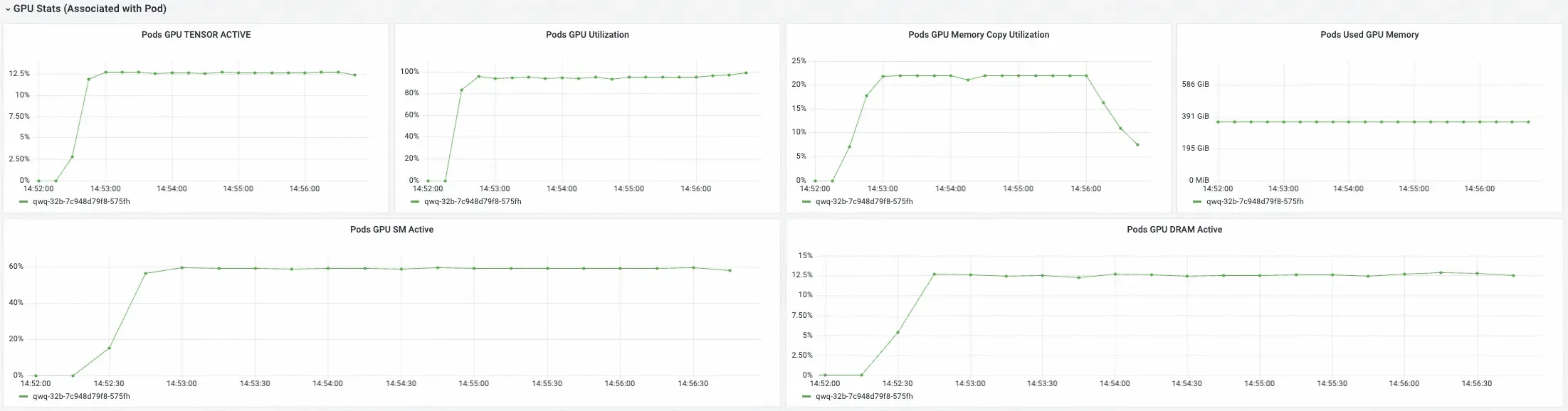
Statistik GPU (Terkait dengan Pod)
Menyediakan metrik rinci tentang pemanfaatan GPU untuk setiap pod. Gunakan panel ini untuk memahami penggunaan sumber daya GPU oleh setiap pod layanan inferensi.
Informasi panel rinci
Tabel berikut menjelaskan setiap panel di dasbor serta kompatibilitasnya dengan berbagai mesin inferensi: