Configure a batch synchronization task in DataWorks to periodically synchronize new and changed data from Tablestore to OSS. This allows for data backup and subsequent processing.
Preparations
Obtain the instance name, endpoint, and region ID of the source Tablestore table. You must also enable the Stream feature for the source table.
For a data table, enable the Stream feature when you create or modify the table. For a time series table, this feature is enabled by default.
Create an AccessKey for your Alibaba Cloud account or a RAM user that has permissions for Tablestore and OSS.
Activate DataWorks and create a workspace in the same region as your OSS bucket or Tablestore instance.
Create a Serverless resource group and attach it to the workspace. For more information about billing, see Billing of Serverless resource groups.
If your DataWorks and Tablestore instances are in different regions, you must create a VPC peering connection to establish cross-region network connectivity.
The following example shows a use case where the source table instance is in the China (Shanghai) region and the DataWorks workspace is in the China (Hangzhou) region.
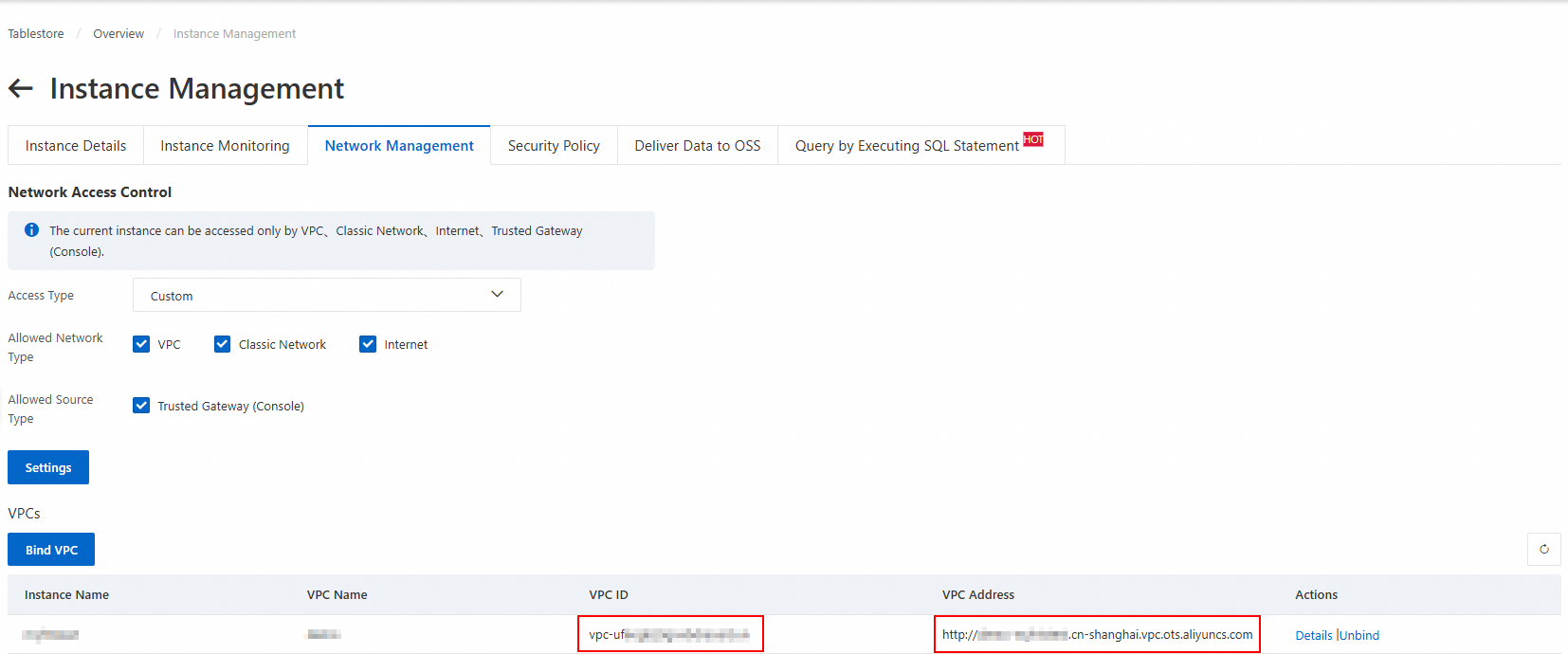
Attach a VPC to the Tablestore instance.
Log on to the Tablestore console. In the top navigation bar, select the region where the target table is located.
Click the instance alias to navigate to the Instance Management page.
On the Network Management tab, click Bind VPC. Select a VPC and vSwitch, enter a VPC name, and then click OK.
Wait for the VPC to attach. The page automatically refreshes to display the VPC ID and VPC Address in the VPC list.
NoteWhen you add a Tablestore data source in the DataWorks console, you must use this VPC address.
Obtain the VPC information for the DataWorks workspace resource group.
Log on to the DataWorks console. In the top navigation bar, select the region where your workspace is located. In the navigation pane on the left, click Workspace to go to the Workspaces page.
Click the workspace name to go to the Workspace Details page. In the left navigation pane, click Resource Group to view the resource groups attached to the workspace.
To the right of the target resource group, click Network Settings. In the Data Scheduling & Data Integration section, view the VPC ID of the attached virtual private cloud.
Create a VPC peering connection and configure routes.
Log on to the VPC console. In the navigation pane on the left, click VPC Peering Connection and then click Create VPC Peering Connection.
On the Create VPC Peering Connection page, enter a name for the peering connection and select the requester VPC instance, accepter account type, accepter region, and accepter VPC instance. Then, click OK.
On the VPC Peering Connection page, find the VPC peering connection and click Configure route in the Requester VPC and Accepter columns.
For the destination CIDR block, enter the CIDR block of the peer VPC. For example, when you configure a route entry for the requester VPC, enter the CIDR block of the accepter VPC. When you configure a route entry for the accepter VPC, enter the CIDR block of the requester VPC.
Procedure
Step 1: Add a Tablestore data source
Configure a Tablestore data source in DataWorks to connect to the source data.
Log on to the DataWorks console. Switch to the destination region. In the navigation pane on the left, choose . From the drop-down list, select the workspace and click Go To Data Integration.
In the navigation pane on the left, click Data source.
On the Data Sources page, click Add Data Source.
In the Add Data Source dialog box, search for and select Tablestore as the data source type.
In the Add OTS Data Source dialog box, configure the data source parameters as described in the following table.
Parameter
Description
Data Source Name
The data source name must be a combination of letters, digits, and underscores (_). It cannot start with a digit or an underscore (_).
Data Source Description
A brief description of the data source. The description cannot exceed 80 characters in length.
Region
Select the region where the Tablestore instance resides.
Tablestore Instance Name
The name of the Tablestore instance.
Endpoint
The endpoint of the Tablestore instance. Use the VPC address.
AccessKey ID
The AccessKey ID and AccessKey secret of the Alibaba Cloud account or RAM user.
AccessKey Secret
Test the resource group connectivity.
When you create a data source, you must test the connectivity of the resource group to ensure that the resource group for the sync task can connect to the data source. Otherwise, the data sync task cannot run.
In the Connection Configuration section, click Test Network Connectivity in the Connection Status column for the resource group.
After the connectivity test passes, click Complete. The new data source appears in the data source list.
If the connectivity test fails, use the Network Connectivity Diagnostic Tool to troubleshoot the issue.
Step 2: Add an OSS data source
Configure the OSS data source as the destination for data exporting.
Click Add Data Source again. In the dialog box, search for and select OSS as the data source type, and then configure the data source parameters.
Parameter
Description
Data Source Name
The data source name must consist of letters, digits, and underscores (_). It cannot start with a digit or an underscore (_).
Data Source Description
A brief description of the data source. The description cannot exceed 80 characters.
Access Mode
RAM Role Authorization Mode: The DataWorks service account accesses the data source by assuming a RAM role. If this is the first time you select this mode, follow the on-screen instructions to grant the required permissions.
AccessKey Mode: Access the data source using the AccessKey ID and AccessKey secret of an Alibaba Cloud account or RAM user.
Role
This parameter is required only when you set Access Mode to RAM Role Authorization Mode.
AccessKey ID
These parameters are required only when you set Access Mode to AccessKey Mode. The AccessKey ID and AccessKey secret of the Alibaba Cloud account or RAM user.
AccessKey Secret
Region
The region where the bucket is located.
Endpoint
The OSS domain name. For more information, see OSS regions and endpoints.
Bucket
The name of the bucket.
After you configure the parameters and the connectivity test passes, click Complete to add the data source.
Step 3: Configure a batch synchronization task
Create and configure a data synchronization task to define the data transfer rules from Tablestore to OSS.
Create a task node
Navigate to the Data Development page.
Log on to the DataWorks console.
In the top navigation bar, select the resource group and region.
In the navigation pane on the left, click .
Select the corresponding workspace and click Go To Data Studio.
In the Data Studio console, click the
 icon next to Workspace Directories, and then select .
icon next to Workspace Directories, and then select .In the Create Node dialog box, select a Path. Set the source to Tablestore Stream and the destination to OSS. Enter a Name and click OK.
Configure the synchronization task
In the Project Directory, click the new batch synchronization task node and configure it using the codeless UI or the code editor.
When you synchronize a time series table, only use the code editor to configure the synchronization task.
Codeless UI (default)
Configure the following items:
Data Source: Select the data sources for the source and destination.
Runtime Resource: Select a resource group. The system automatically tests the connectivity of the data source.
Data Source: Select the source data table. Retain the default settings for other parameters or modify them as needed.
Destination: Select a Text Type and configure the corresponding parameters.
Text Type: The supported text types are csv, text, orc, and parquet.
Object Name (Path Included): The path and name of the file in the OSS bucket. For example:
tablestore/resource_table.csv.Column Delimiter: The default is
,. For non-visible delimiters, enter the Unicode encoding, such as\u001bor\u007c.Object Path: The path of the file in the OSS bucket. This parameter is required only for parquet files.
File Name: The name of the file in the OSS bucket. This parameter is required only when the file type is parquet.
Destination Field Mapping: The mapping is automatically configured based on the source table's primary key and incremental change data. Modify the mapping as needed.
Click Save at the top of the page after you complete the configuration.
Code editor
Click Code Editor at the top of the page to edit the script.
Data table
The following example shows how to configure a task where the destination file type is CSV. The source data table has a primary key that includes one int primary key column named id and one string primary key column named name. When you configure the task, replace the datasource, table, and destination file name (object) in the example script.
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "otsstream",
"parameter": {
"statusTable": "TableStoreStreamReaderStatusTable",
"maxRetries": 31,
"isExportSequenceInfo": false,
"datasource": "source_data",
"column": [
"id",
"name",
"colName",
"version",
"colValue",
"opType",
"sequenceInfo"
],
"startTimeString": "${startTime}",
"table": "source_table",
"endTimeString": "${endTime}"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "oss",
"parameter": {
"dateFormat": "yyyy-MM-dd HH:mm:ss",
"datasource": "target_data",
"writeSingleObject": false,
"column": [
"0",
"1",
"2",
"3",
"4",
"5",
"6"
],
"writeMode": "truncate",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileFormat": "csv",
"object": "tablestore/source_table.csv"
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 2,
"throttle": false
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Time series table
The following example shows how to configure a task where the destination file type is CSV. The source time series table's timeline data includes one int attribute column named value. When you configure the task, replace the datasource, table, and destination file name (object) in the example script.
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "otsstream",
"parameter": {
"statusTable": "TableStoreStreamReaderStatusTable",
"maxRetries": 31,
"isExportSequenceInfo": false,
"datasource": "source_data",
"column": [
{
"name": "_m_name"
},
{
"name": "_data_source"
},
{
"name": "_tags"
},
{
"name": "_time"
},
{
"name": "value",
"type": "int"
}
],
"startTimeString": "${startTime}",
"table": "source_series",
"isTimeseriesTable":"true",
"mode": "single_version_and_update_only",
"endTimeString": "${endTime}"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "oss",
"parameter": {
"dateFormat": "yyyy-MM-dd HH:mm:ss",
"datasource": "target_data",
"writeSingleObject": false,
"writeMode": "truncate",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileFormat": "csv",
"object": "tablestore/source_series.csv"
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 2,
"throttle": false
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}After you finish editing the script, click Save at the top of the page.
Debug the synchronization task
On the right side of the page, click Debugging Configurations. Select the resource group for the task and specify the Script Parameters.
startTime: The inclusive start time of the incremental data sync. Example:
20251119200000.endTime: The end time for the incremental data sync (exclusive). Example:
20251119205000.Incremental synchronization uses a recurring schedule that runs every 5 minutes. The plugin introduces a 5-minute latency. This results in a total synchronization latency of 5 to 10 minutes. When you configure the end time, avoid setting a time that is within 10 minutes of the current time.
Click Run at the top of the page to start the synchronization task.
The preceding example values indicate that incremental data is synchronized from
20:00 on11/19/2025to20:50(exclusive).
Step 4: View the synchronization result
After the synchronization task is complete, you can view the execution status in the log and check the resulting file in the OSS bucket.
View the task running status and result at the bottom of the page. The following log information indicates that the sync task ran successfully.
2025-11-18 11:16:23 INFO Shell run successfully! 2025-11-18 11:16:23 INFO Current task status: FINISH 2025-11-18 11:16:23 INFO Cost time is: 77.208sView the file in the destination bucket.
Go to the Bucket List. Click the destination bucket to view or download the result file.
Going live
After debugging is complete, configure the startTime and endTime scheduling parameters and a recurring scheduling policy in the Scheduling Settings pane on the right side of the page. Then, publish the task to the production environment. For more information about the configuration rules, see Configure and use scheduling parameters, Scheduling policy, and Scheduling time.