Tablestore provides multiple methods to migrate or synchronize data between tables. You can use Tunnel Service, DataWorks, DataX, or the command line interface to synchronize data from one table to another.
Prerequisites
Obtain the instance names, endpoints, and region IDs for the source and target tables.
Create an AccessKey for your Alibaba Cloud account or a RAM user with Tablestore permissions.
Synchronize data using an SDK
Synchronize data between tables using Tunnel Service. This method supports data synchronization within the same region, across different regions, and across different accounts. Tunnel Service captures data changes and synchronizes them to the target table in real time. The following example shows how to use the Java SDK to implement this synchronization.
Before you run the code, replace the table names, instance names, and endpoints with the actual values for the source and target tables. Then, configure the AccessKey ID and AccessKey secret as environment variables.
import com.alicloud.openservices.tablestore.*;
import com.alicloud.openservices.tablestore.core.auth.DefaultCredentials;
import com.alicloud.openservices.tablestore.core.auth.ServiceCredentials;
import com.alicloud.openservices.tablestore.model.*;
import com.alicloud.openservices.tablestore.model.tunnel.*;
import com.alicloud.openservices.tablestore.tunnel.worker.IChannelProcessor;
import com.alicloud.openservices.tablestore.tunnel.worker.ProcessRecordsInput;
import com.alicloud.openservices.tablestore.tunnel.worker.TunnelWorker;
import com.alicloud.openservices.tablestore.tunnel.worker.TunnelWorkerConfig;
import com.alicloud.openservices.tablestore.writer.RowWriteResult;
import com.alicloud.openservices.tablestore.writer.WriterConfig;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicLong;
public class TableSynchronization {
// Source table configurations: table name, instance name, endpoint, AccessKey ID, AccessKey secret
final static String sourceTableName = "sourceTableName";
final static String sourceInstanceName = "sourceInstanceName";
final static String sourceEndpoint = "sourceEndpoint";
final static String sourceAccessKeyId = System.getenv("SOURCE_TABLESTORE_ACCESS_KEY_ID");
final static String sourceKeySecret = System.getenv("SOURCE_TABLESTORE_ACCESS_KEY_SECRET");
// Target table configurations: table name, instance name, endpoint, AccessKey ID, AccessKey secret
final static String targetTableName = "targetTableName";
final static String targetInstanceName = "targetInstanceName";
final static String targetEndpoint = "targetEndpoint";
final static String targetAccessKeyId = System.getenv("TARGET_TABLESTORE_ACCESS_KEY_ID");
final static String targetKeySecret = System.getenv("TARGET_TABLESTORE_ACCESS_KEY_SECRET");
// Tunnel name
static String tunnelName = "source_table_tunnel";
// TablestoreWriter: A tool for high-concurrency data writes.
static TableStoreWriter tableStoreWriter;
// Statistics for successful and failed rows.
static AtomicLong succeedRows = new AtomicLong();
static AtomicLong failedRows = new AtomicLong();
public static void main(String[] args) {
// Create the target table.
createTargetTable();
System.out.println("Create target table: Done.");
// Initialize TunnelClient.
TunnelClient tunnelClient = new TunnelClient(sourceEndpoint, sourceAccessKeyId, sourceKeySecret, sourceInstanceName);
// Create a tunnel.
String tunnelId = createTunnel(tunnelClient);
System.out.println("Create tunnel: Done.");
// Initialize TablestoreWriter.
tableStoreWriter = createTablesStoreWriter();
// Synchronize data through the tunnel.
TunnelWorkerConfig config = new TunnelWorkerConfig(new SimpleProcessor());
TunnelWorker worker = new TunnelWorker(tunnelId, tunnelClient, config);
try {
System.out.println("Connecting to tunnel and working...");
worker.connectAndWorking();
// Monitor the tunnel status. When the status changes from full data synchronization to incremental synchronization, the data synchronization is complete.
while (true) {
if (tunnelClient.describeTunnel(new DescribeTunnelRequest(sourceTableName, tunnelName)).getTunnelInfo().getStage().equals(TunnelStage.ProcessStream)) {
break;
}
Thread.sleep(5000);
}
// Synchronization result.
System.out.println("Data synchronization completed.");
System.out.println("* Succeeded rows: " + succeedRows.get());
System.out.println("* Failed rows: " + failedRows.get());
// Delete the tunnel.
tunnelClient.deleteTunnel(new DeleteTunnelRequest(sourceTableName, tunnelName));
// Shut down resources.
worker.shutdown();
config.shutdown();
tunnelClient.shutdown();
tableStoreWriter.close();
}catch(Exception e){
e.printStackTrace();
worker.shutdown();
config.shutdown();
tunnelClient.shutdown();
tableStoreWriter.close();
}
}
private static void createTargetTable() throws ClientException {
// Query source table information.
SyncClient sourceClient = new SyncClient(sourceEndpoint, sourceAccessKeyId, sourceKeySecret, sourceInstanceName);
DescribeTableResponse response = sourceClient.describeTable(new DescribeTableRequest(sourceTableName));
// Create the target table.
SyncClient targetClient = new SyncClient(targetEndpoint, targetAccessKeyId, targetKeySecret, targetInstanceName);
TableMeta tableMeta = new TableMeta(targetTableName);
response.getTableMeta().getPrimaryKeyList().forEach(
item -> tableMeta.addPrimaryKeyColumn(new PrimaryKeySchema(item.getName(), item.getType()))
);
TableOptions tableOptions = new TableOptions(-1, 1);
CreateTableRequest request = new CreateTableRequest(tableMeta, tableOptions);
targetClient.createTable(request);
// Shut down resources.
sourceClient.shutdown();
targetClient.shutdown();
}
private static String createTunnel(TunnelClient client) {
// Create a tunnel and return the tunnel ID.
CreateTunnelRequest request = new CreateTunnelRequest(sourceTableName, tunnelName, TunnelType.BaseAndStream);
CreateTunnelResponse response = client.createTunnel(request);
return response.getTunnelId();
}
private static class SimpleProcessor implements IChannelProcessor {
@Override
public void process(ProcessRecordsInput input) {
if(input.getRecords().isEmpty())
return;
System.out.print("* Start to consume " + input.getRecords().size() + " records... ");
for (StreamRecord record : input.getRecords()) {
switch (record.getRecordType()) {
// Write row data.
case PUT:
RowPutChange putChange = new RowPutChange(targetTableName, record.getPrimaryKey());
putChange.addColumns(getColumnsFromRecord(record));
tableStoreWriter.addRowChange(putChange);
break;
// Update row data.
case UPDATE:
RowUpdateChange updateChange = new RowUpdateChange(targetTableName, record.getPrimaryKey());
for (RecordColumn column : record.getColumns()) {
switch (column.getColumnType()) {
// Add an attribute column.
case PUT:
updateChange.put(column.getColumn().getName(), column.getColumn().getValue(), System.currentTimeMillis());
break;
// Delete a version of an attribute column.
case DELETE_ONE_VERSION:
updateChange.deleteColumn(column.getColumn().getName(),
column.getColumn().getTimestamp());
break;
// Delete an attribute column.
case DELETE_ALL_VERSION:
updateChange.deleteColumns(column.getColumn().getName());
break;
default:
break;
}
}
tableStoreWriter.addRowChange(updateChange);
break;
// Delete row data.
case DELETE:
RowDeleteChange deleteChange = new RowDeleteChange(targetTableName, record.getPrimaryKey());
tableStoreWriter.addRowChange(deleteChange);
break;
}
}
// Flush the buffer.
tableStoreWriter.flush();
System.out.println("Done.");
}
@Override
public void shutdown() {
}
}
public static List<Column> getColumnsFromRecord(StreamRecord record) {
List<Column> retColumns = new ArrayList<>();
for (RecordColumn recordColumn : record.getColumns()) {
// Replace the data version number with the current timestamp to prevent exceeding the maximum version drift.
Column column = new Column(recordColumn.getColumn().getName(), recordColumn.getColumn().getValue(), System.currentTimeMillis());
retColumns.add(column);
}
return retColumns;
}
private static TableStoreWriter createTablesStoreWriter() {
WriterConfig config = new WriterConfig();
// Row-level callback to count successful and failed rows and print information about failed rows.
TableStoreCallback<RowChange, RowWriteResult> resultCallback = new TableStoreCallback<RowChange, RowWriteResult>() {
@Override
public void onCompleted(RowChange rowChange, RowWriteResult rowWriteResult) {
succeedRows.incrementAndGet();
}
@Override
public void onFailed(RowChange rowChange, Exception exception) {
failedRows.incrementAndGet();
System.out.println("* Failed Row: " + rowChange.getTableName() + " | " + rowChange.getPrimaryKey() + " | " + exception.getMessage());
}
};
ServiceCredentials credentials = new DefaultCredentials(targetAccessKeyId, targetKeySecret);
return new DefaultTableStoreWriter(targetEndpoint, credentials, targetInstanceName,
targetTableName, config, resultCallback);
}
}Synchronize data using DataWorks
DataWorks provides a visual data integration service that lets you configure synchronization tasks between Tablestore tables using a graphical interface. You can also use other tools, such as DataX, to synchronize data between Tablestore tables.
Step 1: Preparations
Create a target data table. Ensure that the primary key structure of the target table, including the data types and order of the primary key columns, is identical to that of the source table.
Activate DataWorks and create a workspace in the region where the source or target table is located.
Create a serverless resource group and attach it to the workspace. For more information about billing, see Serverless resource group billing.
If the source and target tables are in different regions, you must create a VPC peering connection to establish cross-region network connectivity.
The following example describes a scenario in which the DataWorks workspace and the source table instance are in the China (Hangzhou) region, and the target table is in the China (Shanghai) region.
Attach a VPC to the Tablestore instance.
Log on to the Tablestore console. In the top navigation bar, select the region where the target table is located.
Click the instance alias to navigate to the Instance Management page.
On the Network Management tab, click Bind VPC. Select a VPC and vSwitch, enter a VPC name, and then click OK.
Wait for the VPC to attach. The page automatically refreshes to display the VPC ID and VPC Address in the VPC list.
NoteWhen you add a Tablestore data source in the DataWorks console, you must use this VPC address.
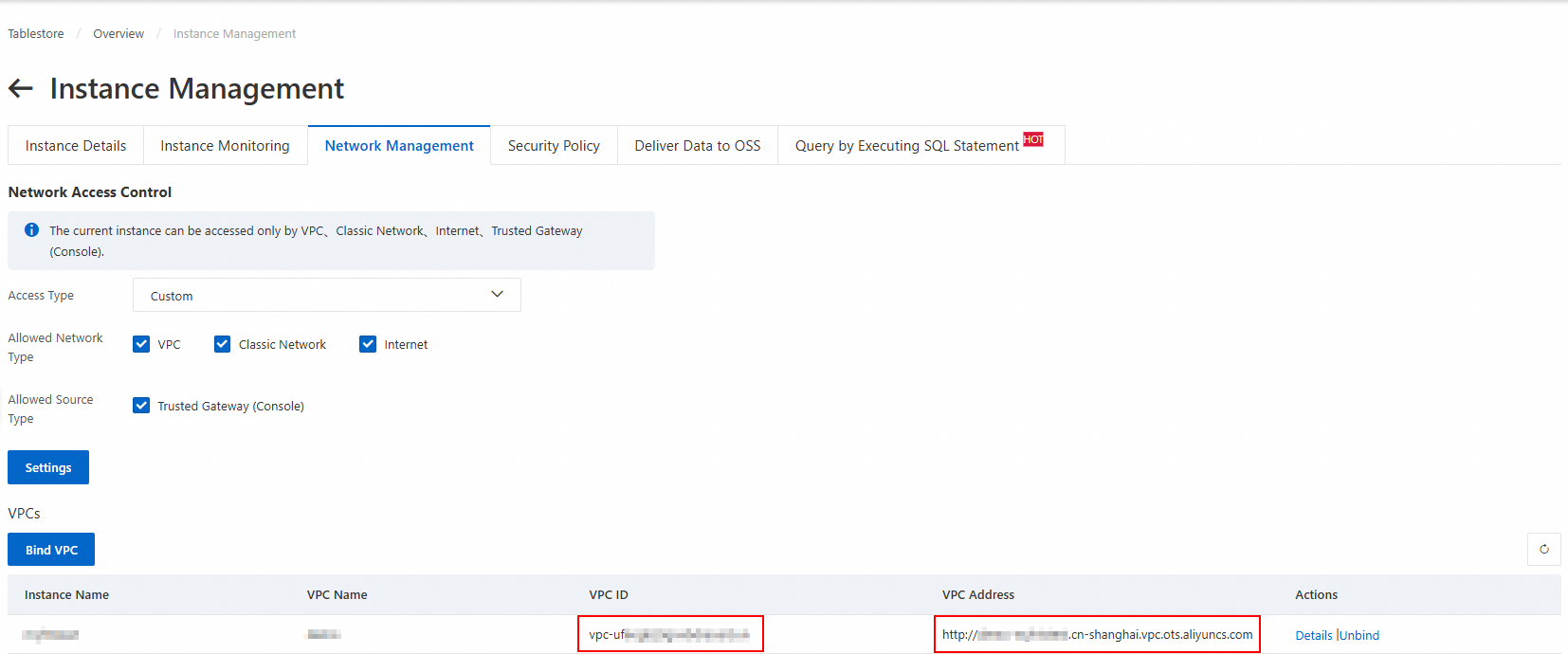
Obtain the VPC information for the DataWorks workspace resource group.
Log on to the DataWorks console. In the top navigation bar, select the region where your workspace is located. In the navigation pane on the left, click Workspace to go to the Workspaces page.
Click the workspace name to go to the Workspace Details page. In the left navigation pane, click Resource Group to view the resource groups attached to the workspace.
To the right of the target resource group, click Network Settings. In the Data Scheduling & Data Integration section, view the VPC ID of the attached virtual private cloud.
Create a VPC peering connection and configure routes.
Log on to the VPC console. In the navigation pane on the left, click VPC Peering Connection and then click Create VPC Peering Connection.
On the Create VPC Peering Connection page, enter a name for the peering connection and select the requester VPC instance, accepter account type, accepter region, and accepter VPC instance. Then, click OK.
On the VPC Peering Connection page, find the VPC peering connection and click Configure route in the Requester VPC and Accepter columns.
For the destination CIDR block, enter the CIDR block of the peer VPC. For example, when you configure a route entry for the requester VPC, enter the CIDR block of the accepter VPC. When you configure a route entry for the accepter VPC, enter the CIDR block of the requester VPC.
Step 2: Add a Tablestore data source
Add a Tablestore data source for both the source table instance and the target table instance.
Log on to the DataWorks console. Switch to the destination region. In the navigation pane on the left, choose . From the drop-down list, select the workspace and click Go to Data Integration.
In the navigation pane on the left, click Data source.
On the Data Sources page, click Add Data Source.
In the Add Data Source dialog box, search for and select Tablestore as the data source type.
In the Add OTS Data Source dialog box, configure the data source parameters as described in the following table.
Parameter
Description
Data Source Name
The data source name must be a combination of letters, digits, and underscores (_). It cannot start with a digit or an underscore (_).
Data Source Description
A brief description of the data source. The description cannot exceed 80 characters in length.
Region
Select the region where the Tablestore instance resides.
Tablestore Instance Name
The name of the Tablestore instance.
Endpoint
The endpoint of the Tablestore instance. Use the VPC address.
AccessKey ID
The AccessKey ID and AccessKey secret of the Alibaba Cloud account or RAM user.
AccessKey Secret
Test the resource group connectivity.
When you create a data source, you must test the connectivity of the resource group to ensure that the resource group for the sync task can connect to the data source. Otherwise, the data sync task cannot run.
In the Connection Configuration section, click Test Network Connectivity in the Connection Status column for the resource group.
After the connectivity test passes, click Complete. The new data source appears in the data source list.
If the connectivity test fails, use the Network Connectivity Diagnostic Tool to troubleshoot the issue.
Step 3: Configure and run the sync task
Create a task node
Go to the Data Development page.
Log on to the DataWorks console.
In the top navigation bar, select the resource group and region.
In the navigation pane on the left, choose .
Select the workspace and click Go To Data Studio.
On the Data Studio console, click the
 icon to the right of Workspace Directories, and then select .
icon to the right of Workspace Directories, and then select .In the Create Node dialog box, select a Path, set both data source and data destination to Tablestore, enter a name, and click OK.
Configure the sync task
In the Workspace Directories, click the newly created batch sync task node. You can configure the sync task in the codeless UI or the code editor.
Codeless UI (default)
Configure the following items:
Data Source: Select the source and destination data sources.
Runtime Resource: Select a resource group. The connectivity of the data source is automatically tested.
Data Source:
Table: From the drop-down list, select the source data table.
Primary Key Range (Start): The starting primary key for data read operations. The format is a JSON array.
inf_minindicates negative infinity.If the primary key consists of an
intprimary key column namedidand astringprimary key column namedname, the following configuration is an example:Specific primary key range
Full data
[ { "type": "int", "value": "000" }, { "type": "string", "value": "aaa" } ][ { "type": "inf_min" }, { "type": "inf_min" } ]Primary Key Range (End): The ending primary key for data read operations. The format is a JSON array.
inf_maxindicates positive infinity.If the primary key consists of an
intprimary key column namedidand astringprimary key column namedname, the following configuration is an example:Specific primary key range
Full data
[ { "type": "int", "value": "999" }, { "type": "string", "value": "zzz" } ][ { "type": "inf_max" }, { "type": "inf_max" } ]Splitting Configuration: The custom shard configuration. The format is a JSON array. Usually, you do not need to configure this parameter. Set it to
[].If hot spots occur in Tablestore data storage and the automatic sharding policy of Tablestore Reader is ineffective, use custom sharding rules. Sharding specifies the shard points within the start and end primary key range. You only need to configure the shard keys, not all primary keys.
Destination:
Table: From the drop-down list, select the destination data table.
Primary Key Information: The primary key information of the destination data table. The format is a JSON array.
If the primary key consists of an
intprimary key column namedidand astringprimary key column namedname, the following configuration is an example:[ { "name": "id", "type": "int" }, { "name": "name", "type": "string" } ]Write Mode: The mode for writing data to Tablestore. The following modes are supported:
PutRow: Writes row data. If the target row does not exist, a new row is added. If the target row exists, the original row is overwritten.
UpdateRow: Updates row data. If the row does not exist, a new row is added. If the row exists, the values of specified columns in the row are added, modified, or deleted based on the request.
Destination Field Mapping: Configure the field mapping from the source data table to the destination data table. Each line represents a field in JSON format.
Source Field: This must include the primary key information of the source data table.
If the primary key consists of an
intprimary key column namedidand astringprimary key column namedname, and the attribute columns include anintfield namedage, the following configuration is an example:{"name":"id","type":"int"} {"name":"name","type":"string"} {"name":"age","type":"int"}Target Field: This does not need to include the primary key information of the destination data table.
If the primary key consists of an
intprimary key column namedidand astringprimary key column namedname, and the attribute columns include anintfield namedage, the following configuration is an example:{"name":"age","type":"int"}
After you complete the configuration, click Save at the top of the page.
Code editor
Click Code Editor at the top of the page. Edit the script on the page that appears.
The following example shows the configuration for a table where the primary key consists of anintprimary key column namedidand astringprimary key column namedname, and the attribute columns include anintfield namedage. When you configure the task, replace thedatasourceandtablenames in the example script with your actual values.
Full data
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "ots",
"parameter": {
"datasource": "source_data",
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
],
"range": {
"begin": [
{
"type": "inf_min"
},
{
"type": "inf_min"
}
],
"end": [
{
"type": "inf_max"
},
{
"type": "inf_max"
}
],
"split": []
},
"table": "source_table",
"newVersion": "true"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "ots",
"parameter": {
"datasource": "target_data",
"column": [
{
"name": "age",
"type": "int"
}
],
"writeMode": "UpdateRow",
"table": "target_table",
"newVersion": "true",
"primaryKey": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
]
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 2,
"throttle": false
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Specific primary key range
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "ots",
"parameter": {
"datasource": "source_data",
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
],
"range": {
"begin": [
{
"type": "int",
"value": "000"
},
{
"type": "string",
"value": "aaa"
}
],
"end": [
{
"type": "int",
"value": "999"
},
{
"type": "string",
"value": "zzz"
}
],
"split": []
},
"table": "source_table",
"newVersion": "true"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "ots",
"parameter": {
"datasource": "target_data",
"column": [
{
"name": "age",
"type": "int"
}
],
"writeMode": "UpdateRow",
"table": "target_table",
"newVersion": "true",
"primaryKey": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
]
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 2,
"throttle": false
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}After you finish editing the script, click Save at the top of the page.
Run the sync task
Click Run at the top of the page to start the sync task. The first time you run the task, you must confirm the debug configuration.
Step 4: View the synchronization result
After the sync task runs, view the execution status in the logs and check the synchronization result in the Tablestore console.
View the task running status and result at the bottom of the page. The following log information indicates that the sync task ran successfully.
2025-11-18 11:16:23 INFO Shell run successfully! 2025-11-18 11:16:23 INFO Current task status: FINISH 2025-11-18 11:16:23 INFO Cost time is: 77.208sView the data in the target table.
Go to the Tablestore console. In the top navigation bar, select the resource group and region.
Click the instance alias. In the table list, click the target data table.
Click Query Data to view the data in the target data table.
Synchronize data using the command line interface
This method requires you to manually export data from the source table to a local JSON file and then import the file into the target table. This method is suitable only for migrating small amounts of data and is not recommended for large-scale data migration.
Step 1: Preparations
Create a target data table. Ensure that its primary key structure, including the name, data type, and order of the columns, is identical to that of the source table.
Step 2: Export source table data
Start the command line interface and run the `config` command to configure the access information for the instance where the source table is located. For more information, see Start and configure access information.
Before you run the command, replace `endpoint`, `instance`, `id`, and `key` with the endpoint, instance name, AccessKey ID, and AccessKey secret of the instance where the source table is located.
config --endpoint https://myinstance.cn-hangzhou.ots.aliyuncs.com --instance myinstance --id NTSVL******************** --key 7NR2****************************************Export the data.
Run the
usecommand to select the source table. The following example usessource_table.use --wc -t source_tableExport the data from the source table to a local JSON file. For more information, see Export data.
scan -o /tmp/sourceData.json
Step 3: Import data to the target table
Run the `config` command to configure the access information for the instance where the target table is located.
Before you run the command, replace `endpoint`, `instance`, `id`, and `key` with the endpoint, instance name, AccessKey ID, and AccessKey secret of the instance where the target table is located.
config --endpoint https://myinstance.cn-hangzhou.ots.aliyuncs.com --instance myinstance --id NTSVL******************** --key 7NR2****************************************Import the data.
Run the
usecommand to select the target table. The following example usestarget_table.use --wc -t target_tableImport the data from the local JSON file into the target table. For more information, see Import data.
import -i /tmp/sourceData.json