SPL syntax
SLS Processing Language (SPL) processes raw log data through multi-level pipelines to extract structured information, manipulate fields, and filter results.
SPL overview
SPL extracts structured information, manipulates fields, and filters raw data. SLS chains multiple pipeline levels: the first applies index filter conditions, and subsequent levels run SPL instructions to produce the final output. SQL users can compare approaches in Comparison of use cases for SPL and SQL.
How it works
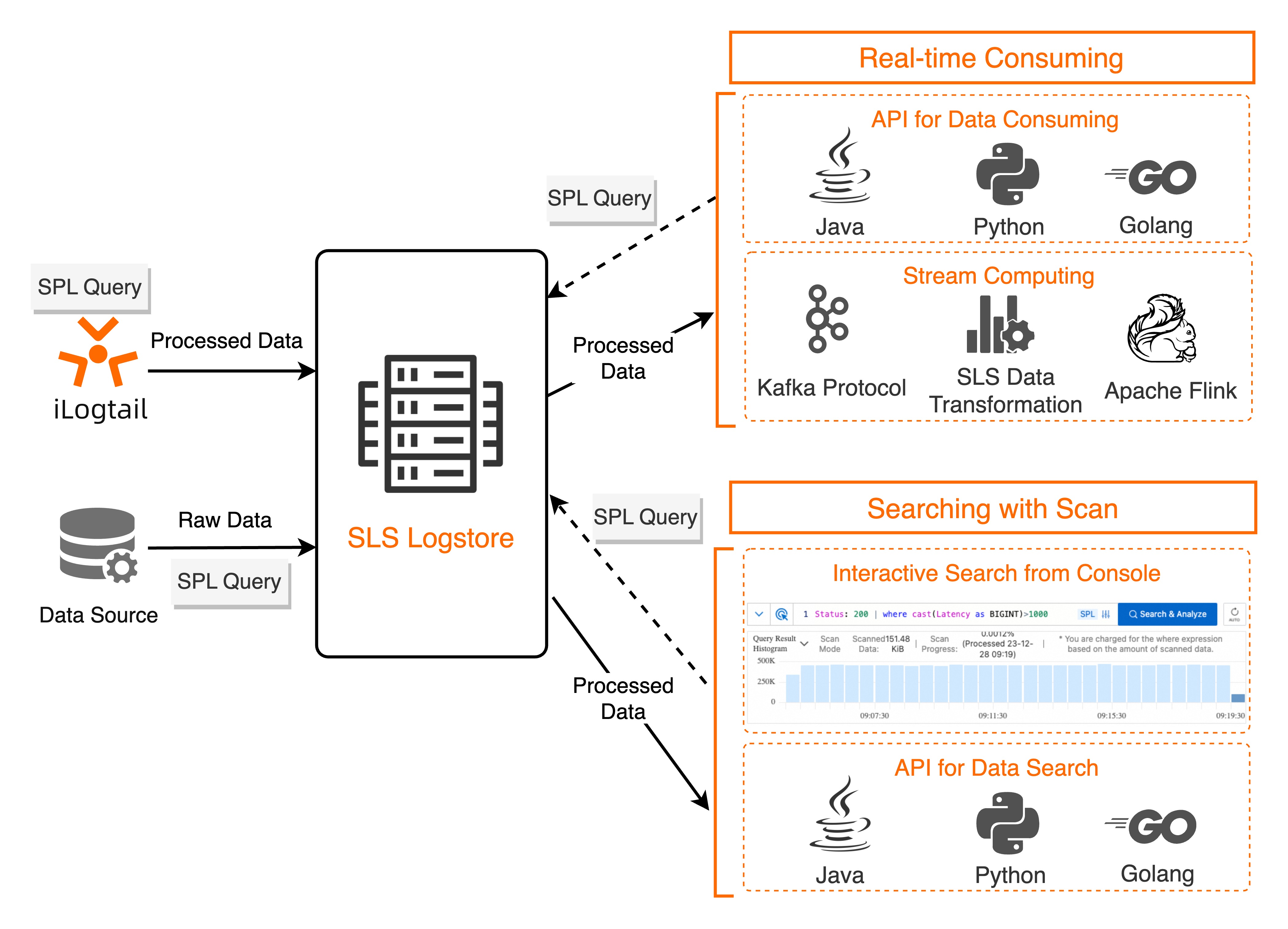
SPL integrates with Logtail data collection, ingest processor, rule-based data consumption, data transformation (new version), and Scan-based query.
For more information about the SPL functions in each use case, see General reference.
Limitations
|
Category |
Limit |
Logtail data collection |
Write Processor |
Real-time consumption |
Data Transformation (New) |
Scan query |
|
SPL complexity |
Number of script pipeline levels |
16 |
16 |
16 |
16 |
16 |
|
Script length |
64 KB |
64 KB |
10 KB |
10 KB |
64 KB |
|
|
SPL runtime |
Runtime memory size Important
Resolve issues using Fault handling. |
50 MB |
1 GB |
1 GB |
1 GB |
2 GB |
|
Runtime timeout Important
Resolve issues using Fault handling. |
1 second |
5 seconds |
5 seconds |
5 seconds |
2 seconds |