Identifying memory-intensive keys before they cause problems is difficult when a Redis instance is under load. Offline key analysis scans backup files of your Tair (Redis OSS-compatible) instance to surface large keys and show memory usage, key distribution, and expiration times — without impacting instance performance. Use the results to optimize your instance and prevent memory exhaustion or performance degradation caused by key skew.
This feature is built on the cache analysis feature of CloudDBA.
Limitations
Disk-based instances are not supported.
If you change the instance type, backup files created before the change cannot be analyzed.
Only Redis Open-Source Edition data structures and the following Tair-proprietary structures are supported: TairString, TairHash, TairGIS, TairBloom, TairDoc, TairCpc, and TairZset. The analysis task fails if the backup file contains other Tair-proprietary structures.
Choose an analysis method
Three analysis methods are available. Choose based on how current the data needs to be.
| Method | Data freshness | Use when |
|---|---|---|
| Use Recent Backup File | Last scheduled backup | Daily or routine inspection |
| Select a historical backup file | A specific past point in time | Comparing against a known state |
| Create New Backup for Analysis | Current instance state | Investigating an active issue |
If you analyze an existing backup file, confirm that its creation time matches the point in time you want to inspect.
Run an offline key analysis
Prerequisites
Before you begin, ensure that you have:
A Tair (Redis OSS-compatible) instance (non-disk-based)
The required permissions. If you are using a Resource Access Management (RAM) user, see
Start an analysis task
Log on to the console and go to the Instances page. Select the region where your instance resides, then click the instance ID.
In the left navigation pane, choose CloudDBA > Offline Key analysis. By default, the page shows analysis results from the previous day. Adjust the time range as needed.
Click Analyze.
In the dialog box, configure the following parameters.
Parameter Description Node The node to analyze. Select the entire instance or a specific node. Analysis method The backup file to use. See Choose an analysis method for guidance. Delimiter Characters used to identify key prefixes. The default delimiters are `:;,_-+@=|#`. Leave blank to use the defaults. 
Click OK. The system submits the analysis task and shows its status. Click Refresh to update the status.
View results
When the task status shows complete, click Details in the Actions column.
The details page contains the following sections:
Basic information — Instance attributes and the analysis method used.

Relevant Nodes — Memory usage and key statistics for each node.
This section appears only for cluster or read/write splitting instances when the entire instance was selected as the Node.

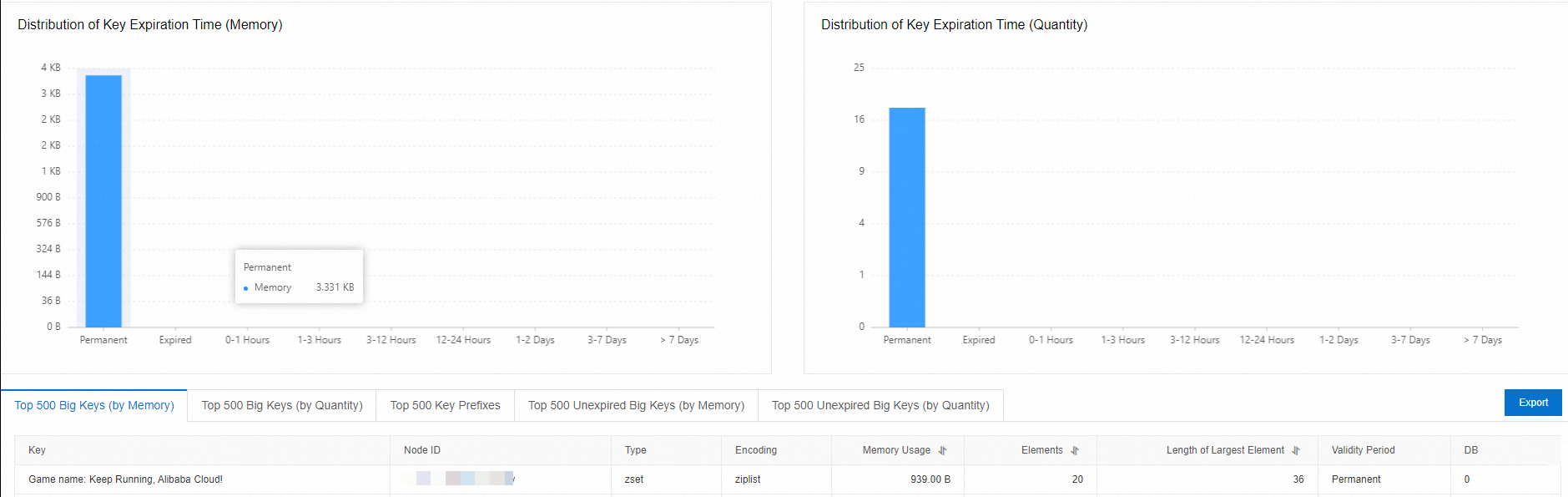
Details — A breakdown that includes:
Memory usage and distribution by key type
Element count and size distribution within keys
Key expiration time distribution
Top large keys ranked by memory
FAQ
Why are there so many expired keys?
Keys with a time-to-live (TTL) configured can accumulate when many expire at the same time. The instance clears them automatically, but to free memory immediately, use the Clear Data feature. See Clear expired keys.
What do I do if a "permission denied" error is reported when I use a RAM user?
Grant the required permissions to the RAM user and retry the operation. For more information, see Common scenarios and examples of custom policies.
Why does analysis speed vary between tasks on the same instance?
Analysis tasks run asynchronously in CloudDBA. If other tasks are queued ahead of yours, your task waits longer. Total time depends on queue depth, not just your instance size.
How do I fix decode rdbfile error: rdb: unknown object type 116 for key?
The backup contains non-standard Bloom structures, which are not supported for analysis.
How do I fix decode rdbfile error: rdb: invalid file format?
Two common causes:
The instance configuration changed after the backup was created. Select a backup that matches the current configuration.
Transparent Data Encryption (TDE) is enabled. This feature cannot analyze encrypted backup files.
How do I fix decode rdbfile error: rdb: unknown module type?
The backup contains Tair-proprietary data structures that are not in the supported list (TairString, TairHash, TairGIS, TairBloom, TairDoc, TairCpc, TairZset). Analysis cannot proceed for backups that include unsupported structures.
How do I fix the XXX backup failed error when creating a new backup for analysis?
A BGSAVE or BGREWRITEAOF command is running on the instance, which blocks the new backup. Run the analysis during off-peak hours, or switch to Use Recent Backup File or Select a historical backup file instead.
Why does the memory usage on the Details page appear smaller than actual usage?
The analysis calculates memory based on serialized key and value data in the Redis Database (RDB) backup file. This covers only part of the actual memory footprint. The remainder includes:
Struct data, pointers, and byte alignment overhead. For instances with 250 million keys, this can add approximately 2–3 GB (allocated via jemalloc).
Client-side buffers: output buffer, query buffer, and append-only file (AOF) rewrite buffer.
Replication backlogs from primary/replica replication.
Why is memory usage for Stream keys several times higher than expected?
Stream is a complex data structure that uses radix trees and listpacks internally. The analysis cannot accurately measure memory for these nested structures, so results are approximate. This discrepancy is statistical and does not affect instance functionality.
Why are the element count and element length the same for String keys?
For Tair (Redis OSS-compatible) instances, the number of elements for a String key is defined as the length of the value. This is by design.
API reference
| API | Description |
|---|---|
| CreateCacheAnalysisJob | Creates a cache analysis task |
| DescribeCacheAnalysisJob | Queries the details of a cache analysis task |
| DescribeCacheAnalysisJobs | Lists cache analysis tasks |
What's next
Top key statistics — Monitor large keys in real time without a backup file