As monitoring workloads scale, a single collector often cannot sustain high-frequency writes, and query latency increases under concurrent load. TairTS, a time series module built into Tair (Enterprise Edition), addresses both problems with millisecond-latency queries and concurrent-safe write accumulation. This topic shows how to use TairTS to build a fine-grained monitoring system.
Key concepts
TairTS organizes time series data using two identifiers:
| Identifier | Role | Example |
|---|---|---|
| pkey (primary key) | Groups related time series | cpu_load (a metric name) |
| skey (secondary key) | Identifies a specific series within the group | app1 (an application instance) |
Other core capabilities:
| Capability | Description |
|---|---|
| Gorilla compression | Reduces storage costs by applying the Gorilla algorithm with a storage layout optimized for time series data |
| TTL per skey | Each skey has its own time-to-live (TTL), allowing data to roll automatically based on time windows |
| Single-command aggregation | Run batch queries with downsampling, attribute-based filtering, batch query, and multi-level filtering in one command to reduce network interaction |
Architecture
Figure 1. Fine-grained monitoring architecture 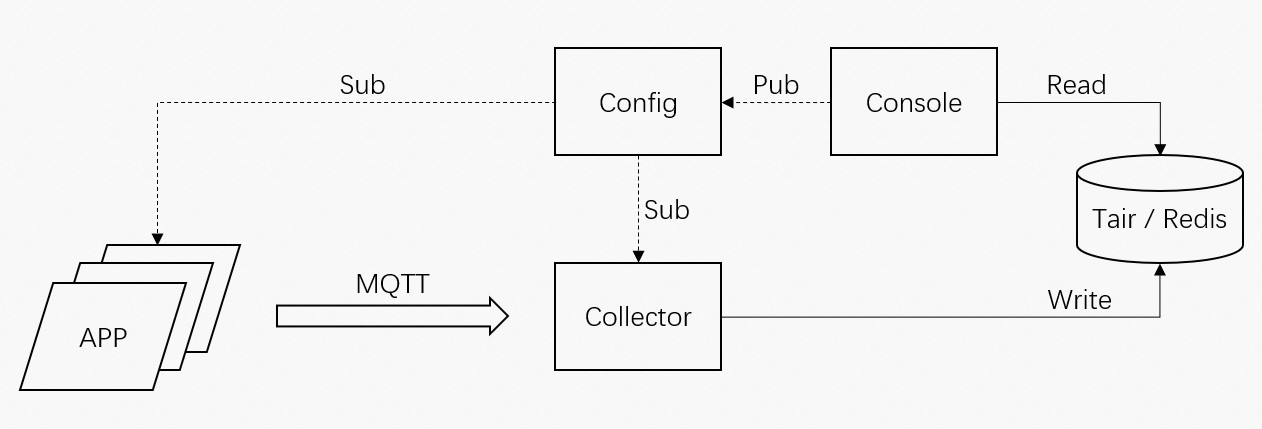
The monitoring system works as follows:
The console sends fine-grained monitoring configurations to the application.
The application pushes configurations to collectors using MQ Telemetry Transport (MQTT).
Collectors process the incoming data and write it to Tair databases using TairTS commands.
Handle high-concurrency queries
TairTS supports aggregate operations — downsampling, attribute-based filtering, batch query, and multi-level filtering using numerical functions — all within a single query. This reduces network interaction and returns results in milliseconds, so issues are detected immediately.
Handle high-concurrency writes
As applications scale, a single collector may not keep up with incoming write volume. TairTS solves this with extsrawincr, which accumulates values across concurrent writes rather than overwriting them. Multiple collectors writing to the same skey at the same timestamp produce a correct cumulative result, reducing memory usage with no data loss.
The following example demonstrates concurrent writes from two collectors to the same pkey (cpu_load) and skey (app1):
import com.aliyun.tair.tairts.TairTs;
import com.aliyun.tair.tairts.params.ExtsAggregationParams;
import com.aliyun.tair.tairts.params.ExtsAttributesParams;
import com.aliyun.tair.tairts.results.ExtsSkeyResult;
import redis.clients.jedis.Jedis;
public class test {
protected static final String HOST = "127.0.0.1";
protected static final int PORT = 6379;
public static void main(String[] args) {
try {
Jedis jedis = new Jedis(HOST, PORT, 2000 * 100);
if (!"PONG".equals(jedis.ping())) {
System.exit(-1);
}
TairTs tairTs = new TairTs(jedis);
// Use the following code if you want to work with a cluster instance:
//TairTsCluster tairTsCluster = new TairTsCluster(jedisCluster);
String pkey = "cpu_load";
String skey1 = "app1";
long startTs = (System.currentTimeMillis() - 100000) / 1000 * 1000;
long endTs = System.currentTimeMillis() / 1000 * 1000;
String startTsStr = String.valueOf(startTs);
String endTsStr = String.valueOf(endTs);
tairTs.extsdel(pkey, skey1);
long num = 5;
// Concurrently update data in Collector A.
for (int i = 0; i < num; i++) {
double val = i;
long ts = startTs + i*1000;
String tsStr = String.valueOf(ts);
ExtsAttributesParams params = new ExtsAttributesParams();
params.dataEt(1000000000);
String addRet = tairTs.extsrawincr(pkey, skey1, tsStr, val, params);
}
ExtsAggregationParams paramsAgg = new ExtsAggregationParams();
paramsAgg.maxCountSize(10);
paramsAgg.aggAvg(1000);
System.out.println("Updated result of Collector A:");
ExtsSkeyResult rangeByteRet = tairTs.extsrange(pkey, skey1, startTsStr, endTsStr, paramsAgg);
for (int i = 0; i < num; i++) {
System.out.println(" ts: " + rangeByteRet.getDataPoints().get(i).getTs() + ", value: " + rangeByteRet.getDataPoints().get(i).getDoubleValue());
}
// Concurrently update data in Collector B.
for (int i = 0; i < num; i++) {
double val = i;
long ts = startTs + i*1000;
String tsStr = String.valueOf(ts);
ExtsAttributesParams params = new ExtsAttributesParams();
params.dataEt(1000000000);
String addRet = tairTs.extsrawincr(pkey, skey1, tsStr, val, params);
}
System.out.println("Updated result of Collector B:");
rangeByteRet = tairTs.extsrange(pkey, skey1, startTsStr, endTsStr, paramsAgg);
for (int i = 0; i < num; i++) {
System.out.println(" ts: " + rangeByteRet.getDataPoints().get(i).getTs() + ", value: " + rangeByteRet.getDataPoints().get(i).getDoubleValue());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}Both collectors call extsrawincr with the same timestamps and values. After Collector A writes 5 data points, the query returns:
Updated result of Collector A:
ts: 1597049266000, value: 0.0
ts: 1597049267000, value: 1.0
ts: 1597049268000, value: 2.0
ts: 1597049269000, value: 3.0
ts: 1597049270000, value: 4.0After Collector B writes the same values, extsrawincr accumulates the new values on top of the existing ones:
Updated result of Collector B:
ts: 1597049266000, value: 0.0
ts: 1597049267000, value: 2.0
ts: 1597049268000, value: 4.0
ts: 1597049269000, value: 6.0
ts: 1597049270000, value: 8.0Each value is doubled because both collectors contributed equal amounts. This accumulation behavior is what makes extsrawincr safe for concurrent multi-collector writes.