Tair DRAM-based instances are the high-performance tier of ApsaraDB for Redis. Each data node delivers approximately three times the throughput of a Redis Open-Source Edition instance of equivalent specifications, thanks to a multi-threaded architecture that separates I/O, command execution, and monitoring across dedicated thread types. Use DRAM-based instances when hotkey traffic, concurrent write pressure, or cluster maintenance cost is a bottleneck.
Benefits
| Benefit | Details |
|---|---|
| Compatibility | Fully compatible with Redis 7.0, Redis 6.0, and Redis 5.0. No changes to application code are required. |
| Performance | Multi-threaded architecture delivers approximately 3× the QPS of Redis Open-Source Edition instances of the same specifications. Full and incremental data synchronization runs in I/O threads to accelerate synchronization. |
| Synchronization mode | Supports semi-synchronous replication mode. After the master node executes a client update, it replicates the logs to a replica node and returns a response only after the replica confirms receipt, ensuring no data loss during high-availability switchovers. |
| Deployment architectures | Standard, cluster, and read/write splitting. |
| Extended data structures | Integrates multiple in-house Tair modules: exString (including CAS/CAD commands), exHash, exZset, GIS, Bloom, Doc, TS, Cpc, Roaring, Search, and Vector. |
| Enterprise-grade features | Data flashback, proxy query cache, and Global Distributed Cache. |
| Data security | Supports SSL (Secure Sockets Layer) encryption and TDE (Transparent Data Encryption) for encrypting and decrypting RDB (Redis Database) files. |
When to use DRAM-based instances
Choose a DRAM-based instance if any of the following apply:
Single-node QPS exceeds 100,000: Redis Open-Source Edition nodes top out at 80,000–100,000 QPS. DRAM-based instances handle hot data QPS exceeding 200,000 without performance degradation.
Flash sales or traffic spikes: The multi-threaded model absorbs burst traffic and maintains stable performance, preventing connection issues during peak hours.
Cluster command restrictions: Redis Open-Source Edition cluster instances have limits on database transactions and Lua scripts. DRAM-based cluster instances lift those restrictions.
Read/write splitting with heavy writes: Redis Open-Source Edition read/write splitting handles high read volume but cannot sustain large concurrent write loads. DRAM-based instances in read/write splitting mode support both — one data node and up to five read replicas for millions of QPS.
Cluster cost reduction: If a self-managed Redis cluster keeps growing in node count, switching to DRAM-based cluster instances can reduce cluster size by two thirds and cut O&M costs significantly.
Architecture selection guide
| Architecture | Redis Open-Source Edition | DRAM-based instances |
|---|---|---|
| Standard | Not suitable when single-node QPS exceeds 100,000 | Handles single-node QPS above 100,000 |
| Cluster | Hot data on a node degrades performance for other data on the same node | High-performance hot data access at reduced maintenance costs |
| Read/write splitting | High read throughput; limited concurrent write capacity | High read throughput and high concurrent write capacity |
How it works
Multi-threaded architecture
Redis Open-Source Edition uses a single-threaded model where one thread handles all network I/O and command execution. This is sufficient for moderate loads but becomes a bottleneck at high concurrency.
Tair DRAM-based instances separate work across three thread types:
I/O threads — read requests, parse commands, and send responses
Worker threads — execute commands and timer events
Auxiliary threads — monitor node heartbeats and status for high availability
Each instance supports up to four I/O threads running concurrently. Unlocked queues and pipelines transfer data between I/O and worker threads to maximize multi-threading performance.

*Figure 1. Redis single-threaded model — one thread handles read requests, request parsing, data processing, and responses.*
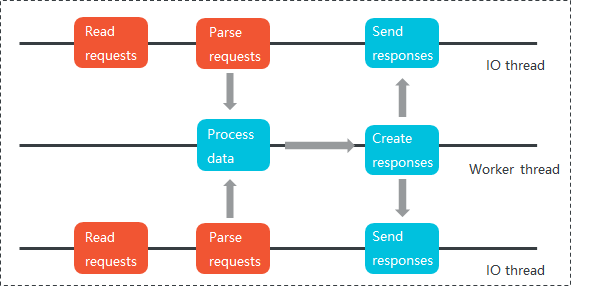
*Figure 2. Tair multi-threaded model — I/O, worker, and auxiliary threads process tasks in parallel.*
What the multi-threaded model accelerates:
| Operation type | Acceleration |
|---|---|
| Common data structures (String, List, Set, Hash, Sorted Set, HyperLogLog, Geo) | Yes — significant improvements |
| Extended data structures (Tair modules) | Yes |
| pub/sub and blocking API operations | Yes — approximately 50% throughput increase, replicated in worker threads |
| Transactions and Lua scripts | No — must execute sequentially |
Unlike Redis 6.0 multi-threading, which improves performance by up to 2× but consumes high CPU resources, the Real Multi-IO architecture of DRAM-based instances thoroughly accelerates both I/O and command execution. This provides stronger resistance to connection impacts and linearly increasing throughput capacity.
Extended data structures
Standard Redis data types — String, List, Hash, Set, Sorted Set, and Stream — cover most common use cases. For more complex scenarios such as geospatial queries, time series analysis, vector search, or probabilistic data structures, modifying application data or writing Lua scripts is typically required with standard Redis.
DRAM-based instances integrate multiple in-house Tair modules that add these capabilities natively.
Module availability by Redis version:
| Module | Redis 7.0 or 6.0 | Redis 5.0 |
|---|---|---|
| exString | Yes | Yes |
| exHash | Yes | Yes |
| exZset | Yes | Yes |
| GIS | Yes | Yes |
| Bloom | Yes | Yes |
| Doc | Yes | Yes |
| TS | Yes | Yes |
| Cpc | Yes | Yes |
| Roaring | Yes | Yes |
| Search | Yes | Yes |
| Vector | Yes | No |
Enterprise-grade features
| Feature | Description |
|---|---|
| Data flashback | Tair retains AOF (append-only file) backup data for up to seven days. Specify any point in time accurate to the second to restore data to a new instance. |
| Proxy query cache | Proxy nodes cache responses for hotkeys within a configurable validity period. Repeated requests are served from the cache without touching backend data shards. |
| Global Distributed Cache | An active geo-redundancy database system that supports multiple sites in different regions serving traffic simultaneously. |
| Two-way data synchronization via DTS | Data Transmission Service (DTS) supports two-way data synchronization between Tair instances for active geo-redundancy and geo-disaster recovery scenarios. For setup instructions, see Configure two-way data synchronization between Tair instances. |
FAQ
My client does not support the commands provided by Tair modules. What should I do?
Define the module commands in your application code before using them, or switch to a client that includes built-in support. For a list of compatible clients, see Clients.