Elastic Algorithm Service (EAS), part of Platform for AI (PAI), offers scenario-based deployment. By configuring only a few parameters, you can deploy a dialogue system that integrates a large language model (LLM) and Retrieval-Augmented Generation (RAG) technology with a single click, significantly reducing deployment time. During inference, this service retrieves relevant information from a knowledge base and combines it with the LLM's responses to produce accurate, information-rich answers, improving the quality and performance of your Q&A system. The service is ideal for question answering, summary generation, and other natural language processing tasks that rely on external knowledge. This topic describes how to build a vector database using ApsaraDB RDS for PostgreSQL, deploy the RAG dialogue service, and validate the model's inference results.
Background
Large language models (LLMs) have limitations in response accuracy and freshness, which make them unsuitable for scenarios that require precise information, such as customer support or Q&A. To address this, the industry widely adopts Retrieval-Augmented Generation (RAG) technology to enhance LLM performance. This technique can significantly improve the quality of Q&A, summary generation, and other natural language processing (NLP) tasks that rely on external knowledge.
RAG enhances the accuracy and richness of generated answers by combining an LLM, such as Qwen, with an information retrieval component. When processing a user query, the RAG system's retrieval component searches a knowledge base for relevant documents or information snippets. This retrieved content, along with the original query, is then fed to the LLM. The model then uses its inductive generation capabilities to produce fact-based, up-to-date responses without being retrained.
The dialogue system service, deployed using EAS, integrates an LLM and RAG technology to overcome the accuracy and freshness limitations of standalone LLMs. It delivers accurate and information-rich responses for various Q&A scenarios, which improves the overall effectiveness and user experience of NLP tasks.
Prerequisites
You have created a Virtual Private Cloud (VPC), a vSwitch, and a security group. For more information, see Create and manage a VPC and Create a security group.
If you deploy a service using a custom fine-tuned model, prepare an Object Storage Service (OSS) bucket or an Apsara File Storage NAS (NAS) file system to store the model files. For more information, see Get started with the console or Create a file system.
Usage notes
This procedure is subject to the maximum token limit of the LLM service and helps you explore the basic retrieval functions of a RAG-based dialogue system:
The server resources of the LLM service and the default token limit determine the maximum conversation length.
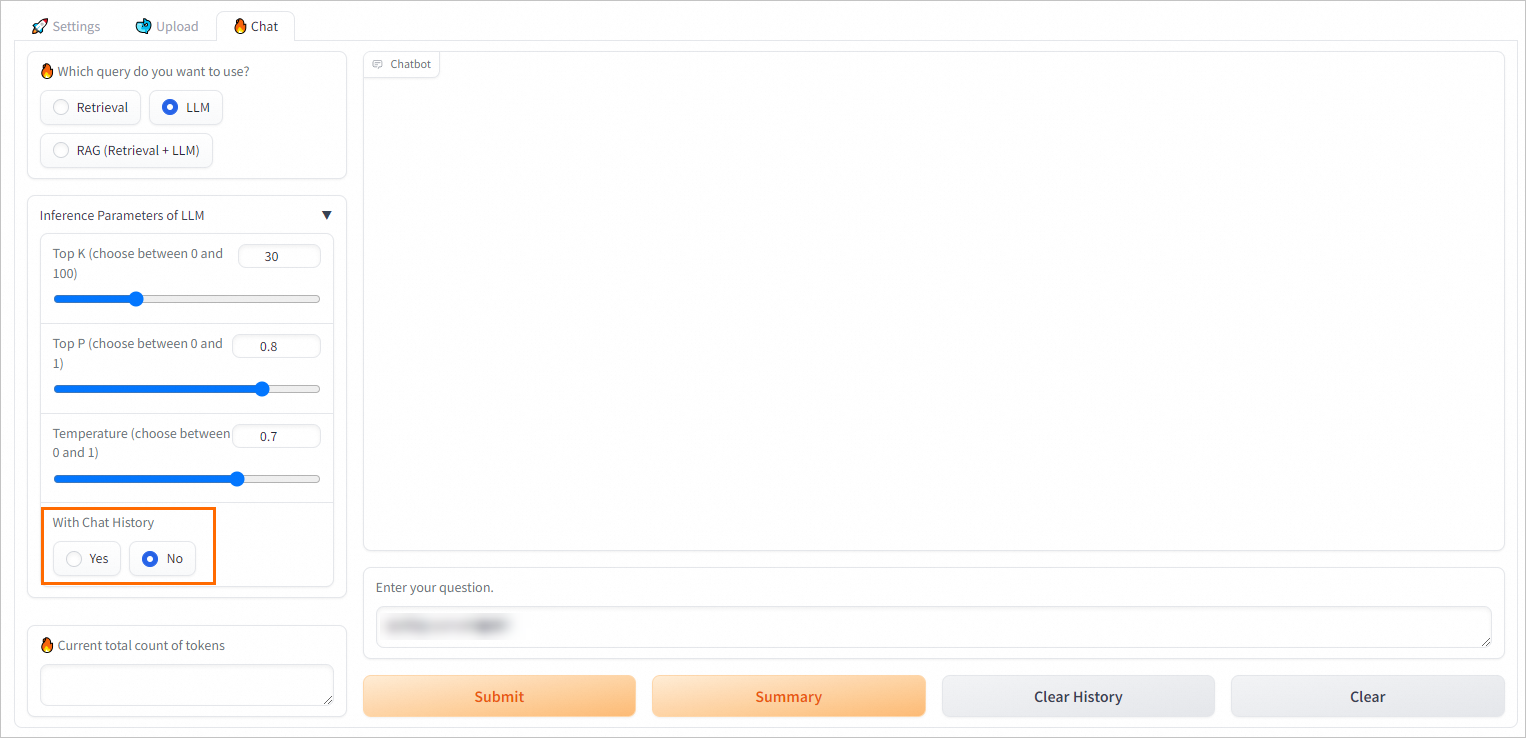
If you do not require multi-turn conversations, we recommend that you disable the
with chat historyfeature in the RAG service. This helps you avoid reaching the token limit. For more information, see How do I disable the "with chat history" feature in the RAG service?.
Step 1: Prepare the ApsaraDB RDS for PostgreSQL vector database
You can build a vector database for RAG with ApsaraDB RDS for PostgreSQL. You will need the configuration parameters to connect to the database.
Quickly create an ApsaraDB RDS for PostgreSQL instance.
We recommend that you deploy the ApsaraDB RDS for PostgreSQL instance and the RAG service in the same region so they can communicate over the VPC internal network.
Create an account and a database for the RDS instance. For more information, see Create an account and a database.
Note:
When you create the account, set Account Type to Privileged Account.
When you create the database, select the created privileged account for Authorized By.
Configure the database connection.
Go to the Instances page. In the top navigation bar, select the region in which the RDS instance resides. Then, find the RDS instance and click the ID of the instance.
In the left-side navigation pane, click Database Connection.
On the Database Connection page, view the database endpoint and port number.
Add pg_jieba to the Running Parameter Value of shared_preload_libraries. For example, change the Running Parameter Value to
'pg_stat_statements,auto_explain,pg_cron'. For more information, see Set instance parameters.NoteApsaraDB RDS for PostgreSQL uses the pg_jieba extension to segment Chinese text for keyword-based retrieval and recall.
Step 2: Deploy the RAG service
Navigate to the model online service page.
Log on to the PAI console.
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the workspace that you want to manage.
If you do not have a workspace, see Create and manage a workspace.
In the left-side navigation pane of the workspace, choose Model Deployment > Elastic Algorithm Service (EAS) to open the Elastic Algorithm Service (EAS) page.
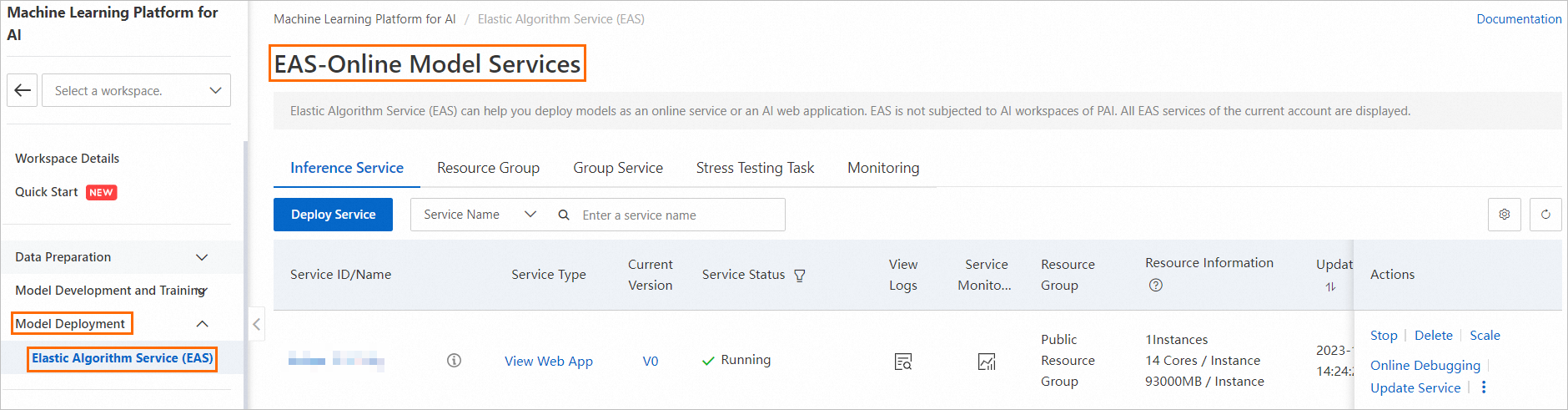
On the Elastic Algorithm Service (EAS) page, click Deploy Service. In the Scenario-based Model Deployment section, click RAG-based Smart Dialogue Deployment.
On the RAG-based LLM Chatbot Deployment page, configure the following key parameters.
Basic information
Parameter
Description
Service Name
A custom service name.
Model Source
Valid values: Open Source Model and Custom Fine-tuned Model.
Model Type
Select a model type based on your scenario.
If you use a custom fine-tuned model, you must configure the parameter size and precision of the model.
Model Configuration
If you use a custom fine-tuned model, you must configure the file path of the fine-tuned model. Two methods are supported:
NoteMake sure that the model file format is compatible with HuggingFace Transformers.
By Object Storage Service (OSS): Select the OSS path where the fine-tuned model files are stored.
By Apsara File Storage NAS: Select the NAS file system and NAS source path where the fine-tuned model files are stored.
Resource configuration
Parameter
Description
Resource Configuration
If you use an open source model, the system automatically recommends and selects a suitable instance type based on the selected model category.
If you use a custom fine-tuned model, select an instance type that matches your model. For more information, see How do I switch to other open source large models?.
Inference Acceleration
Inference acceleration is supported for Qwen, Llama2, ChatGLM, or Baichuan2 series models deployed on A10 or GU30-series instances. Two acceleration types are supported:
BladeLLM Inference Acceleration: BladeLLM provides highly cost-effective LLM inference acceleration, helping you leverage high concurrency and low latency with a single click.
Open-source vLLM Inference Acceleration
Vector database settings
Parameter
Description
Version Type
Select ApsaraDB RDS for PostgreSQL.
Host Address
Set this to the internal or public endpoint of the ApsaraDB RDS for PostgreSQL instance.
Use an internal endpoint: If the RAG application and the database are in the same region, you can use the internal endpoint to connect to the instance.
Use a public endpoint: If the RAG application and the database are in different regions, you must request a public endpoint for the ApsaraDB RDS for PostgreSQL instance. For more information, see Apply for or release a public endpoint.
Port
The default value is 5432. Enter a different value if necessary.
Database
The name of the ApsaraDB RDS for PostgreSQL database.
Table Name
Enter a new table name or an existing one. The structure of an existing table must meet PAI-RAG requirements. For example, you can enter the name of a table that was automatically created when you previously deployed a RAG service using EAS.
Account
The privileged account of the ApsaraDB RDS for PostgreSQL instance.
Password
The password of the privileged account for the ApsaraDB RDS for PostgreSQL instance.
VPC configuration
Parameter
Description
VPC
If you use an internal endpoint for the host address, you must configure the RAG service to use the same VPC as the ApsaraDB RDS for PostgreSQL instance.
If you use a public endpoint for the host address, you must configure a VPC and a vSwitch for the RAG service, and configure a NAT gateway and an elastic IP address (EIP) for the VPC to provide public internet access for the RAG application. For more information, see Use the SNAT feature of a public NAT gateway to access the internet. You must also add the bound EIP to the public IP address whitelist of the ApsaraDB RDS for PostgreSQL instance. For more information, see Configure an IP address whitelist.
vSwitch
Security Group Name
Configure a security group.
ImportantDo not use the security group named created_by_rds. This security group is reserved for internal system use.
Click Deploy.
When the Service Status changes to Running, the service is successfully deployed.
Step 3: Validate inference with the web UI
You can first debug the service on the web UI by following the steps in this section. After you achieve the desired Q&A performance in the web UI, you can use the API provided by PAI to integrate the service into your own business system. For more information, see Step 4: Validate model inference by using the API.
1. Configure the RAG service
After the RAG service is deployed, click Service Type in the View Web App column to open the web UI.
Configure the machine learning model.
Embedding Model Name: Four built-in models are available. The system automatically selects and configures the most suitable model.
Embedding Dimension: After you select an Embedding Model Name, the system configures this parameter automatically. No action is required.
Test the vector database connection.
The system automatically detects and applies the vector database settings that you configured during service deployment, and these settings cannot be modified. Click Connect PostgreSQL to verify the connectivity to ApsaraDB RDS for PostgreSQL.
2. Upload business data files
On the Upload tab, upload your business data files. The supported formats are .txt, .pdf, Excel (.xlsx or .xls), .csv, Word (.docx or .doc), Markdown, and .html.
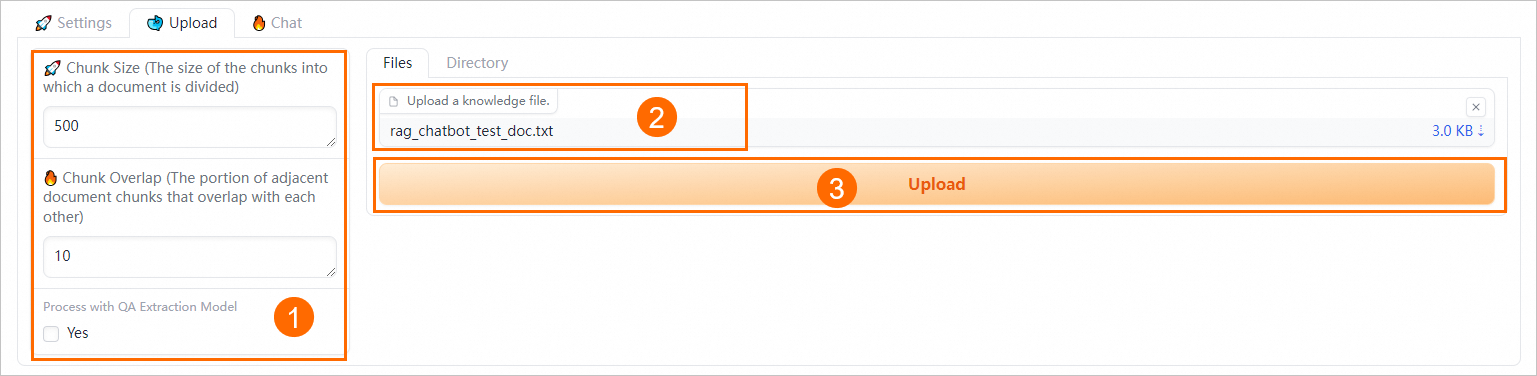
Set semantic chunking parameters.
Use the following parameters to control the document chunking granularity and perform QA information extraction:
Parameter
Description
Chunk size
The size of each chunk in bytes. The default value is 500.
Chunk overlap
The amount of overlap between adjacent chunks. The default value is 10.
Process with QA extraction model
Select the Yes checkbox to enable QA information extraction. The system automatically extracts Q&A pairs from your uploaded business data files to improve retrieval and response quality.
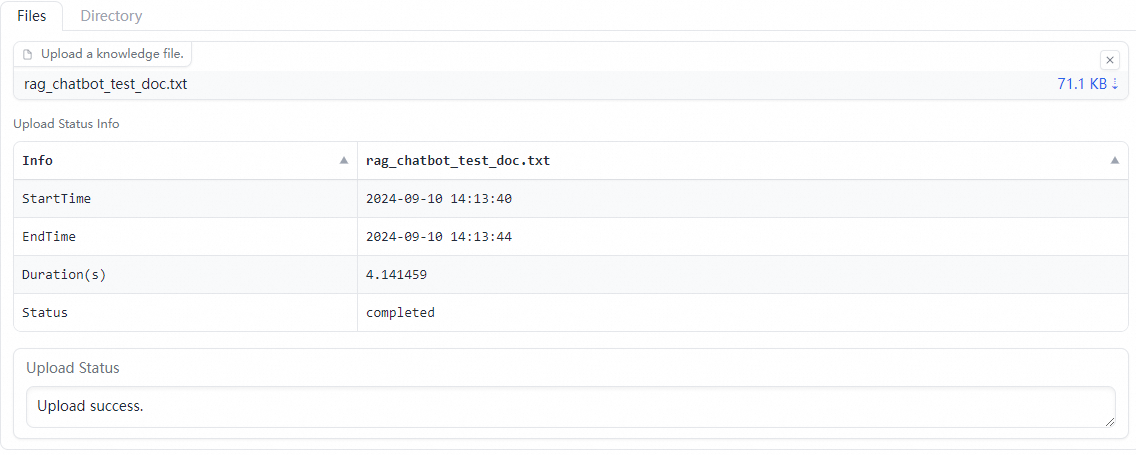
On the Files or Directory tab, upload your business data files (multiple files are supported) or the corresponding directory. For example, upload rag_chatbot_test_doc.txt.
After you select files, the system performs data cleansing (text extraction, hyperlink replacement, and more) and semantic chunking on the selected files before uploading them.
3. Configure model inference parameters
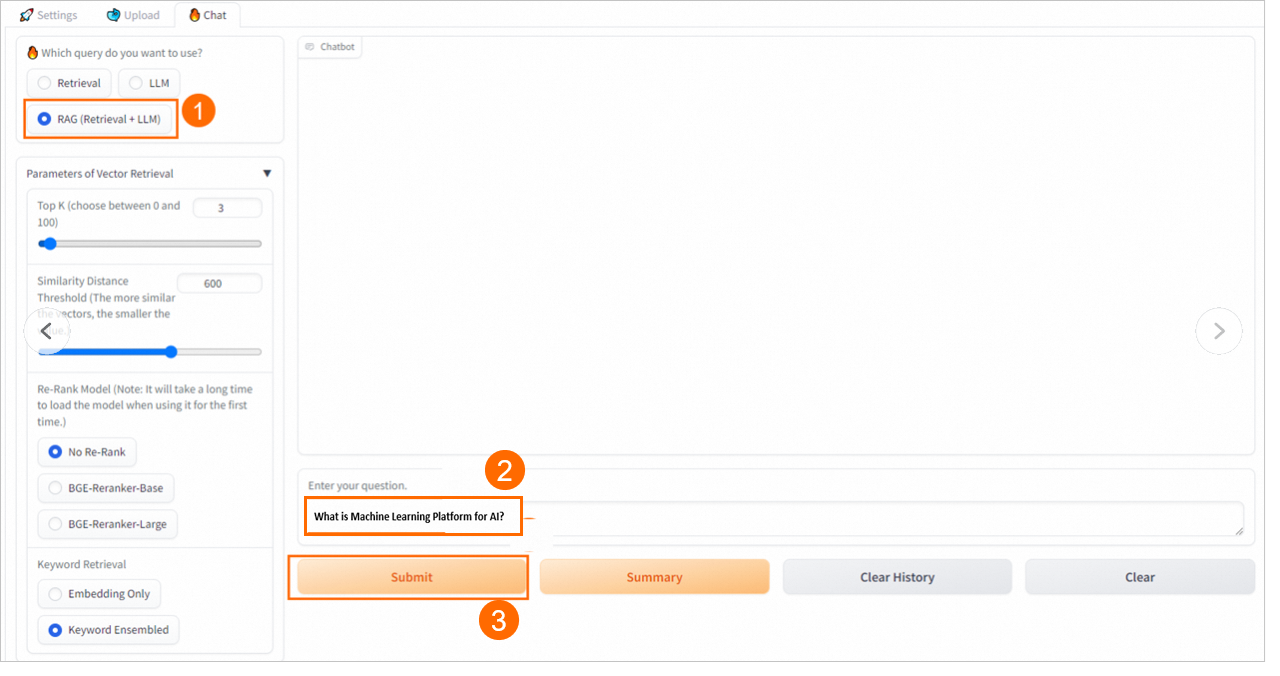
On the Chat tab, configure the Q&A strategy.
Retrieval Q&A
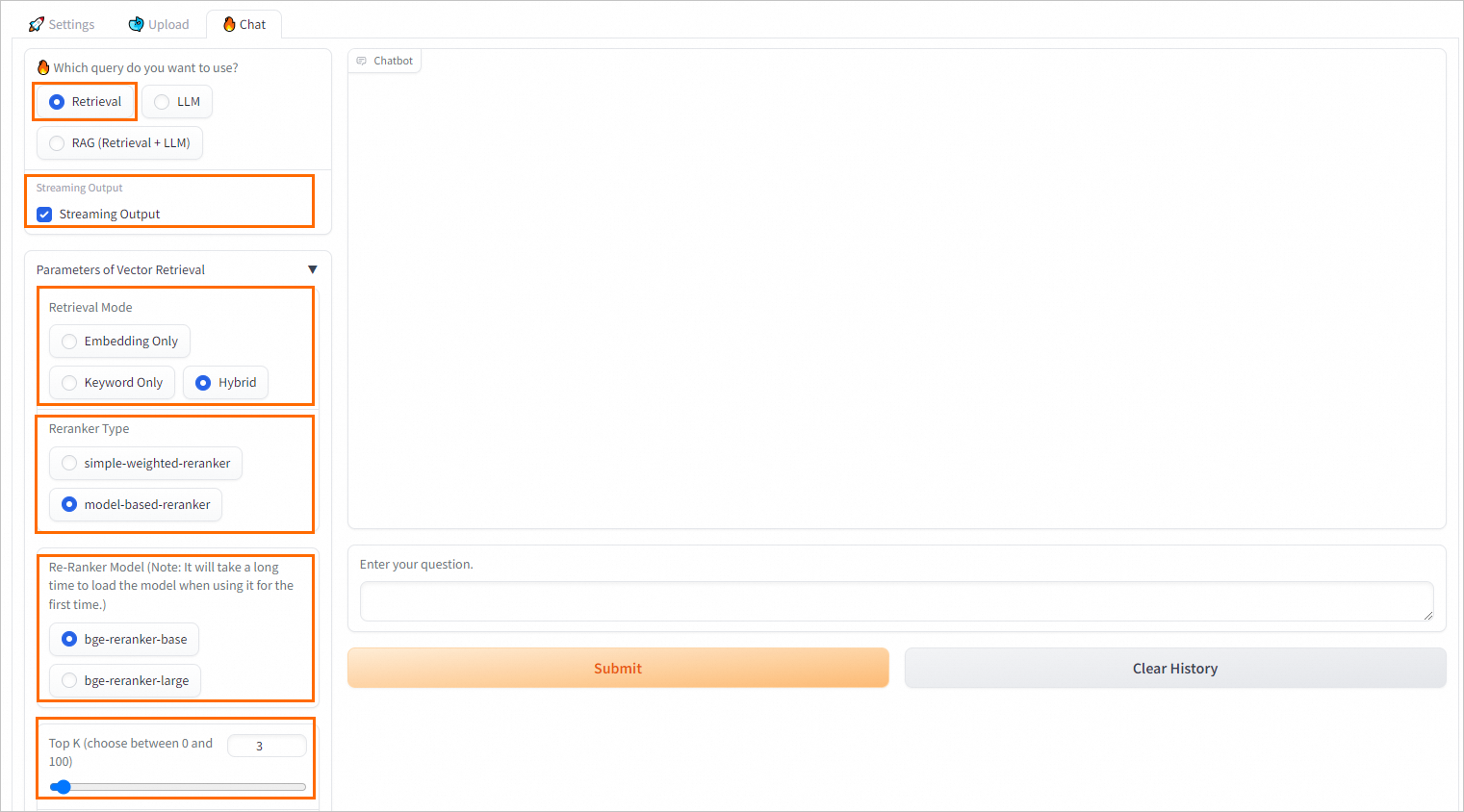
Parameter | Description |
Streaming output | If you select Streaming Output, the system returns results in streaming mode. |
Retrieval model | The following three retrieval methods are supported:
Note In most complex scenarios, vector database retrieval performs well. However, in some vertical domains with sparse corpora or in scenarios that require exact matching, vector retrieval methods might be less effective than traditional sparse retrieval methods. Sparse retrieval methods are simpler and more efficient because they retrieve by calculating the keyword overlap between the user query and the knowledge documents. ApsaraDB RDS for PostgreSQL uses the pg_jieba extension to segment Chinese text for keyword-based recall. For more information about how to use the pg_jieba extension, see Chinese word segmentation (pg_jieba). |
Reranker type | Most vector databases sacrifice some accuracy for computational efficiency, which introduces some randomness into their retrieval results. As a result, the initially returned top K results may not be the most relevant. You can select the simple-weighted-reranker or model-based-reranker model to perform a higher-precision reranking operation on the top K results that are initially recalled by the vector database. This helps you obtain more relevant and accurate knowledge documents. Note When you use a model for the first time, it may take a long time to load. Select a model based on your requirements. |
Top K | The number of similar results to return from the vector database. The system recalls the top K most similar results. |
Similarity score threshold | The similarity threshold. A larger value indicates higher similarity. |
RAG (Retrieval + LLM) Q&A
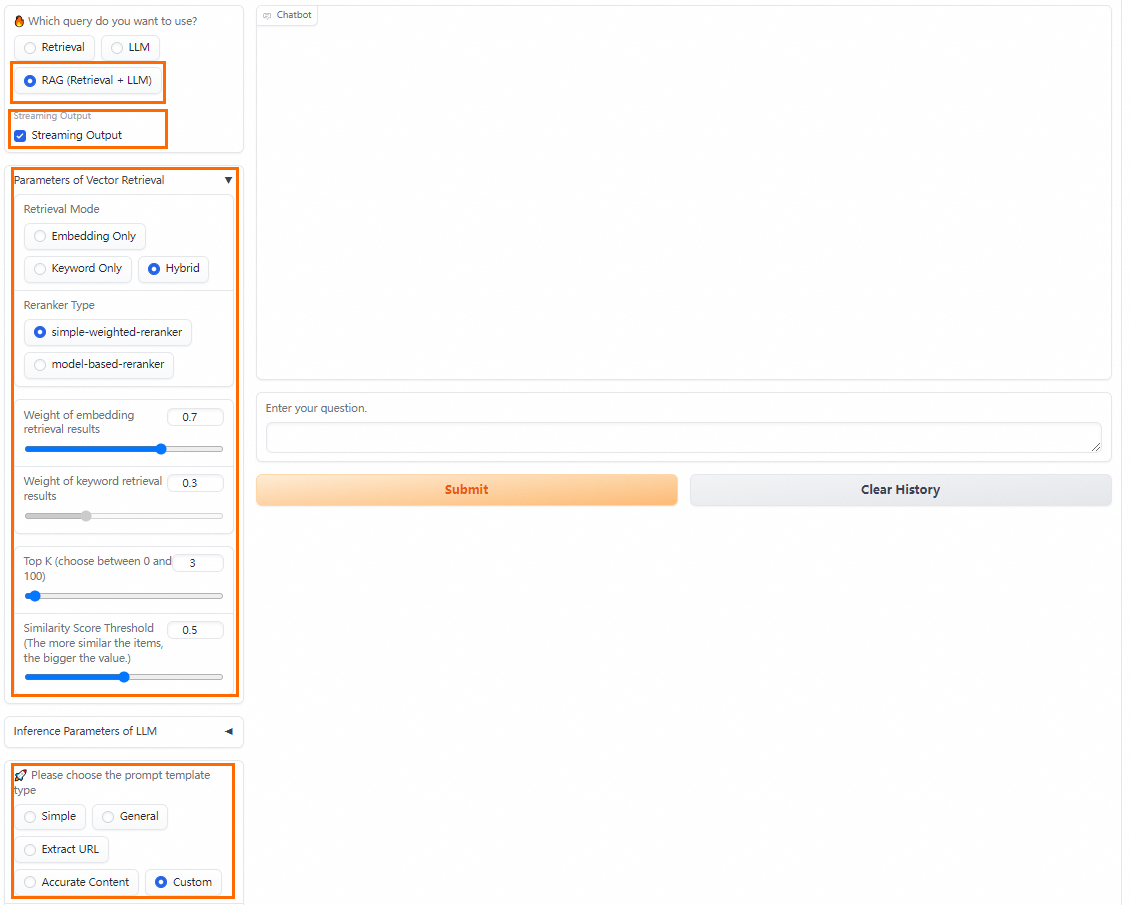
PAI provides multiple prompt strategies. You can select a suitable predefined prompt template or enter a custom prompt template to improve inference results.
The RAG (Retrieval + LLM) Q&A method also supports configuring parameters such as Streaming Output, Retrieval Mode, and Reranker Type. For more information, see Retrieval Q&A.
4. Validate model inference
Retrieval
Directly retrieves and returns the top K most similar results from the vector database.

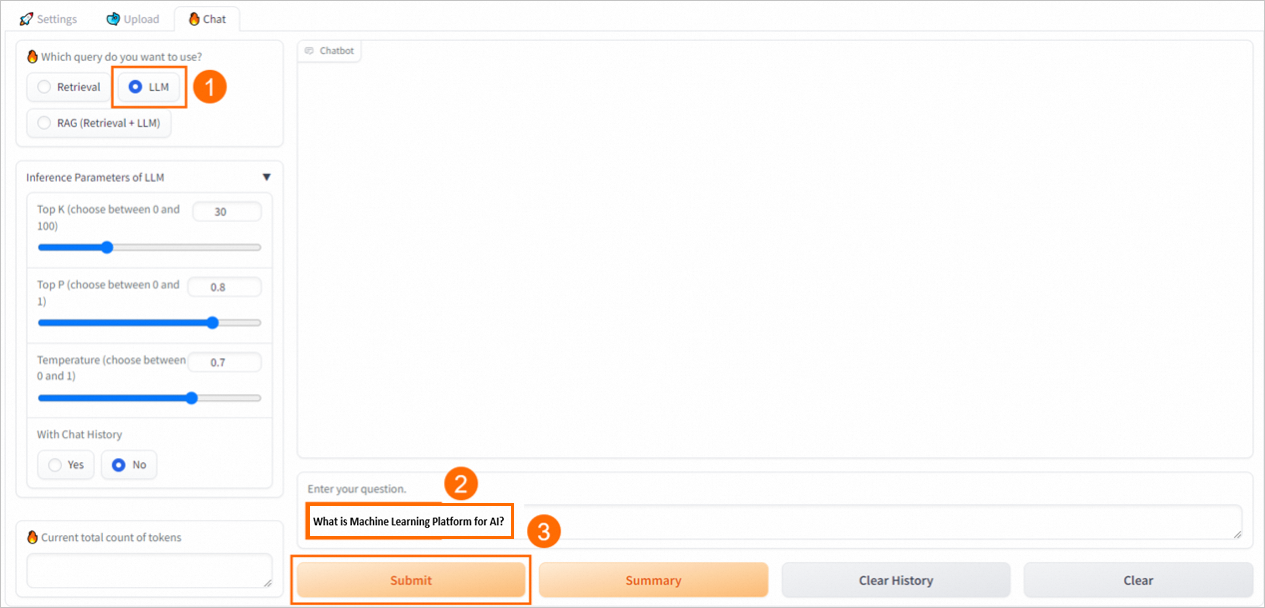
LLM
Directly interacts with the EAS-LLM service and returns the LLM's response.
RAG (Retrieval + LLM)
Inserts the retrieved results and the user's question into the selected prompt template, sends the combined input to the EAS-LLM service, and obtains the Q&A result.
Step 4: Validate inference with the API
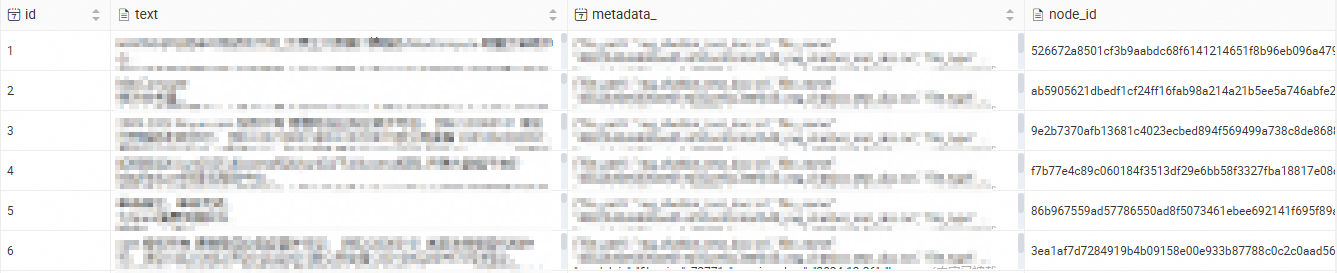
View knowledge base in RDS for PostgreSQL
After you connect to the ApsaraDB RDS for PostgreSQL database that serves as the vector database, you can view the imported knowledge base content. For instructions on how to connect to the database, see Connect to a PostgreSQL instance.
Next steps
You can also use EAS for the following scenario-based deployments:
Deploy an LLM application that supports both a web UI and API calls. After you deploy the application, use the LangChain framework to integrate your enterprise knowledge base to enable intelligent Q&A and automation. For more information, see Use EAS to quickly deploy an LLM application.
Deploy an AI video generation service based on ComfyUI and Stable Video Diffusion models to help you generate short video content for social media platforms and create animations. For more information, see AI video generation - ComfyUI deployment.
FAQ
How to disable chat history in the RAG service?
In the web UI of the RAG service, clear the Chat history checkbox.