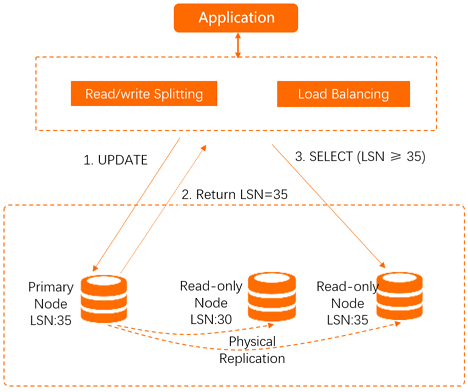
When a single primary node cannot handle the read load, PolarDB for MySQL clusters distribute read requests across multiple nodes automatically. Connect to a cluster endpoint in Read/Write (Automatic Read/Write Splitting) mode, and write requests are routed to the primary node while read requests are distributed across the primary node and read-only nodes based on the number of pending requests on each node. Read/write splitting is free to use.
When to use read/write splitting
Read/write splitting is useful when:
Read-heavy workloads: Your application runs significantly more reads than writes—such as reporting, analytics, or search—and a single node cannot handle the read load.
Scaling without code changes: You want to add read capacity by attaching more read-only nodes without updating connection strings or application logic.
High availability for reads: You need reads to continue even when a read-only node fails, with automatic failover to healthy nodes.
How it works
A built-in database proxy, deployed within existing secure links, manages all routing. When an application connects through the cluster endpoint, the proxy establishes connections to both the primary node and read-only nodes. Within each connection session, the proxy routes each request to the most suitable node based on the data synchronization status of that node—ensuring reads always reflect the latest writes.
Because the proxy is built into the secure link rather than deployed as a separate cloud component, data does not pass through multiple forwarding layers. This keeps latency low compared to external proxy-based read/write splitting.
Request routing rules
The cluster endpoint operates in two modes: Read/Write and Read-Only. The following tables describe how requests are routed in each mode.
Read/Write mode
| Destination | Requests routed there |
|---|---|
| Primary node only | All DML statements: INSERT, UPDATE, DELETE, SELECT FOR UPDATE |
| All DDL statements (create, drop, or alter databases, tables, schemas, or permissions) | |
| All transactions when transaction splitting is disabled | |
| User-defined functions | |
| Stored procedures | |
| LOCK TABLES and UNLOCK TABLES statements | |
| Multi-statement queries | |
| Requests involving temporary tables | |
SELECT last_insert_id() statements | |
| User environment variable queries or modifications | |
BINLOG DUMP statements | |
| Primary node or read-only nodes | Non-transactional read requests (only when Primary Node Accepts Read Requests is set to Yes) |
Read-only transactions using START TRANSACTION READ ONLY (only when Primary Node Accepts Read Requests is set to Yes) | |
| All nodes | System environment variable modifications |
| USE statements | |
| PREPARE and DEALLOCATE PREPARE statements | |
| COM_CHANGE_USER, COM_RESET_CONNECTION, COM_QUIT, and COM_SET_OPTION statements | |
SHOW PROCESSLIST statements (returns processes from all nodes) | |
KILL statements in SQL (not KILL commands in Linux) |
For transaction routing rules when transaction splitting is enabled, see the "Transaction splitting" section in Load balancing.
Read-Only mode
| Behavior | Details |
|---|---|
| DML and DDL | Not supported |
| Read requests | Distributed across read-only nodes in load balancing mode |
| Primary node | Not used, even if added to the selected nodes list |
BINLOG DUMP | Forwarded to a specific read-only node only |
Node health checks
The read/write splitting module automatically runs health checks on all nodes. If a node fails or the latency exceeds the specified threshold, PolarDB stops routing read requests to that node and redirects them to healthy nodes. After the node recovers, PolarDB automatically adds it back to the routing pool.
Related features
Explore the following features to fine-tune how read/write splitting behaves in your cluster: