ChatBI uses natural language to SQL (NL2SQL) technology to generate reports from natural language queries. This topic demonstrates the key features of ChatBI using a fictional restaurant management system, "Ali Xiang", to help you use the service quickly and efficiently.
Enable the PolarDB for AI feature
Add an AI node and set its database account. For more information, see Enable the PolarDB for AI feature.
NoteIf you added an AI node when you purchased the cluster, you can directly set the database account for the AI node. For more information, see Create a standard account.
The account must have read and write permissions to access the target data tables and run the database operations required by ChatBI.
Connect to the PolarDB cluster using the Cluster Endpoint. For more information, see Log on to PolarDB for AI.
NoteWhen you connect to the cluster from the command line, add the
-coption.By default, DMS connects to the cluster using the Primary Endpoint. You must manually change the endpoint to the Cluster Endpoint. Then, close the current SQL window and open a new one to run your SQL statements.
Data preparation
"Ali Xiang" is a fictional restaurant company. Its bill management system contains the three tables shown below, which you can download.
Add comments to your tables and columns based on your table schema. This helps the large language model (LLM) better recognize and understand your data, which improves the model's accuracy and efficiency during data processing and analysis.
CREATE TABLE restaurant_info (
id INT COMMENT 'Outlet ID',
position VARCHAR(128) COMMENT 'Outlet location',
PRIMARY KEY (id)
) COMMENT='Outlet table';
CREATE TABLE menu_info (
id INT COMMENT 'Dish ID',
name VARCHAR(64) COMMENT 'Dish name',
type INT COMMENT 'Dish type',
unit_price INT COMMENT 'Unit price of the dish',
PRIMARY KEY (id)
) COMMENT='Menu table';
CREATE TABLE bill_info (
id INT COMMENT 'Bill ID',
items VARCHAR(512) COMMENT 'Ordered dishes',
actual_amount INT COMMENT 'Actual amount paid',
restaurant_id INT COMMENT 'Dining outlet',
waiter VARCHAR(16) COMMENT 'Waiter',
diner_count INT COMMENT 'Number of diners',
pay_time DATE COMMENT 'Payment time',
PRIMARY KEY (id)
) COMMENT='Bill table';Use ChatBI
You can now use the PolarDB for AI NL2SQL model to generate SQL statements that correspond to user questions.
Create a table schema index
Run the following SQL statement to create a table schema index table named schema_index. This table provides table schema information to the LLM.
/*polar4ai*/CREATE TABLE schema_index(id integer, table_name varchar, table_comment text_ik_max_word, table_ddl text_ik_max_word, column_names text_ik_max_word, column_comments text_ik_max_word, sample_values text_ik_max_word, vecs vector_768,ext text_ik_max_word, PRIMARY key (id));This table is not directly visible in the database. To view its information, run the following SQL statement.
/*polar4ai*/SHOW TABLES;Next, run the following SQL statement to import the data table schema into the schema_index index table.
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema') INTO schema_index;When you run the statement, PolarDB for AI vectorizes all tables in the current database and samples the column values by default.
After you run the statement, a task_id for the background task, such as bce632ea-97e9-11ee-bdd2-492f4dfe0918, is returned. Run the following SQL statement to query the task status. The index building is complete when the taskStatus is finish.
/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;Answer questions using the NL2SQL model
Run the following SQL statement to use the LLM-based NL2SQL feature online. In this example, the user's question is What is the total income for this week, and the table schema index is schema_index.
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select 'What is the total income for this week') WITH (basic_index_name='schema_index');The database needs some time to process the request and retrieve a response from the LLM. The expected result is shown below:
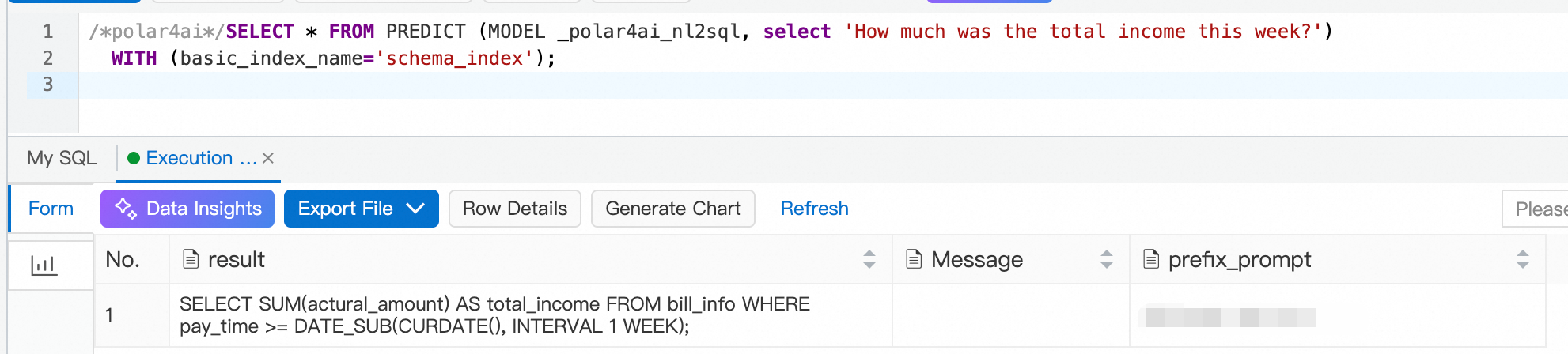
Based on the preceding example, you can ask other typical questions. These questions cover various scenarios, such as GROUP BY, multi-table JOIN, ORDER BY, and formulas.
Question No. | User question | NL2SQL return value |
1 | Sort outlets by income |
|
2 | Which outlet in Shanghai has the highest income? |
|
3 | What is the average spending per person in Shanghai? |
|
4 | What are the top ten most ordered dishes this month? |
|
5 | What is the month-over-month income growth percentage for this month compared to last month? |
|
6 | Which outlet in Shanghai has the highest customer traffic? |
|
The LLM-based NL2SQL model answers user questions well, but some responses may not be as expected. For example, in the second question, the user wants the outlet name. If you rephrase the question as Which outlet in Shanghai has the highest income? Please return the outlet name., the model returns the following SQL statement: SELECT r.name FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position = 'Shanghai' ORDER BY b.actual_amount DESC LIMIT 1;. You can also fine-tune the model to improve its accuracy. The following sections describe how to address these issues.
Fine-tune the model
Configure question templates
You can use general question templates to guide the model. These templates provide specific knowledge to help the model generate SQL statements.
Run the following SQL statement to create the question template table
polar4ai_nl2sql_pattern.CREATE TABLE `polar4ai_nl2sql_pattern` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `pattern_question` text COMMENT 'Template question', `pattern_description` text COMMENT 'Template description', `pattern_sql` text COMMENT 'Template SQL', `pattern_params` text COMMENT 'Template parameters', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;The table name must start with
polar4ai_nl2sql_pattern. The table schema must include the five columns from the `CREATE TABLE` statement.Next, create the index table
pattern_indexfor the question template./*polar4ai*/CREATE TABLE pattern_index(id integer, pattern_question text_ik_max_word, pattern_description text_ik_max_word, pattern_sql text_ik_max_word, pattern_params text_ik_max_word, pattern_tables text_ik_max_word, vecs vector_768, PRIMARY key (id));To fine-tune the model, configure a template for the second question. The goal is to return the outlet's name.
Run the following SQL statement to add a new pattern:
INSERT INTO polar4ai_nl2sql_pattern (id, pattern_question, pattern_description, pattern_sql, pattern_params) VALUES ( 1, "Which outlet in #{position} has the highest income?", "Which outlet in [location] has the highest income?", "SELECT r.position FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position LIKE '%#{position}%' ORDER BY b.actual_amount DESC LIMIT 1;", '[{"table_name":"bill_info","param_info":[{"param_name":"#{position}","value":["Shanghai"]}], "explanation": "Consumption location"}]' );The pattern uses slots to match multiple locations. In the
pattern_sqlcolumn, enter the correct SQL statement and mark the slot with#{}. Thepattern_paramscolumn is used for additional post-processing of table information, but you can ignore it here.Next, import the question template information into the index table.
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern') INTO pattern_index;Similar to the process for building the
schema_indextable, a task ID is returned. You can check the task status by running/*polar4ai*/show task 'xxx-xxx-xxx'.NoteIf the data in the
polar4ai_nl2sql_patterntable is updated, you must recreatepattern_indexand import the data again. Use the following SQL statement to delete the old index table:/*polar4ai*/DROP TABLE pattern_index;Re-execute the problematic SQL statement and add the
pattern_indexhint./*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select 'Which outlet in Shanghai has the highest income?') WITH (basic_index_name='schema_index',pattern_index_name='pattern_index');
Create a configuration table
If you want to pre-process questions or post-process the generated SQL, you can use a configuration table.
Vocabulary meaning hints
In the sixth question, the LLM cannot accurately interpret the term "customer traffic". You can configure the polar4ai_nl2sql_llm_config table to preprocess this term.
CREATE TABLE `polar4ai_nl2sql_llm_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key',
`is_functional` int(11) NOT NULL DEFAULT '1' COMMENT 'Whether it is effective',
`text_condition` text COMMENT 'Text condition',
`query_function` text COMMENT 'Query processing',
`formula_function` text COMMENT 'Formula information',
`sql_condition` text COMMENT 'SQL condition',
`sql_function` text COMMENT 'SQL processing',
PRIMARY KEY (`id`)
);You can insert the configuration item to instruct the Large Language Model (LLM) to count "customer traffic" or "customer flow" as the number of diners.
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
1,
1,
"customer traffic||customer flow",
"",
"Customer traffic or customer flow is counted as the sum of the number of diners",
"",
""
);A value of 1 for is_functional indicates that the configuration item is active. The text_condition field value "customer traffic||customer flow" matches questions that contain either "customer traffic" or "customer flow". The formula_function field uses text or a formula to explain the meaning of a technical term to the LLM.
In this case, you can run SQL generation directly without building an index table or performing vectorization. The result is shown below.

Fuzzy matching hints
In the third question, matching a place name with the = operator may fail. You can add the following configuration item to hint that a fuzzy search should be used for place name matching.
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
2,
1,
"",
"",
"Matching for the outlet location 'position' requires a fuzzy search",
"",
""
);Here, text_condition is empty, which means the configuration item applies globally. Use this with caution.
The result is shown below. The location matching now correctly uses a fuzzy search.
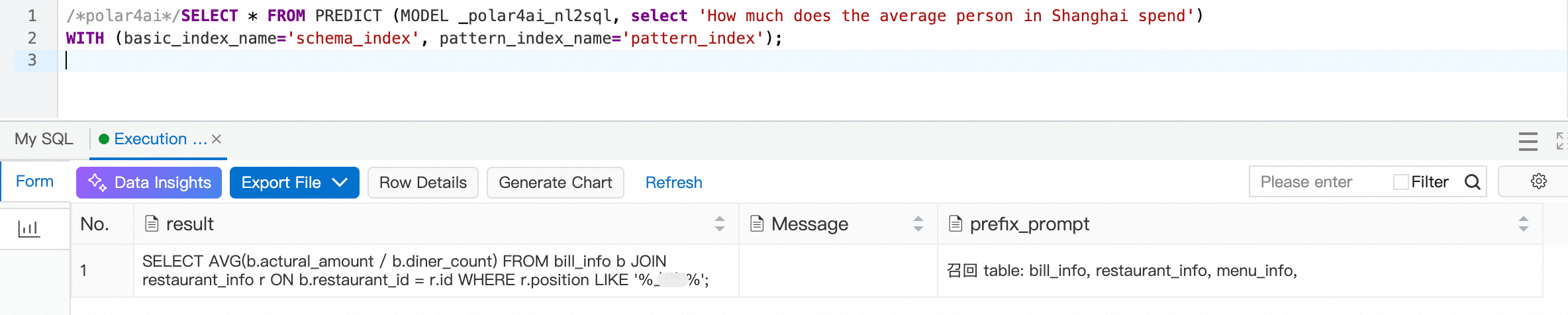
Similarly, for the fifth question, you can add the calculation formulas for "month-over-month" and "year-over-year" to the polar4ai_nl2sql_llm_config table. This improves the precision of the generated SQL. You can try this yourself as a challenge.
Retrain and fine-tune the model
If the model does not meet your business requirements, you can retrain it and fine-tune its internal parameters to achieve better results.
Conditions
This feature is only supported on clusters with AI nodes of the polar.mysql.x8.2xlarge.gpu (16-core, 125 GB, one GU100) specification.
You can train only one model at a time.
You can deploy only one model at a time.
Instructions
Train the model
/*polar4ai*/CREATE MODEL udf_qwen14b WITH (model_class='qwen-turbo', model_parameter=(basic_index_name='schema_index', pattern_index_name='pattern_index',training_type='efficient_sft')) as (SELECT '')Parameter descriptions
Parameter | Description | Default | Valid values/Range |
model_class | The model type. Currently, 'qwen-14b-chat' and 'qwen-turbo' are supported. | None | {'qwen-14b-chat', 'qwen-turbo'} |
model_parameter | The model parameter settings, including required and optional parameters. | None | None |
basic_index_name | The name of the index table from which the database information in the training data is sampled. This must be a database index table. | None | None |
pattern_index_name | The name of the index table from which the question template information in the training data is sampled. This must be a question template index table. | None | None |
training_type | The training type. Valid values are 'efficient_sft' and 'sft'. 'efficient_sft' indicates efficient training, typically using LoRa. 'sft' indicates full-parameter training. | None | {'efficient_sft', 'sft'} |
n_epochs | The number of epochs. This is the number of times the model learns from the dataset during training. A range of 1 to 3 is recommended, but you can adjust it as needed. | 3 | [1, 200] |
learning_rate | The learning rate. This represents the incremental parameter weight for each data update. A larger learning rate results in larger parameter changes and has a greater impact on the model. | '3e-4' | None |
batch_size | The batch size. This represents the data step size for updating model parameters. A batch size of 16 or 32 is recommended. | 16 | {8, 16, 32} |
lr_scheduler_type | The learning rate scheduler type. This dynamically changes the learning rate used when updating weights during training. | 'linear' | {'linear', 'cosine', 'cosine_with_restarts', 'polynomial', 'constant', 'constant_with_warmup', 'inverse_sqrt', 'reduce_lr_on_plateau'} |
eval_steps | The interval step size for model validation. This is used to periodically evaluate training accuracy and loss. | 50 | [1, 2147483647] |
sequence_length | The sequence length of the training data. This is the maximum length of a single sample. Data exceeding this length is automatically truncated. | 2048 | [500, 2048] |
lr_warmup_ratio | The ratio of warmup steps to the total number of training steps. | 0.05 | (0, 1) |
weight_decay | L2 regularization, which helps reduce overfitting. | 0.01 | (0, 0.2) |
gradient_checkpointing | Enables or disables gradient checkpointing to save GPU memory. | 'True' | {'True', 'False'} |
use_flash_attn | Specifies whether to use Flash Attention. | 'True' | {'True', 'False'} |
lora_rank | The rank in LoRa training. This affects the degree to which the training data influences the model. | 8 | {2, 4, 8, 16, 32, 64} |
lora_alpha | The scaling factor in LoRa training. This is used to adjust the initial training weights. | 32 | {8, 16, 32, 64} |
lora_dropout | The ratio of neurons to randomly drop during training. This prevents overfitting and improves the model's generalization ability. | 0.1 | (0, 0.2) |
lora_target_modules | Selects specific modules of the model for fine-tuning. | 'ALL' | {'ALL', 'AUTO'} |
View the model
/*polar4ai*/SHOW model udf_qwen14bDelete the model
/*polar4ai*/DROP model udf_qwen14bView all models
/*polar4ai*/SHOW modelsModel deployment
A trained model must be deployed before it can be used in NL2SQL.
/*polar4ai*/deploy model udf_qwen14bView the deployment
/*polar4ai*/SHOW deployment udf_qwen14bDelete the deployment
/*polar4ai*/DROP deployment udf_qwen14bView all deployments
/*polar4ai*/SHOW deploymentsUse a deployed model for natural language to SQL
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT 'What is the content for id 1?') WITH (basic_index_name='schema_index', llm_model='udf_qwen14b')Parameter descriptions
Parameter | Description |
basic_index_name | Required. The index table for the database information related to the current question. |
llm_model | Optional. If you leave this empty, the system calls the model without fine-tuning for NL2SQL. If you specify a value, make sure it is the name of a deployment that is in the "serving" state. Models that are not fully deployed cannot be used. |