Qwen3 is Alibaba Cloud's latest open-source LLM series featuring a hybrid thinking mode and Mixture-of-Experts (MoE) architecture. Deploy, fine-tune, and evaluate Qwen3 models in Model Gallery using SGLang, vLLM, or BladeLLM.
Inference engines
Model Gallery supports three inference engines for Qwen3 deployment. Select an engine based on your requirements:
-
SGLang (recommended): High-throughput serving framework with optimized scheduling. Best for production workloads. This tutorial uses SGLang as the default engine.
-
vLLM: Popular open-source engine with PagedAttention for efficient memory management. Good for compatibility with existing vLLM-based pipelines.
-
BladeLLM: High-performance inference framework developed by Alibaba Cloud PAI. Optimized for Alibaba Cloud GPU instances.
Model deployment and invocation
Deploy the model
Deploy the Qwen3-235B-A22B model with SGLang.
-
Go to the Model Gallery page.
-
Log on to the PAI console and select a region. Switch regions if the current region lacks computing resources.
-
In the navigation pane, click Workspace Management and click the target workspace name.
-
In the left navigation pane, choose QuickStart > Model Gallery.
-
-
On the Model Gallery page, click the Qwen3-235B-A22B model card to open the model details page.
-
Click Deploy. Configure the following parameters and keep defaults for others.
-
Deployment Method: Set Inference Engine to SGLang and Deployment Template to Single-Node.
-
Resource Information: Set Resource Type to Public Resources. The system automatically recommends an instance type. For minimum required configuration, see Required computing power & supported token count.
-
Important
If no instance types are available, the public resource inventory in this region is insufficient. Try the following:
-
Switch regions. China (Ulanqab) has larger inventory of Lingjun preemptible resources, such as ml.gu7ef.8xlarge-gu100, ml.gu7xf.8xlarge-gu108, ml.gu8xf.8xlarge-gu108, and ml.gu8tf.8.40xlarge. Preemptible resources can be reclaimed, so be mindful of your bid.
-
Use an EAS resource group. Purchase dedicated EAS resources from EAS Dedicated Resources Subscription.
-

-
Debug online
On the Service Details page, click Online Debugging.

Call the API
-
Obtain the service endpoint and token.
-
In Model Gallery > Job Management > Deployment Jobs, click the name of the deployed service to open the service details page.
-
Click View Invocation Method to view the Internet Endpoint and token.

-
-
Call the
/v1/chat/completionsendpoint for an SGLang deployment.curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: <EAS_TOKEN>" \ -d '{ "model": "<model_name, obtained from /v1/models API>", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "hello!" } ] }' \ <EAS_ENDPOINT>/v1/chat/completionsfrom openai import OpenAI ##### API configuration ##### # Replace <EAS_ENDPOINT> with service endpoint and <EAS_TOKEN> with service token. openai_api_key = "<EAS_TOKEN>" openai_api_base = "<EAS_ENDPOINT>/v1" client = OpenAI( api_key=openai_api_key, base_url=openai_api_base, ) models = client.models.list() model = models.data[0].id print(model) stream = True chat_completion = client.chat.completions.create( messages=[ {"role": "user", "content": "Hello, please introduce yourself."} ], model=model, max_completion_tokens=2048, stream=stream, ) if stream: for chunk in chat_completion: print(chunk.choices[0].delta.content, end="") else: result = chat_completion.choices[0].message.content print(result)Replace
<EAS_ENDPOINT>with your service endpoint and<EAS_TOKEN>with your service token.
Invocation methods vary by deployment type. For more examples, see Deploy large language models and call APIs.
Integrate third-party applications
To connect to Chatbox, Dify, or Cherry Studio, see Integrate third-party clients.
Advanced configuration
The default deployment works without additional configuration. The following settings are for specific use cases: extending context length beyond 32K tokens, enabling structured tool calling, or controlling the thinking mode. Skip this section if defaults meet your requirements.
To modify the configuration: On the deployment page, edit JSON in Service Configuration. For a deployed service, update it first to access the deployment page.

Modify the token limit
Qwen3 models natively support 32,768 tokens. Use RoPE scaling to extend this to 131,072 tokens, though this may cause slight performance degradation. Modify the containers.script field in the service configuration JSON:
-
vLLM:
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072 -
SGLang:
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
Parse tool calls
vLLM and SGLang support parsing tool calling output into structured messages. Modify the containers.script field in the service configuration JSON:
-
vLLM:
vllm serve ... --enable-auto-tool-choice --tool-call-parser hermes -
SGLang:
python -m sglang.launch_server ... --tool-call-parser qwen25
Control the thinking mode
Qwen3 uses thinking mode by default. Control this behavior with a hard switch (completely disable thinking) or a soft switch (model follows user instruction on whether to think).
Use a soft switch /no_think
Example request body:
{
"model": "<MODEL_NAME>",
"messages": [
{
"role": "user",
"content": "/no_think Hello!"
}
],
"max_tokens": 1024
}Use a hard switch
-
Control with an API parameter (for vLLM and SGLang): Add the
chat_template_kwargsparameter to your API call.curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: <EAS_TOKEN>" \ -d '{ "model": "<MODEL_NAME>", "messages": [ { "role": "user", "content": "Give me a short introduction to large language models." } ], "temperature": 0.7, "top_p": 0.8, "max_tokens": 8192, "presence_penalty": 1.5, "chat_template_kwargs": {"enable_thinking": false} }' \ <EAS_ENDPOINT>/v1/chat/completionsfrom openai import OpenAI # Replace <EAS_ENDPOINT> with service endpoint and <EAS_TOKEN> with service token. openai_api_key = "<EAS_TOKEN>" openai_api_base = "<EAS_ENDPOINT>/v1" client = OpenAI( api_key=openai_api_key, base_url=openai_api_base, ) chat_response = client.chat.completions.create( model="<MODEL_NAME>", messages=[ {"role": "user", "content": "Give me a short introduction to large language models."}, ], temperature=0.7, top_p=0.8, presence_penalty=1.5, extra_body={"chat_template_kwargs": {"enable_thinking": False}}, ) print("Chat response:", chat_response)Replace
<EAS_ENDPOINT>with your service endpoint,<EAS_TOKEN>with your service token, and<MODEL_NAME>with the model name from/v1/modelsAPI. -
Disable by modifying the service configuration (for BladeLLM): Use a chat template that prevents the model from generating thinking content.
-
On the model's product page in Model Gallery, check for a method to disable thinking mode for BladeLLM. For example, with Qwen3-8B, modify the
containers.scriptfield in the service configuration JSON:blade_llm_server ... --chat_template /model_dir/no_thinking.jinja -
Alternatively, write a custom chat template such as
no_thinking.jinja, mount it from OSS, and modify thecontainers.scriptfield.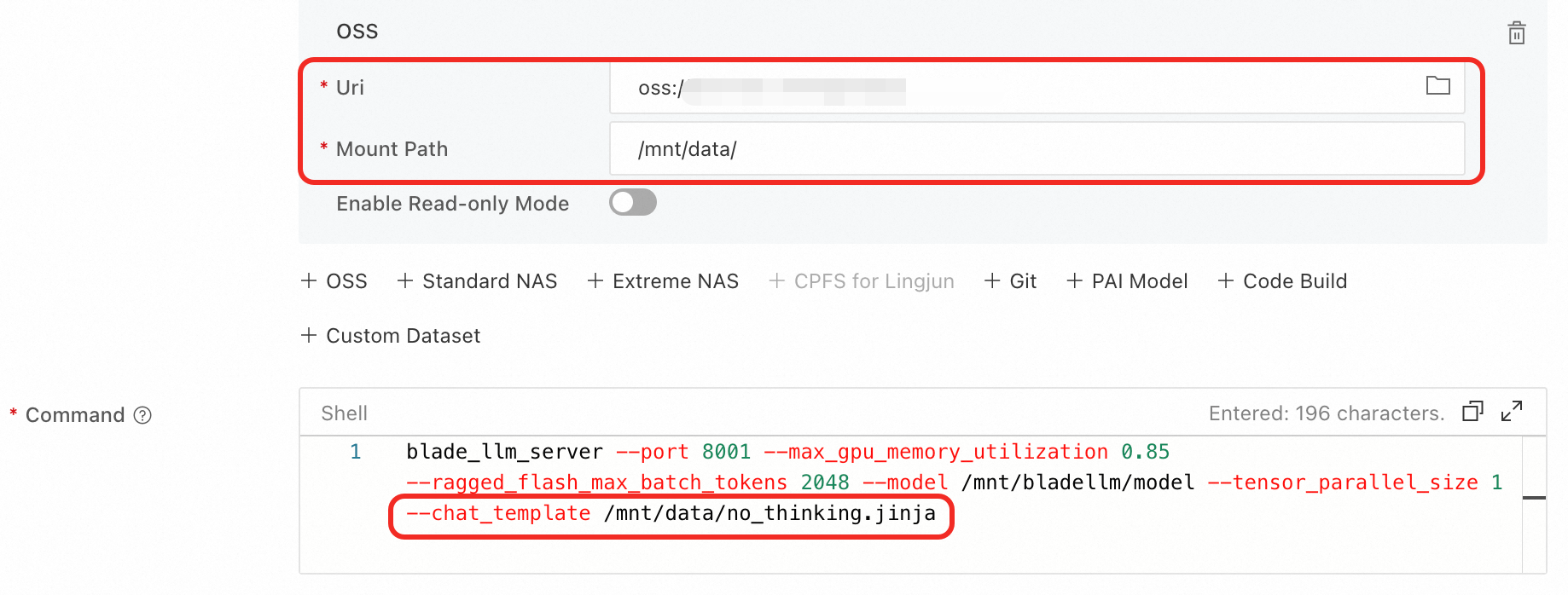
-
Parse thinking content
To output thinking content separately, modify the containers.script field in the service configuration JSON:
-
vLLM:
vllm serve ... --enable-reasoning --reasoning-parser qwen3 -
SGLang:
python -m sglang.launch_server ... --reasoning-parser deepseek-r1
Model fine-tuning
Qwen3-32B, 14B, 8B, 4B, 1.7B, and 0.6B models support fine-tuning in Model Gallery. The following algorithms are available:
-
Supervised Fine-Tuning (SFT): Train the model on instruction-output pairs. Supports full-parameter, LoRA, and QLoRA strategies. Use full-parameter training for maximum quality when compute resources are sufficient. Use LoRA or QLoRA for resource-efficient training with minimal quality trade-off.
-
Generative Rejection-based Preference Optimization (GRPO): Align model outputs with human preferences using reward signals. Suitable for improving response quality after SFT.
Training data format
SFT accepts JSON-formatted input. Each record contains an instruction and its corresponding output:
[
{
"instruction": "Summarize the key features of Qwen3 models.",
"output": "Qwen3 models feature a hybrid thinking mode that can be toggled on or off, support for tool calling, and a Mixture-of-Experts (MoE) architecture in the 235B-A22B and 30B-A3B variants for efficient inference."
},
{
"instruction": "What is the difference between LoRA and QLoRA?",
"output": "LoRA adds low-rank adapters to the model weights for efficient fine-tuning. QLoRA combines LoRA with 4-bit quantization, further reducing memory usage while maintaining comparable training quality."
}
]Fine-tuning procedure
-
On the model details page in Model Gallery, click Train. Configure the following parameters:
-
Algorithm: Select SFT or GRPO.
-
Dataset Configuration: Upload training data to OSS, or select data from NAS or CPFS. PAI also provides public datasets for testing.
-
Compute Resource Configuration: A10 GPUs (24 GB) or higher are recommended. For 32B models, use GU100 GPUs (80 GB) or higher.
-
Model Output Path: The fine-tuned model is saved to OSS for download or deployment.

-
-
Configure hyperparameters. The following table describes key parameters:
Parameter
Default
Required
Description
training_strategy
sft
Yes
Training strategy. Set to
sftfor supervised fine-tuning orgrpofor preference optimization.learning_rate
5e-5
Yes
Controls weight adjustment magnitude per training step.
num_train_epochs
1
Yes
Number of passes over the training dataset.
per_device_train_batch_size
1
Yes
Samples processed per GPU per step. Larger values improve efficiency but increase VRAM usage.
lora_dim
32
No
LoRA adapter rank. When set to > 0, enables LoRA or QLoRA training. Set to 0 for full-parameter training.
load_in_4bit
false
No
Load model in 4-bit precision. When lora_dim > 0 and load_in_4bit is true, uses QLoRA training.
-
Click Train to start the job. Monitor status and view logs on the training page.
-
After training completes, click Deploy to deploy the fine-tuned model as an online service.
Model evaluation
Evaluate model performance before and after fine-tuning to measure improvements and compare different training strategies. Model Gallery provides built-in evaluation algorithms for Qwen3 models.
To evaluate a model:
-
On the model details page in Model Gallery, click Evaluate.
-
Select the evaluation target: the original pre-trained model or a fine-tuned version.
-
Configure the evaluation dataset and metrics. PAI supports standard benchmarks (MMLU, C-Eval, MATH) and custom datasets.
-
Submit the evaluation job and view results on the evaluation page.
For detailed instructions, see Model evaluation and Best practices for LLM evaluation.
Appendix: Required computing power and supported token count
The following table lists minimum configurations for deploying Qwen3 models and maximum supported token counts per inference framework.
Among FP8 models, only Qwen3-235B-A22B has a lower computing power requirement than its original counterpart. Other FP8 models require the same resources as their non-FP8 versions and are not listed separately. For example, for Qwen3-30B-A3B-FP8, refer to Qwen3-30B-A3B.
|
Model |
Maximum token count (input + output) |
Minimum configuration |
|
|
SGLang deployment |
vLLM deployment |
||
|
Qwen3-235B-A22B |
32,768 (with RoPE scaling: 131,072) |
32,768 (with RoPE scaling: 131,072) |
8 × GPU H / GU120 (8 × 96 GB GPU memory) |
|
Qwen3-235B-A22B-FP8 |
32,768 (with RoPE scaling: 131,072) |
32,768 (with RoPE scaling: 131,072) |
4 × GPU H / GU120 (4 × 96 GB GPU memory) |
|
Qwen3-30B-A3B Qwen3-30B-A3B-Base Qwen3-32B |
32,768 (with RoPE scaling: 131,072) |
32,768 (with RoPE scaling: 131,072) |
1 × GPU H / GU120 (96 GB GPU memory) |
|
Qwen3-14B Qwen3-14B-Base |
32,768 (with RoPE scaling: 131,072) |
32,768 (with RoPE scaling: 131,072) |
1 × GPU L / GU60 (48 GB GPU memory) |
|
Qwen3-8B Qwen3-4B Qwen3-1.7B Qwen3-0.6B Qwen3-8B-Base Qwen3-4B-Base Qwen3-1.7B-Base Qwen3-0.6B-Base |
32,768 (with RoPE scaling: 131,072) |
32,768 (with RoPE scaling: 131,072) |
1 × A10 / GU30 (24 GB GPU memory) Important
An 8B model with RoPE scaling requires 48 GB of GPU memory. |
FAQ
How do I maintain conversation context across multiple API calls?
PAI model services are stateless. Each API call is independent — the server does not retain context between requests.
To implement multi-turn conversation, manage conversation history on the client side. Pass the entire conversation history in the messages payload with each API call. For an example, see Implement multi-turn conversation