Evaluate large language models (LLMs) using custom datasets or public benchmarks such as MMLU and C-Eval to quantify and compare model performance.
Overview
Model evaluation supports two evaluation approaches:
-
Custom dataset evaluation
Rule-based evaluation: Measures similarity between model predictions and reference answers using ROUGE and BLEU metrics.
Judge model evaluation: Uses a judge model from Token Service to score model outputs item by item. This approach is best suited for open-ended and complex question-answering scenarios.
-
Public dataset evaluation
Evaluates models against industry-standard public datasets, including MMLU, TriviaQA, HellaSwag, GSM8K, C-Eval, and TruthfulQA.
Produces benchmark scores aligned with industry evaluation standards.
Supported models: All HuggingFace AutoModelForCausalLM model types are supported.
Use cases
Use model evaluation to:
Model benchmarking: Evaluate a model's general capabilities against public datasets and compare results with industry models or baselines.
Domain-specific evaluation: Test a model in a specific domain and compare pretrained versus fine-tuned model performance to assess how well the model applies domain knowledge.
Regression testing: Build a regression test set to evaluate model performance in real-world business scenarios and determine whether the model meets production standards.
Billing
OSS storage fees: Applies to storing evaluation datasets and results. See OSS billing.
DLC evaluation job fees: Applies to running evaluation jobs. See DLC billing.
Judge model evaluation: See PAI Token Service pricing.
Data preparation
Model evaluation supports both custom and public datasets, including C-Eval.
-
Public datasets:
PAI provides the following public datasets: MMLU, TriviaQA, HellaSwag, GSM8K, C-Eval, and TruthfulQA. Check the console for the current list. Select any dataset to use it directly.
-
Custom datasets:
Prepare a custom evaluation file in JSONL format and upload it to OSS. Then create a custom dataset. For details, see Upload OSS files and Create and manage datasets. The file format is as follows:
Use
questionfor the question column andanswerfor the reference answer column. You can also change these column mappings on the evaluation page. If you only need judge model evaluation, theanswercolumn is optional.{"question": "Did ancient China invent papermaking?", "answer": "Yes"} {"question": "Did ancient China invent gunpowder?", "answer": "Yes"}Sample file: eval.jsonl
Evaluate a model

Step 1: Select a model
-
Go to the Model Gallery page.
Log in to the PAI console.
In the left navigation pane, click Workspaces, then select your target workspace.
In the left navigation pane, choose QuickStart>Model Gallery.
-
Find a model that supports evaluation.
Filter evaluable models from Models. In the Supported Operations filter area, select Evaluate to show only evaluable models.
Evaluate a fine-tuned model. Fine-tuned models retain evaluation capability. On the Model Gallery page, click Job Management>Training Jobs, then click the job name to open the job details page. The Evaluate button appears in the upper-right corner.
Step 2: Configure the evaluation task
Configure the evaluation task by selecting a dataset, setting hyperparameters, and optionally enabling judge model evaluation.
-
Configure basic parameters:
Job Name: An auto-generated unique name.
Result Output Path: The OSS path where evaluation results are stored.
Label: Used for multi-dimensional resource lookup, batch operations, and cost allocation.
-
Configure the evaluation method:
-
Evaluation Method: Choose Custom Dataset Evaluation or Public Dataset Evaluation.
-
Public Dataset Evaluation:
Uses open-source datasets covering multiple domains (such as mathematics and coding) to provide a comprehensive capability evaluation for LLMs. Higher scores indicate better model performance.
Multiple datasets can be selected at the same time. GSM8K, TriviaQA, and HellaSwag are large datasets and may require longer evaluation times.
-
Custom Dataset Evaluation: Specify the question and reference answer columns for your custom dataset. If you only need judge model evaluation, the reference answer column can be left blank.
Dataset Source: Choose Select OSS File or Select an existing dataset..
-
Evaluation Method: Select one or both of the following evaluation methods:
General NLP Metric Evaluation: Calculates text similarity between model predictions and reference answers using ROUGE and BLEU metrics. Suited for scenarios with definitive answers. The dataset must include question-answer pairs.
Multi-Metric Evaluation with LLM-as-a-Judge: Automatically scores model answers using a judge model, with support for custom metrics. Suited for complex or open-ended answers. The dataset can contain questions only, or question-answer pairs.
-
-
-
Configure compute resources:
Resource Type: Supported resource types vary by model. Refer to the console for the available options.
Source: Choose from public resources, resource quotas, or spot resources.
After configuring all parameters, click OK to submit the task. You are redirected to the task details page. After the task completes, click Evaluation Report to view the evaluation report.
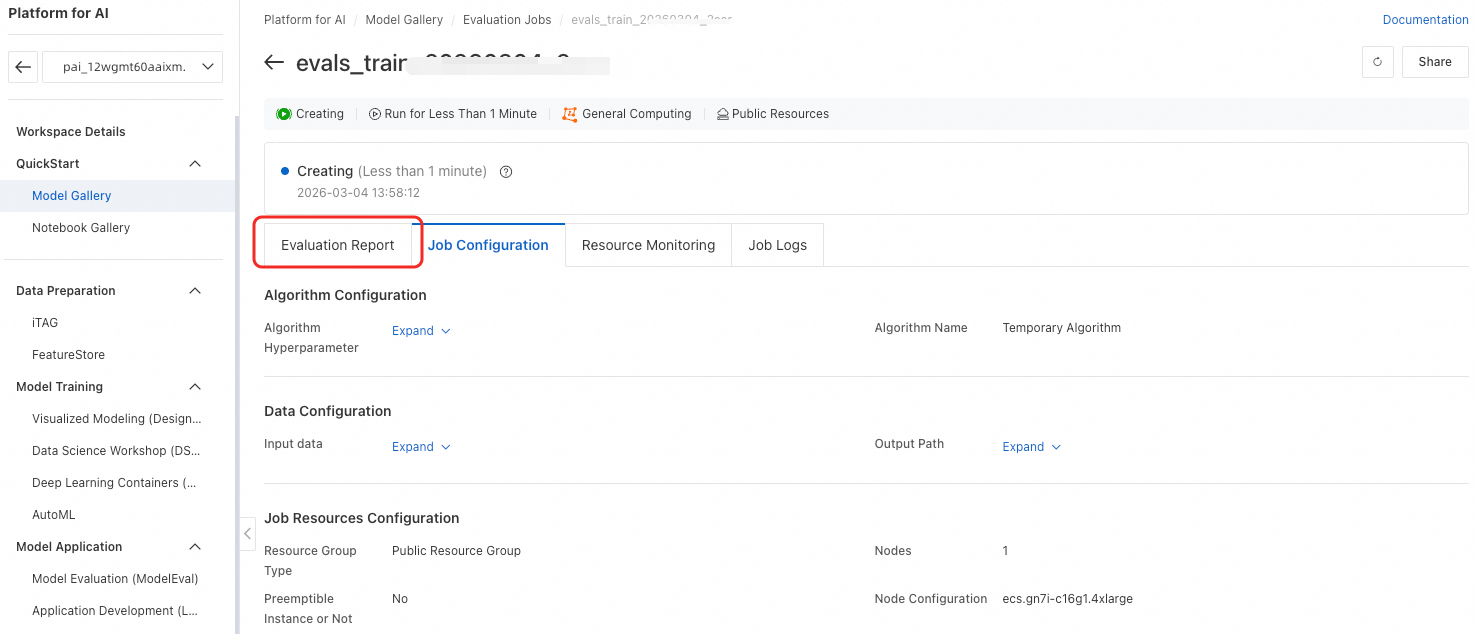
Step 3: View evaluation results
After the task completes, see View evaluation results below for instructions to view single-task results, compare multiple evaluation tasks, and interpret the scores.
View evaluation results
Evaluation task list
On the Model Gallery page, click Job Management, then switch to the Evaluation Jobs tab.
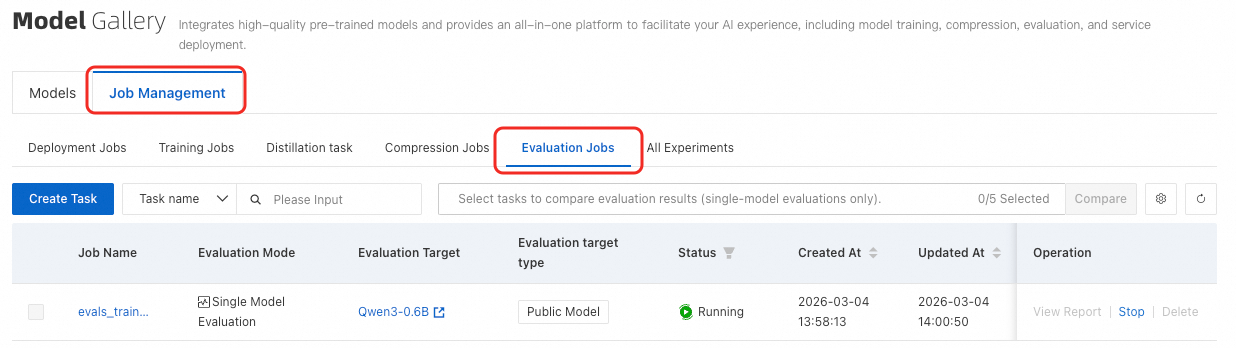
Single task results
On the evaluation task list page, click View Report in the Actions column for the task. The task details page opens and displays the model's evaluation scores on custom and public datasets in the Evaluation report section.
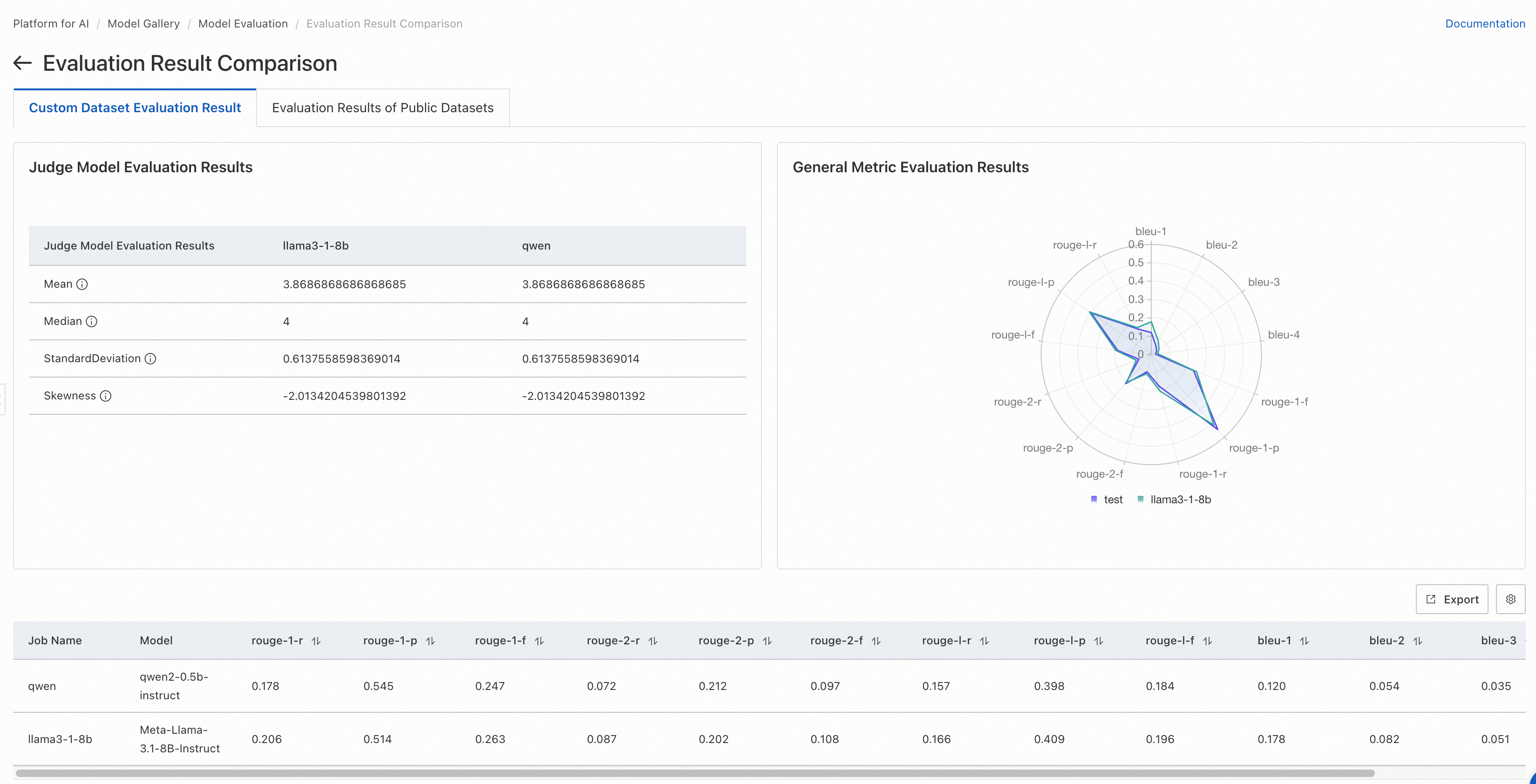
Custom dataset evaluation results
-
Rule-based evaluation:
Calculates similarity between model output and reference answers using standard NLP text-matching methods. Higher values indicate better model performance.
Suited for evaluating how well a model adapts to a specific domain using domain-specific data.
A radar chart shows the model's scores across the 13 ROUGE and BLEU metrics. For metric definitions, see Appendix: Metrics reference.
-
Judge model evaluation:
Uses an LLM to evaluate output quality at the semantic level. Higher mean and median values with a lower standard deviation indicate better model performance. This approach is more accurate than rule-based text matching.
-
A table shows the following statistical metrics from the judge model scores:
Mean: The average score assigned by the judge model (excluding invalid scores), on a scale of 1–5. Higher values indicate better answers.
Median: The median score assigned by the judge model (excluding invalid scores), on a scale of 1–5. Higher values indicate better answers.
Standard deviation: The standard deviation of judge model scores (excluding invalid scores). When the mean and median are equal, a lower standard deviation indicates better model consistency.
Skewness: The skewness of the judge model score distribution (excluding invalid scores). A positive skew indicates a longer tail on the right (high-score end); a negative skew indicates a longer tail on the left (low-score end).
Per-question evaluation details from the evaluation file are also displayed at the bottom of the page.

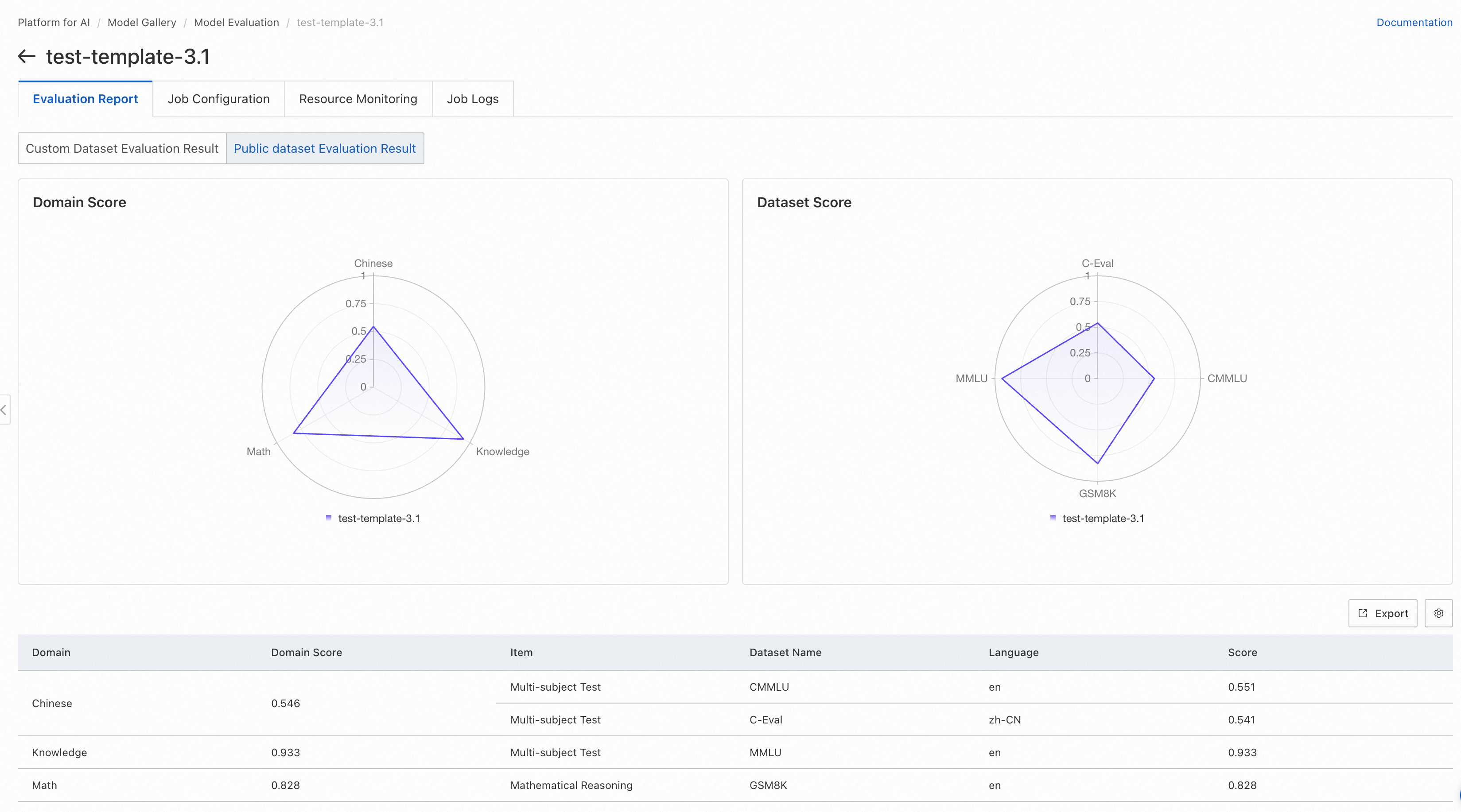
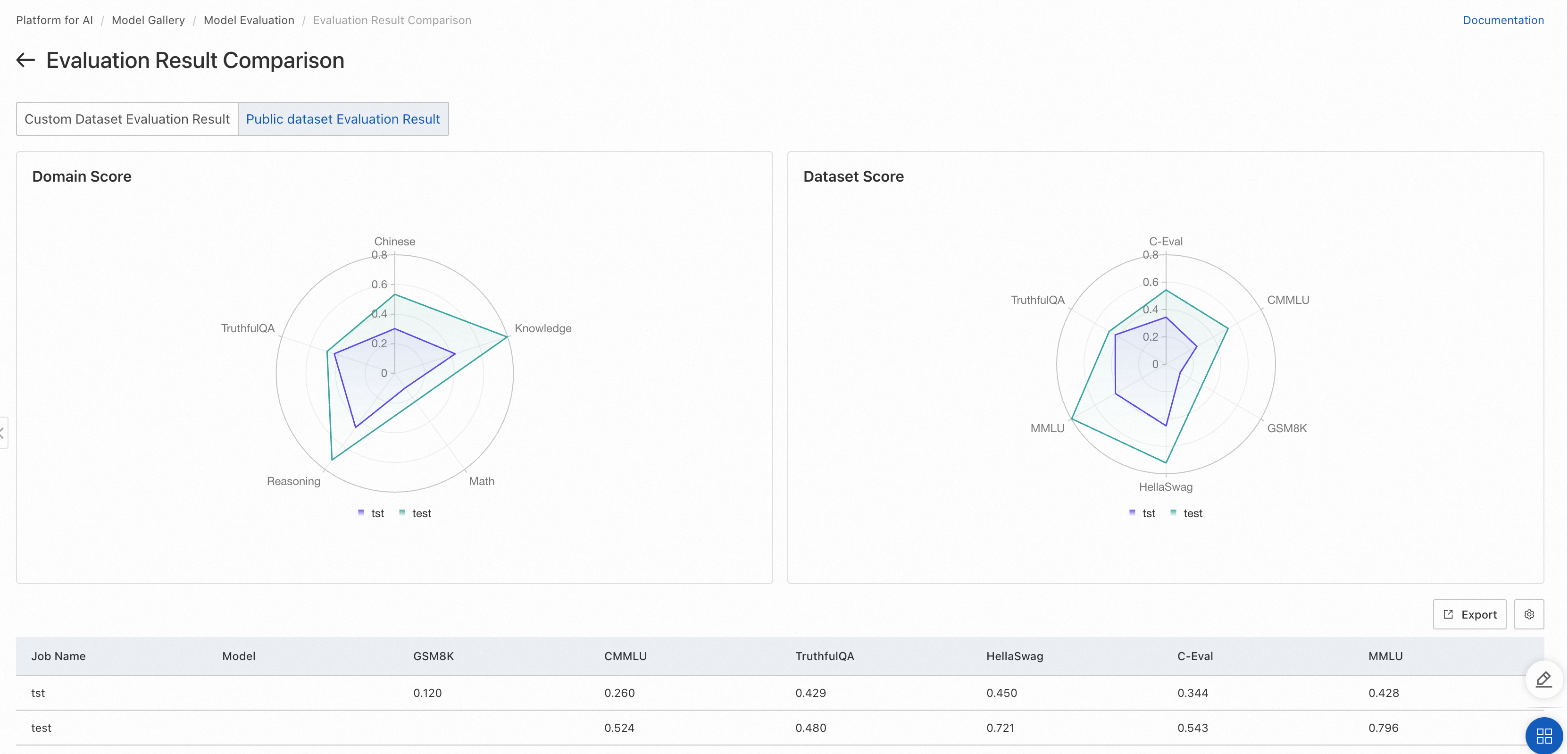
Public dataset evaluation results
If the evaluation task used public datasets, a radar chart shows the model's scores on those datasets.
The left chart shows the model's scores by domain. Each domain may include multiple datasets. For datasets in the same domain, scores are averaged to produce the domain score.
The right chart shows the model's scores on each individual public dataset. Refer to each dataset's official documentation for its evaluation scope.
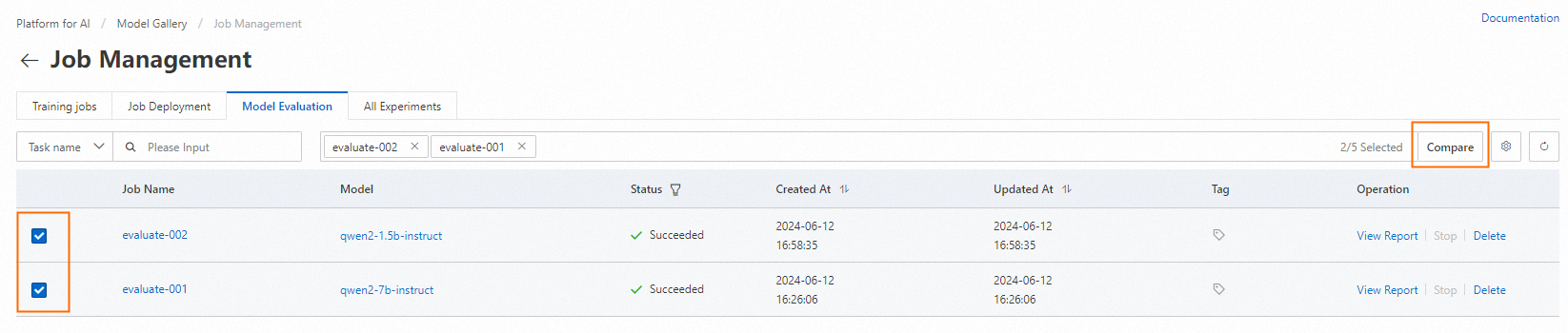
Compare multiple evaluation tasks
To compare results across multiple models, select the evaluation tasks on the left side of the evaluation task list page, then click Compare in the upper-right corner.
Custom dataset comparison
Public dataset comparison
References
You can also evaluate models using the PAI Python SDK. See the following notebooks:
Appendix: Metrics reference
This appendix provides detailed definitions for each metric used in custom dataset rule-based evaluation.
ROUGE metrics
ROUGE metrics measure the similarity between model predictions and reference answers.
ROUGE-N metrics calculate N-gram overlap (overlap of consecutive sequences of N words). ROUGE-1 and ROUGE-2 are the most widely used, measuring unigram (1-gram) and bigram (2-gram) overlap respectively.
ROUGE-L is based on the Longest Common Subsequence (LCS).
Metric suffixes: -p (precision), -r (recall), -f (F-score).
|
Metric |
Description |
|
rouge-1-p |
Proportion of unigrams in the system summary that match unigrams in the reference summary. |
|
rouge-1-r |
Proportion of unigrams in the reference summary that appear in the system summary. |
|
rouge-1-f |
Harmonic mean of rouge-1-p and rouge-1-r. |
|
rouge-2-p |
Proportion of bigrams in the system summary that match bigrams in the reference summary. |
|
rouge-2-r |
Proportion of bigrams in the reference summary that appear in the system summary. |
|
rouge-2-f |
Harmonic mean of rouge-2-p and rouge-2-r. |
|
rouge-l-p |
Ratio of the LCS length to the system output length (precision). |
|
rouge-l-r |
Ratio of the LCS length to the reference answer length (recall). |
|
rouge-l-f |
Harmonic mean of rouge-l-p and rouge-l-r. |
BLEU metrics
Bilingual Evaluation Understudy (BLEU) is a widely used metric for evaluating machine translation quality. It scores by measuring N-gram overlap between model output and reference answers.
|
Metric |
Description |
|
bleu-1 |
Measures unigram overlap. |
|
bleu-2 |
Measures bigram overlap. |
|
bleu-3 |
Measures trigram (3-gram) overlap. |
|
bleu-4 |
Measures 4-gram overlap. |