Overview
Alibaba Cloud OpenLake is a next-generation open lakehouse platform for big data, search, and artificial intelligence (AI) integration scenarios. The platform builds a unified metadata catalog on Data Lake Formation (DLF). It combines structured, semi-structured, unstructured, and vector data. This creates an Agentic Data architecture that uses a single copy of data with multiple engines, global search, and end-to-end governance.
OpenLake supports popular open table formats such as Paimon, Iceberg, and Lance. It provides a complete workflow from data ingestion, feature engineering, and vectorization to retrieval-augmented generation, model training, and inference. OpenLake offers enterprises a high-performance, low-cost, high-availability (HA), and easy-to-manage infrastructure for multimodal data.
The platform is suitable for enterprises in industries such as the Internet, finance, retail, manufacturing, education, and autonomous driving. These enterprises need to process multimodal data and build AI-native applications.

Benefits
Open standards to break down data silos
It is fully compatible with open source table formats such as Paimon, Iceberg, and Lance. It also supports open file standards such as Parquet, ORC, Avro, and CSV.
It seamlessly integrates with popular compute engines such as Spark, Flink, Trino, StarRocks, Hologres, and MaxCompute. This avoids the costs of data migration and format conversion.
It uses the DLF Omni Catalog to create a unified catalog for five data types: structured, semi-structured, unstructured, vector, and streaming. This lets you ingest data once and use it anywhere.
High-performance engine collaboration for efficient computing
Multiple engines, such as Spark, Flink, StarRocks, Hologres, and MaxCompute, can access the same lake data without redundant copies.
The unified DLF metadata service ensures consistent permissions, schema synchronization, and transaction isolation across engines.
Batch processing, stream computing, interactive queries, and AI training share the same storage. This significantly improves resource utilization and end-to-end efficiency.
It supports high-concurrency, low-latency mixed workloads. This meets the needs of scenarios that require both T+1 batch processing and real-time analytics with latency at the second level.
Unified development and governance to reduce complexity
OpenLake Studio, integrated with DataWorks, provides a unified development experience with a Notebook, a SQL IDE, and visual scheduling.
Centralized management of metadata, data permissions, data lineage, task orchestration, and quality monitoring enables governance from the start of development.
It supports large-scale, high-concurrency task scheduling to ensure enterprise-grade Service-Level Agreements (SLAs) and stability.
The entire data pipeline is traceable, auditable, and supports rollbacks to meet compliance requirements.
Data, Search, and AI integration to unlock data value
It combines structured tables, unstructured files (such as images, audio, video, and documents), and vector data to build a unified, multimodal lakehouse.
It natively supports SQL queries, full-text search (OpenSearch or Elasticsearch), and vector similarity search (Milvus or PgVector).
It provides a high-quality, searchable, and governable data pipeline for Large Language Model (LLM) retrieval-augmented generation (RAG) and intelligent agents.
It streamlines the entire workflow from data ingestion, feature engineering, and vectorization to retrieval augmentation and model inference. This accelerates the implementation of AI applications.
Core features
Feature | Description | Documentation |
Unified metadata and table management | Uses DLF to support a unified catalog for formats such as Paimon, Iceberg, Lance, and Parquet. | |
Storage cost optimization | Reduces storage costs using OSS intelligent tiering, compression, and lifecycle policies. | |
Real-time Integration of Data Lakes and Streams | Flink, Streaming Storage Fluss, and DLF enable data ingestion in seconds and data visibility in minutes. | |
Enterprise-grade high-performance engines | Integrates cloud-native engines such as Serverless Spark, Flink, Hologres, and MaxCompute. | What is EMR Serverless Spark, What is Realtime Compute for Apache Flink, What is Hologres, What is MaxCompute |
Collaborative development for big data and AI | OpenLake Studio combines a Notebook, SQL, and visual scheduling. | |
Agent and Copilot integration | The OpenLake Agent / MCP protocol lets multimodal intelligent agents directly access the lakehouse. |
Typical architecture solutions
Solution 1: Classic lakehouse architecture (Serverless Spark + StarRocks + DLF)
Scenarios: This solution is primarily for T+1 batch processing and is designed for cost-effective and fully managed batch analytics scenarios, such as reports, business intelligence, and user personas.
Components: EMR Serverless Spark (batch processing) + StarRocks (sub-second queries) + DLF (unified metadata).
Alternative solutions: AWS Redshift + Glue, Databricks (batch processing), Hive + Presto.
Benefits: Reduces costs by over 30%, improves query performance by 3 to 5 times, and is fully managed.
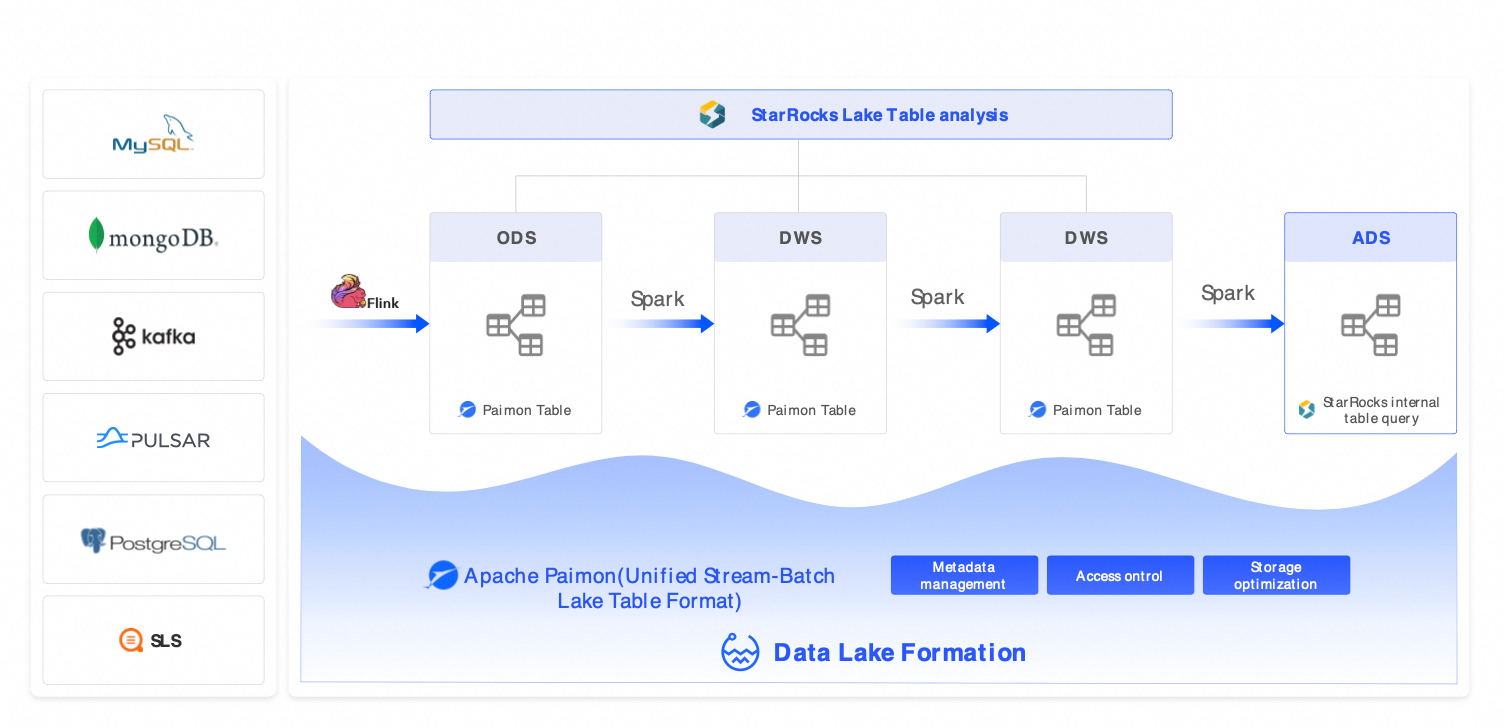
Solution 2: Streaming lakehouse architecture (Flink + Hologres + DLF)
Scenarios: This solution is for near-real-time analytics with second-to-minute latency, such as real-time risk control, ad performance monitoring, and IoT device monitoring.
Components: Flink (streaming extract, transform, and load (ETL)) + Hologres (real-time serving) + DLF (cross-engine collaboration).
Alternative solutions: Kafka + ClickHouse + Hive, AWS Kinesis + Redshift.
Benefits: End-to-end data visibility within 10 minutes and query latency of less than 1 second.

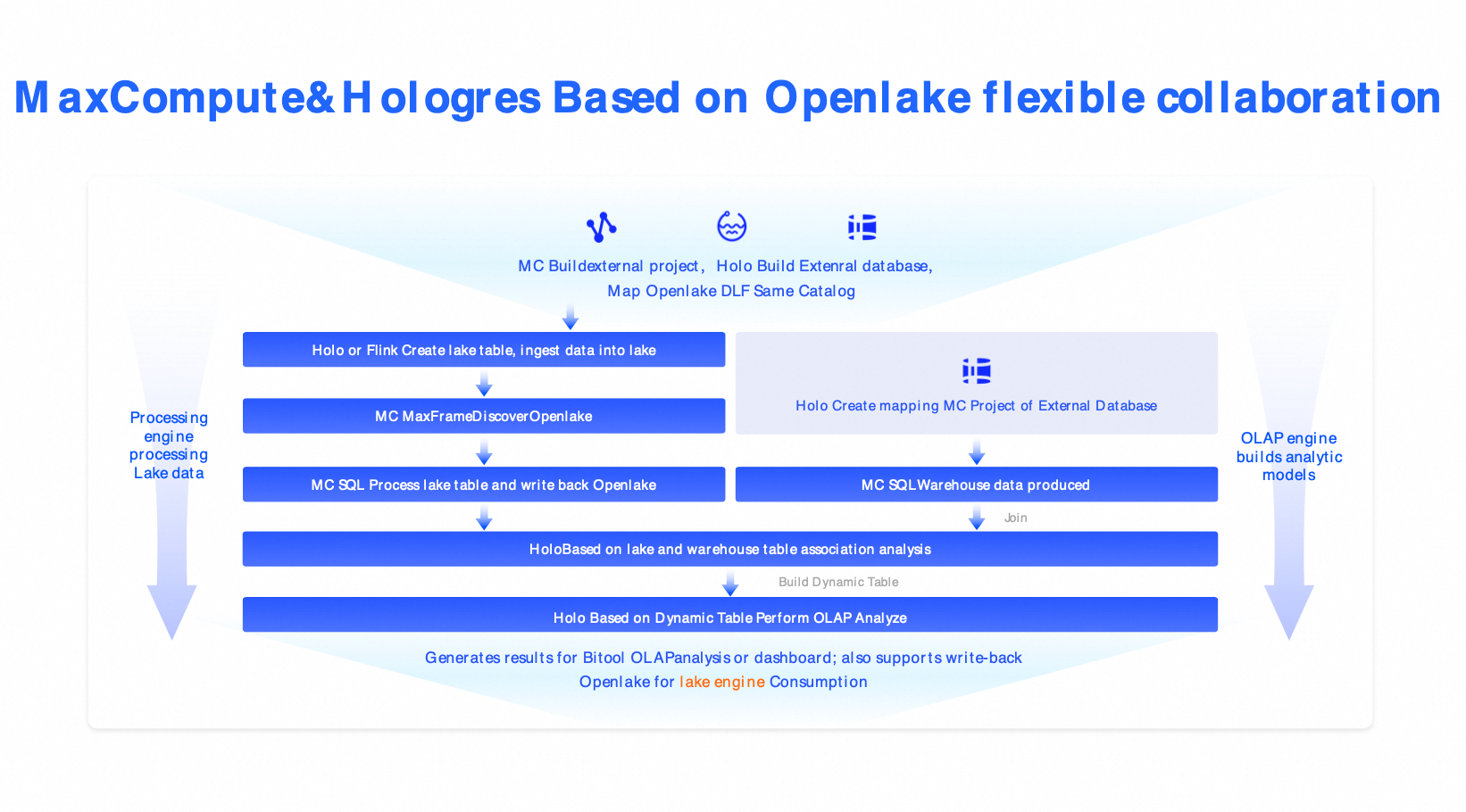
Solution 3: Cloud-native lakehouse architecture (MaxCompute + Hologres + DLF)
Scenarios: This solution is for industries such as finance and government that have strict requirements for security, compliance, and large-scale processing.
Components: MaxCompute (petabyte-scale batch processing) + Hologres (millisecond writes) + DLF (governance).
Alternative solutions: Snowflake, Azure Synapse, Databricks commercial editions.
Benefits: Enterprise-grade security, elastic scaling, RPO=0, and RTO < 30 minutes.
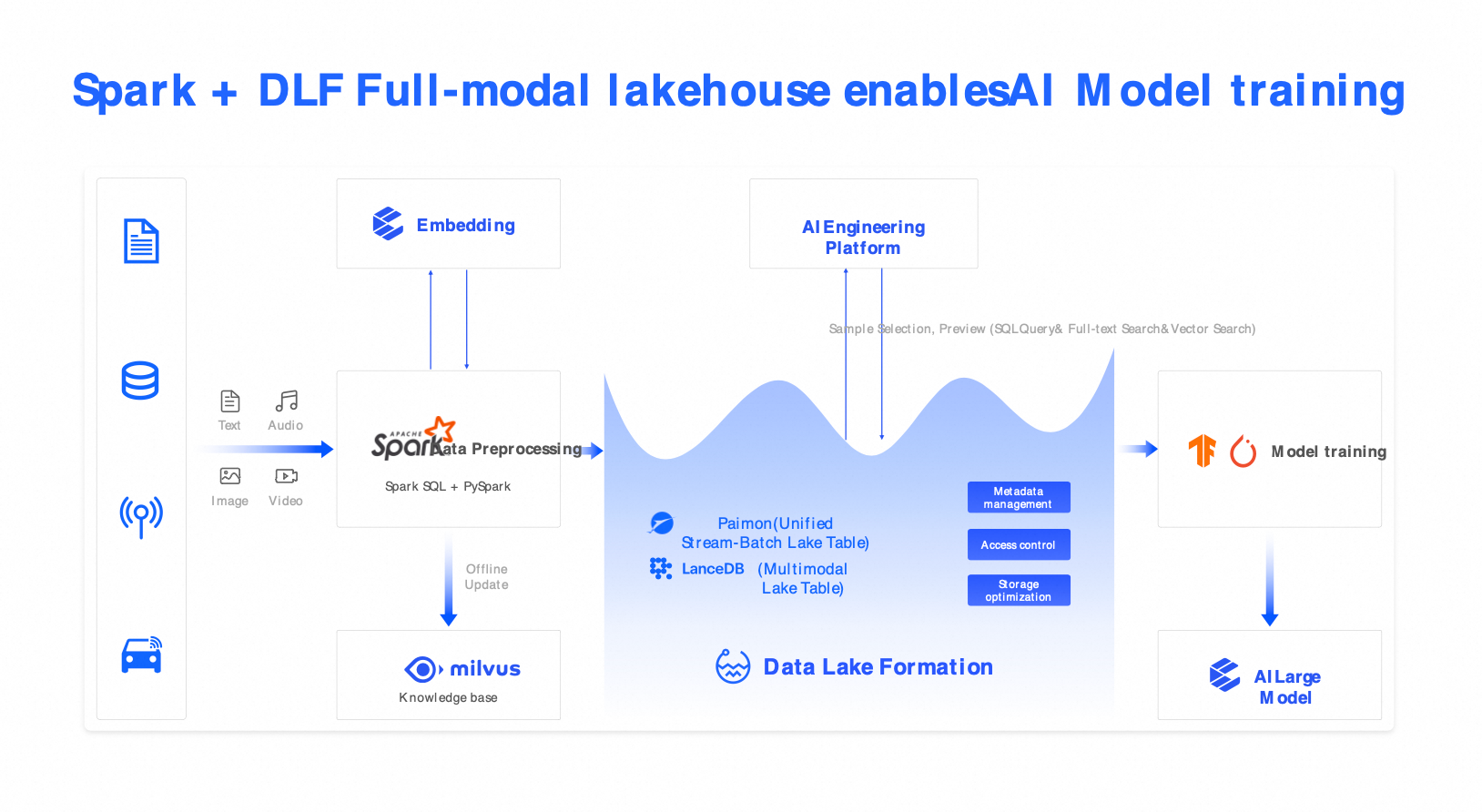
Solution 4: Omni-modal vector lake (Spark + Milvus + DLF)
Scenarios: This solution is for AI training, multimodal semantic search, RAG applications, intelligent customer service, and autonomous driving perception data management.
Components: Spark (multimodal pre-processing), Milvus (vector search), and DLF (unified catalog).
Capabilities: Supports hybrid search across text, images, audio, and video using combined SQL and vector queries.
Benefits: Improves sample selection efficiency by 5 times and supports high-quality fine-tuning for LLMs.
Use cases: AI training, multimodal semantic search, RAG applications, intelligent customer service, and autonomous driving perception data management.