DataWorks Notebook is an interactive, modular environment for data analysis and development. Use Python, SQL, and Markdown cells together to connect to compute engines such as MaxCompute, EMR, and AnalyticDB — covering everything from data processing and exploratory analysis to visualization and model development. This document guides you through using Notebook efficiently for data development and task scheduling.
Run your first Notebook
This section walks you through creating a Notebook, passing a variable from Python to SQL, and querying data from a MaxCompute table.
Before you begin, ensure that you have met the following requirements:
The new Data Studio is enabled in your workspace.
A serverless resource group has been created. Running Notebooks in the production environment requires a serverless resource group.
A personal development environment instance has been created. If your Notebook contains Python cells, a personal development environment instance is required to run and debug them in the development environment.
If you have not created one yet, see Create a personal development environment instance.
Steps:
Create a Notebook node
Go to Data Studio. Under Data Development in Workspace Directories, create a Notebook node.
Name the Notebook (for example,
hello_notebook) and submit it.
Select a personal development environment
In the top navigation bar, click Personal Development Environment and select your personal development environment instance from the drop-down list.
Write a Python cell to define a variable
Add a Python cell and enter the following code. This step defines a city variable for the SQL query in the next step.
# Define a variable for subsequent SQL queries city = 'Beijing' print(f"Defined city variable city = {city}")Write an SQL cell to query data
Below the first cell, add an SQL cell.
In the lower-right corner of the cell, switch the SQL type to
MaxCompute SQL.Enter the following SQL code. The code references the
cityvariable defined in the previous Python cell by using the${city}syntax.-- Query using the variable defined in Python SELECT '${city}' AS city;
Run all cells and verify the output
Click Run All in the Notebook toolbar.
Observe the output of each cell:
The Python cell prints
Defined city variable city = Beijing.The SQL cell displays the query result in a table below it.
You have created and run a Notebook that passes data between Python and SQL.
Key concepts
Understanding the following key concepts helps you ensure consistent behavior when moving Notebooks from development to production.
Notebook modes
DataWorks Notebook supports two modes:
SQL and Markdown mode: Contains only SQL and Markdown cells. This mode is suitable for pure data querying and documentation. In this mode, only a serverless resource group is required to run in both the development and production environments — no personal development environment instance is needed. This is the default mode, and the Notebook displays SQL Kernel in the upper-right corner.
Full mode (Python + SQL + Markdown): Supports mixed use of Python, SQL, and Markdown cells. This mode is suitable for complex scenarios that require data processing, analysis, and visualization. In the development environment, a personal development environment instance is required to execute Python code. After you select a personal development environment, the upper-right corner of the Notebook displays
 (the Python version is for reference only).
(the Python version is for reference only).
Development environment vs. production environment
Aspect | Development environment | Production environment |
Runtime | Personal development environment instance | The Resource Group and Image specified in schedule settings |
Key differences | For Notebooks that contain Python cells, a dedicated personal development instance is used. You can freely install Python libraries in this instance for debugging. For Notebooks that contain only SQL and Markdown cells, only a serverless resource group is required. | Whether tasks are periodically scheduled through Operation Center or manually triggered as workflow runs in Data Studio, they run on the resource group specified in the schedule settings. The environment (such as dependency libraries and network) is entirely determined by the image and resource group configuration you select. |
How to ensure consistency | If you installed Python packages by using pip install or similar methods in your personal development environment instance, you need to build a DataWorks image from your personal development environment and select that custom image in the schedule settings to ensure the production environment has the same dependencies as the development environment. Important Network connectivity notes: When a personal development environment is not associated with a VPC, it is bound to a random public IP address with limited bandwidth by default and can access the Internet directly. However, Notebook nodes deployed to the production environment use the network of the resource group configured in the schedule settings. We recommend that you associate the personal development environment with the same resource group used in the schedule settings to keep the network configuration consistent. | |
Compute resources and kernels
In DataWorks Notebook, code execution is determined by two core concepts: compute resources and kernels.
Compute resource: A compute resource is the backend compute engine that ultimately executes and processes data tasks. It defines the runtime environment, computing power, and execution logic for tasks.
Definition: An independent, schedulable compute service instance, such as a MaxCompute project or an EMR Serverless Spark cluster.
Purpose: Provides the actual computing power for SQL queries, Spark jobs, and other tasks.
Selection: You must explicitly associate a task with a specific compute resource before execution.
Kernel: A kernel is the component in the Notebook environment that parses and executes the code you write in a cell. It determines the programming language accepted by the cell.
Python kernel:
Functionality: Executes code written in Python. Supports complex logic such as data processing, algorithm implementation, and task scheduling.
Interaction mode: In the Python kernel, you can use
Magic Command(such as%sql) or SDK libraries to submit packaged compute tasks (such as SQL statements) to a specified compute resource for execution and retrieve the results for further analysis.
SQL kernel:
Functionality: Directly interprets and submits SQL queries.
Interaction mode: The SQL kernel forwards SQL statements directly to the backend compute resource (such as EMR Spark SQL or MaxCompute SQL Session) that you specify for the cell.
Markdown kernel:
Functionality: Renders rich-text documents in Markdown format. Does not execute any computation logic.
Summary:
A kernel is the frontend language interpreter that determines what you write (Python or SQL).
A compute resource is the backend execution engine that determines where code runs (on MaxCompute or Spark).
Directory types and use cases
The location where you create a Notebook determines its collaboration model, permissions, and deployment process.
Directory type | Use case | Collaboration and deployment |
Workspace directories | Team collaboration and periodic production tasks. Nodes in this directory are shared across the workspace and follow the standard development, submission, and deployment process. | Supports multi-user collaboration. Nodes must be deployed to the production environment before they can be periodically scheduled. |
Personal directories | Personal development and debugging. This directory is invisible to other workspace members and is used for personal scripts and temporary tasks. | Visible only to you. To be scheduled, you must first submit nodes to workspace directories and then deploy them. |
Develop and debug Notebooks
Data Studio does not auto-save by default. Save your work manually on a regular basis to avoid losing code. You can also enable auto-save in the Data Studio editor by going to Settings > Files: Auto Save.
If the Notebook becomes unresponsive or hangs during execution, click Restart in the toolbar to restart the Notebook kernel.
Cell management
Add a cell: Hover over the top or bottom edge of an existing cell and click the + SQL button that appears. You can also use the buttons in the top toolbar.
Switch the cell type: Click the type label in the lower-right corner of a cell (for example,
Python) and select a new type from the menu, such asSQLorMarkdown. The code in the cell is preserved when you switch types. You must manually update it to match the new type.Move a cell: Hover over the blue vertical bar on the left side of a cell, then hold and drag to reorder.
Run a cell:
Run a single cell: Click the Run button on the left side of the cell.
Run all cells: Click the Run All button in the Notebook toolbar.
Variable passing
Pass Python variables to SQL
Variables defined in a Python cell can be directly referenced in subsequent SQL cells by using the ${variable_name} format.
Example:
Python cell
table_name = "dwd_user_info_d" limit_num = 10SQL cell
SELECT * FROM ${table_name} LIMIT ${limit_num};
Pass SQL results to Python
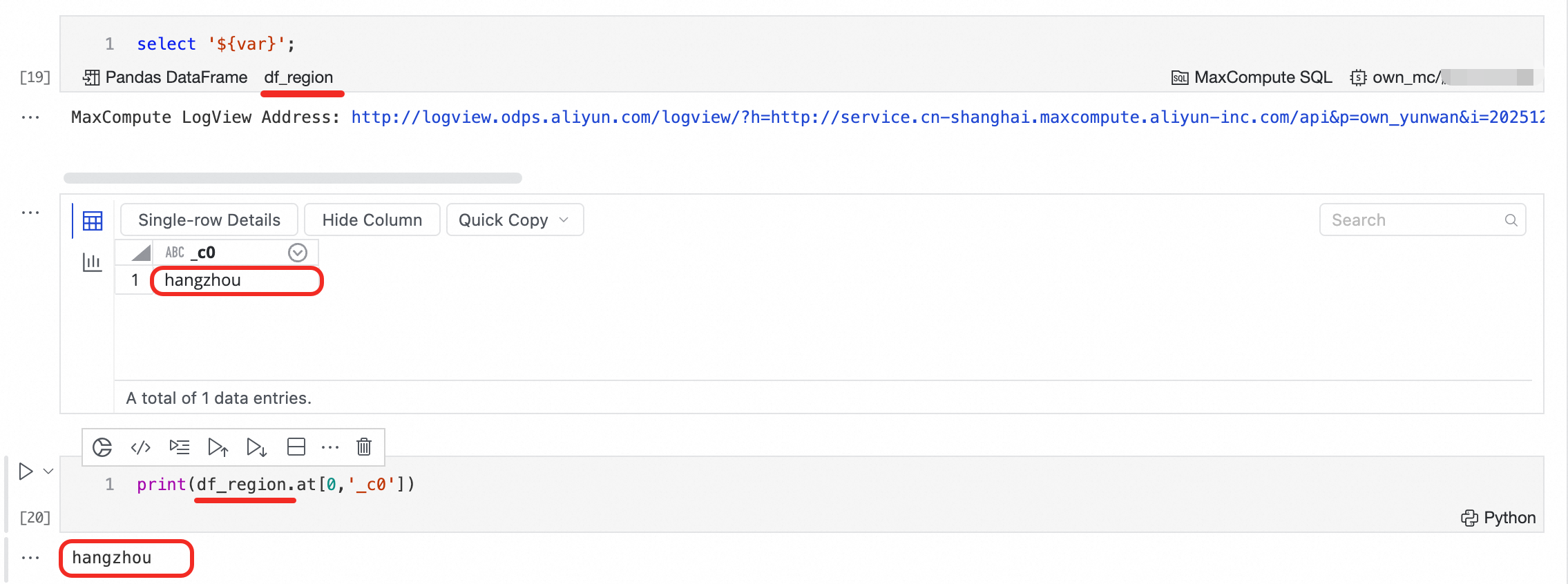
When an SQL cell executes a SELECT query, the result automatically generates a DataFrame variable that can be used in subsequent Python cells.
If multiple SQL statements exist, only the result of the last SQL statement is stored in the DataFrame variable.
Variable naming: The default variable name starts with
df_. You can click the variable name in the lower-left corner of the SQL cell to rename it.Variable type:
If multiple variable types are supported, click DataFrame in the lower-left corner to switch the type.
For MaxCompute SQL,
Pandas DataFrameandMaxCompute MaxFrameobjects are supported.For ADB Spark SQL,
Pandas DataFrameandPySpark MaxFrameobjects are supported.For other SQL types, the generated object is a
Pandas DataFrame.
Example:
View lineage (beta)
Supported regions: China (Hangzhou), China (Shanghai), China (Beijing), China (Zhangjiakou), China (Ulanqab), China (Shenzhen), China (Chengdu), and China (Hong Kong).
When Notebook code becomes complex and involves reading from and writing to multiple tables or files, understanding data flow can be difficult. The lineage analysis feature statically parses Python code in Notebooks (with support for the MaxFrame framework) to help you quickly trace data origins and destinations.
Procedure
In the Notebook toolbar, click the Lineage button. The system automatically parses the code in all cells of the current Notebook and displays a lineage graph below.
Lineage analysis is based on static parsing of Notebook code. It reflects the data logic described in the code, not the actual data flow after task execution. Therefore, you can view lineage without running the code.
This feature is currently intended for development and debugging. The analyzed lineage is not automatically reported to Data Map.
If you modify the code, click Lineage or Refresh again to obtain the latest lineage graph.
Supported scenarios
The lineage analysis feature currently supports only the following scenarios:
Lineage between MaxCompute tables: When you read data from one or more MaxCompute tables, process it with MaxFrame, and then write the results to another MaxCompute table, the system clearly displays the processing relationships between tables.
For example, you can join an order table (ods_order) with a shop dimension table (dim_shop) and write the results to an order wide table (dwd_order).
Lineage between MaxCompute tables and external data: When your code processes interactions between MaxCompute tables and external data (such as associated datasets or OSS files), lineage analysis clearly displays the relationships between them.
Through associated datasets: When your code accesses an associated dataset through the mount path of a personal development environment (such as
/mnt/data/) and exchanges data with MaxCompute tables (for example, reading data from a dataset and writing it to a table, or reading from a table and writing to a dataset), the lineage graph shows the complete data pipeline between the two.Through OSS paths: Even if you have not associated a dataset, lineage analysis can identify the bidirectional data flow between OSS storage paths and MaxCompute tables when you directly read from or write to files through OSS paths in your code.
NoteIf the OSS path happens to be registered as a dataset in Data Map, the lineage graph automatically displays it as a dataset node to help you better manage your data assets.
Copilot-assisted programming
DataWorks Copilot is a built-in intelligent programming assistant that helps you generate and explain code.
How to invoke Copilot:
Click the Copilot
 icon in the upper-left corner of the selected cell.
icon in the upper-left corner of the selected cell.Right-click inside an SQL cell and select Copilot.
Use the keyboard shortcut
Cmd+I(Mac) orCtrl+I(Windows).
Schedule and deploy Notebooks
To run a Notebook on a periodic schedule, you must configure schedule settings and deploy it to the production environment.
Step 1: Configure scheduling parameters (parameterized scheduling)
If you want the parameters in a Notebook to change dynamically for each scheduled run (for example, processing data from different partitions on a daily basis), configure parameterized scheduling.
Mark a parameter cell: In the Python cell that contains key parameter definitions, click the
...menu in the upper-right corner and select Mark Cell as Parameters. Aparameterstag is added to the cell, indicating that it is the parameter entry point for the scheduled task.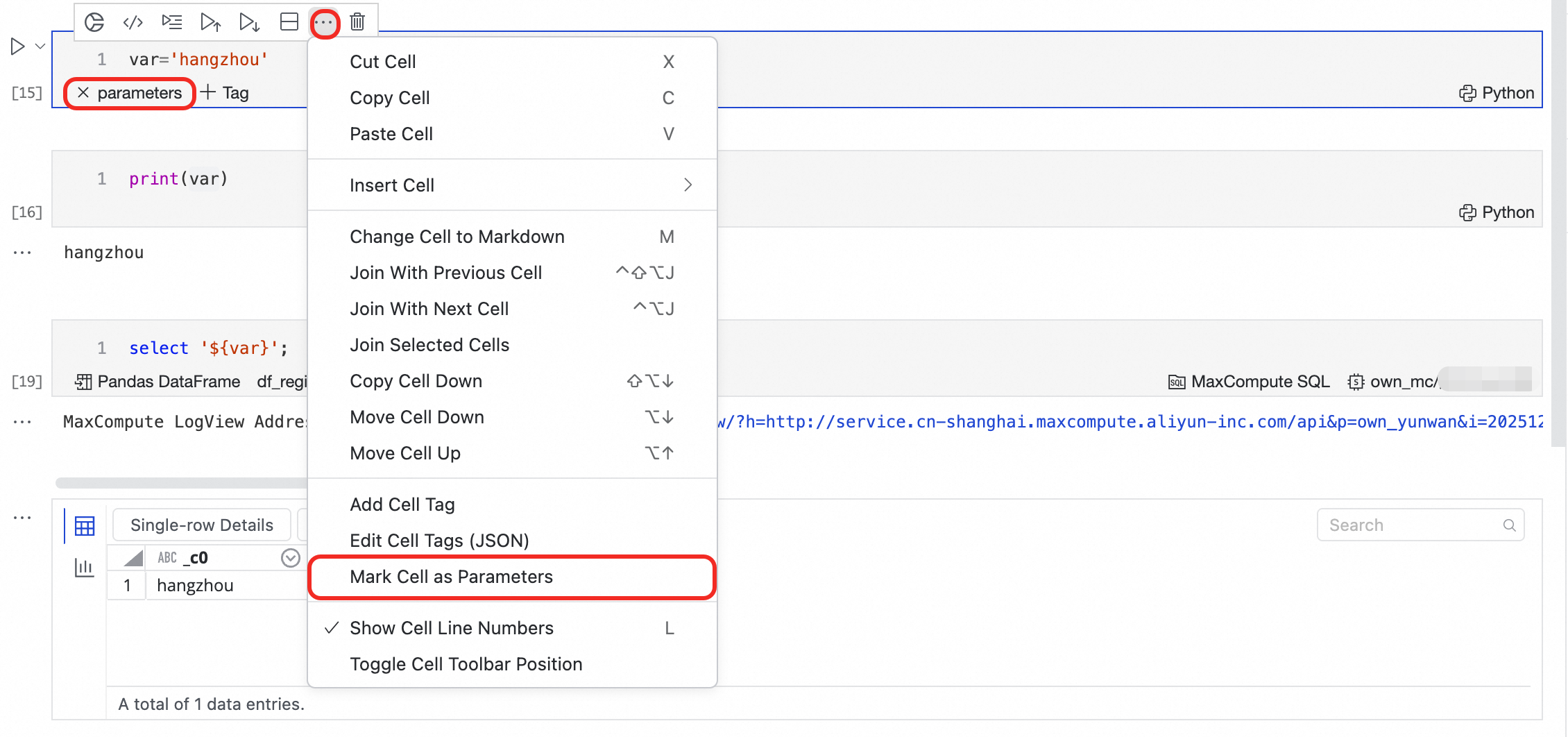
Configure scheduling parameters:
In the right-side panel of the Notebook, click Schedule Settings.
In the Scheduling Parameters section, assign values to the variables you defined in the code (such as
var).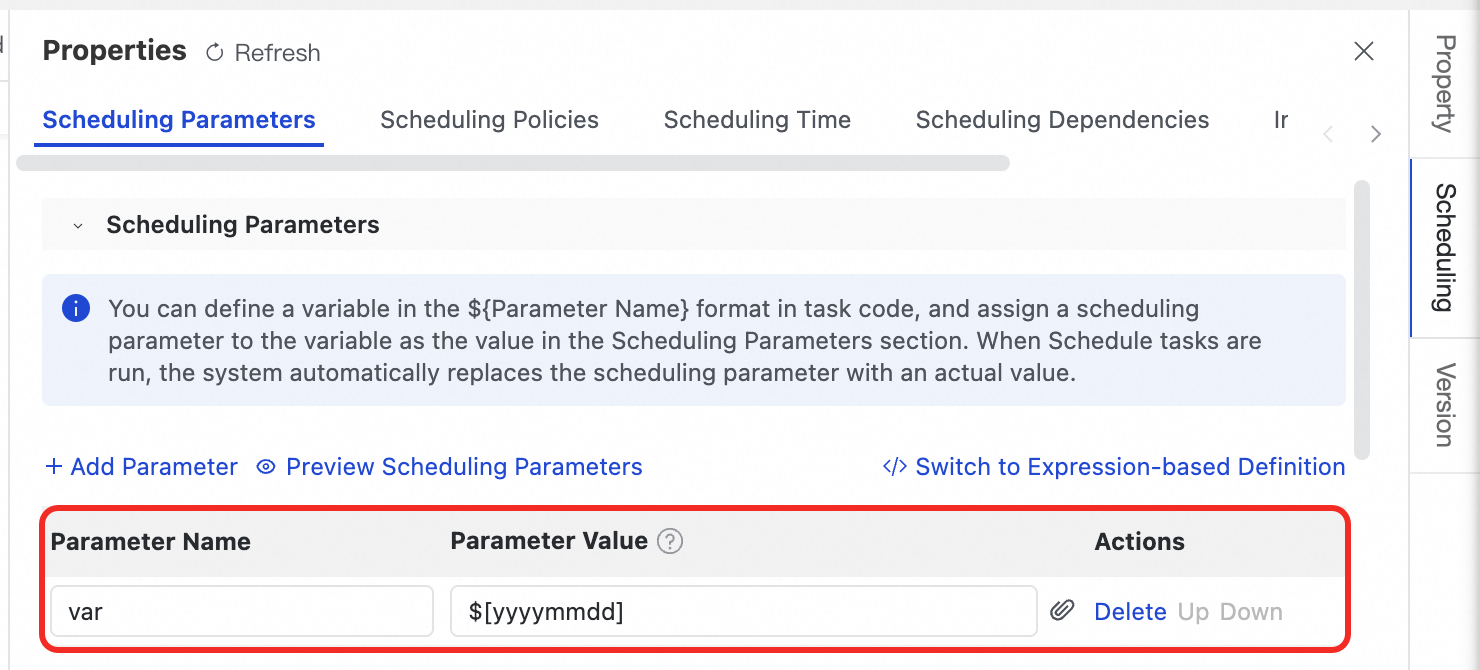
When the task is automatically executed by the scheduling system, the actual value of the var parameter in the code is dynamically replaced with the value configured in the scheduling parameters.
Step 2: Configure the runtime environment and resources
Configure an image: In the schedule settings, select an image that contains all dependencies required by the Notebook. This is critical to ensuring successful execution in the production environment.
ImportantIf you installed Python packages by using pip install or similar methods in your personal development environment instance, you need to build a DataWorks image from your personal development environment and select that custom image in the schedule settings to ensure the production environment has the same dependencies as the development environment.
Configure a resource group: Select the resource group for task execution. For serverless resource groups, we recommend that you configure no more than
16CUto avoid task startup failures caused by insufficient resources. The maximum supported for a single task is64CU.Configure an associated role: For fine-grained access control, you can associate a specific RAM role with the node so that it runs under that role identity. For more information, see Configure an associated role for a node.
Step 3: Deploy the node
Only nodes in workspace directories can be deployed and periodically scheduled.
For Notebooks in workspace directories: After you complete the configuration, click Deploy in the top toolbar.
For Notebooks in personal directories: Click Save first to Submit to Workspace Directory, and then deploy the node.
After successful deployment, you can monitor and manage your Notebook tasks on the Scheduled Tasks page in Operation Center.
FAQ
Q: Why can my code access the Internet during development but fails during scheduled runs?
A: This is because the development environment and the production environment have different network policies.
Development environment (personal development environment): For debugging convenience, when a VPC is not configured, the personal development environment instance provides limited Internet access by default so that you can temporarily install packages or call APIs.
Production environment (scheduled tasks): For security and stability, tasks run in a VPC by default and cannot directly access the Internet. The network configuration is determined by the resource group you select in Schedule Settings. If the VPC of the resource group does not have an Internet NAT Gateway configured, Internet access is unavailable.
Solution: Ensure that the personal development environment instance and the serverless resource group are configured with the same VPC.
Q: Why does my code run successfully in the development environment but fail to find third-party packages during scheduled runs?
A: Ensure that all dependency packages (such as Python libraries) have been built into a custom image in advance and that the image is specified in Schedule Settings. For more information, see Build a DataWorks image from your personal development environment.
Q: How do I switch the Python kernel version?
A: You can manually install the desired Python version in the terminal
 of the personal development environment, and then click
of the personal development environment, and then click  on the right side of the Notebook toolbar to switch to another Python kernel version. We do not recommend installing additional Python kernels because new versions lack the dependencies required by SQL cells and cannot function properly.
on the right side of the Notebook toolbar to switch to another Python kernel version. We do not recommend installing additional Python kernels because new versions lack the dependencies required by SQL cells and cannot function properly.