For online knowledge base Q&A scenarios, AI Search Open Platform provides a complete RAG development pipeline. This pipeline includes three main modules: data pre-processing, retrieval service, and Q&A summary generation. AI Search Open Platform componentizes the algorithm services available for each module. You can flexibly select services for each module, such as document parsing, sorting, and Q&A summary services, to quickly generate development code. AI Search Open Platform exposes services as APIs. Developers can download the code locally and then replace information such as the API key, API endpoint, and local knowledge base, following the steps in this topic. This lets you quickly build a knowledge base Q&A application based on the RAG development pipeline.
Technical principles
Retrieval-Augmented Generation (RAG) is an artificial intelligence method that combines retrieval and generation technologies. It aims to improve the relevance, accuracy, and diversity of content generated by models. When processing generation tasks, RAG first retrieves the most relevant segments for the input from large amounts of external data or knowledge bases. It then feeds the retrieved information along with the original input into a Large Language Model (LLM) as a prompt or context. This guides the model to generate more precise and rich answers. This method allows the model to rely not only on its internal parameters and training data when generating responses, but also to use external, up-to-date, or domain-specific information to improve answer accuracy.
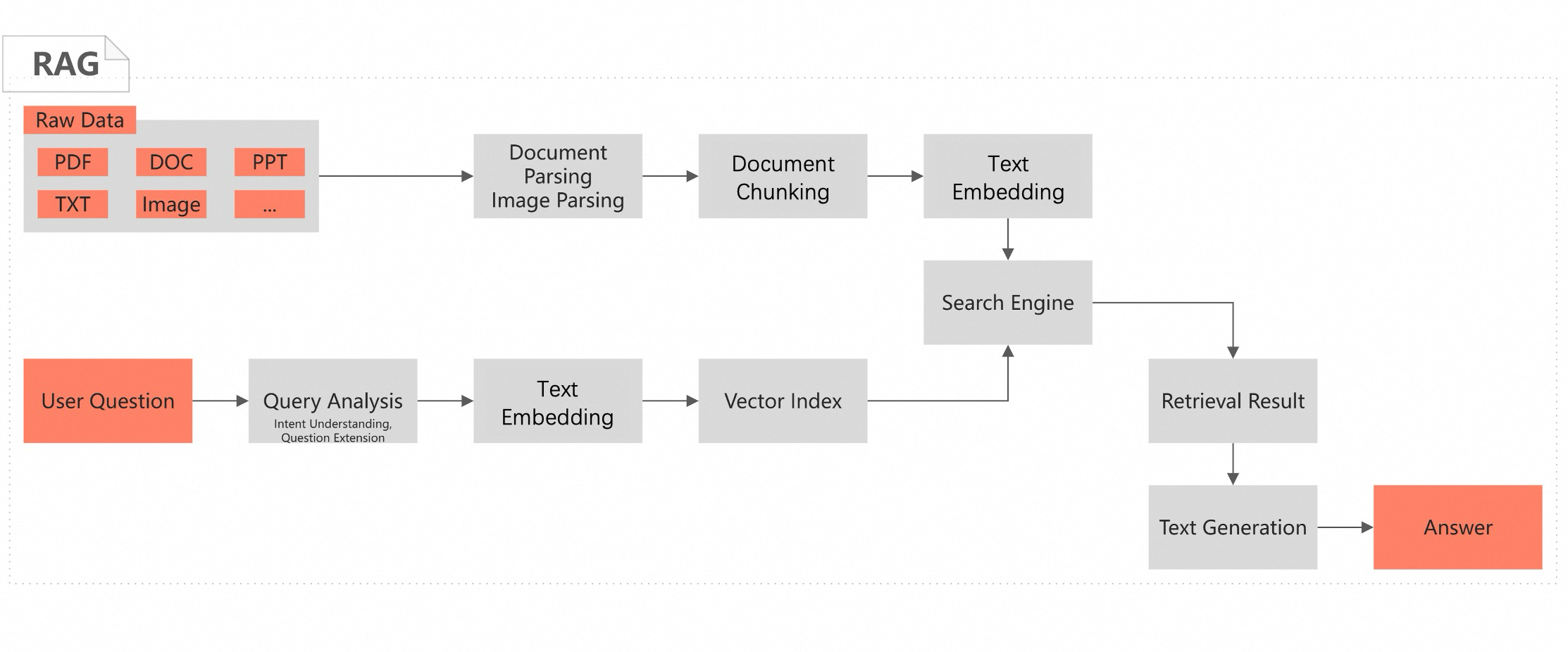
Scenarios
Knowledge base online Q&A is often used in business scenarios such as enterprise internal knowledge base retrieval and summarization, and online Q&A in vertical domains. Leveraging customers' professional knowledge base documents, Retrieval-Augmented Generation (RAG) technology and Large Language Models (LLM) can understand and respond to complex natural language queries. This helps enterprise customers quickly retrieve information from PDF, Word, table, and image documents using natural language.
Prerequisites
-
Activate AI Search Open Platform. For more information, see Activate Service.
-
Obtain the service endpoint and authentication information. For more information, see Obtain Service Endpoint and Obtain API Key.
AI Search Open Platform supports service invocation via public network and VPC endpoints. VPC enables cross-region service invocation. Currently, users in Shanghai, Hangzhou, Shenzhen, Beijing, Zhangjiakou, and Qingdao regions can invoke AI Search Open Platform services via VPC endpoints.

-
Create an Alibaba Cloud Elasticsearch (ES) instance. ES 8.5 or later is required. For more information, see Create an Alibaba Cloud Elasticsearch Instance. When accessing an Alibaba Cloud ES instance via a public or private network, add the IP address of the device to the instance's access whitelist. For more information, see Configure a Public or Private Network Access Whitelist for an Instance.
-
Use Python 3.7 or later. In your development environment, install the Python package dependencies `aiohttp 3.8.6` and `elasticsearch 8.14`.
Build the RAG development pipeline
For ease of use, AI Search Open Platform provides four types of development frameworks:
-
Java SDK.
-
Python SDK.
-
If your business already uses the LangChain development framework, select LangChain.
-
If your business already uses the LlamaIndex development framework, select LlamaIndex.
Step 1: Select services and download code
Based on your knowledge base and business needs, select the algorithm services and development framework required in the RAG pipeline. This topic uses the Python SDK development framework as an example to describe how to build the RAG pipeline.
-
Log on to the AI Search Open Platform console.
-
Select the Shanghai region, switch to AI Search Open Platform, and switch to the target workspace.
Note-
Currently, AI Search Open Platform is available only in the China (Shanghai) and Germany (Frankfurt) regions.
-
Users in the China (Hangzhou), China (Shenzhen), China (Beijing), China (Zhangjiakou), and China (Qingdao) regions can invoke AI Search Open Platform services across regions using VPC endpoints.
-
-
In the navigation pane on the left, select Scenario Center. To the right of RAG Scenario - Knowledge Base Online Q&A, click Enter.
-
Based on the service information and business requirements, select the required service from the drop-down list. The Service Details page displays detailed information about the service.
Note-
When invoking algorithm services in the RAG pipeline via API, provide the service ID (service_id). For example, the ID for the document content parsing service is ops-document-analyze-001.
-
After switching services from the service list, the service_id in the generated code updates synchronously. After downloading the code to your local environment, you can still change the service_id to invoke the corresponding service.
Stage
Service Description
Document Content Parsing
Document Content Parsing Service (ops-document-analyze-001): Provides a general document parsing service. It supports extracting logical hierarchical structures such as titles and paragraphs from unstructured documents (text, tables, images, etc.) and outputs them in a structured format.
Image Content Parsing
-
Image Content Recognition Service (ops-image-analyze-vlm-001): Parses and understands image content and recognizes text based on multimodal Large Language Models. The parsed text can be used for image retrieval Q&A scenarios.
-
Image Text Recognition Service (ops-image-analyze-ocr-001): Uses OCR capabilities for image text recognition. The parsed text can be used for image retrieval Q&A scenarios.
Document Segmentation
Document Segmentation Service (ops-document-split-001): Provides a general text segmentation service. It supports splitting structured data in HTML, Markdown, and TXT formats based on document paragraphs, text semantics, and specified rules. It also supports extracting code, images, and tables from documents as rich text.
Text Embedding
-
OpenSearch Text Embedding Service-001 (ops-text-embedding-001): Provides multilingual (40+) text embedding services. The maximum input text length is 300, and the output vector dimension is 1536.
-
OpenSearch General Text Embedding Service-002 (ops-text-embedding-002): Provides multilingual (100+) text embedding services. The maximum input text length is 8192, and the output vector dimension is 1024.
-
OpenSearch Text Embedding Service-Chinese-001 (ops-text-embedding-zh-001): Provides Chinese text embedding services. The maximum input text length is 1024, and the output vector dimension is 768.
-
OpenSearch Text Embedding Service-English-001 (ops-text-embedding-en-001): Provides English text embedding services. The maximum input text length is 512, and the output vector dimension is 768.
Text Sparse Embedding
Provides a service to convert text data into sparse vector representation. Sparse vectors require less storage space and are often used to express keywords and term frequency information. Combine them with dense vectors for hybrid retrieval to improve retrieval effectiveness.
OpenSearch Text Sparse Embedding Service (ops-text-sparse-embedding-001): Provides multilingual (100+) text embedding services. The maximum input text length is 8192.
Query Analysis
Query Analysis Service 001 (ops-query-analyze-001) provides a general query analysis service. It uses Large Language Models to understand the intent of user queries and expand similar questions.
Search Engine
-
Alibaba Cloud Elasticsearch: A fully managed cloud service built on open-source Elasticsearch. It is 100% compatible with open-source features and supports out-of-the-box use and pay-as-you-go billing.
NoteWhen selecting Alibaba Cloud Elasticsearch as the search engine service, the text sparse embedding service is unavailable due to compatibility issues. Use text embedding-related services instead.
-
OpenSearch Vector Search Edition is a large-scale distributed vector search engine independently developed by Alibaba. It supports various vector retrieval algorithms, offers excellent performance with high accuracy, and enables cost-effective large-scale index building and retrieval. Additionally, the index supports horizontal scaling and merging, stream-based index building, real-time indexing and querying, and dynamic data updates.
NoteTo use the OpenSearch Vector Search Edition engine solution, replace the engine configuration and code in the RAG pipeline.
Sorting Service
BGE Rerank Model (ops-bge-reranker-larger): A general document scoring service. It sorts documents by relevance to the query, from highest to lowest score, and outputs the scoring results.
Large Language Model
-
OpenSearch-Qwen-Turbo (ops-qwen-turbo): Uses the Qwen-Turbo large language model as its base, with supervised model fine-tuning to enhance retrieval augmentation and reduce harmfulness.
-
Qwen-Turbo (qwen-turbo): A Qwen ultra-large language model that supports input in various languages, including Chinese and English. For more information, see Introduction to Qwen Large Language Models.
-
Qwen-Plus (qwen-plus): An enhanced version of the Qwen ultra-large language model that supports input in various languages, including Chinese and English. For more information, see Introduction to Qwen Large Language Models.
-
Qwen-Max (qwen-max): A Qwen hundred-billion-parameter ultra-large language model that supports input in various languages, including Chinese and English. For more information, see Introduction to Qwen Large Language Models.
-
-
Click Configuration Complete, View Code to view and download the code.
The code is divided into two parts: offline document processing and online user Q&A processing. This division aligns with the application's runtime flow when invoking the RAG pipeline:
Process
Function
Description
Offline Document Processing
Handles document processing, including document parsing, image extraction, segmentation, embedding, and writing document processing results to an ES index.
Use the main function `document_pipeline_execute` to complete the following process. You can input documents to be processed via document URL or Base64 encoding.
-
Document parsing. For service invocation, see Document Parsing API.
-
Invoke the asynchronous document parsing API to extract document content from a document URL or decode it from a Base64 encoded file.
-
Construct a parsing task using the `create_async_extraction_task` function and poll the task completion status using the `poll_task_result` function.
-
-
Image extraction. For service invocation, see Image Content Extraction API.
-
Invoke the asynchronous image parsing API to extract image content from an image URL or decode it from a Base64 encoded file.
-
Create an image parsing task using the `create_image_analyze_task` function and get the image parsing task status using the `get_image_analyze_task_status` function.
-
-
Document segmentation. For service invocation, see Document Segmentation API.
-
Invoke the document segmentation API to segment the parsed document according to a specified strategy.
-
Perform document segmentation using the `document_split` function, which includes document segmentation and rich text content parsing.
-
-
Text embedding. For service invocation, see Text Embedding API.
-
Invoke the text dense vector representation API to embed the segmented text.
-
Calculate the embedding vector for each segment using the `text_embedding` function.
-
-
Write to ES. For service invocation, see Use the kNN Feature of Elasticsearch for Vector Nearest Neighbor Search.
-
Create ES index configuration, including specifying the vector field `embedding` and document content field `content`.
ImportantWhen creating an ES index, the system deletes existing indexes with the same name. To avoid accidentally deleting indexes with the same name, change the index name in the code.
-
Batch write embedding results to the ES index using the `helpers.async_bulk` function.
-
Online Q&A Processing
Handles user online queries, including generating query vectors, query analysis, retrieving relevant document segments, sorting retrieval results, and generating answers based on retrieval results.
Use the main function `query_pipeline_execute` to complete the following process, which processes user queries and outputs answers.
-
Query embedding. For service invocation, see Text Embedding API.
-
Invoke the text dense vector representation API to convert user queries into vectors.
-
Generate query vectors using the `text_embedding` function.
-
-
Invoke the query analysis service. For more information, see Query Analysis API.
Invoke the query analysis API to identify user query intent and generate similar questions by analyzing historical messages.
-
Search embedding segments. For service invocation, see Use the kNN Feature of Elasticsearch for Vector Nearest Neighbor Search.
-
Use ES to retrieve document segments in the index that are similar to the query vector.
-
Perform similarity retrieval using the `AsyncElasticsearch` search API in conjunction with kNN queries.
-
-
Invoke the sorting service. For more information, see Sorting API.
-
Invoke the sorting service API to score and sort the retrieved relevant segments.
-
Score and sort document content based on user queries using the `documents_ranking` function.
-
-
Invoke the Large Language Model to generate answers. For service invocation, see Answer Generation API.
Invoke the Large Language Model service to generate the final answer using retrieval results and user queries via the `llm_call` function.
Select the Document Processing Flow and Online Q&A Flow under Code Query, and click Copy Code or Download File to download the code to your local machine.
-
Step 2: Adapt to local environment and test the RAG development pipeline
After downloading the code to two local files, such as `online.py` and `offline.py`, configure key parameters in the code.
|
Category |
Parameter |
Description |
|
AI Search Open Platform |
api_key |
API key. For more information, see Manage API Key. |
|
aisearch_endpoint |
API endpoint. For more information, see Obtain Service Endpoint. Note
Remove "http://." Supports API invocation via public network and VPC. |
|
|
workspace_name |
AI Search Open Platform |
|
|
service_id |
Service ID. For convenience, configure services and their IDs using `service_id_config` in both the offline document processing (`offline.py`) and online Q&A processing (`online.py`) code.
|
|
|
ES Search Engine |
es_host |
Elasticsearch (ES) instance endpoint. When accessing an Alibaba Cloud ES instance via public or private network, add the IP address of the device to be accessed to the instance's access whitelist. For more information, see Configure a Public or Private Network Access Whitelist for an Instance. |
|
es_auth |
Username and password for accessing the Elasticsearch instance. The username is `elastic`, and the password is the one you set when creating the instance. If you forget the password, reset it. For specific operations, see Reset Instance Access Password. |
|
|
Other Parameters |
No modification is needed if you use sample data. |
|

After configuring the parameters, in a Python 3.7 or later environment, run the `offline.py` offline document processing file and the `online.py` online Q&A processing file sequentially to test whether the results are correct.
For example, if the knowledge base document is Introduction to AI Search Open Platform, ask the document: What can AI Search Open Platform do?
The running results are as follows:
-
Offline document processing results
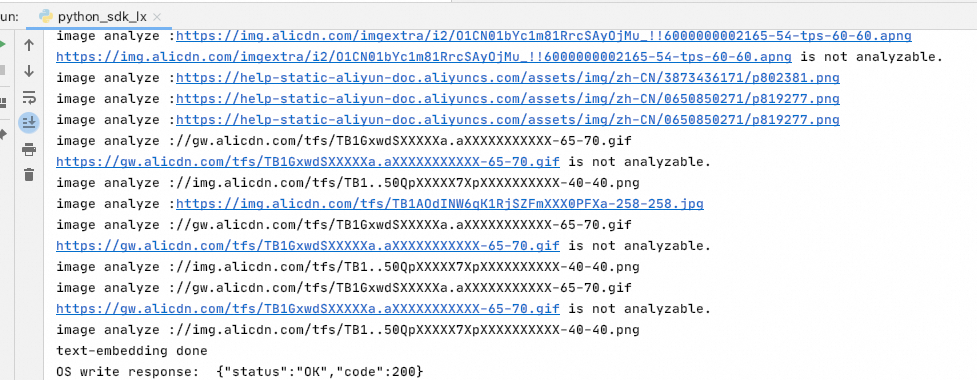
-
Online Q&A processing results

-
View source files
FAQ
During code execution, "Unclosed connector" warnings may appear because resources are not released promptly. No action is needed.