This topic describes how to use a PyODPS node to read data from the level-1 partition of the specified table.
Prerequisites
The following operations are performed:
MaxCompute is activated. For more information, see Activate MaxCompute.
DataWorks is activated. For more information, see Purchase guide.
A workflow is created in the DataWorks console. In this example, a workflow is created for a DataWorks workspace in basic mode. For more information, see Create a workflow.
Procedure
This example uses the basic mode of DataWorks. When creating a workspace, by default, Participate in Public Preview of Data Studio is not enabled, and this example does not apply to workspaces participating in the Data Studio public preview.
Prepare test data.
Create a partitioned table and a source table, and import data to the source table. For more information, see Create tables and upload data.
In this example, use the following table creation statements and source data.
Execute the following statement to create a partitioned table named user_detail:
create table if not exists user_detail ( userid BIGINT comment 'user ID', job STRING comment 'job type', education STRING comment 'education level' ) comment 'user information table' partitioned by (dt STRING comment 'date',region STRING comment 'region');Execute the following statement to create a source table named user_detail_ods:
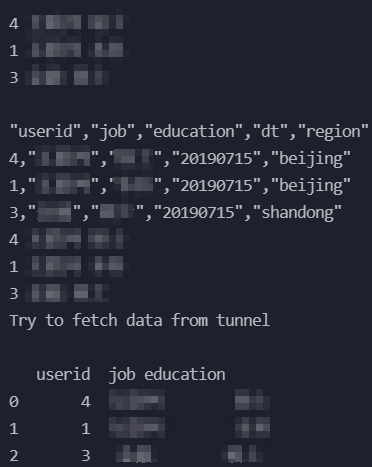
create table if not exists user_detail_ods ( userid BIGINT comment 'user ID', job STRING comment 'job type', education STRING comment 'education level', dt STRING comment 'date', region STRING comment 'region' );Create a source data file named user_detail.txt and save the following data to the file. Import the data to the user_detail_ods table.
0001,Internet,bachelor,20190715,beijing 0002,education,junior college,20190716,beijing 0003,finance,master,20190715,shandong 0004,Internet,master,20190715,beijing
Right-click the workflow and choose .
In the Create Node dialog box, specify Name and click Confirm.
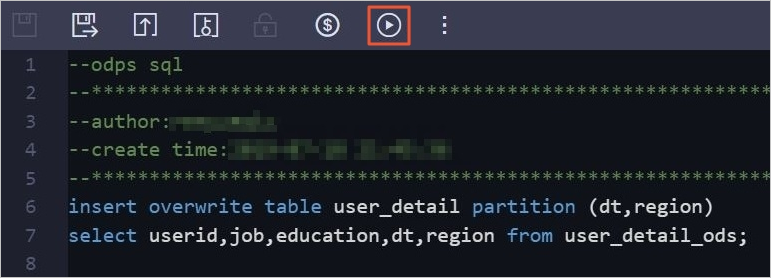
On the configuration tab of the ODPS SQL node, enter the following code in the code editor:
insert overwrite table user_detail partition (dt,region) select userid,job,education,dt,region from user_detail_ods;Click the Run icon in the toolbar to insert the data from the user_detail_ods table into the user_detail partitioned table.
Use a PyODPS node to read data from the level-1 partition of the user_detail table.
Log on to the DataWorks console.
In the left-side navigation pane, click Workspace.
Find your workspace, and choose in the Actions column.
On the DataStudio page, right-click the created workflow and choose .
In the Create Node dialog box, specify Name and click Confirm.
On the configuration tab of the PyODPS 2 node, enter the following code in the code editor:
import sys reload(sys) # Set UTF-8 as the default encoding format. sys.setdefaultencoding('utf8') # Read data from the level-1 partition in asynchronous mode. instance = o.run_sql('select * from user_detail WHERE dt=\'20190715\'') instance.wait_for_success() for record in instance.open_reader(): print record["userid"],record["job"],record["education"] # Read data from the level-1 partition in synchronous mode. with o.execute_sql('select * from user_detail WHERE dt=\'20190715\'').open_reader() as reader4: print reader4.raw for record in reader4: print record["userid"],record["job"],record["education"] # Use the PyODPS DataFrame to read data from the level-1 partition. pt_df = DataFrame(o.get_table('user_detail').get_partition('dt=20190715')) print pt_df.head(10)Click the Run icon in the toolbar.
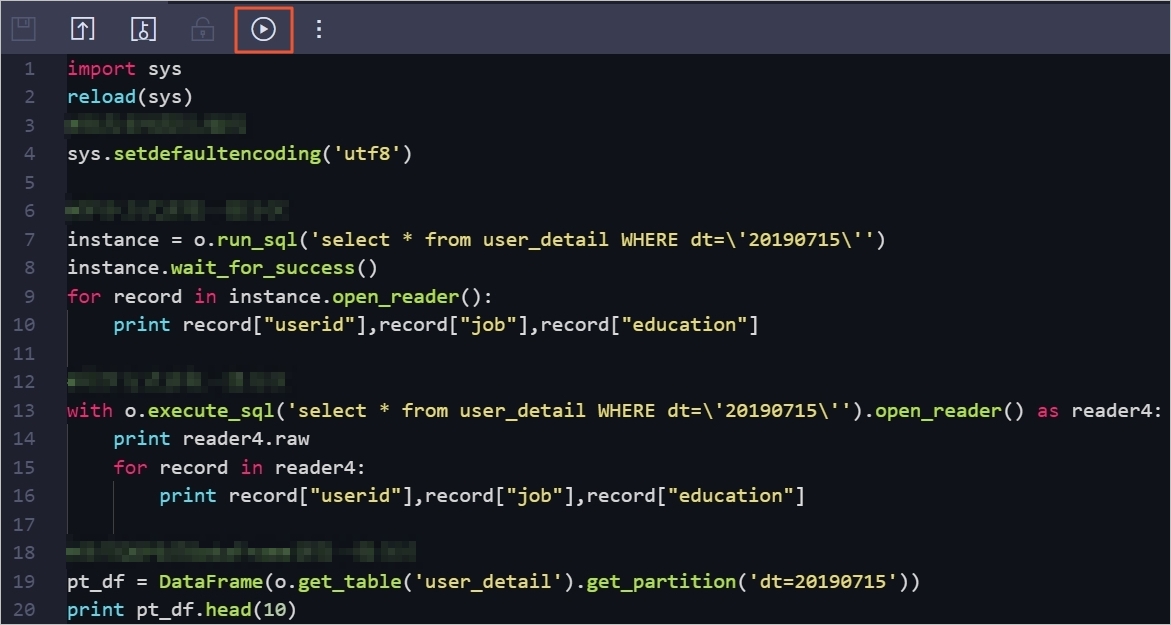
View the running result of the PyODPS 2 node on the Run Log tab.