This topic describes how to write a user-defined aggregate function (UDAF) in Java.
UDAF code structure
You can use Maven in IntelliJ IDEA or MaxCompute Studio to write a UDAF in Java. The UDAF code can contain the following information:
Java package: optional.
You can package Java classes that are defined into a JAR file for future use.
Base UDAF classes: required.
The required UDAF classes are
com.aliyun.odps.udf.Aggregatorandcom.aliyun.odps.udf.annotation.Resolve. The com.aliyun.odps.udf.annotation.Resolve class corresponds to the@Resolveannotation.com.aliyun.odps.udf.UDFException: optional. This class corresponds to the methods that are used to initialize and terminate Java classes. If you want to use other UDAF classes or complex data types, add the required classes by following the instructions provided in Overview.@Resolveannotation: required.The annotation is in the
@Resolve(<signature>)format. Thesignatureis a function signature that defines the data types of input parameters and the return values of a UDAF. UDAFs cannot obtain function signatures by using the reflection feature. You can obtain a function signature only by using a@Resolveannotation, such as@Resolve("smallint->varchar(10)"). For more information about the@Resolveannotation, see @Resolve annotations in this topic.Custom Java class: required.
A custom Java class is the organizational unit of UDAF code. This class defines the variables and methods that are used to meet your business requirements.
Methods to implement the custom Java class: required.
Java UDAFs must inherit the
com.aliyun.odps.udf.Aggregatorclass and implement the following methods:import com.aliyun.odps.udf.ContextFunction; import com.aliyun.odps.udf.ExecutionContext; import com.aliyun.odps.udf.UDFException; public abstract class Aggregator implements ContextFunction { // The initialization method. @Override public void setup(ExecutionContext ctx) throws UDFException { } // The terminate method. @Override public void close() throws UDFException { } // Create an aggregation buffer. abstract public Writable newBuffer(); // The iterate method. // The buffer is an aggregation buffer, which stores the data that is aggregated in a specific phase. The aggregated data refers to the dataset that is obtained after GROUP BY is performed for different Map tasks. One buffer is created for each row of data that is aggregated. // Writable[] indicates a row of data, which specifies the passed column in the code. For example, writable[0] indicates the first column, and writable[1] indicates the second column. // args specifies the parameters that are used to call a UDAF in SQL. It cannot be NULL, but the values in args can be NULL, which indicates that the input data is NULL. abstract public void iterate(Writable buffer, Writable[] args) throws UDFException; // The terminate method. abstract public Writable terminate(Writable buffer) throws UDFException; // The merge method. abstract public void merge(Writable buffer, Writable partial) throws UDFException; }The most important methods are
iterate,merge, andterminate. The methods are used to implement the main logic of the UDAF. In addition, you must implement a user-defined writable buffer.A user-defined writable buffer converts the objects in memory into byte sequences (or other data transmission protocols) for persistent storage in disks and network transmission. MaxCompute uses distributed computing to process UDAFs. Therefore, MaxCompute must serialize or deserialize data before the data can be transmitted between different devices.
When you write a Java UDAF, you can use Java data types or Java writable data types. For more information about the mappings among the data types that are supported by MaxCompute projects, Java data types, and Java writable data types, see Data types in this topic.
Sample code:
// Package the defined Java classes into a file named org.alidata.odps.udaf.examples.
package org.alidata.odps.udaf.examples;
// The base UDAF classes.
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import com.aliyun.odps.io.DoubleWritable;
import com.aliyun.odps.io.Writable;
import com.aliyun.odps.udf.Aggregator;
import com.aliyun.odps.udf.UDFException;
import com.aliyun.odps.udf.annotation.Resolve;
// The custom Java class.
// The @Resolve annotation.
@Resolve("double->double")
public class AggrAvg extends Aggregator {
// The methods that are used to implement the custom Java class.
private static class AvgBuffer implements Writable {
private double sum = 0;
private long count = 0;
@Override
public void write(DataOutput out) throws IOException {
out.writeDouble(sum);
out.writeLong(count);
}
@Override
public void readFields(DataInput in) throws IOException {
sum = in.readDouble();
count = in.readLong();
}
}
private DoubleWritable ret = new DoubleWritable();
@Override
public Writable newBuffer() {
return new AvgBuffer();
}
@Override
public void iterate(Writable buffer, Writable[] args) throws UDFException {
DoubleWritable arg = (DoubleWritable) args[0];
AvgBuffer buf = (AvgBuffer) buffer;
if (arg != null) {
buf.count += 1;
buf.sum += arg.get();
}
}
@Override
public Writable terminate(Writable buffer) throws UDFException {
AvgBuffer buf = (AvgBuffer) buffer;
if (buf.count == 0) {
ret.set(0);
} else {
ret.set(buf.sum / buf.count);
}
return ret;
}
@Override
public void merge(Writable buffer, Writable partial) throws UDFException {
AvgBuffer buf = (AvgBuffer) buffer;
AvgBuffer p = (AvgBuffer) partial;
buf.sum += p.sum;
buf.count += p.count;
}
}In the preceding UDAF code, the same buffer is used for the iterate and merge methods. You can aggregate input rows of data into this buffer based on the UDAF code.
Limits
Access the Internet by using UDFs
By default, MaxCompute does not allow you to access the Internet by using UDFs. If you want to access the Internet by using UDFs, fill in the network connection application form based on your business requirements and submit the application. After the application is approved, the MaxCompute technical support team will contact you and help you establish network connections. For more information about how to fill in the network connection application form, see Network connection process.
Access a VPC by using UDFs
By default, MaxCompute does not allow you to access resources in VPCs by using UDFs. To use UDFs to access resources in a VPC, you must establish a network connection between MaxCompute and the VPC. For more information about related operations, see Use UDFs to access resources in VPCs.
Read table data by using UDFs, UDAFs, or UDTFs
You cannot use UDFs, UDAFs, or UDTFs to read data from the following types of tables:
Table on which schema evolution is performed
Table that contains complex data types
Table that contains JSON data types
Transactional table
Usage notes
Before you write a Java UDAF, take note of the following points:
We recommend that you do not package classes that have the same name but different logic into the JAR files of different UDAFs. For example, the JAR file of UDAF 1 is named udaf1.jar and the JAR file of UDAF 2 is named udaf2.jar. Both JAR files contain a class named
com.aliyun.UserFunction.class, but the class has different logic in the files. If UDAF 1 and UDAF 2 are called in the same SQL statement, MaxCompute loads the com.aliyun.UserFunction.class from one of the two files. As a result, the UDAFs cannot run as expected and the compilation may fail.The data type of an input parameter or a return value in a Java UDAF is an object. The first letter of the data types that you specify in the Java UDAF code must be in uppercase, such as String.
NULL values in MaxCompute SQL are represented by NULL in Java. Primitive data types in Java cannot represent NULL values in MaxCompute SQL. Therefore, these data types cannot be used.
@Resolve annotations
@Resolve annotation format:
@Resolve(<signature>)The signature parameter is a string that specifies the data types of input parameters and return value. When you run a UDAF, the data types of input parameters and return value of the UDAF must be consistent with the data types specified in the function signature. The data type consistency is checked during semantic parsing. If the data types are inconsistent, an error is returned. Format of a signature:
'arg_type_list -> type'
arg_type_list: indicates the data types of input parameters. If multiple input parameters are used, specify multiple data types and separate them with commas (,). The following data types are supported: BIGINT, STRING, DOUBLE, BOOLEAN, DATETIME, DECIMAL, FLOAT, BINARY, DATE, DECIMAL(precision,scale), CHAR, VARCHAR, complex data types (ARRAY, MAP, and STRUCT), and nested complex data types.arg_type_listcan also be set to an asterisk (*) or left empty.If
arg_type_listis set to an asterisk (*), a random number of input parameters are used.If
arg_type_listis left empty, no input parameters are used.
typespecifies the data type of the return value. For a UDAF, only one column of values is returned. The following data types are supported: BIGINT, STRING, DOUBLE, BOOLEAN, DATETIME, DECIMAL, FLOAT, BINARY, DATE, and DECIMAL(precision, scale). Complex data types, such as ARRAY, MAP, and STRUCT, and nested complex data types are also supported.
When you write UDAF code, you can select a data type based on the data type edition used by your MaxCompute project. For more information about data type editions and data types supported by each edition, see Data type editions.
The following table provides examples of @Resolve annotations.
@Resolve annotation | Description |
| The data types of input parameters are BIGINT or DOUBLE, and the data type of the return value is STRING. |
| A random number of input parameters are used and the data type of the return value is STRING. |
| No input parameters are used and the data type of the return value is DOUBLE. |
| The data type of input parameters is ARRAY<BIGINT> and the data type of return values is STRUCT<x:STRING, y:INT>. |
Data types
In MaxCompute, different data type editions support different data types. In MaxCompute V2.0 and later, more data types and complex data types, such as ARRAY, MAP, and STRUCT, are supported. For more information about MaxCompute data type editions, see Data type editions.
The following table describes the mappings among the data types that are supported by MaxCompute projects, Java data types, and Java writable data types. You must write Java UDAFs based on the mappings to ensure data type consistency.
MaxCompute data type | Java data type | Java writable data type |
TINYINT | java.lang.Byte | ByteWritable |
SMALLINT | java.lang.Short | ShortWritable |
INT | java.lang.Integer | IntWritable |
BIGINT | java.lang.Long | LongWritable |
FLOAT | java.lang.Float | FloatWritable |
DOUBLE | java.lang.Double | DoubleWritable |
DECIMAL | java.math.BigDecimal | BigDecimalWritable |
BOOLEAN | java.lang.Boolean | BooleanWritable |
STRING | java.lang.String | Text |
VARCHAR | com.aliyun.odps.data.Varchar | VarcharWritable |
BINARY | com.aliyun.odps.data.Binary | BytesWritable |
DATE | java.sql.Date | DateWritable |
DATETIME | java.util.Date | DatetimeWritable |
TIMESTAMP | java.sql.Timestamp | TimestampWritable |
INTERVAL_YEAR_MONTH | N/A | IntervalYearMonthWritable |
INTERVAL_DAY_TIME | N/A | IntervalDayTimeWritable |
ARRAY | java.util.List | N/A |
MAP | java.util.Map | N/A |
STRUCT | com.aliyun.odps.data.Struct | N/A |
The input parameters or return values of a UDAF can be of Java writable data types only if your MaxCompute project uses the MaxCompute V2.0 data type edition.
Instructions
After you develop a Java UDAF, you can use MaxCompute SQL to call this UDAF. For more information about how to develop a Java UDAF, see the "Development process" section in Overview. You can use one of the following methods to call the Java UDAF:
Use a UDF in a MaxCompute project: The method is similar to that of using built-in functions.
Use a UDF across projects: Use a UDF of Project B in Project A. The following statement shows an example:
select B:udf_in_other_project(arg0, arg1) as res from table_t;. For more information about cross-project sharing, see Cross-project resource access based on packages.
For more information about how to use MaxCompute Studio to develop and call a Java UDAF, see Examples in this topic.
Examples
This example describes how to develop a UDAF named AggrAvg by using MaxCompute Studio. The AggrAvg UDAF is used to calculate average values. The following figure shows the logic of the AggrAvg UDAF.
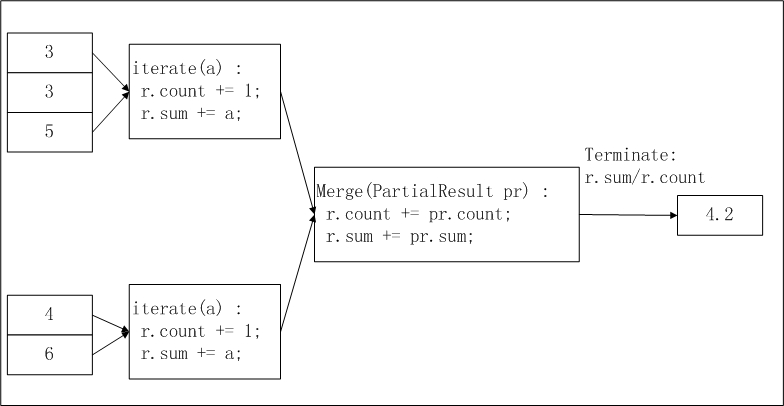
Slice the input data. MaxCompute slices the input data into the specified size based on the MapReduce processing workflow. The size of each slice is suitable for a worker to finish the calculation within a specified period of time.
You can configure the
odps.stage.mapper.split.sizeparameter to adjust the size of the slices. For more information about the logic of data slicing, see the "Process" section in Overview.Each worker counts the number of data records and total data volume in a slice. You can use the number of data records and total data volume in each slice as an intermediate result.
Each worker collects the information of each slice generated in Step 2.
In the final output,
r.sum/r.countis the average value of all input data.
To use MaxCompute Studio to develop and call a Java UDAF, perform the following steps:
Make preparations.
Before you use MaxCompute Studio to develop and debug a UDF, you must install MaxCompute Studio and connect MaxCompute Studio to a MaxCompute project. For more information about how to install MaxCompute Studio and connect MaxCompute Studio to a MaxCompute project, see the following topics:
Write UDAF code.
In the left-side navigation pane of the Project tab, choose , right-click java, and then choose .
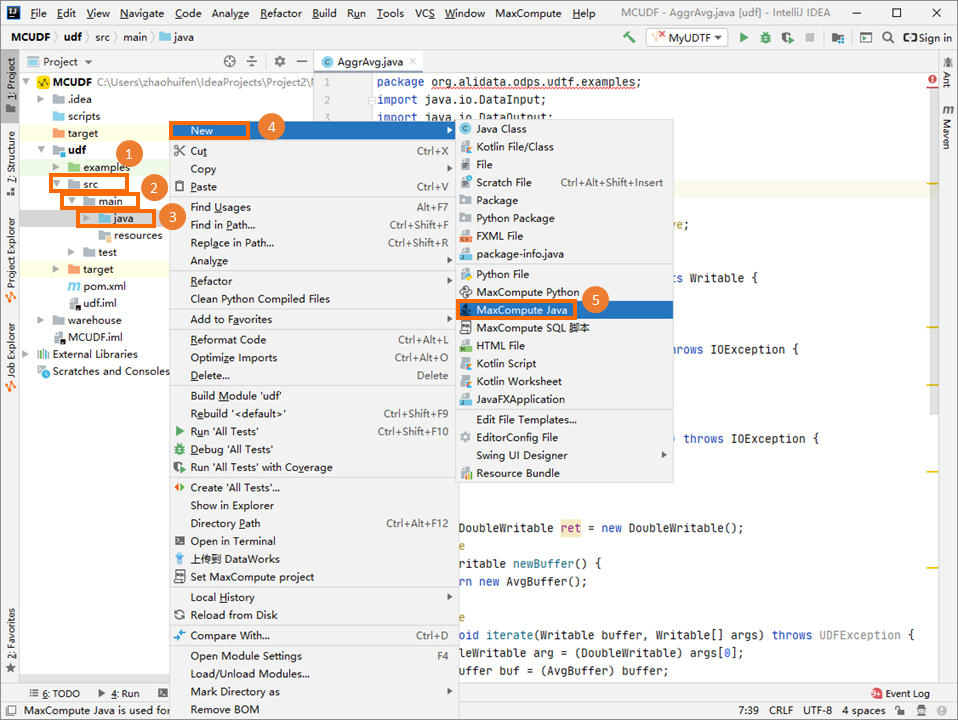
In the Create new MaxCompute java class dialog box, click UDAF, enter a class name in the Name field, and then press Enter. In this example, the Java class is named AggrAvg.
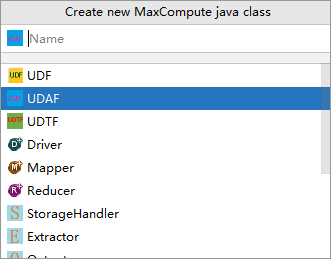
Name: the name of the MaxCompute Java class. If you have not created a package, specify this parameter in the packagename.classname format. The system automatically generates a package.
Write code in the code editor.
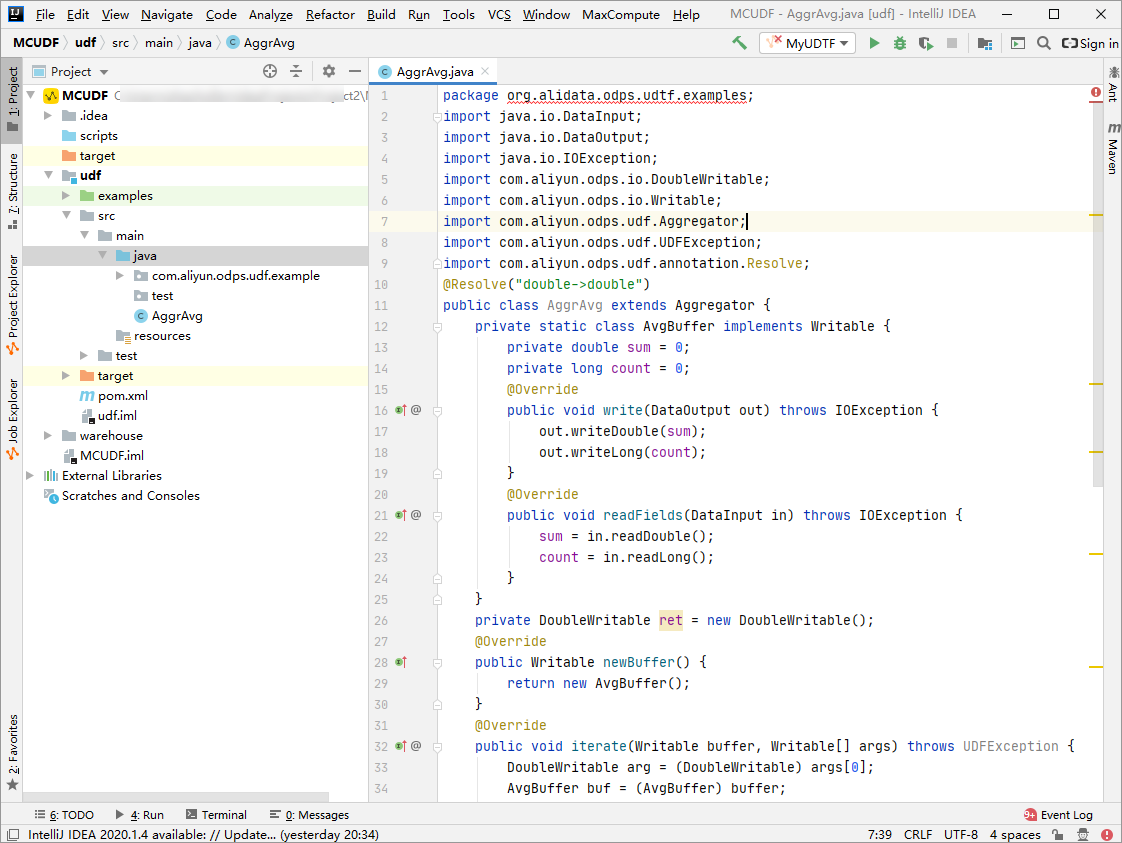 Sample UDAF code:
Sample UDAF code: import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import com.aliyun.odps.io.DoubleWritable; import com.aliyun.odps.io.Writable; import com.aliyun.odps.udf.Aggregator; import com.aliyun.odps.udf.UDFException; import com.aliyun.odps.udf.annotation.Resolve; @Resolve("double->double") public class AggrAvg extends Aggregator { private static class AvgBuffer implements Writable { private double sum = 0; private long count = 0; @Override public void write(DataOutput out) throws IOException { out.writeDouble(sum); out.writeLong(count); } @Override public void readFields(DataInput in) throws IOException { sum = in.readDouble(); count = in.readLong(); } } private DoubleWritable ret = new DoubleWritable(); @Override public Writable newBuffer() { return new AvgBuffer(); } @Override public void iterate(Writable buffer, Writable[] args) throws UDFException { DoubleWritable arg = (DoubleWritable) args[0]; AvgBuffer buf = (AvgBuffer) buffer; if (arg != null) { buf.count += 1; buf.sum += arg.get(); } } @Override public Writable terminate(Writable buffer) throws UDFException { AvgBuffer buf = (AvgBuffer) buffer; if (buf.count == 0) { ret.set(0); } else { ret.set(buf.sum / buf.count); } return ret; } @Override public void merge(Writable buffer, Writable partial) throws UDFException { AvgBuffer buf = (AvgBuffer) buffer; AvgBuffer p = (AvgBuffer) partial; buf.sum += p.sum; buf.count += p.count; } }
Debug the UDAF on your on-premises machine and verify that the code runs as expected.
For more information about debugging operations, see the "Perform a local run to debug the UDF" section in Develop a UDF.
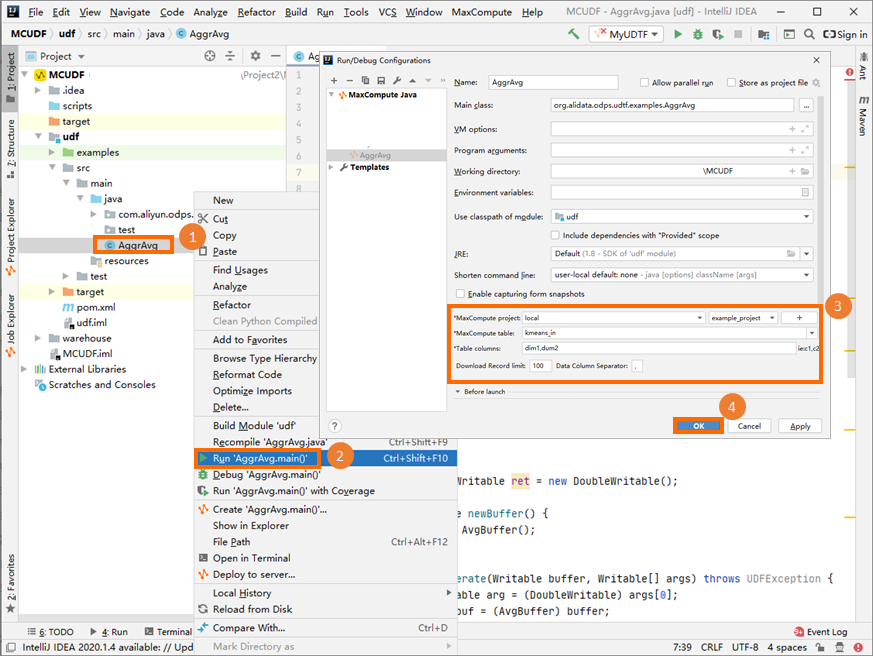 Note
NoteThe parameter settings in the preceding figure are for reference.
Package the UDAF code into a JAR file, upload the file to your MaxCompute project, and then create the UDAF. In this example, a UDAF named
user_udafis created.For more information about how to package a UDAF, see the "Procedure" section in Package a Java program, upload the package, and create a MaxCompute UDF.
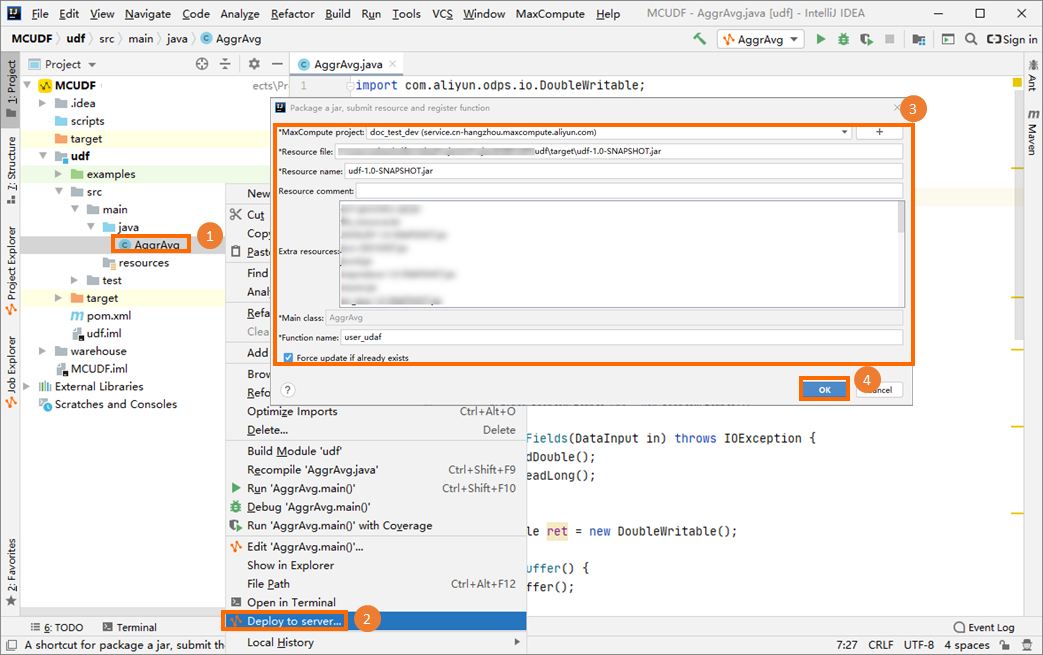
In the left-side navigation pane of MaxCompute Studio, click Project Explorer. Right-click your MaxCompute project to start the MaxCompute client, and execute an SQL statement to call the created UDAF.
The following example shows the data structure of the my_table table that you want to query.
+------------+------------+ | col0 | col1 | +------------+------------+ | 1.2 | 2.0 | | 1.6 | 2.1 | +------------+------------+Execute the following SQL statement to call the UDAF:
select user_udaf(col0) as c0 from my_table;The following result is returned:
+----+ | c0 | +----+ | 1.4| +----+