Multi-cluster and auto scaling are available for virtual warehouse instances in Hologres V4.0 and later. A virtual warehouse can run across multiple Clusters, and auto scaling adjusts the number of active Clusters based on load — handling high-concurrency workloads and providing resource isolation within the warehouse.
How it works
Without multi-cluster: All compute resources in a virtual warehouse belong to a single Cluster. All requests share those resources.
With multi-cluster: Multiple Clusters run inside one virtual warehouse. Compute resources are physically isolated between Clusters. The access node FE load-balances incoming requests and routes them to a Cluster for execution.
With multi-cluster and auto scaling: The virtual warehouse monitors load (resource usage and queueing) and automatically launches additional elastic Clusters during high-load periods. When load drops, it releases those elastic Clusters to reduce costs.

Choose a mode
Use this table to pick the right mode for your workload before you configure anything.
| Mode | Best for | Not suitable for |
|---|---|---|
| Multi-cluster (fixed) | High-concurrency workloads with small to medium queries and a stable, predictable load | Low-concurrency workloads with large tasks that need more compute in a single Cluster |
| Multi-cluster + auto scaling | High-concurrency workloads with unpredictable traffic spikes | Low-concurrency large tasks; workloads already managed by time-based elasticity |
When to use manual or time-based scale-up instead: If your peak traffic is predictable, adjust the number of Clusters manually or use time-based elasticity. Auto scaling is most valuable when peaks are unpredictable. You cannot use time-based elasticity and auto scaling on the same virtual warehouse simultaneously.
Key concepts
For definitions of multi-cluster concepts, instances, and virtual warehouse-level compute resources, see Resource Elasticity Overview.
Resource example: The following shows how resources are counted when a virtual warehouse uses auto scaling.
| Resource | Value | Description |
|---|---|---|
| Instance reserved resources | 64 CU | Total reserved compute for this instance |
| — Allocated to init_warehouse | 32 CU | Reserved resources committed to the virtual warehouse |
| — Unallocated | 32 CU | Available for new virtual warehouses or to increase reserved compute |
| Instance elastic resources | 32 CU | Compute launched by the elasticity feature |
| init_warehouse reserved Clusters | 1 | Number of always-on Clusters |
| Single Cluster specification | 32 CU | Compute per Cluster |
| Reserved resources | 32 CU | 1 × 32 CU |
| Current number of Clusters | 2 | 1 reserved + 1 elastic |
| Elastic resources | 32 CU | Compute launched by auto scaling |
| Total compute resources | 64 CU | 32 CU reserved + 32 CU elastic |
Instance elastic resources are independent of unallocated instance resources. Even if an instance has unallocated reserved resources, auto scaling launches additional elastic compute instead of using those unallocated resources.
Limitations
Requires Hologres V4.0 or later.
Supported on virtual warehouse instances only. Serverless instances and general-purpose instances are not supported.
Regional availability:
Feature Availability Multi-cluster All regions Auto scaling See the table below Region Auto scaling support Notes China (Hangzhou), China (Shanghai), China (Beijing), China (Shenzhen) Supported (public preview) Fill out the application form to apply for a trial. China (Chengdu), China (Hong Kong), Singapore, Germany (Frankfurt), US (Silicon Valley), US (Virginia), UAE (Dubai), Japan (Tokyo), Malaysia (Kuala Lumpur), Indonesia (Jakarta), Finance Cloud China (Shanghai), Alibaba Gov Cloud China (Beijing), Finance Cloud China (Shenzhen) Not supported Trial not available.
Billing
Reserved resources are billed under your instance billing method (subscription or pay-as-you-go).
Auto scaling resources are billed separately for the elastic compute launched:
Cost = Elastic resources launched (CU·hour) × Unit priceThe system records elastic resource usage every minute and pushes an hourly bill. Fees are deducted automatically from your account. For unit pricing, see Billing overview.
Auto scaling resources are pay-as-you-go. A successful Cluster launch is not guaranteed. Configure CloudMonitor alerts for failed launch events — see Monitoring and alerts.
Prerequisites
Before you begin, ensure that you have:
A virtual warehouse instance running Hologres V4.0 or later
An Alibaba Cloud account or a Resource Access Management (RAM) user granted the AliyunHologresWarehouseFullAccess permission (includes read-only access to the Hologres Management Console and auto scaling configuration permissions). For authorization steps, see Grant permissions to a RAM user.
Superuser permissions within the instance. For authorization steps, see Grant development permissions to a RAM user for an instance.
Enable multi-cluster
You can enable the multi-cluster feature by modifying the Number of reserved Clusters for a virtual warehouse. For detailed steps, see Manage virtual warehouses.
Adding or removing Clusters may affect query performance temporarily. For details, see Manage virtual warehouses.
Enable auto scaling
Auto scaling adjusts the number of active Clusters based on load, which includes resource usage and queueing.
Log on to the Hologres Management Console. In the top-left corner, select the region where your instance is deployed.
In the left navigation pane, click Instances. Click the target Instance ID/Name to open the Instance Details page.
In the left navigation pane of the instance details page, click Virtual Warehouse Management. On the right, select the Auto-scaling tab.
Click Enable Auto-scaling. Set the Maximum Clusters value and click Save.
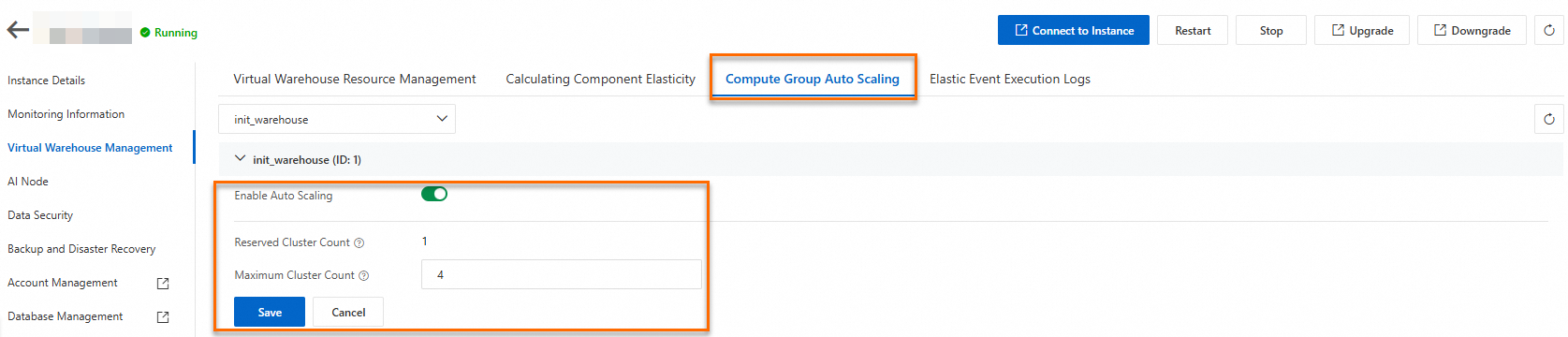
Maximum Clusters defines the upper bound for elastic scale-out. The virtual warehouse adds Clusters up to this limit during high-load periods.
Verify auto scaling behavior
After enabling auto scaling, use pgbench (the native PostgreSQL performance testing tool) to confirm that scaling triggers correctly. This example uses a configuration of 32 CU per Cluster, 1 reserved Cluster, and a maximum of 4 Clusters.
Create test tables and load data:
CREATE TABLE tbl_1 (col1 INT, col2 INT, col3 TEXT); CREATE TABLE tbl_2 (col1 INT, col2 INT, col3 TEXT); INSERT INTO tbl_1 SELECT i, i+1, md5(random()::TEXT) FROM generate_series(0, 500000) AS i; INSERT INTO tbl_2 SELECT i, i+1, md5(random()::TEXT) FROM generate_series(0, 500000) AS i;On the stress testing server, create a file named
select.sqlwith the following query:EXPLAIN ANALYZE SELECT * FROM tbl_1 LEFT JOIN tbl_2 ON tbl_1.col3 = tbl_2.col3 ORDER BY 1;Set the password as an environment variable:
export PGPASSWORD='<AccessKey_Secret>'Run the stress test. Replace the placeholders with your actual values. For connection parameter details, see Connect to Hologres and Develop.
Placeholder Description <AccessKey_Secret>AccessKey Secret for your account <Database>Target Hologres database name <AccessKey_ID>AccessKey ID for your account <Endpoint>Hologres instance endpoint <Port>Connection port pgbench \ -c 30 \ -j 30 \ -f select.sql \ -d <Database> \ -U <AccessKey_ID> \ -h <Endpoint> \ -p <Port> \ -T 1800
Expected results:
Cluster CPU utilization:

When Cluster 1 sustains high load, auto scaling adds a Cluster (position 1 in the chart).
After the stress test ends, both Clusters show low load and auto scaling removes the elastic Cluster (position 2).
Virtual warehouse CPU utilization:

A new Cluster is added when the virtual warehouse CPU utilization continuously exceeds 85%.
After the new Cluster is added, overall CPU utilization drops to approximately 70%.
Monitoring and alerts
Metrics
In the Hologres Management Console, monitor the following metrics for your virtual warehouse. For configuration instructions, see Monitoring Metrics in Hologres Console.
Cluster CPU utilization
Cluster memory usage
Number of cores launched by virtual warehouse auto scaling
Elastic event logs
On the Virtual Warehouse Management page, click the Elastic Event Execution Logs tab.
Select a time range to view past scaling events. Each event record includes the running time, virtual warehouse, execution status, event type, number of reserved Clusters, and target number of Clusters.
CloudMonitor events
Auto scaling scale-out and scale-in events are recorded in CloudMonitor.
Go to the CloudMonitor Event Center. On the System Events page, select Hologres as the product in the Event Monitoring area. The following auto scaling events are available:
Event name Description Instance:Warehouse:AutoElastic:StartAuto scaling has started for a virtual warehouse Instance:Warehouse:AutoElastic:FinishAuto scaling completed successfully Instance:Warehouse:AutoElastic:FailedAuto scaling failed (for example, a Cluster could not be launched) Based on these events, configure notifications or alert rules. For setup instructions, see Use System Event Alerts.
The following shows an example CloudMonitor event payload for a failed scale-out event:
{
"status": "Failed",
"instanceName": "<instance_id>",
"resourceId": "<instance_resource_id>",
"content": {
"AutoElasticCPU": <cpu_num>,
"ScaleType": "ScaleOut",
"ScheduleId": "xxxxxx",
"WarehouseId": "<warehouse_id>",
"WarehouseName": "<warehouse_name>"
},
"product": "hologres",
"time": 1722852008000,
"level": "WARN",
"regionId": "<region>",
"id": "<event_id>",
"groupId": "0",
"name": "Instance:Warehouse:TimedElastic:Failed"
}ActionTrail
All operations performed in the Hologres Management Console — including editing auto scaling configurations — and actual Cluster scaling operations triggered by auto scaling are recorded in ActionTrail. For details, see Event Audit Logs.
What's next
Manage virtual warehouses — adjust reserved Clusters, scale up/down, start/stop, or delete a virtual warehouse
Resource Elasticity Overview — concepts and terminology for Hologres resource elasticity
Billing overview — unit pricing for elastic compute resources