This topic applies only to DLF-Legacy. Use the latest version of Data Lake Formation (DLF) instead. For the new DLF, see Manage Paimon catalogs.
Without a catalog, Flink jobs require manual table registration in every session. A DLF catalog connects Realtime Compute for Apache Flink to your Data Lake Formation (DLF)-Legacy instance, letting Flink jobs access Iceberg and Hudi tables directly — no repeated registration needed. This topic describes how to create, view, use, and delete a DLF catalog.
Background information
Alibaba Cloud Data Lake Formation (DLF) is a unified metadata management product offered by Alibaba Cloud. You can use DLF to manage tables in open source formats, such as Iceberg, Hudi, Delta, Parquet, ORC, or Avro.
Prerequisites
Before you begin, ensure that you have:
-
Activated the Alibaba Cloud Data Lake Formation (DLF)-Legacy service
Limitations
Flink supports only Iceberg and Hudi table formats in a DLF catalog.
Create a DLF catalog
Two methods are available: the console UI and SQL. Use the UI method unless you need SQL for automation.
UI method
-
Log on to the Realtime Compute for Apache Flink console. Find the workspace and click Console in the Actions column. Then click Data Management.
-
Click Create Catalog, select DLF, and then click Next.
-
Configure the catalog parameters. Parameter notes:
-
`warehouse`: To use an OSS-HDFS path, your Ververica Runtime (VVR) version must be 8.0.3 or later. Find your bucket name and object path in the OSS consoleOSS consoleOSS consoleOSS console. For the OSS-HDFS endpoint, go to the bucket's Overview page and find the Endpoint of HDFS Service in the Access Ports section.
-
`oss.endpoint`: For endpoint values by region, see Regions and endpoints. To access OSS across Virtual Private Clouds (VPCs), see How do I access other services across VPCs?.
-
`dlf.endpoint`: To access DLF across VPCs, see Workspace management.
Parameter Description Required Example catalognameA custom name for the DLF catalog. Use English characters. Yes my_dlf_catalogaccess.key.idThe AccessKey ID for accessing Object Storage Service (OSS). See Obtain an AccessKey pair. Yes — access.key.secretThe AccessKey secret for accessing OSS. See Obtain an AccessKey pair. Yes — warehouseThe default OSS path for storing catalog tables. Supports OSS and OSS-HDFS paths. Yes oss://<bucket>/<object>oross://<bucket>.<oss-hdfs-endpoint>/<object>oss.endpointThe OSS service endpoint. Use the VPC endpoint to avoid cross-network latency. Yes oss-cn-hangzhou-internal.aliyuncs.comdlf.endpointThe DLF service endpoint. Use the VPC endpoint. Yes dlf-vpc.cn-hangzhou.aliyuncs.comdlf.region-idThe region where DLF resides. Must match the region in dlf.endpoint.Yes cn-hangzhouMore Configurations Additional DLF settings, one per line. No dlf.catalog.id:my_catalog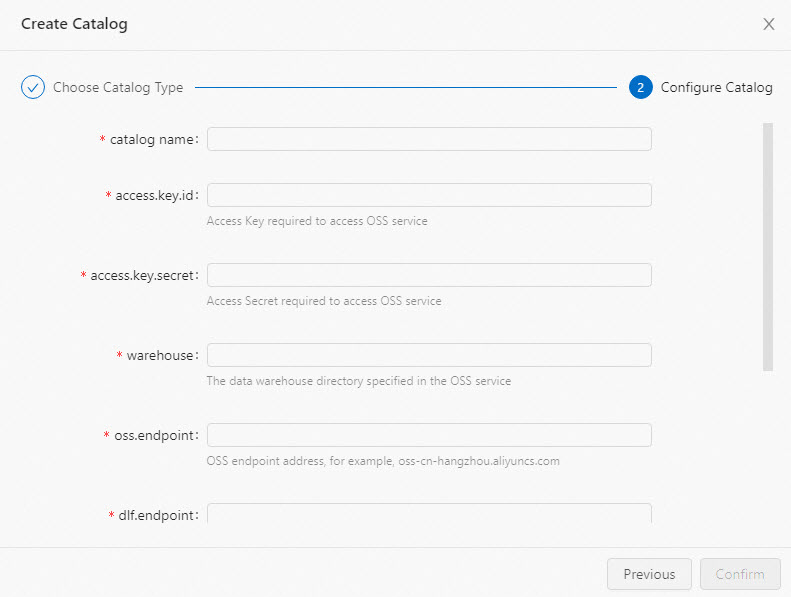
-
-
Click OK.
The catalog appears in the Metadata area.
SQL method
-
On the Data Query page, enter the following statement in the text editor.
ImportantAfter replacing the placeholders, remove the angle brackets (
<>). Leaving them in causes a syntax error.Parameter Description Required Example yourcatalognameA custom name for the DLF catalog. Use English characters. Yes my_dlf_catalogtypeThe catalog type. Fixed value: dlf.Yes dlfaccess.key.idThe AccessKey ID of your Alibaba Cloud account. See Obtain an AccessKey pair. Yes — access.key.secretThe AccessKey secret of your Alibaba Cloud account. See Obtain an AccessKey pair. Yes — warehouseThe default OSS path for storing catalog tables. Format: oss://<bucket>/<object>. Find your bucket and object names in the OSS consoleOSS consoleOSS consoleOSS console.Yes oss://examplebucket/warehouseoss.endpointThe OSS service endpoint. Use the VPC endpoint. For values by region, see Regions and endpoints. Yes oss-cn-hangzhou-internal.aliyuncs.comdlf.endpointThe DLF service endpoint. Use the VPC endpoint. To access DLF across VPCs, see Workspace management. Yes dlf-vpc.cn-hangzhou.aliyuncs.comdlf.region-idThe region where DLF resides. Must match the region in dlf.endpoint.Yes cn-hangzhouCREATE CATALOG <yourcatalogname> WITH ( 'type' = 'dlf', 'access.key.id' = '<YourAliyunAccessKeyId>', 'access.key.secret' = '<YourAliyunAccessKeySecret>', 'warehouse' = '<YourAliyunOSSLocation>', 'oss.endpoint' = '<YourAliyunOSSEndpoint>', 'dlf.region-id' = '<YourAliyunDLFRegionId>', 'dlf.endpoint' = '<YourAliyunDLFEndpoint>' ); -
Select the statement and click Run.
The catalog appears in the Metadata area on the left.
View a DLF catalog
-
Log on to the Realtime Compute for Apache Flink console. Find the workspace and click Console in the Actions column. Then click Data Management.
-
On the Catalog List page, check the Catalog Name and Type columns. To view the databases and tables in a catalog, click View in the Actions column.
Use a DLF catalog
Run all SQL statements on the Data Query page: select the statement and click Run. After each operation, verify the result in the Metadata section on the left of the SQL Development page.
Manage databases
-- Create a database
CREATE DATABASE dlf.dlf_testdb;
-- Delete a database
DROP DATABASE dlf.dlf_testdb;Manage tables
Create a table using a connector
Use SQL or the console UI.
SQL method
-- Create an Iceberg table
CREATE TABLE dlf.dlf_testdb.iceberg (
id BIGINT,
data STRING,
dt STRING
) PARTITIONED BY (dt) WITH (
'connector' = 'iceberg'
);
-- Create a Hudi table
CREATE TABLE dlf.dlf_testdb.hudi (
id BIGINT PRIMARY KEY NOT ENFORCED,
data STRING,
dt STRING
) PARTITIONED BY (dt) WITH (
'connector' = 'hudi'
);UI method
-
Log on to the Realtime Compute for Apache Flink console. Find the workspace and click Console in the Actions column. Then click Data Management.
-
Find the catalog and click View in the Actions column.
-
Find the database and click View in the Actions column.
-
Click Create Table.
-
On the Connect with Built-in Connector tab, select a table type from the Connection Method list.
-
Click Next.
-
Enter the table creation statement and configure the parameters. Example:
CREATE TABLE dlf.dlf_testdb.iceberg ( id BIGINT, data STRING, dt STRING ) PARTITIONED BY (dt) WITH ( 'connector' = 'iceberg' ); CREATE TABLE dlf.dlf_testdb.hudi ( id BIGINT PRIMARY KEY NOT ENFORCED, data STRING, dt STRING ) PARTITIONED BY (dt) WITH ( 'connector' = 'hudi' ); -
Click OK.
Create an Iceberg table from an existing schema
This method applies only to Iceberg tables.
CREATE TABLE iceberg_table_like LIKE iceberg_table;Delete a table
DROP TABLE iceberg_table;Modify an Iceberg table schema
Run the following statements on the Data Query page.
| Operation | Statement |
|---|---|
| Change table properties | ALTER TABLE iceberg_table SET ('write.format.default'='avro'); |
| Rename a table | ALTER TABLE iceberg_table RENAME TO new_iceberg_table; |
| Rename a column (VVR 8.0.7 and later) | ALTER TABLE iceberg_table RENAME id TO index; |
| Change a column type (VVR 8.0.7 and later) | ALTER TABLE iceberg_table MODIFY (id, BIGINT) |
Supported type conversions:
-
INTtoBIGINT -
FloattoDouble -
DecimaltoDecimal
Write and read data
-- Write data
INSERT INTO dlf.dlf_testdb.iceberg VALUES (1, 'AAA', '2022-02-01'), (2, 'BBB', '2022-02-01');
INSERT INTO dlf.dlf_testdb.hudi VALUES (1, 'AAA', '2022-02-01'), (2, 'BBB', '2022-02-01');
-- Read data
SELECT * FROM dlf.dlf_testdb.iceberg LIMIT 2;
SELECT * FROM dlf.dlf_testdb.hudi LIMIT 2;Delete a DLF catalog
Deleting a catalog does not affect currently running jobs. However, any job that references tables from the deleted catalog will fail with a table not found error when restarted or republished.
Two methods are available: the console UI and SQL. Use the UI method unless you need SQL for automation.
UI method
-
Log on to the Realtime Compute for Apache Flink console. Find the workspace and click Console in the Actions column. Then click Data Management.
-
On the Catalog List page, find the catalog and click Delete in the Actions column.
-
In the confirmation dialog, click Delete.
Confirm the catalog no longer appears in the Metadata section.
SQL method
-
On the Data Query page, run the following statement.
DROP CATALOG ${catalog_name}Replace
${catalog_name}with the name of the catalog as shown in the Realtime Compute for Apache Flink console. -
Select the statement and click Run.
Confirm the catalog no longer appears in the Metadata area.
What's next
-
To use Iceberg tables in your jobs, see Iceberg.
-
To use Hudi tables in your jobs, see Hudi (deprecated).
-
To define custom metadata catalogs beyond DLF-Legacy, see Manage custom catalogs.