This topic explains how to create a materialized table, perform data backfilling, modify data freshness, and view data lineage.
Limitations
This feature is available only in Ververica Runtime (VVR) 8.0.10 and later versions.
Materialized tables can be created only in an Apache Paimon catalog that uses either Filesystem or DLF for metadata storage. Custom Apache Paimon catalogs are not supported.
You must have the permissions to develop and deploy jobs. For more information, see Development console authorization.
Temporary objects, such as temporary tables, temporary user-defined functions, and temporary views, are not supported.
Create a materialized table
Syntax
CREATE MATERIALIZED TABLE [catalog_name.][db_name.]table_name
-- Primary key constraint
[([CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED)]
[COMMENT table_comment]
-- Partition key
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
-- With options
[WITH (key1=val1, key2=val2, ...)]
-- Data freshness
FRESHNESS = INTERVAL '<num>' { SECOND | MINUTE | HOUR | DAY }
-- Refresh mode
[REFRESH_MODE = { CONTINUOUS | FULL }]
AS <select_statement>Parameters
Parameter | Required | Description |
FRESHNESS | Yes | The data freshness of the materialized table, defining the maximum allowed latency for data updates from the source tables. Note
|
AS <select_statement> | Yes | Defines the query that populates the materialized table. The upstream table can be a materialized table, a regular table, or a view. The |
PRIMARY KEY | No | The optional columns that uniquely identify each row in the table. These columns cannot contain null values. |
PARTITIONED BY | No | The optional columns used to partition the materialized table. |
WITH Options | No | Defines table properties and time format parameters for partitioning columns. For example, you can set the time format parameter for a partitioning column with |
REFRESH_MODE | No | Specifies the refresh mode for the materialized table. A specified refresh mode takes precedence over the mode automatically inferred by the framework based on data freshness. This allows you to handle specific scenarios.
|
Procedure
Log on to the Realtime Compute for Apache Flink console.
In the Actions column of the target workspace, click Console.
In the left-side navigation pane, click Catalogs, and then click the target Apache Paimon catalog.
Click the target database, and then click Create Materialized Table.
Assume you have a source table named
orderswith a primary keyorder_id, a category nameorder_name, and a date fieldds. The following examples show how to create materialized tables based on this table:Create a materialized table
mt_orderbased on theorderstable. The query selects all columns, and the data freshness is set to 5 seconds.CREATE MATERIALIZED TABLE mt_order FRESHNESS = INTERVAL '5' SECOND AS SELECT * FROM `paimon`.`db`.`orders` ;Create a materialized table
mt_idbased on the materialized tablemt_order. The query selectsorder_idanddsas table columns, setsorder_idas the primary key,dsas the partitioning column, and the data freshness to 30 minutes.CREATE MATERIALIZED TABLE mt_id ( PRIMARY KEY (order_id) NOT ENFORCED ) PARTITIONED BY(ds) FRESHNESS = INTERVAL '30' MINUTE AS SELECT order_id,ds FROM mt_order ;Create the materialized table
mt_dsbased on the materialized tablemt_order, and specify adate-formatter(time format) for thedspartitioning column. Each time a schedule is run, the scheduling time minus the freshness is converted to the correspondingdspartition value. For example, if the data freshness is set to 1 hour and the scheduling time is2024-01-01 00:00:00, the calculated value of ds is 20231231, and only the data in the partitionds = '20231231'is refreshed. If the scheduled time is2024-01-01 01:00:00, the calculated value of ds is 20240101, and the data in the partitionds = '20240101'is refreshed.CREATE MATERIALIZED TABLE mt_ds PARTITIONED BY(ds) WITH ( 'partition.fields.ds.date-formatter' = 'yyyyMMdd' ) FRESHNESS = INTERVAL '1' HOUR AS SELECT order_id,order_name,ds FROM mt_order ;NoteIn
partition.fields.#.date-formatter, the#placeholder must be a valid partitioning column of the STRING type.The
partition.fields.#.date-formatteroption specifies the time partition format for the materialized table. The#placeholder represents the name of a string-type partitioning column. This information allows the system to identify which partition to refresh during a scheduled update.
Start or stop updating the materialized table.
Click the target materialized table under its catalog.
In the upper-right corner, click Start Update or Stop Update.
NoteIf you stop an update that is in progress, the job finishes the current update cycle before stopping.
View the details of the materialized table job.
On the Table Schema tab, in the Basic Information section, click the job ID next to Latest Job or Workflow to view the details.
Modifying a materialized table query
Limitations
You can modify the query only for materialized tables created in VVR 11.1 or later.
When modifying a query, you can only add columns and modify computation logic. You cannot change the order of existing columns or modify their definitions.
Operation
Supported
Description
Add a new column
Yes
You can append new columns to the schema while maintaining the existing column order.
Modify computation logic for an existing column (without changing its name or type)
Yes
You can modify the computation logic, but the column name and data type must remain the same.
Change the order of existing columns
No
The column order is fixed. To change it, you must drop and re-create the materialized table.
Modify the name or data type of an existing column
No
You must drop and re-create the materialized table.
Example
Click Edit Table and modify the query. The following code provides an example:
ALTER MATERIALIZED TABLE `paimon`.`default`.`mt-orders` AS SELECT *, price * quantity AS total_price FROM orders WHERE price * quantity > 1000 ;Click Preview to see a before-and-after comparison.
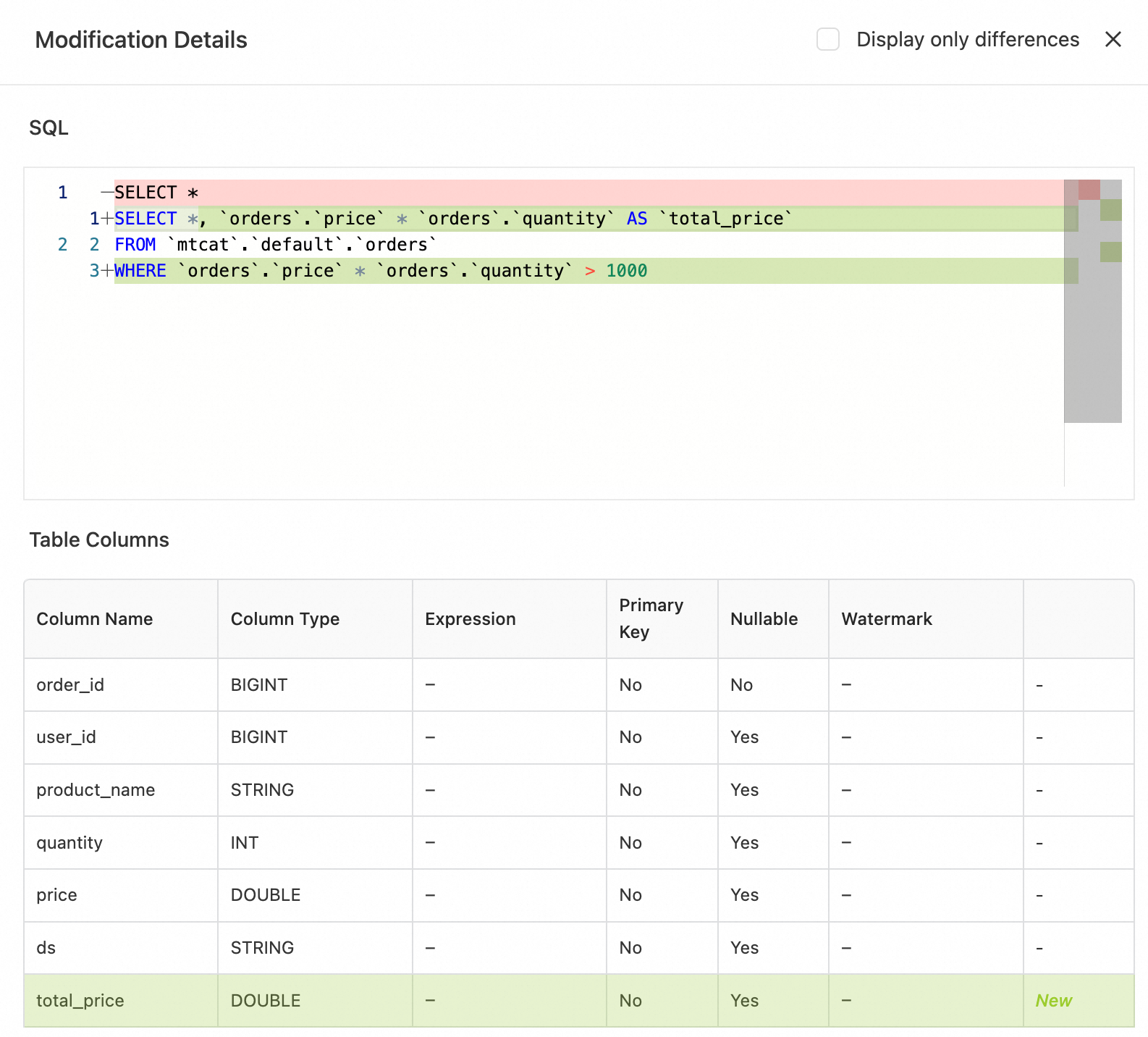
Click OK. You can view the newly added column and modified query logic on the Table Schema tab.
Adding columns usually does not affect downstream consumers. However, if a downstream job relies on dynamic parsing (such as SELECT * or automatic field mapping) when consuming data from the upstream materialized table, the job might fail or report a data format mismatch error. We recommend that you avoid dynamic parsing, use fixed column lists, and update the downstream table schema promptly whenever the upstream schema changes.
Incremental updates
Limitations
This feature is available only in VVR 8.0.11 and later versions.
Update modes
Materialized tables support three update modes: streaming, full batch, and incremental batch.
The mode is determined by the data freshness setting. A freshness of less than 30 minutes enables streaming mode, while 30 minutes or more enables batch mode. In batch mode, the engine automatically decides between a full or incremental update. An incremental update computes only the data that has changed since the last update and merges it into the materialized table. A full update computes data for the entire table or partition and overwrites the existing data in the materialized table. In batch mode, the engine prioritizes incremental updates and falls back to a full update only when an incremental update is not possible.
Incremental update conditions
An incremental update is performed only if the materialized table meets all the following conditions:
The
partition.fields.#.date-formatterparameter is not configured in the table definition.The source table does not have a primary key defined.
The query in the materialized table definition supports incremental updates as described in the following table:
SQL Clause
Support
SELECT
Supported for column selection and scalar function expressions, including user-defined functions. Aggregate functions are not supported.
FROM
Supported for table names and subqueries.
WITH
Supported for Common Table Expressions (CTEs).
WHERE
Supported for filter conditions that include various scalar function expressions, including user-defined functions. Subqueries such as
WHERE [NOT] EXISTS <subquery>andWHERE <column> [NOT] IN <subquery>are not supported.UNION
Only
UNION ALLis supported.JOIN
INNER JOINis supported.LEFT/RIGHT/FULL [OUTER] JOINare not supported, except in the specificLATERAL JOINand lookup join cases described below.[LEFT [OUTER]] JOIN LATERALwith a table function expression (including user-defined functions) is supported.For lookup join, only
A [LEFT [OUTER]] JOIN B FOR SYSTEM_TIME AS OF PROCTIME()is supported.
NoteImplicit joins without the
JOINkeyword, such asSELECT * FROM a, b WHERE a.id = b.id, are supported.Incremental computation for
INNER JOINstill reads the full data from both source tables.
GROUP BY
Not supported.
Incremental update examples
Example 1: Process data from the orders source table by using scalar functions.
CREATE MATERIALIZED TABLE mt_shipped_orders (
PRIMARY KEY (order_id) NOT ENFORCED
)
FRESHNESS = INTERVAL '30' MINUTE
AS
SELECT
order_id,
COALESCE(customer_id, 'Unknown') AS customer_id,
CAST(order_amount AS DECIMAL(10, 2)) AS order_amount,
CASE
WHEN status = 'shipped' THEN 'Completed'
WHEN status = 'pending' THEN 'In Progress'
ELSE 'Unknown'
END AS order_status,
DATE_FORMAT(order_ts, 'yyyyMMdd') AS order_date,
UDSF_ProcessFunction(notes) AS notes
FROM
orders
WHERE
status = 'shipped';Example 2: Enrich data from the orders source table by using LATERAL JOIN and lookup join.
CREATE MATERIALIZED TABLE mt_enriched_orders (
PRIMARY KEY (order_id, order_tag) NOT ENFORCED
)
FRESHNESS = INTERVAL '30' MINUTE
AS
WITH o AS (
SELECT
order_id,
product_id,
quantity,
proc_time,
e.tag AS order_tag
FROM
orders,
LATERAL TABLE(UDTF_StringSplitFunction(tags, ',')) AS e(tag))
SELECT
o.order_id,
o.product_id,
p.product_name,
p.category,
o.quantity,
p.price,
o.quantity * p.price AS total_amount,
order_tag
FROM o
LEFT JOIN
product_info FOR SYSTEM_TIME AS OF PROCTIME() AS p
ON
o.product_id = p.product_id;Data backfilling
Previously, correcting stream processing results for historical data required developing a separate batch job. By using materialized tables, you can directly backfill historical data partitions. This approach unifies batch and streaming processing, which reduces development and O&M costs.
Click the target materialized table under its catalog.
On the Data Information tab, backfill the data.
If you defined a partitioning column when you created the materialized table, it is a partitioned table. Otherwise, it is a non-partitioned table.
Partitioned table
In the Data Partitions section, click Trigger Update if this is the first time you are backfilling data or if the required partition does not exist. If partitions already exist, you can select a specific partition and click Refresh in the Actions column.
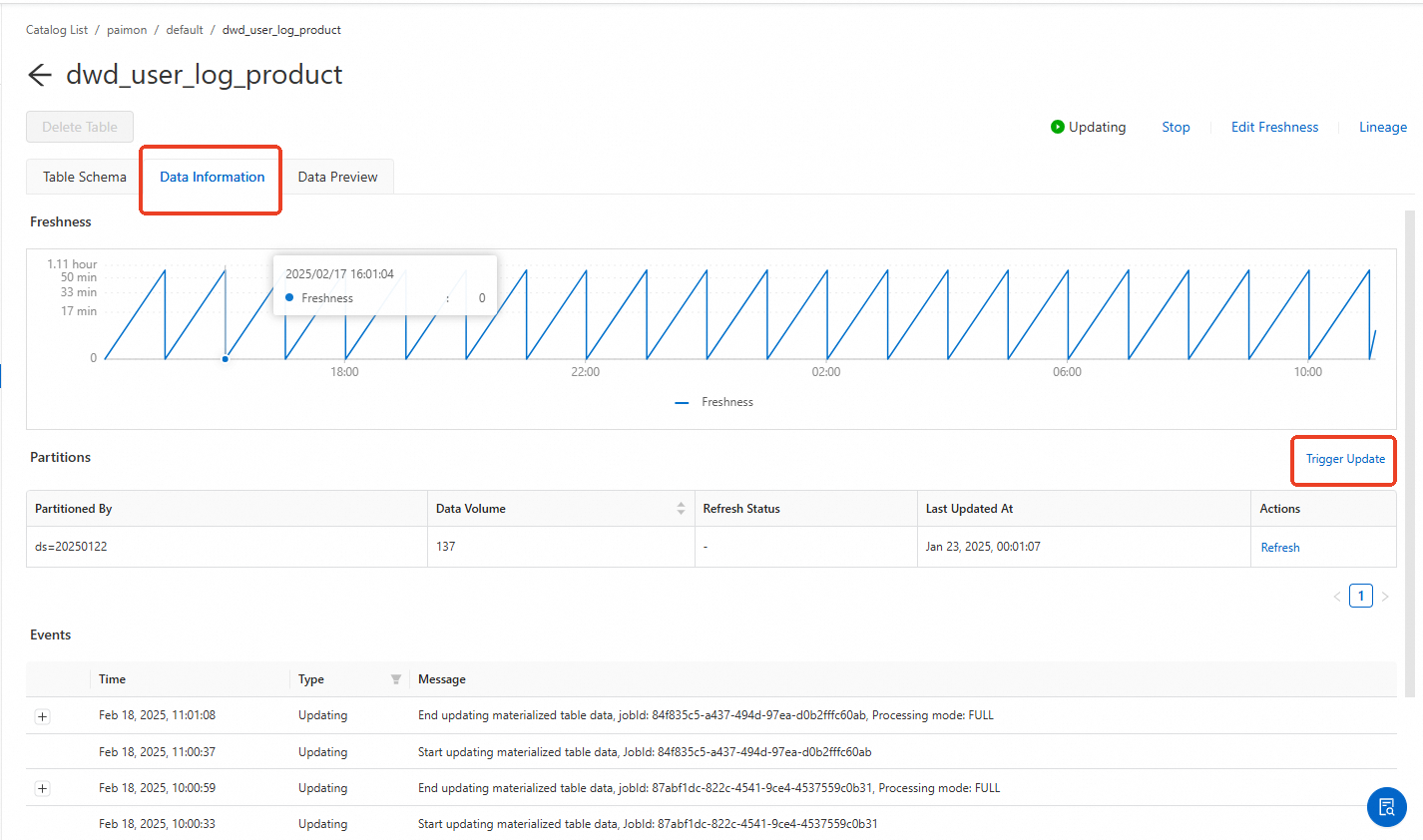
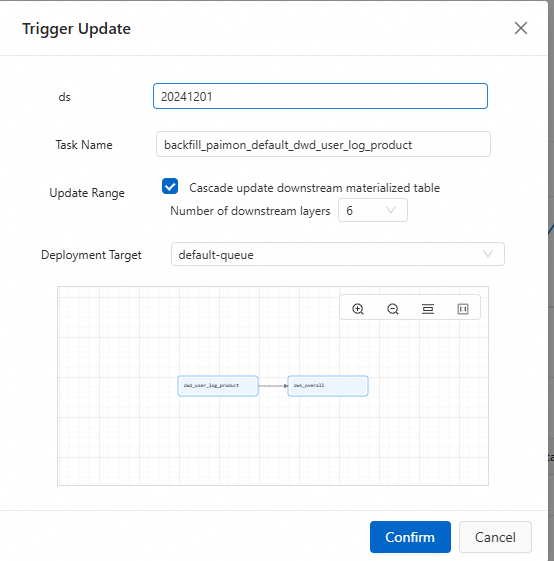
Parameters
Partitioning column: The partitioning column of the table. For example, if you enter
20241201, all data in the partitionds=20241201is backfilled.Task Name: The name of the data backfilling task.
Update Range (Optional): Specifies whether to cascade updates to downstream materialized tables. Starting from the current table, all materialized tables in the data lineage are updated. The maximum supported depth of the downstream lineage is 6 levels.
NoteWhen updating a partitioned table, the downstream materialized tables must have the exact same partitioning columns as the starting table. Otherwise, the update operation fails.
If an update fails for any materialized table in the lineage, all subsequent downstream nodes will also fail.
Deployment Target: You can select a queue or a session cluster. The default selection is
default-queue.
Non-partitioned table
In the Data Status section, click Refresh.

Parameters
Task Name: The name of the data backfilling task.
Update Range: This option is not available for non-partitioned tables.
NoteDuring an update, downstream data is fully refreshed.
If an update fails for any materialized table in the lineage, all subsequent downstream nodes will also fail.
Cascading updates are not supported if the starting table is a non-partitioned table that is updated by a streaming job.
Deployment Target: You can select a queue or a session cluster. The default selection is
default-queue.
Scheduled and batch backfilling.
You can use Task Orchestration to create a workflow for the materialized table to run backfilling jobs on a schedule. You can also use the workflow's data backfilling feature to backfill data in bulk for a specified time range.
Modify data freshness
Under the corresponding catalog, click the materialized table database, and then click the target materialized table.
In the upper-right corner, click Edit Freshness.
If the materialized table does not have a primary key, you cannot switch its update method between streaming and batch. The system uses a streaming job for data freshness values under 30 minutes and a batch job for values of 30 minutes or more. Therefore, changing the freshness across this 30-minute threshold is not permitted for tables without a primary key.
If the upstream table is a materialized table, ensure that the data freshness of the downstream table is a positive integer multiple of the upstream table's data freshness.
The maximum data freshness is one day.
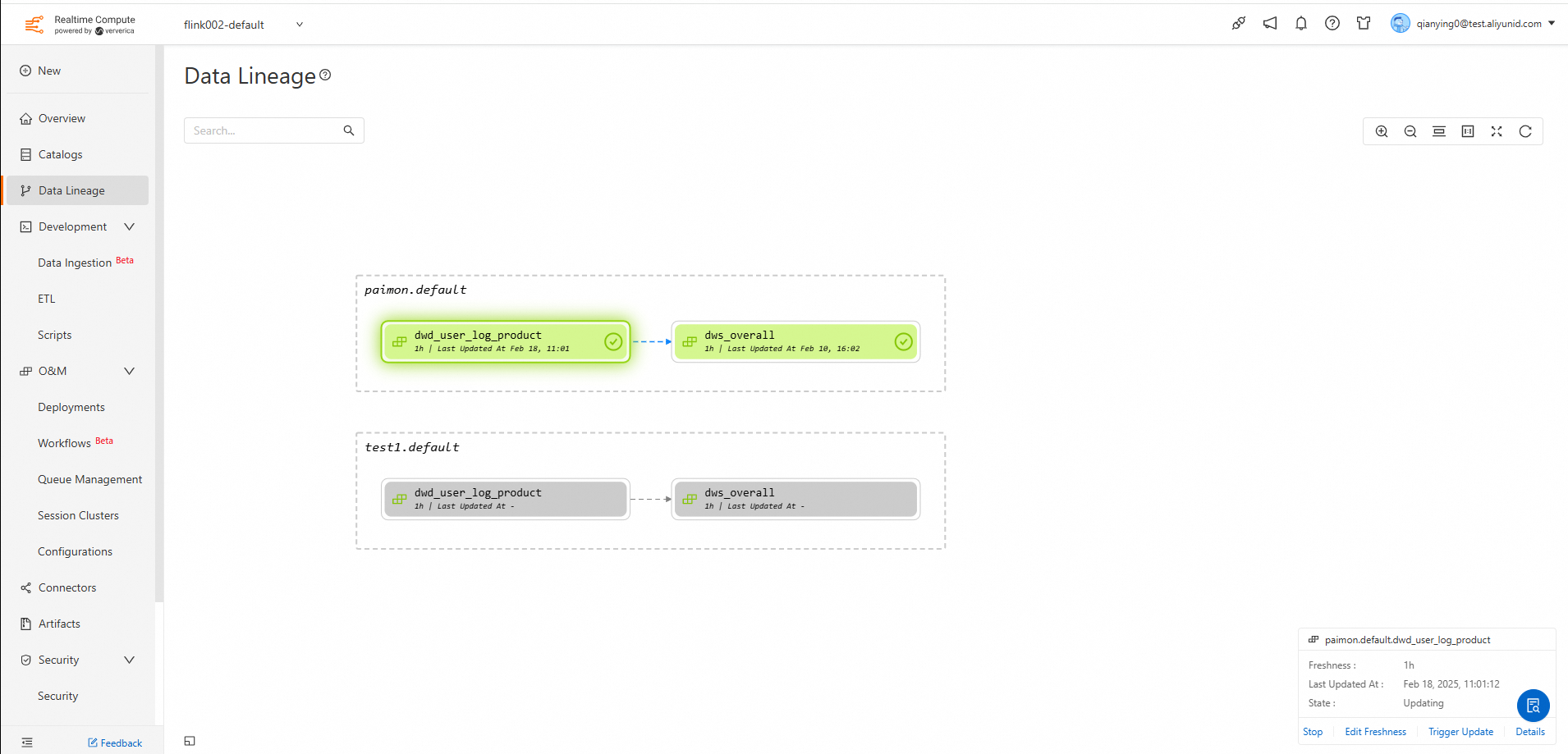
View data lineage
In the left-side navigation pane, choose to go to the data lineage page for materialized tables. On this page, you can view the lineage relationships between all materialized tables. You can also perform operations such as Start/Stop Update and Edit Freshness directly on a materialized table. Click Details to navigate to the details page of the corresponding materialized table.
Related documents
For an introduction to materialized tables, see Manage materialized tables.
To learn how to build an analytical pipeline in a data lakehouse with unified batch and streaming processing based on Paimon and materialized tables, and how to switch from batch to stream mode by modifying data freshness for real-time updates, see Quick start: Build a data lakehouse with unified batch and streaming processing by using materialized tables.