Realtime Compute for Apache Flink provides two automatic tuning modes—Autopilot and scheduled tuning—to reduce manual resource management. Manual tuning requires assigning resources before a job starts, adjusting allocations during job execution to maximize utilization, and reacting to backpressure or latency spikes. Both modes automate these decisions so your jobs stay efficient without constant intervention.
Choose a tuning mode
| Tuning mode | Use when | How it works | References |
|---|---|---|---|
| Autopilot | Workloads are variable or unpredictable, and you want the system to respond automatically to changes in CPU, memory, or latency. | The system continuously monitors live metrics and adjusts parallelism, CPU, and memory without manual intervention. | Enable and configure Autopilot |
| Scheduled tuning | Traffic follows a predictable pattern (for example, daily peaks and off-peak hours) and you can plan resource changes in advance. | You define time-based resource plans. The system applies them at configured trigger times. | Configure and apply a scheduled tuning plan |
Limitations and considerations
Unaligned checkpointing: Job parallelism cannot be modified when unaligned checkpointing is enabled.
Session clusters: Autopilot is not supported for jobs running on session clusters.
YAML-developed jobs: Automatic tuning is not supported for jobs developed using YAML.
Hardcoded parallelism: Do not hardcode parallelism in Flink SQL jobs with a custom connector or in DataStream API jobs. Hardcoded values override automatic tuning configurations.
Maximum resource plans: A maximum of 20 resource plans can be created.
Mutually exclusive plans: Only one scheduled tuning plan can be applied at a time. Stop the active plan before applying a different one.
Job restarts: Automatic tuning may restart jobs, momentarily halting data consumption.
Resource modification behavior: When automatic tuning applies changes, the system compares the before and after configurations to determine the update method. If CPU or memory changes are involved, the deployment restarts. If only parallelism changes, a dynamic update is applied to minimize downtime.
Performance bottlenecks: Autopilot does not resolve all streaming performance bottlenecks. It works best when traffic changes smoothly, no data skew exists, and operator throughput scales linearly with parallelism. Outside these conditions, you may see:
-
Failed parallelism changes, or the job repeatedly restarts without reaching a stable state.
-
Degraded performance in user-defined scalar functions (UDFs), user-defined aggregate functions (UDAFs), or user-defined table-valued functions (UDTFs).
External system issues: Autopilot does not detect issues in external systems. If an external system fails or responds slowly, Autopilot may increase job parallelism, adding load to an already stressed system. Common external-system issues include:
-
Insufficient DataHub partitions or low throughput on ApsaraMQ for RocketMQ.
-
Low sink operator performance.
-
Deadlocks on ApsaraDB RDS databases.
Enable and configure Autopilot
Autopilot strategies
Select a strategy based on your workload characteristics:
| Strategy | Best for | How it works |
|---|---|---|
| Adaptive strategy (recommended) | Variable workloads, high latency sensitivity, data skew, or uneven load distribution. | Continuously adjusts resource configuration based on real-time metrics, responding quickly to demand changes. |
| Stable strategy | Stable, predictable workloads where restarts are costly and convergence to a fixed plan is preferred. | Targets a fixed or scheduled resource plan for the job's full running cycle. After configurations converge, the system outputs a resource plan you can save and reuse. Job restarts or hot updates reset the convergence process. |
Procedure
-
Go to the Autopilot configuration page.
-
Log on to the Realtime Compute for Apache Flink console.
-
Find the target workspace and click Console in the Actions column.
-
In the left-side navigation pane, choose O&M > Deployments, then click the name of the target deployment.
-
On the Resources tab, select the Autopilot Mode subtab.
-
-
Turn on Autopilot. Autopilot Mode Applying appears below the Resources tab. To disable Autopilot, turn off the toggle or click Turn Off Autopilot.
-
In the Configurations section, click Edit, select a strategy, and configure the parameters.
(Recommended) Adaptive strategy
Adaptive strategy parameters
Parameter Description Max CPU Maximum CPU cores the job can use. Default: 64 cores. Max Memory Maximum memory the job can use. Default: 256 GiB. Max Parallelism Maximum job parallelism. Default: 1,024. When integrated with ApsaraMQ for Kafka, Message Queue, Simple Log Service, or other message queue services, the system automatically caps this at the partition count if the configured value exceeds it. Min Parallelism Minimum job parallelism. Default: 1. Scale Up Rules Conditions that trigger a scale-up. Any single condition being met triggers the action. Configurable conditions: <br>- Delays stay above a threshold for a specified duration. <br>- An operator's average busy rate stays above a threshold for a specified duration. <br>- A TaskManager's memory utilization stays above a threshold for a specified duration. <br>- An out-of-memory (OOM) error occurs. <br>- The time TaskManager or JobManager spends in garbage collection per second stays above a threshold for a specified duration. <br> NoteSet thresholds based on historical data or start with looser values and tighten them over time. Threshold percentages range from 0–100%. Setting an appropriate duration helps filter brief fluctuations and prevents scale-ups from transient spikes. OOM is enabled or disabled only—no threshold needed.
Scale Down Rules Conditions that trigger a scale-down. Any single condition being met triggers the action. Configurable conditions: <br>- An operator's average busy rate stays below a threshold for a specified duration. <br>- A TaskManager's memory utilization stays below a threshold for a specified duration. Advanced Rules Currently in testing and not generally available. Contact us to enable advanced rules. Stable strategy
Stable strategy parameters
Parameter Description Cooldown Minutes Minimum interval between Autopilot-triggered restarts. Default: 10 minutes. Max CPU Maximum CPU cores the job can use. Default: 16 cores. Max Memory Maximum memory the job can use. Default: 64 GiB. Max Delay Maximum allowed source delay. Default: 1 minute. More Configurations Advanced parameters (see table below). Stable strategy: advanced parameters
Parameter Description Default mem.scale-down.intervalMinimum interval between memory scale-downs. When memory utilization stays below the set threshold within this window, the system adjusts or recommends a memory reduction. 4 hours parallelism.scale.maxMaximum parallelism. -1means unlimited. When integrated with ApsaraMQ for Kafka, Message Queue, Simple Log Service, or other message queue services, the system automatically caps this at the partition count.-1 parallelism.scale.minMinimum parallelism. 1 delay-detector.scale-up.thresholdMaximum allowed source delay before triggering a scale-up. If insufficient processing capacity causes delay to reach this value, the system increases parallelism or unchains operators to improve throughput. 1 minute slot-usage-detector.scale-up.thresholdUpper usage rate threshold for compute/IO resources of non-source operators. Flink increases parallelism when an operator's processing time ratio stays above this value. 0.8 slot-usage-detector.scale-down.thresholdLower usage rate threshold for compute/IO resources of non-source operators. Flink reduces parallelism when an operator's processing time ratio stays below this value. 0.2 slot-usage-detector.scale-up.sample-intervalInterval at which Flink samples non-source operator busy rates and compares against the scale-up and scale-down thresholds. 3 minutes resources.memory-scale-up.maxMaximum TaskManager and JobManager memory size. When a TaskManager and the JobManager perform Autopilot or increase the parallelism, the upper limit of memory is 16 GiB. 16 GiB -
Click Save.
Save a resource plan
When a job using the stable strategy converges, the system generates a resource plan you can save and apply. Two plan types are available:
| Plan type | Description | What happens when applied |
|---|---|---|
| Fixed resource plan | A single resource configuration with no time dimension. | The deployment's resource configuration is updated with the saved values and applied at the next start. |
| Scheduled plan (public preview) | Multiple resource configurations, each tied to a time period. | The tuning mode automatically switches to scheduled tuning. Resources are not adjusted after the job runs stably. |
To save and apply a fixed resource plan:
In the Autopilot Mode Applying banner, click Details. On the panel that appears, set Recommended Plan to Specified resource and click Save. In the confirmation dialog, click Confirm.
To save and apply a scheduled plan:
Configure and apply a scheduled tuning plan
Create and apply a scheduled plan
-
Go to the scheduled plan configuration page.
-
Log on to the Realtime Compute for Apache Flink console.
-
Find the target workspace and click Console in the Actions column.
-
In the left-side navigation pane, choose O&M > Deployments, then click the name of the target deployment.
-
On the Resources tab, select the Scheduled Mode subtab.
-
-
Click New Plan.
-
In the Resource Setting section of the New Plan panel, configure the plan:
-
Trigger Period: Select No Repeat, Every Day, Every Week, or Every Month. For weekly or monthly periods, specify the dates on which the plan takes effect.
-
Trigger Time: Set the time at which the plan takes effect.
-
Mode: Select Basic or Expert. For details, see Configure job resources.
-
Other parameters: See Runtime parameter configuration.
-
-
(Optional) Click New Resource Setting Period to add more time periods to the plan and configure their trigger times and resource settings.
ImportantThe interval between trigger times must exceed 30 minutes.
-
In the Resource Plans section of the Scheduled Mode subtab, find the plan and click Apply in the Actions column.
Save and apply a scheduled plan
When a job using Autopilot's stable strategy converges, the system automatically generates a scheduled plan based on observed resource usage. You can view, modify, save, and apply this plan.
-
Go to the Autopilot configuration page.
-
Log on to the Realtime Compute for Apache Flink console.
-
Find the target workspace and click Console in the Actions column.
-
In the left-side navigation pane, choose O&M > Deployments, then click the name of the target deployment.
-
Click the Resources tab.
-
-
In the Autopilot Mode Applying banner, click Details. On the panel that appears, set Recommended Plan to Scheduled plan.
-
Configure the plan:
Action Description Notes Specify Max Change Count Set the maximum number of resource changes applied to the scheduled plan. Allowed range: 2–5. Click Merge time periods Merge time periods based on the specified max change count. Scale resources up or down before merging to match your business requirements. -
Review and modify the merged resource configurations. For details, see Configure job resources.
-
Click Save in the lower-left corner.
-
In the dialog box, enter a Scheduled plan name or select Apply this plan immediately, then click Confirm. After the plan is applied, the tuning mode automatically switches to scheduled tuning. Autopilot stops adjusting resources once the job runs stably.
Example
This example uses a daily traffic pattern: peak hours from 09:00:00 to 19:00:00 with 30 compute units (CUs), and off-peak hours from 19:00:00 to 09:00:00 the next day with 10 CUs.
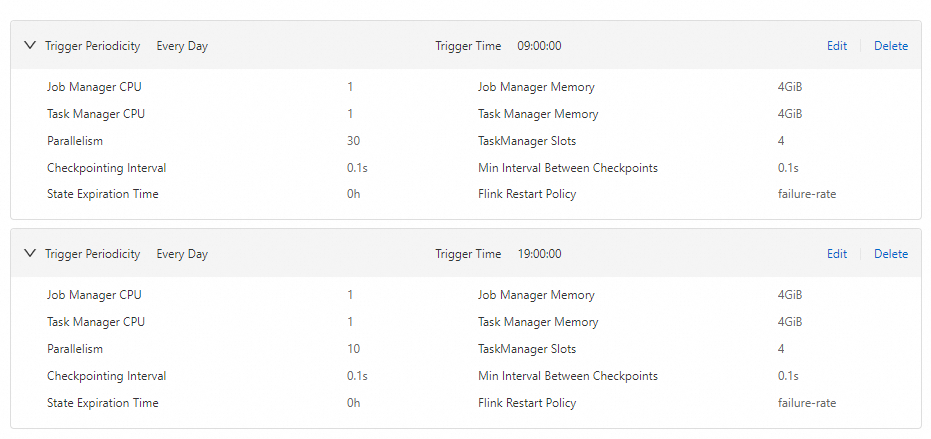
What's next
-
Use the intelligent deployment diagnostics feature to monitor deployment health and ensure business stability. For details, see Perform intelligent job diagnostics.
-
Improve Flink SQL deployment performance through deployment configurations and query optimization. For details, see Optimize Flink SQL.