You can use the Event Center to view system O&M events for Alibaba Cloud Elasticsearch (ES). This helps you promptly detect service anomalies and quickly analyze and locate issues. This topic describes the event categories for ES and how to view and handle events.
Event categories
ES events are categorized by cause and impact as follows.
For more information, see Appendix: Event details.
Event category | Definition | Cause and impact | Examples |
System change | System change events are initiated by Alibaba Cloud. You are notified of these events and must check if your cluster is affected. | System change events caused by infrastructure changes or faults may affect cluster access. When this type of event is triggered, the system sends a notification. Check the notification and your cluster status promptly. |
|
Cluster health | The system regularly inspects cluster health based on actual usage. It displays unexpected diagnostic results as events. | To ensure the sustainability of the Alibaba Cloud service, the system automatically triggers a cluster health event when it detects a cluster resource anomaly or risk. This minimizes the impact. Note During the execution of an O&M event, the cluster may experience brief jitter but normal access is not affected. If automatic execution fails, you can manually trigger a node restart on the Event Center page. The manual intervention window is 24 to | An inspection finds that an ES node is offline. |
Cluster change | These are operation events that you initiate to change a cluster. Failures or blocks can occur during the change process. | Cluster change events caused by instance type changes or kernel upgrades trigger a restart of the corresponding nodes. During the execution of an O&M event, the cluster may experience brief jitter but normal access is not affected. |
|
View and handle events
On the Event Center page, you can view information about events generated under the current account and handle them as needed.
Go to the Event Center.
Log on to the Alibaba Cloud Elasticsearch console.
In the navigation pane on the left, click Event Center.
View event information.
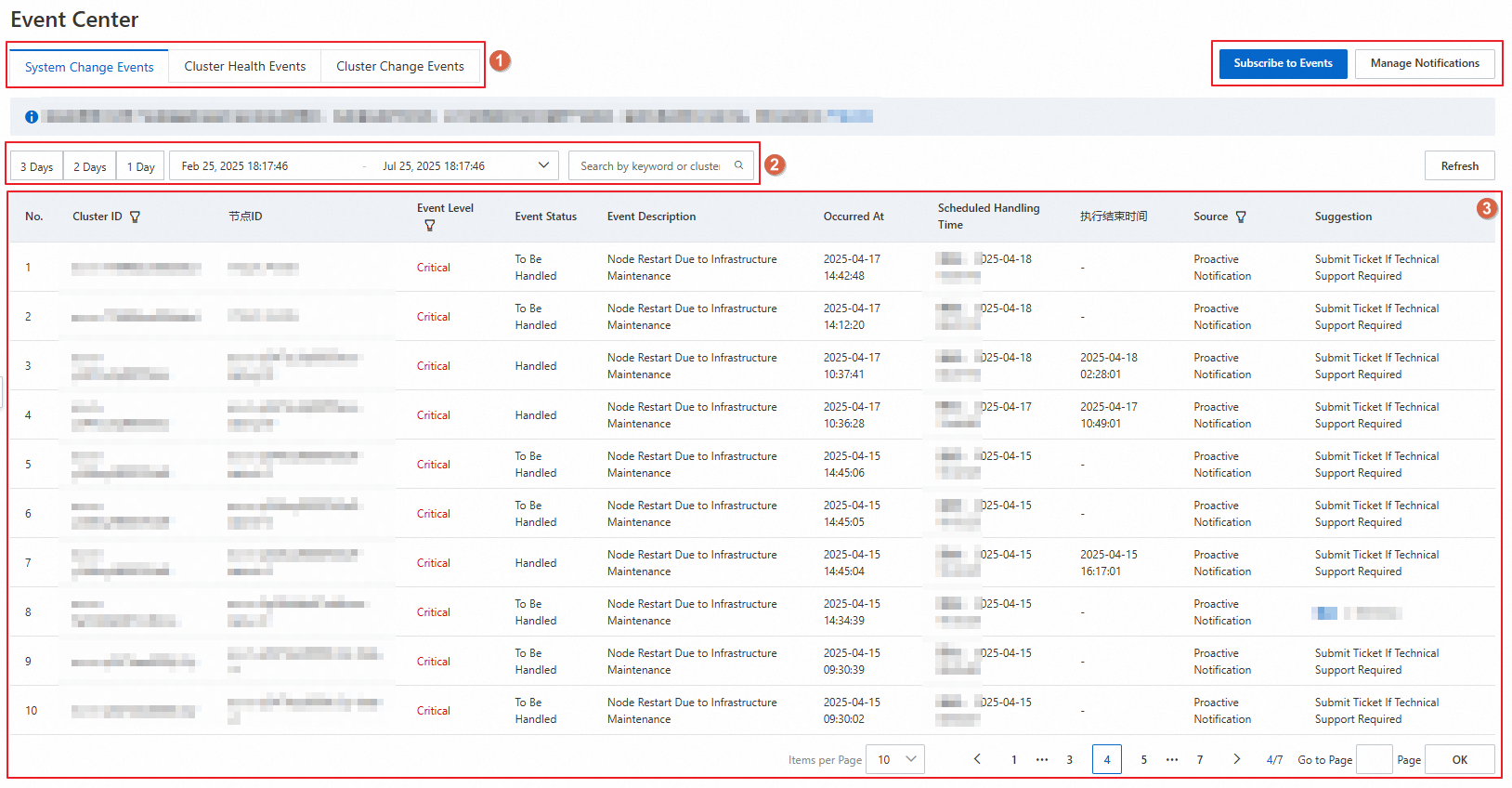
On the Event Center page, you can filter by conditions to view all events for a target instance of a selected type within a specified time period. Then, you can perform operations based on the event details.
 Note
NoteYou can view all event information in the Event Center. You can also subscribe to events and set notifications for critical alerts that require prompt handling. When an alert is triggered, the system automatically sends an alert notification to the specified alert contacts by phone, text message, or email.
The event information and related handling operations are described in the following table.
Event information
Description
Cluster ID
The ID of the Alibaba Cloud ES instance that generated the event.
Node ID
The ID of the instance node that generated the event.
Event Level
The severity of the event. Levels include the following:
Info: Records the status or operations of the system during normal operation. Often used for system status observation or debugging.
Warning: A potential issue or anomaly exists in the system but does not affect the current operation. Continuous monitoring is required.
Critical: A serious error or fault has occurred in the system. Immediate handling is required. Otherwise, service unavailability or data loss may occur.
Event Status
The execution status of the event. Statuses include To Be Handled, In Progress, Handled, Handling Failed, Handling Interrupted, Canceled, Execution to be confirmed, and Ready to continue. Among them:
To Be Handled: The event is waiting to be executed at the system-set time or your scheduled time.
Execution to be confirmed: You can decide whether to execute the event immediately or create a snapshot backup for the event based on the event details.
NoteOnly some events related to local disks in system change events support this status.
Only deployment events, such as an ES cluster upgrade or deploying a new version to a specified node, support snapshot backups.
Ready to continue: The current change task has completed the grayscale change. You need to confirm the stability of the changed nodes and cluster and decide whether to execute subsequent tasks. For example, a change operation needs to be tested on some nodes first. After the change is verified in a small scope, it is then executed on all nodes.
For events in the Handling Failed or Handling Interrupted state, find the cause and handle them promptly to avoid affecting normal business operations.
Event Description
The cause and impact of the event.
Occurred At and Ended At
The start and end time of the event execution.
Scheduled Handling Time and Execution End Time
The scheduled start time and estimated end time of the event.
NoteOnly system change events support this setting.
Source
The source of the event. Sources include the following:
Proactive Notification: ES proactively pushes events to Event Center after they are generated.
Event Subscription: You subscribe to listen for specified events. When an event occurs, the system receives a corresponding notification.
Suggestion
You can handle related events based on the recommended operations. The supported handling operations vary for different events. The actual interface prevails.
Contact Technical Support: If you have questions about an event, you can contact technical support for consultation.
Restart: Immediately restart the specified node of the related instance.
Schedule Restart: You must specify a restart time. The system will restart the specified node of the related instance at the scheduled time. The node restart time must be at least
5minutes later than the scheduled time. The system will restart the node for you within5minutes of the scheduled time.
NoteWhen you restart, forcibly restart, or perform a grayscale restart on the current instance or node, the system automatically triggers the execution of a restart event for that instance or node. However, for redeployment events, such as an ES version upgrade, you still need to submit a ticket to contact technical support personnel.
Appendix: Event details
Event type | Event code and name | Event level | CloudMonitor event name | Description and impact |
System change event |
| Critical |
| An infrastructure failure makes the local disk unavailable. |
| Critical |
| The performance of the cloud disk is degraded due to an infrastructure failure. | |
| Critical |
| The instance may stop due to a potential infrastructure failure. | |
| Critical |
|
| |
| Warning |
|
| |
Cluster health event |
| Critical |
| The instance restarts due to an abnormal cluster status. |
Cluster change event |
| Info |
|
|
| Info |
|
| |
| Info |
| The instance restarts due to a kernel version update. |