You can use Alibaba Cloud Filebeat to collect the logs of Container Service for Kubernetes (ACK) clusters and send the collected logs to Alibaba Cloud Elasticsearch for analysis and presentation. This topic describes how to configure a Filebeat shipper to collect the logs of an ACK cluster and how to view the resources that are deployed in the ACK cluster for the shipper.
Prerequisites
An Alibaba Cloud Elasticsearch cluster is created.
For more information, see Create an Alibaba Cloud Elasticsearch cluster.
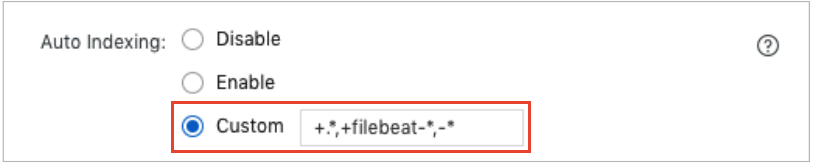
The Auto Indexing feature is enabled for the Elasticsearch cluster, and a prefix is customized for the names of indexes that will be automatically created based on the feature.
To avoid conflicts between the aliases of the indexes that are generated during a rollover and the names of the indexes, we recommend that you customize the filebeat- prefix for index names. You can enter +.*,+filebeat-*,-* in the Custom field. For more information, see Configure the YML file.
 Important
ImportantIf you enable the Rolling Update feature when you configure lifecycle management for indexes in your Elasticsearch cluster, you must disable the Auto Indexing feature to avoid conflicts between the aliases of the indexes that are generated after rolling updates and the names of the indexes. If you do not enable the Rolling Update feature for indexes, you must enable the Auto Indexing feature. We recommend that you customize a prefix for index names.
The permissions on Beats and ACK clusters are granted to a RAM user.
For more information, see Create a custom policy and Grant permissions to a RAM user.
An ACK cluster is created, and a pod is created in the cluster. In this example, an NGINX container is used.
For more information, see Create an ACK managed cluster.
Precautions
Alibaba Cloud Filebeat shippers support only Docker containers. The shippers do not support containers such as containerd containers and sandboxed containers. If you use containers other than Docker containers, Filebeat shippers are stuck in the active state after the shippers are created.
Alibaba Cloud Filebeat shippers can be installed only on ACK dedicated clusters or ACK managed clusters.
ImportantFilebeat shippers can be installed on Kubernetes clusters only of 1.18 or 1.20.
Procedure
- Log on to the Alibaba Cloud Elasticsearch console.
- Navigate to the Beats Data Shippers page.
- In the top navigation bar, select a region.
- In the left-side navigation pane, click Beats Data Shippers.
- Optional:If this is the first time you go to the Beats Data Shippers page, view the information displayed in the message that appears and click OK to authorize the system to create a service-linked role for your account. Note When Beats collects data from various data sources, Beats depends on the service-linked role and the rules specified for the role. Do not delete the service-linked role. Otherwise, the use of Beats is affected. For more information, see Overview of the Elasticsearch service-linked role
In the Create Shipper section, move the pointer over Filebeat and click ACK Logs.
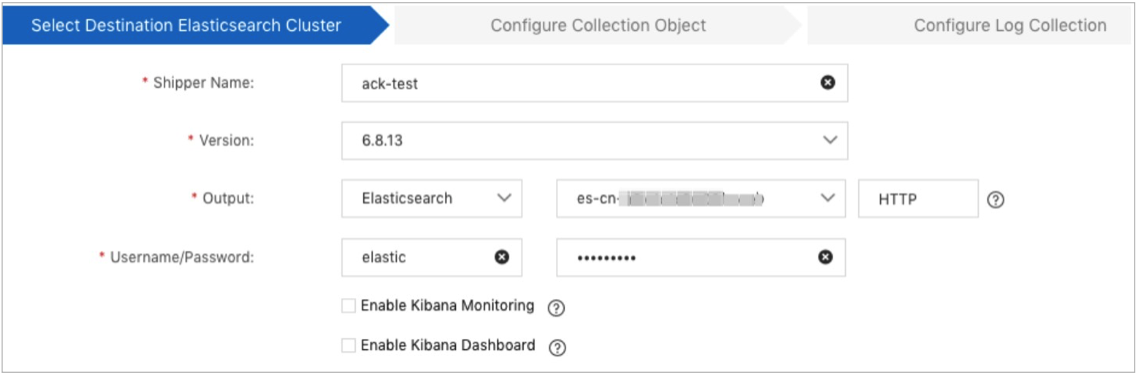
In the Select Destination Elasticsearch Cluster step, configure the parameters.
Parameter
Description
Shipper Name
The name of the shipper. The name must be 1 to 30 characters in length and can contain letters, digits, underscores (_), and hyphens (-). The name must start with a letter.
Version
Set this parameter to 6.8.13, which is the only version supported by Filebeat.
Output
The destination for the data collected by the shipper. The destination is the Elasticsearch cluster that you created. The protocol must be the same as that of the selected Elasticsearch cluster.
ImportantElasticsearch V8.X clusters are not supported.
Username/Password
The username and password that are used to access the Elasticsearch cluster. The default username is elastic. The password is specified when you create the Elasticsearch cluster. If you forget the password, you can reset it. For more information about the procedure and precautions for resetting the password, see Reset the access password of an Elasticsearch cluster.
Enable Kibana Monitoring
Specifies whether to monitor the metrics of the shipper. If you select Elasticsearch for Output, the Kibana monitor uses the Elasticsearch cluster that you configured for the Output parameter as the destination.
Enable Kibana Dashboard
Specifies whether to enable the default Kibana dashboard. Alibaba Cloud Kibana is deployed in a virtual private cloud (VPC). You must enable the Private Network Access feature for Kibana on the Kibana Configuration page. For more information, see Configure a public or private IP address whitelist for Kibana.
Click Next. In the Configure Collection Object step, configure a collection object.
Select the desired ACK cluster from the Source ACK Cluster drop-down list.
ImportantYou must select a running ACK cluster that resides in the same VPC as the Elasticsearch cluster and is not an ACK edge cluster. For more information, see What is ACK Edge?
Click Install to install ES-operator for the ACK cluster. Beats is dependent on ES-operator.
If the Install button is not displayed, ES-operator is installed. If the Install button is not displayed after you install ES-operator, the installation is successful.
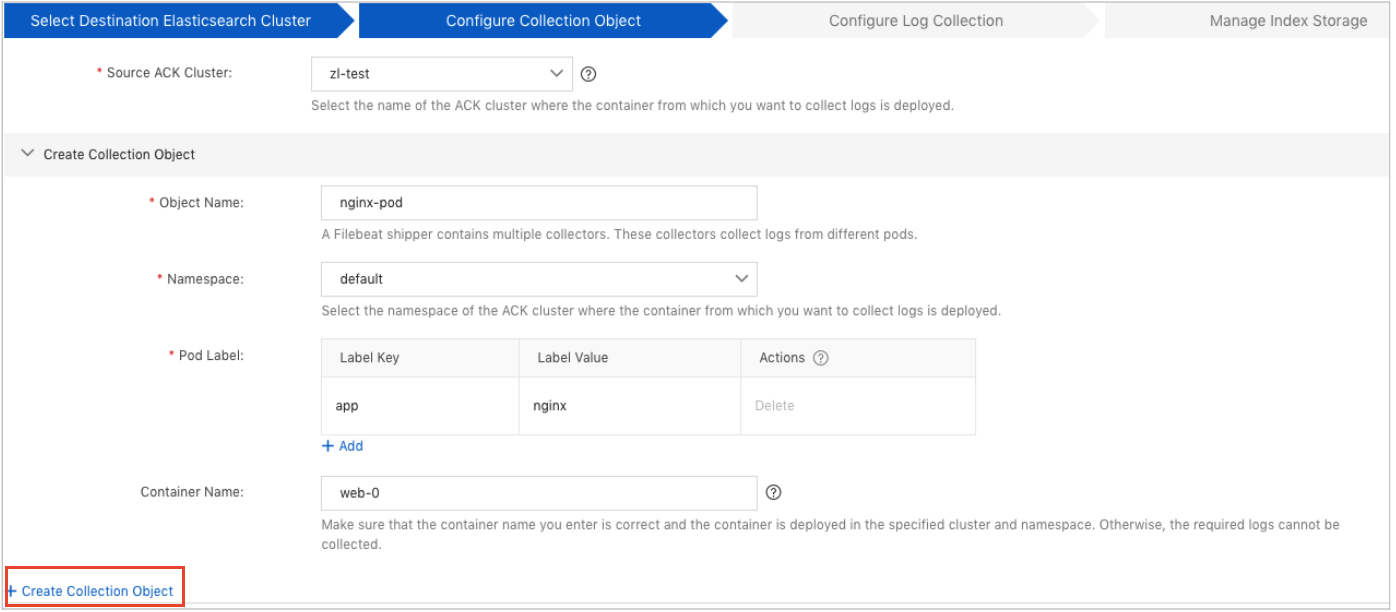
Click Create Collection Object in the lower-left corner to configure a collection object. You can configure multiple collection objects.
Parameter
Description
Object Name
The name of the collection object. You can create multiple collection objects. The name of each collection object must be unique.
Namespace
The namespace of the ACK cluster in which the pod from which you want to collect logs is deployed. By default, the namespace default is used if you do not specify a namespace when you create the pod.
Pod Label
The label of the pod. You can specify multiple labels. The specified labels have logical AND relations.
ImportantYou can delete the labels that you specified only if at least two labels are specified.
You can specify only the labels defined for the pod. If you specify the labels defined for other objects such as Deployments, the shipper fails to be created.
Container Name
The complete name of the container. If you leave this parameter empty, the shipper collects logs from all the containers in the namespace that comply with the labels added to the pod.
NoteFor more information about how to obtain the configurations of the pod, such as the namespace, labels, and name, see Manage pods.
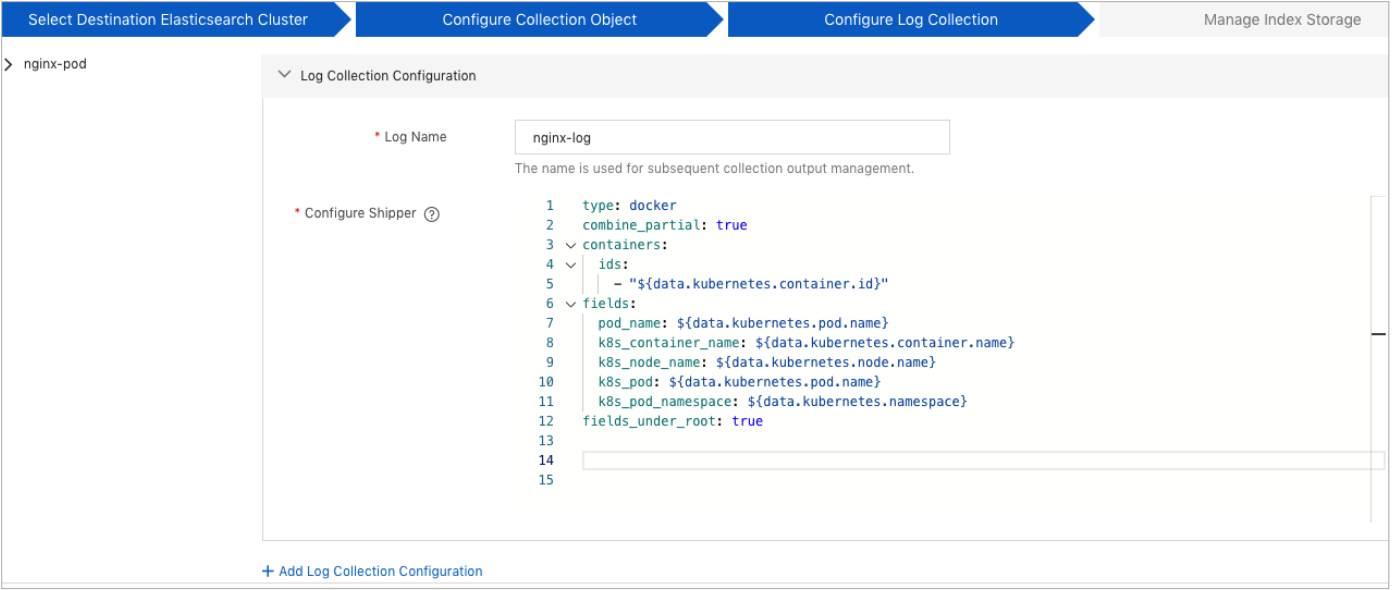
Click Next. In the Configure Log Collection step, click Add Log Collection Configuration in the lower-left corner to configure log collection information. You can specify multiple containers from which you want to collect logs.
Parameter
Description
Log Name
You can specify multiple containers for each pod. Each container corresponds to a log name. Each log name must be unique. A log name can be a part of an index name and used for subsequent collection output.
Configure Shipper
The general template for collecting logs from a Docker container is used. The Autodiscover provider is integrated into the log collection configuration. The collection configuration supports Docker inputs.
type: the input type. If you want to collect logs from containers, the value of this parameter is docker. The value of this parameter varies based on the input type. For more information, see Configure inputs.
combine_partial: specifies whether to enable partial message joining. For more information, see Docker input (combine_partial).
container ids: the IDs of the Docker containers from which you want to collect logs. For more information, see Docker input (containers.ids).
fields.k8s_container_name: Add the k8s_container_name field to the output information of the shipper to reference the variable ${data.kubernetes.container.name}.
NoteThe Autodiscover provider is integrated into the Docker container configuration. You can reference the configuration of the Autodiscover provider to configure the Docker container.
fileds.k8s_node_name: Add the k8s_node_name field to the output information of the shipper to reference the variable ${data.kubernetes.node.name}.
fileds.k8s_pod: Add the k8s_pod field to the output information of the shipper to reference the variable ${data.kubernetes.pod.name}.
fileds.k8s_pod_namespace: Add the k8s_pod_namespace field to the output information of the shipper to reference the variable ${data.kubernetes.namespace}.
fields_under_root: If you set this parameter to true, the fields are stored as top-level fields in the output document. For more information, see Docker input (fields_under_root).
NoteIf the general template cannot meet your requirements, you can modify the configurations. For more information, see Filebeat Docker input.
You can configure only one Docker container in each collection configuration. If you want to configure multiple Docker containers, click Add Log Collection Configuration to perform the operation.
(Optional) Click Next. In the Manage Index Storage step, enable and configure the Index Storage Management for Collected Data feature based on your business requirements.
After you enable the Index Storage Management for Collected Data feature, click Add Management Policy to create and configure an index management policy. You can configure multiple index management policies. To create and configure an index management policy, configure the following parameters.
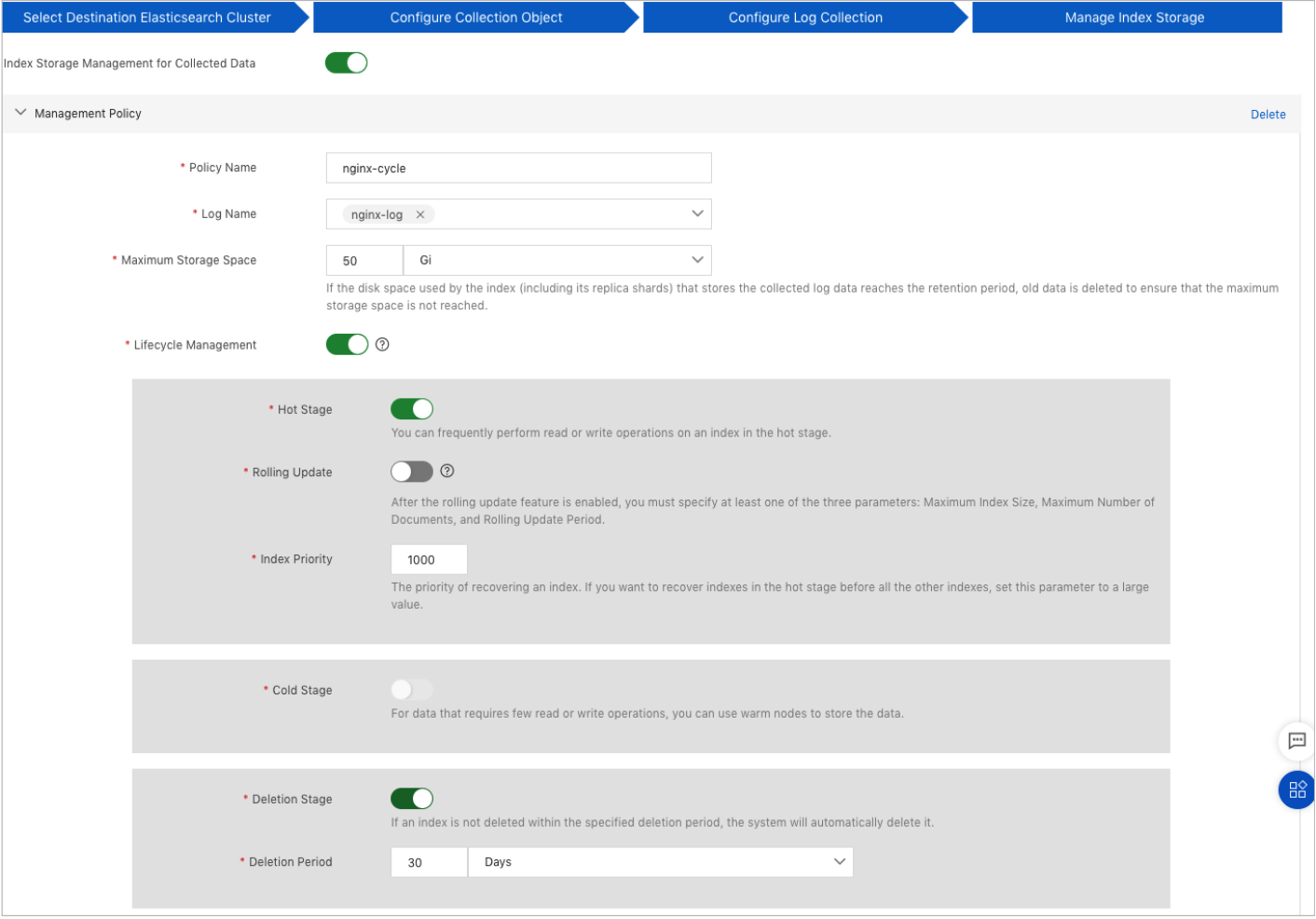
Parameter
Description
Policy Name
The name of the policy. You can customize a name.
Log Name
The name of the log file that you want to associate with the policy. You must select at least one name. Multiple log files can be associated with the same policy, but each log file can be associated with only one policy.
Maximum Storage Space
If the disk space consumed by an index (including the replica shards of the index) reaches the value of this parameter, the system deletes old data to save disk space.
Lifecycle Management
Specifies whether to enable lifecycle management for the index. After you turn on Lifecycle Management, the system separates hot data from cold data for data nodes and automatically deletes old data.
ImportantIf you turn on Rolling Update, the shipper writes data to an index whose name is in the <Log name>-<Date>-<Serial number> format, such as log-web-2021.01.22-000001.
If you do not turn on Rolling Update, the shipper writes data to an index whose name is in the filebeat-<Log name>-<Date> format.
Click Enable.
After the shipper is enabled, you can view the information about the shipper in the Manage Shippers section. You can also perform the operations provided in the following table.
NoteBy default, resources for the shipper are deployed in the logging namespace of the ACK cluster. After the resources are deployed, you can access the ACK cluster to view the resources, such as containers for index management and the rolling update policy for index lifecycles. For more information, see View the resources deployed in the ACK cluster for the shipper.
Operation
Description
View Configuration
View information such as the destination Elasticsearch cluster, source ACK cluster, and name of the log collection task of the shipper. You cannot modify the information.
Modify Configuration
Modify collection objects, log collection configurations, and index storage management policies.
More
Enable, disable, restart, or delete the log collection task, and view the information about the task in the dashboard and helm charts.
View the resources deployed in the ACK cluster for the shipper
Run the following command, use kubectl to connect to the ACK cluster, and view the resources for the shipper in the logging namespace. For more information, see Obtain the kubeconfig file of a cluster and use kubectl to connect to the cluster.
kubectl get pods -n logging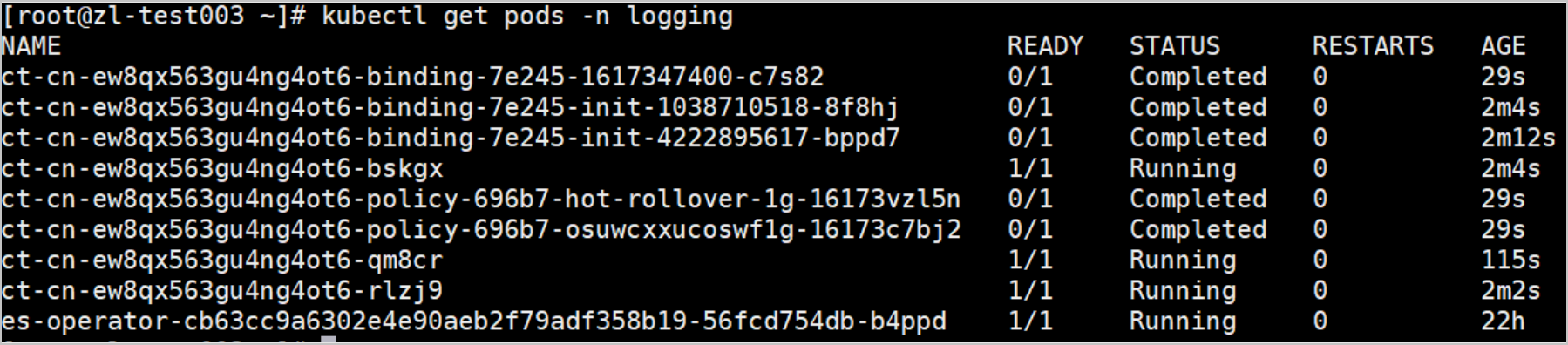
You are not allowed to delete the resources that are deployed in the logging namespace or perform other operations on the resources. If you perform operations on the resources, the shipper cannot run as expected.
Pod name | Description | Example |
Cluster name-binding-Serial number | The container that is used to manage indexes, such as a container that is used to delete old data on a regular basis. | ct-cn-ew8qx563gu4ng4ot6-binding-7e245-1617347400-c**** |
Cluster name-policy-Serial number | The policy for rolling updates on indexes. | ct-cn-ew8qx563gu4ng4ot6-policy-696b7-hot-rollover-1g-16173v**** |
Cluster name-Serial number | The container for which the shipper is installed. | ct-cn-ew8qx563gu4ng4ot6-q**** |
es-operator-Serial number | The container for which ES-operator is installed. | es-operator-cb63cc9a6302e4e90aeb2f79adf358b19-56fcd754db-b**** |