EMR on ACK supports three ways to submit a Spark job: using a Custom Resource Definition (CRD), running the spark-submit command via the emr-spark-ack tool, or using the EMR console.
Prerequisites
Before you begin, make sure you have:
A Spark cluster created on the EMR on ACK page. For details, see Create a cluster.
Usage notes
The examples use a JAR file packaged directly into the Spark image (local:///opt/spark/examples/spark-examples.jar). To use your own JAR file, upload it to Object Storage Service (OSS) and replace the path with the OSS path in the oss://<yourBucketName>/<path>.jar format. For details, see Simple upload.
Choose a submission method
| Method | Best for |
|---|---|
| CRD | Declarative, Kubernetes-native job management. Define the full job spec in a YAML file and let the Spark operator handle the lifecycle. |
| spark-submit (`emr-spark-ack`) | Familiar spark-submit syntax with support for cluster mode, interactive spark-shell, and automatic upload of local file dependencies (Spark 3 or later, EMR V5.X). |
| EMR console | Quick interactive queries or one-off jobs without leaving the browser. |
Method 1: Submit a Spark job using a CRD
Connect to the ACK cluster using kubectl. For details, see Obtain the kubeconfig file of a cluster and use kubectl to connect to the cluster.
Create a file named
spark-pi.yamlwith the following content:apiVersion: "sparkoperator.k8s.io/v1beta2" kind: SparkApplication metadata: name: spark-pi-simple spec: type: Scala sparkVersion: 3.2.1 mainClass: org.apache.spark.examples.SparkPi mainApplicationFile: "local:///opt/spark/examples/spark-examples.jar" arguments: - "1000" driver: cores: 1 coreLimit: 1000m memory: 4g executor: cores: 1 coreLimit: 1000m memory: 8g memoryOverhead: 1g instances: 1The example uses Spark 3.2.1 for EMR V5.6.0. Adjust
sparkVersionto match your EMR version. For all supported fields, see the spark-on-k8s-operator API reference.Submit the job:
kubectl apply -f spark-pi.yaml --namespace <your-namespace>Replace
<your-namespace>with the namespace where your cluster resides. To find the namespace, go to the Cluster Details tab in the EMR console. The expected output is:sparkapplication.sparkoperator.k8s.io/spark-pi-simple created(Optional) View the submitted job on the Job Details tab in the EMR console.
Method 2: Submit a Spark job using spark-submit
The emr-spark-ack tool wraps the standard Spark CLI for ACK clusters. It supports cluster mode, client mode (spark-sql, spark-shell, pyspark), and automatic upload of local file dependencies in Spark 3 or later for EMR V5.X.
Connect to the ACK cluster using kubectl. For details, see Obtain the kubeconfig file of a cluster and use kubectl to connect to the cluster.
Download the
emr-spark-acktool and make it executable:wget https://ecm-repo-cn-hangzhou.oss-cn-hangzhou.aliyuncs.com/emr-on-ack/util/emr-spark-ack chmod 755 emr-spark-ackSubmit a Spark job. The general syntax is:
./emr-spark-ack -n <your-namespace> <spark-command><spark-command>can bespark-submit,spark-sql,spark-shell, orpyspark.Cluster mode — spark-submit:
./emr-spark-ack -n <your-namespace> spark-submit \ --name spark-pi-submit \ --deploy-mode cluster \ --class org.apache.spark.examples.SparkPi \ local:///opt/spark/examples/spark-examples.jar \ 1000Client mode — spark-sql:
# Prepare a local SQL file echo "select 1+1" > test.sql # Submit the job ./emr-spark-ack -n <your-namespace> spark-sql -f test.sqlThe tool automatically uploads
test.sql(and any other local files specified via--jars,--files, or-f) to the Spark cluster before submitting.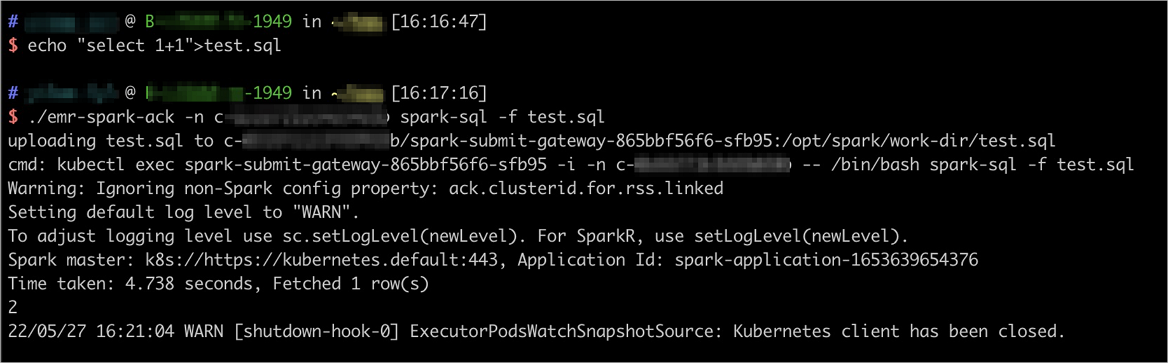
Client mode — spark-shell:
./emr-spark-ack -n <your-namespace> spark-shell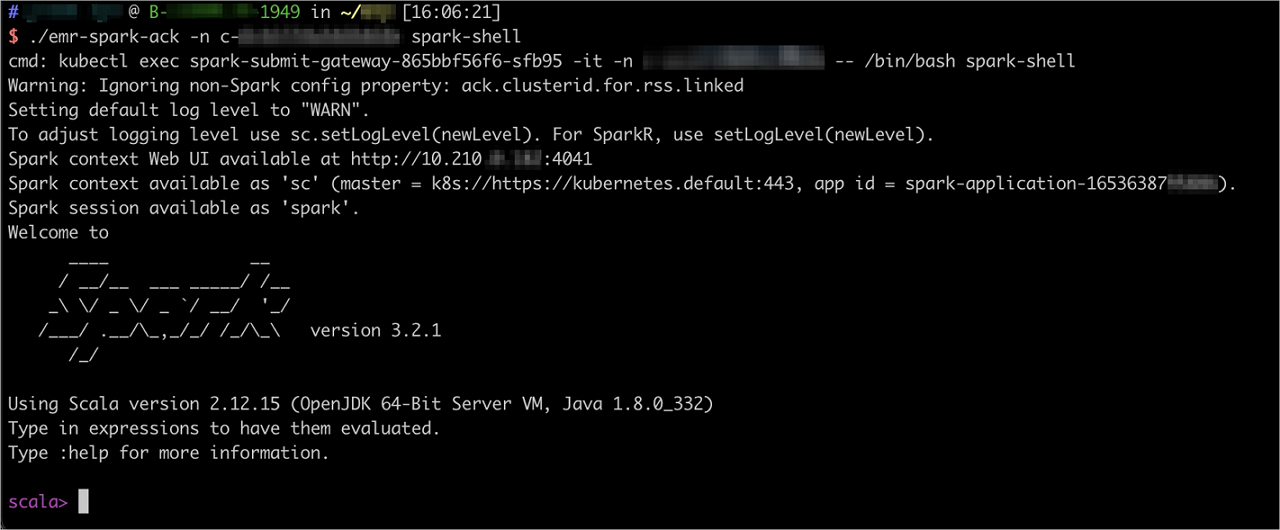
(Optional) View the submitted job on the Job Details tab in the EMR console.
(Optional) To stop a running job, use the
killsubcommand with the Spark application ID shown in the submission output:./emr-spark-ack -n <your-namespace> kill <Spark_app_id>
Method 3: Submit a Spark job in the EMR console
In the EMR console, click EMR on ACK in the left-side navigation pane.
On the EMR on ACK page, click the cluster name in the Cluster ID/Name column.
Click the Access Links and Ports tab, then click the link in the SparkSubmitGateway UI row. A browser-based Shell terminal opens.
In the Shell terminal, run one of the following commands: Interactive query with spark-sql:
spark-sqlBatch job with spark-submit:
spark-submit \ --name spark-pi-submit \ --deploy-mode cluster \ --class org.apache.spark.examples.SparkPi \ local:///opt/spark/examples/spark-examples.jar \ 1000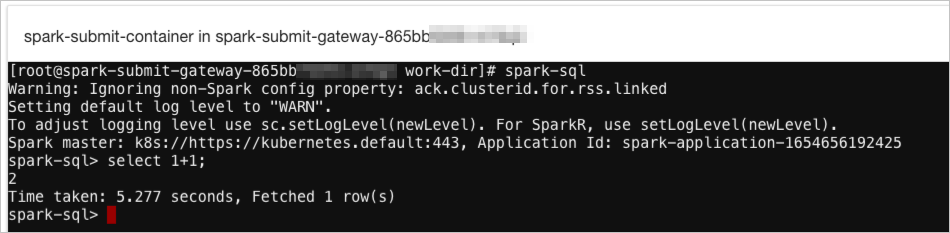
(Optional) View the submitted job on the Job Details tab.