If you want to search and analyze the production data in your ApsaraDB RDS for MySQL database by using Alibaba Cloud Elasticsearch, you can use Data Transmission Service (DTS) to synchronize the data to an Elasticsearch cluster in real time. The synchronization is implemented based on a real-time synchronization task. This solution is suitable for scenarios in which high performance of real-time synchronization is required. This topic describes how to create a real-time synchronization task to synchronize data from an ApsaraDB RDS for MySQL database to an Alibaba Cloud Elasticsearch cluster in real time. This topic also describes how to verify the synchronization results of full data and incremental data.
Background information
DTS is a data transmission service that integrates data migration, data subscription, and real-time data synchronization. For more information, see DTS. DTS supports synchronization of data changes generated by insert, delete, and update operations. For information about the versions of data sources from which DTS can synchronize data, see Overview of data synchronization scenarios.
You can use DTS to synchronize full or incremental data from MySQL to Elasticsearch. This solution is suitable for scenarios in which you require high performance of real-time synchronization from a relational database or you need to synchronize full or incremental data from a relational database to an Alibaba Cloud Elasticsearch cluster.
Precautions
DTS does not synchronize data changes generated by DDL operations. If a DDL operation is performed on a table in the source database during data synchronization, you must perform the following operations: Remove the table from the data synchronization task, remove the index for the table from the Elasticsearch cluster, and then add the table to the data synchronization task again. For more information, see Remove an object from a data synchronization task and Add an object to a data synchronization task.
If you want to add columns to the source table, modify the mappings of the index that corresponds to the table. Then, perform the related DDL operation on the source table, pause the data synchronization task, and start the task again.
DTS uses read and write resources of the source and destination during initial full data synchronization. This may increase the loads of the source and destination. If the performance of the source or destination is unfavorable, the specifications of the source or destination are low, or the data volume is large, the source or destination may become unavailable. For example, DTS occupies a large number of read and write resources in the following cases: a large number of slow SQL queries are performed on the source, one or more tables do not have primary keys, or a deadlock occurs on the destination. To prevent this issue, you must evaluate the impact of data synchronization on the performance of the source and destination before data synchronization. We recommend that you synchronize data during off-peak hours. For example, you can synchronize data when the CPU utilization of the source and destination is less than 30%.
If you synchronize full data during peak hours, the synchronization may fail. In this case, restart the synchronization task.
If you synchronize incremental data during peak hours, data synchronization latency may occur.
ApsaraDB RDS for MySQL and Elasticsearch support different data types. During initial schema synchronization, DTS establishes mappings between source fields and destination fields based on the data types supported by the destination. For more information, see Data type mappings for schema synchronization.
Process
Make preparations: Add the data to be synchronized to the source ApsaraDB RDS for MySQL database, create an Alibaba Cloud Elasticsearch cluster, and enable the Auto Indexing feature for the Elasticsearch cluster.
Create and run a data synchronization task: Create and run a data synchronization task in the DTS console.
Verify the data synchronization results: Log on to the Kibana console of the Elasticsearch cluster to verify the synchronization result of full data. Then, add data to the source ApsaraDB RDS for MySQL database and log on to the Kibana console of the Elasticsearch cluster to verify the synchronization result of incremental data.
Procedure
Step 1: Make preparations
In this example, an ApsaraDB RDS instance that runs MySQL 8.0 and an Alibaba Cloud Elasticsearch V7.10 cluster are prepared.
Prepare the source database and the data to be synchronized
Create an ApsaraDB RDS instance that runs MySQL 8.0. For more information, see Create an ApsaraDB RDS for MySQL instance.
Create an account and a database named
test_mysql. For more information, see Create accounts and databases.In the
test_mysqldatabase, create a table namedes_testand insert data into the table. In this example, the following statements are executed to create a table and insert data into the table:-- create table CREATE TABLE `es_test` ( `id` bigint(32) NOT NULL, `name` varchar(32) NULL, `age` bigint(32) NULL, `hobby` varchar(32) NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8; -- insert data INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (1,'user1',22,'music'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (2,'user2',23,'sport'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (3,'user3',43,'game'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (4,'user4',24,'run'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (5,'user5',42,'basketball');
Prepare the destination Elasticsearch cluster
Create an Alibaba Cloud Elasticsearch V7.10 cluster. For more information, see Create an Alibaba Cloud Elasticsearch cluster.
Enable the Auto Indexing feature for the Elasticsearch cluster. For more information, see Configure the YML file.
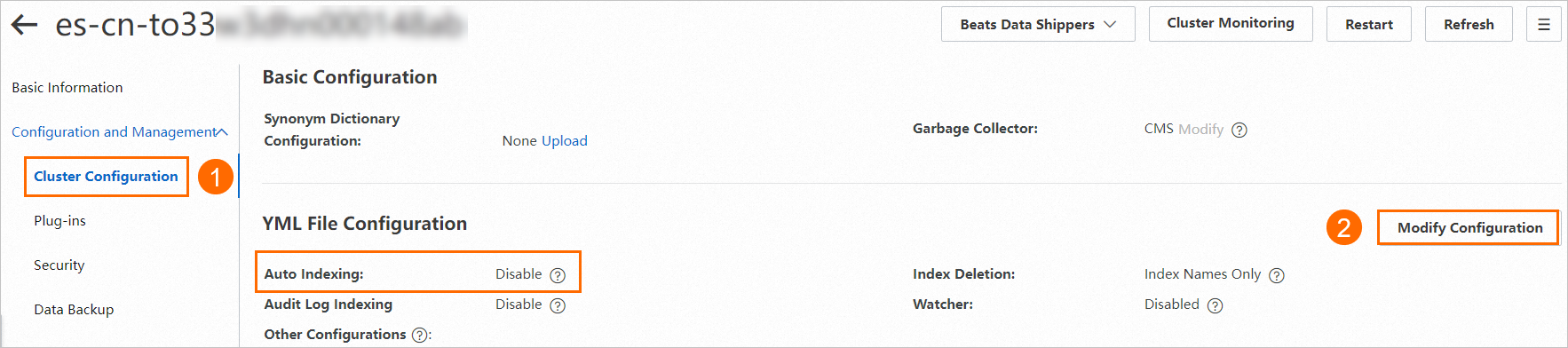
Step 2: Create and run a data synchronization task
Click Create Task.
On the page that appears, create and configure a data synchronization task as prompted.
NoteFor information about the parameters that are involved in the following steps, see Synchronize data from an ApsaraDB RDS for MySQL instance to an Elasticsearch cluster.
Configure the source and destination. In the lower part of the page, click Test Connectivity and Proceed.
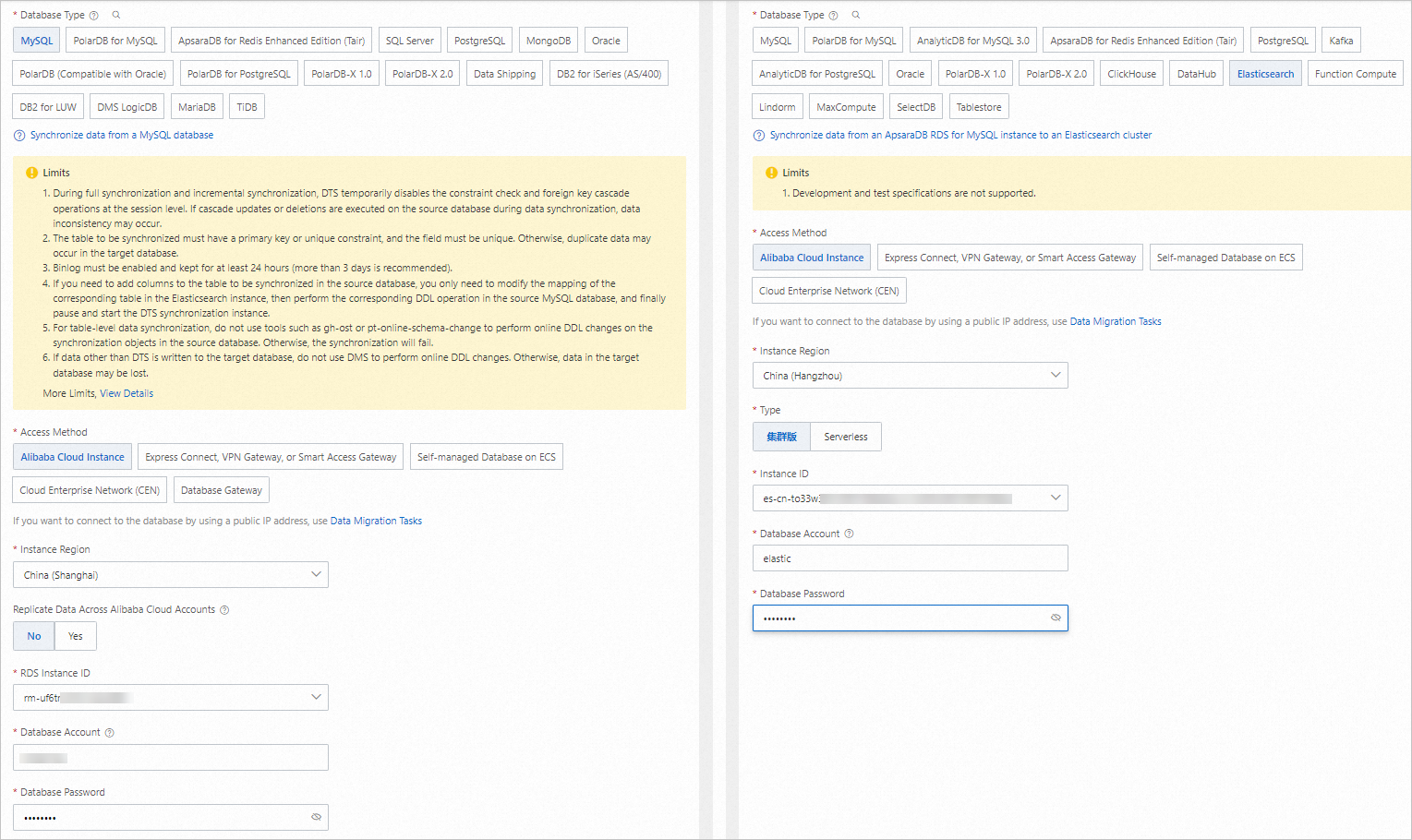
Configure the objects from which you want to synchronize data.
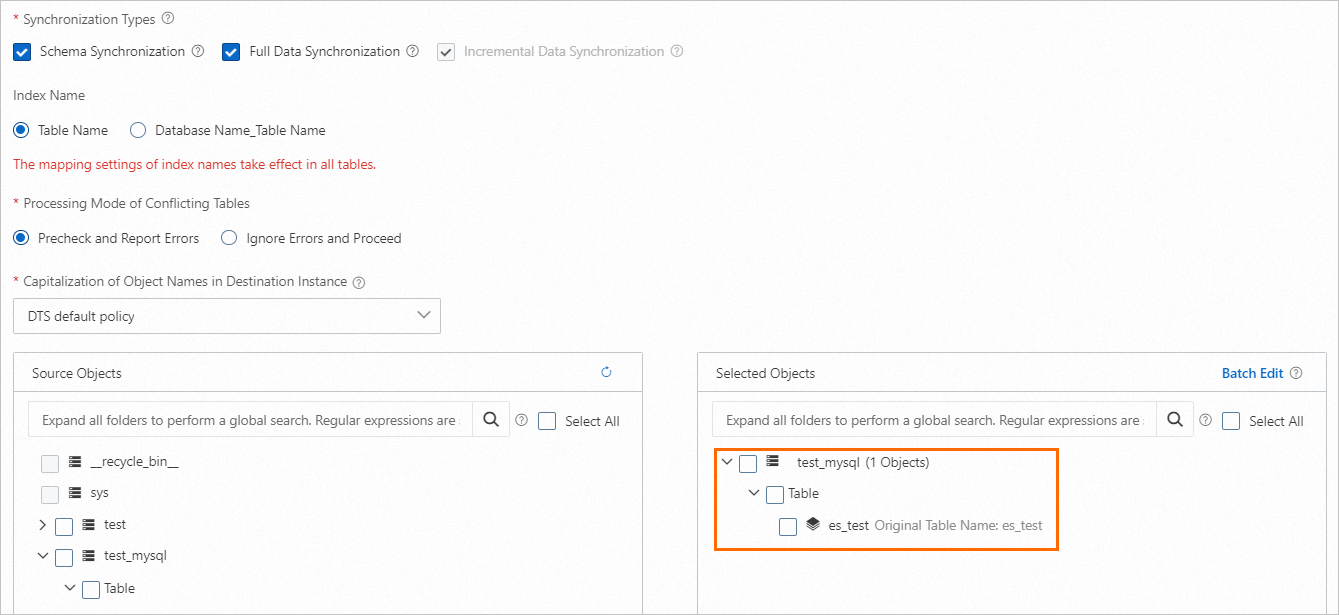
Configure advanced settings. In this example, the default advanced settings are used.
In the Data Verification substep, select Apply _routing Policy to No Tables.
NoteIf the destination Elasticsearch cluster is of V7.X, you must select Apply _routing Policy to No Tables.
After the configuration is complete, save the data synchronization task, perform a pre-check on the task, and purchase a DTS instance to start the data synchronization task.
After the DTS instance is purchased, the data synchronization task starts to run. You can view the data synchronization progress of the task on the Data Synchronization page. After the full data is synchronized, you can view the full data in the Elasticsearch cluster.

Step 3: (Optional) Verify the data synchronization results
Log on to the Kibana console of the Elasticsearch cluster.
For more information, see Log on to the Kibana console.
In the upper-left corner of the Kibana console, choose
 > Management > Dev Tools. On the page that appears, click the Console tab.
> Management > Dev Tools. On the page that appears, click the Console tab. Verify the synchronization result of full data.
Run the following command:
GET /es_test/_searchIf the command is successfully run, the following result is returned:
{ "took" : 10, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "es_test", "_type" : "es_test", "_id" : "3", "_score" : 1.0, "_source" : { "id" : 3, "name" : "user3", "age" : 43, "hobby" : "game" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "5", "_score" : 1.0, "_source" : { "id" : 5, "name" : "user5", "age" : 42, "hobby" : "basketball" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "4", "_score" : 1.0, "_source" : { "id" : 4, "name" : "user4", "age" : 24, "hobby" : "run" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "2", "_score" : 1.0, "_source" : { "id" : 2, "name" : "user2", "age" : 23, "hobby" : "sport" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "1", "_score" : 1.0, "_source" : { "id" : 1, "name" : "user1", "age" : 22, "hobby" : "music" } } ] } }Verify the synchronization result of incremental data.
Execute the following statement to insert a data record into the source table:
INSERT INTO `test_mysql`.`es_test` (`id`,`name`,`age`,`hobby`) VALUES (6,'user6',30,'dance');After the data record is synchronized, run the
GET /es_test/_searchcommand.If the command is successfully run, the following result is returned:
{ "took" : 541, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "es_test", "_type" : "es_test", "_id" : "3", "_score" : 1.0, "_source" : { "id" : 3, "name" : "user3", "age" : 43, "hobby" : "game" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "5", "_score" : 1.0, "_source" : { "id" : 5, "name" : "user5", "age" : 42, "hobby" : "basketball" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "4", "_score" : 1.0, "_source" : { "id" : 4, "name" : "user4", "age" : 24, "hobby" : "run" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "2", "_score" : 1.0, "_source" : { "id" : 2, "name" : "user2", "age" : 23, "hobby" : "sport" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "6", "_score" : 1.0, "_source" : { "name" : "user6", "id" : 6, "age" : 30, "hobby" : "dance" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "1", "_score" : 1.0, "_source" : { "id" : 1, "name" : "user1", "age" : 22, "hobby" : "music" } } ] } }