DNS resolution failures in Kubernetes are tricky to diagnose because the resolution pipeline spans multiple components — CoreDNS, kube-proxy, the Container Network Interface (CNI), and upstream DNS servers. This guide walks you through a structured process to isolate the root cause and apply the right fix.
Before diving into diagnostics, review Best practices for DNS services to reduce the risk of recurring DNS failures.
Key concepts
| Term | Definition |
|---|---|
| Internal domain name | Resolved by CoreDNS from its local cache. Always ends with .cluster.local. |
| External domain name | Resolved by an upstream DNS server (Alibaba Cloud DNS, Alibaba Cloud DNS PrivateZone, or a third-party provider). CoreDNS only forwards these queries. |
| Application pod | Any pod that is not a system component pod in the Kubernetes cluster. |
| NodeLocal DNSCache | A local DNS cache that intercepts pod DNS queries before they reach CoreDNS. Queries that NodeLocal DNSCache cannot resolve are forwarded to the kube-dns Service. |
Identify the error
Common error messages
Match your error message to identify the failure category:
| Client | Error message | Failure category |
|---|---|---|
ping | ping: xxx.yyy.zzz: Name or service not known | Domain not found, or DNS server unreachable (latency > 5s suggests unreachable) |
curl | curl: (6) Could not resolve host: xxx.yyy.zzz | Domain not found, or DNS server unreachable |
| PHP HTTP client | php_network_getaddresses: getaddrinfo failed: Name or service not known in xxx.php on line yyy | Domain not found, or DNS server unreachable |
| Go HTTP client | dial tcp: lookup xxx.yyy.zzz on 100.100.2.136:53: no such host | Domain does not exist |
dig | ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: xxxxx | Domain does not exist |
| Go HTTP client | dial tcp: lookup xxx.yyy.zzz on 100.100.2.139:53: read udp 192.168.0.100:42922->100.100.2.139:53: i/o timeout | DNS server unreachable |
dig | ;; connection timed out; no servers could be reached | DNS server unreachable |
Set up a debug pod
Before running any diagnostic commands, establish a clean observation environment. This eliminates ambiguity between application bugs and DNS bugs.
kubectl run -it --rm debug --image=nicolaka/netshoot -- digYou can also run the following command:
nslookup <Domain name>Diagnostic procedure
The following diagram shows the overall troubleshooting flow for CoreDNS and NodeLocal DNSCache failures.
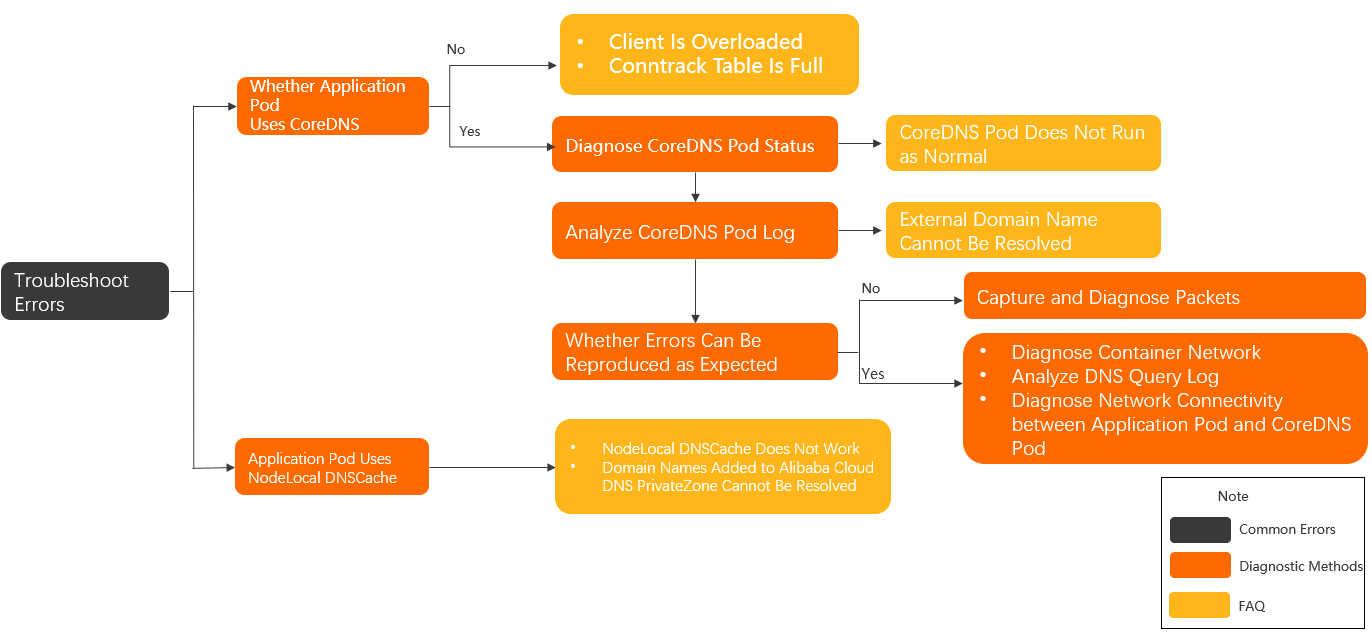
Step 1: Check the DNS configuration of the application pod
# Get the pod's YAML to check its dnsPolicy field
kubectl get pod <pod-name> -o yaml
# If dnsPolicy looks correct, inspect the in-container DNS config
kubectl exec -it <pod-name> -- cat /etc/resolv.confCheck whether nameserver points to CoreDNS or NodeLocal DNSCache:
CoreDNS (kube-dns Service IP, e.g.,
172.21.0.10): continue to Step 2.NodeLocal DNSCache (
169.254.20.10): see NodeLocal DNSCache issues.Neither (no cluster DNS configured): the pod may be running on an overloaded node, or the conntrack table may be full. See Client overload and Conntrack table full.
DNS policy reference
The following table describes the available dnsPolicy values and when to use each:
dnsPolicy value | Behavior |
|---|---|
ClusterFirst (default) | Uses the kube-dns Service IP as the DNS server. For host-network pods, behaves the same as Default. |
Default | Uses the DNS servers from the ECS instance's /etc/resolv.conf. Use this only if the pod does not need cluster-internal service discovery. |
ClusterFirstWithHostNet | Same as ClusterFirst but for host-network pods. |
None | Lets you specify custom DNS servers and options in dnsConfig. Used when NodeLocal DNSCache injects its configuration automatically. |
A pod configured for NodeLocal DNSCache typically looks like this:
apiVersion: v1
kind: Pod
metadata:
name: <pod-name>
namespace: <pod-namespace>
spec:
containers:
- image: <container-image>
name: <container-name>
dnsPolicy: None
dnsConfig:
nameservers:
- 169.254.20.10
- 172.21.0.10
options:
- name: ndots
value: "3"
- name: timeout
value: "1"
- name: attempts
value: "2"
searches:
- default.svc.cluster.local
- svc.cluster.local
- cluster.localStep 2: Check CoreDNS pod status
kubectl -n kube-system get pod -o wide -l k8s-app=kube-dnsExpected output (all pods in Running state):
NAME READY STATUS RESTARTS AGE IP NODE
coredns-xxxxxxxxx-xxxxx 1/1 Running 0 25h 172.20.6.53 cn-hangzhou.192.168.0.198Check resource usage:
kubectl -n kube-system top pod -l k8s-app=kube-dnsExpected output:
NAME CPU(cores) MEMORY(bytes)
coredns-xxxxxxxxx-xxxxx 3m 18MiIf a pod is not in Running state, describe it to find the cause:
kubectl -n kube-system describe pod <coredns-pod-name>See CoreDNS pods not running as expected for common error logs and fixes.
Step 3: Check CoreDNS operational logs
kubectl -n kube-system logs -f --tail=500 --timestamps <coredns-pod-name>| Flag | Effect |
|---|---|
-f | Streams live log output |
--tail=500 | Shows the last 500 lines |
--timestamps | Adds a timestamp to each log line |
Look for NXDOMAIN, SERVFAIL, or REFUSED responses in the logs. If any of these appear for external domain names, the upstream DNS server is returning errors. See External domain name cannot be resolved.
Step 4: Check whether the issue is reproducible
Always fails: proceed with Diagnose the DNS query log and Diagnose network connectivity between application pods and CoreDNS.
Intermittent: capture packets as described in Capture packets.
Diagnose the DNS query log
CoreDNS generates a query log entry for each DNS request only when the log plugin is enabled. To enable it, see Configure CoreDNS.
Run the same command used to query operational logs to view the DNS query logs. For more information, see Step 3: Check CoreDNS operational logs.
After saving, CoreDNS automatically reloads. Confirm by checking the logs for reload.
DNS query log format
[INFO] 172.20.2.25:44525 - 36259 "A IN redis-master.default.svc.cluster.local. udp 56 false 512" NOERROR qr,aa,rd 110 0.000116946sDNS response codes
For the full specification, see RFC 1035.
| Response code | Meaning | Common cause |
|---|---|---|
NOERROR | Resolved successfully | — |
NXDOMAIN | Domain does not exist in the upstream DNS server | Pod requests append search domain suffixes; a suffixed name that doesn't exist triggers this code |
SERVFAIL | Error in the upstream DNS server | Upstream DNS is unreachable or misconfigured |
REFUSED | Query rejected by the upstream DNS server | Upstream DNS server (in the CoreDNS config or node's /etc/resolv.conf) cannot resolve the domain |
If the log shows NXDOMAIN, SERVFAIL, or REFUSED for external domain names, the upstream DNS server is the root cause. By default, CoreDNS uses VPC DNS servers 100.100.2.136 and 100.100.2.138 as upstream resolvers. Submit a ticket to the ECS team and include:
| Field | Description | Example |
|---|---|---|
| Domain name | The external domain name from the log | www.aliyun.com |
| DNS response code | The response code in the log | NXDOMAIN |
| Time | Log entry timestamp (seconds precision) | 2022-12-22 20:00:03 |
| ECS instance IDs | IDs of the ECS instances running CoreDNS pods | i-xxxxx i-yyyyy |
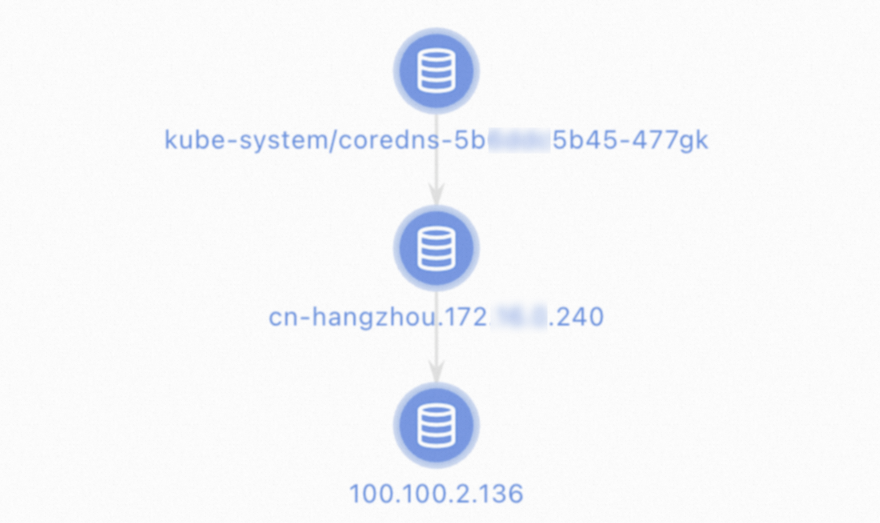
Diagnose network connectivity of the CoreDNS pod
Use either the ACK console or the CLI.
ACK console
Log on to the ACK console. In the left-side navigation pane, click Clusters.
On the Clusters page, click the cluster name. In the left-side navigation pane, choose Inspections and Diagnostics > Diagnostics.
On the Diagnosis page, click Network diagnosis.
In the Network panel, configure the following parameters: Read the warning, select I know and agree, then click Create diagnosis.
Source address: IP address of the CoreDNS pod
Destination address: IP address of the upstream DNS server (
100.100.2.136or100.100.2.138)Destination port:
53Protocol:
udp
On the Diagnosis result page, the Packet paths section shows all nodes that were diagnosed.
CLI
Log on to the node running the CoreDNS pod.
Get the CoreDNS process ID:
ps aux | grep corednsEnter the CoreDNS network namespace:
nsenter -t <pid> -n -- <related commands>Replace
<pid>with the process ID from the previous step.Test connectivity:
# Test connectivity to the Kubernetes API server telnet <apiserver_clusterip> 6443 # Test connectivity to upstream DNS servers dig <domain> @100.100.2.136 dig <domain> @100.100.2.138
| Issue | Cause | Action |
|---|---|---|
| CoreDNS cannot connect to the Kubernetes API server | API server errors, node overload, or kube-proxy issues | Submit a ticket |
| CoreDNS cannot connect to upstream DNS servers | Node overload, wrong CoreDNS config, or Express Connect routing issues | Submit a ticket |
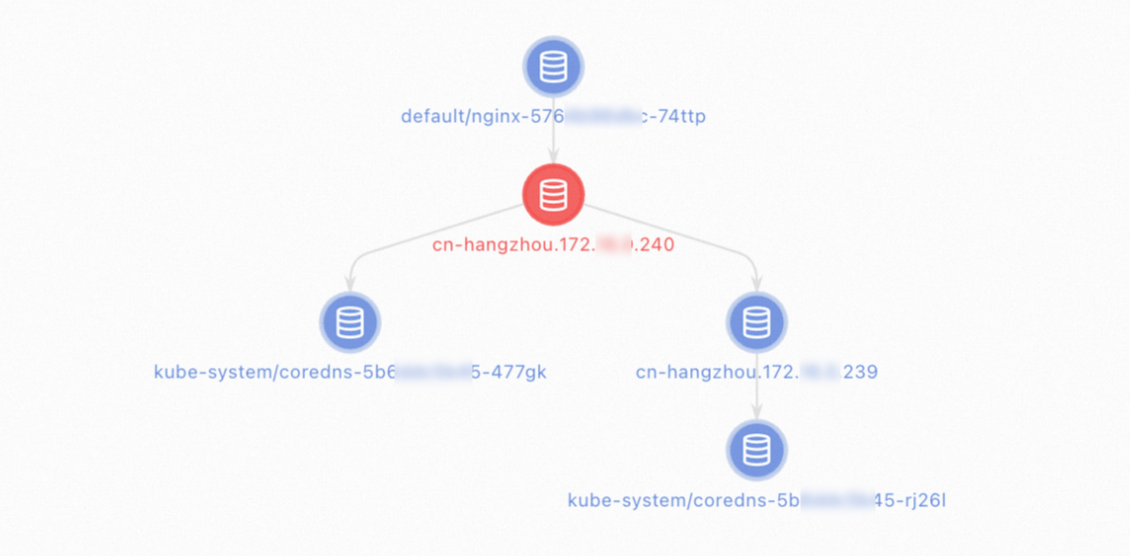
Diagnose network connectivity between application pods and CoreDNS
ACK console
Log on to the ACK console. In the left-side navigation pane, click Clusters.
On the Clusters page, click the cluster name. In the left-side navigation pane, choose Inspections and Diagnostics > Diagnostics.
On the Diagnosis page, click Network diagnosis.
In the Network panel, configure the following parameters: Read the warning, select I know and agree, then click Create diagnosis.
Source address: IP address of the application pod
Destination address: IP address of the CoreDNS pod or the cluster
Destination port:
53Protocol:
udp
On the Diagnosis result page, the Packet paths section shows all nodes that were diagnosed.
CLI
Connect to the application pod's network namespace using one of these methods:
Method 1 —
kubectl exec:kubectl exec -it <pod-name> -- bashMethod 2 —
nsenter(whenkubectl execis unavailable):ps aux | grep <application-process-name> nsenter -t <pid> -n bashMethod 3 — for pods that restart frequently:
Do not add a space between
-nand<netns-path>.docker ps -a | grep <application-container-name> docker inspect <sandboxed-container-id> | grep netns nsenter -n<netns-path> -n bash
From inside the pod's network namespace, test connectivity:
# Test connectivity to the kube-dns Service
dig <domain> @<kube_dns_svc_ip>
# Test ICMP reachability of the CoreDNS pod
ping <coredns_pod_ip>
# Test DNS resolution via the CoreDNS pod directly
dig <domain> @<coredns_pod_ip>| Issue | Cause | Action |
|---|---|---|
| Cannot connect to the kube-dns Service | Node overload, kube-proxy issues, or UDP port 53 blocked | Check whether security group rules allow UDP port 53. If they do, submit a ticket. |
| Cannot ping the CoreDNS pod | Container network errors or ICMP blocked by security group rules | Check whether ICMP is allowed. If it is, submit a ticket. |
dig to CoreDNS pod fails | Node overload or UDP port 53 blocked by security group rules | Check whether security group rules allow UDP port 53. If they do, submit a ticket. |
Capture packets
If you cannot identify the issue through logs and connectivity tests, capture packets to narrow down where packets are being dropped.
Log on to the nodes running the application pods and the CoreDNS pod.
Capture packets on each ECS instance:
Packet capture does not interrupt service. It causes a minor increase in CPU utilization and disk I/O. The command rotates files and generates at most 200
.pcapfiles, each up to 20 MB.tcpdump -i any port 53 -C 20 -W 200 -w /tmp/client_dns.pcapAnalyze the captured packets from the time period when the error occurred.
Other modules in the DNS resolution pipeline
In addition to CoreDNS and NodeLocal DNSCache, the following components can cause DNS resolution failures.

| Component | How it can cause failures |
|---|---|
| DNS resolver (Go, glibc, musl) | Language-level or library-level DNS implementation bugs can cause failures in rare cases |
/etc/resolv.conf | Misconfigured DNS server IPs or search domains in the container |
| kube-proxy | After a CoreDNS update, if kube-proxy rules are not updated, CoreDNS becomes unreachable |
| Upstream DNS servers | CoreDNS forwards external domain queries to upstream servers (such as VPC Private DNS). Misconfigurations on the upstream server cause forwarded queries to fail. |
FAQ
What to do if an external domain name cannot be resolved
Internal domain names resolve correctly, but external domain names fail.
Check the CoreDNS query log for NXDOMAIN, SERVFAIL, or REFUSED on the failing domain name. These codes indicate that the upstream DNS server (by default, 100.100.2.136 and 100.100.2.138) is returning an error. Submit a ticket to the ECS team with the domain name, response code, timestamp, and ECS instance IDs of the nodes running CoreDNS.
What to do if headless Service domain names cannot be resolved
CoreDNS cannot resolve headless Service domain names.
This typically happens with CoreDNS versions earlier than 1.7.0, which can exit unexpectedly during Kubernetes API server network jitters, leaving headless Service DNS records stale. Update CoreDNS to 1.7.0 or later. See [Component Updates] Update CoreDNS.
If dig shows the tc flag in the response, the headless Service has too many backing IP addresses and the DNS response exceeds the UDP packet size limit. Configure the client to send DNS queries over TCP:
For glibc-based resolvers, add
use-vctodnsConfig:dnsConfig: options: - name: use-vcThis maps to the
optionsdirective in/etc/resolv.conf. For details, see the Linux man page for resolv.conf.For Go applications, configure the resolver to use TCP:
package main import ( "fmt" "net" "context" ) func main() { resolver := &net.Resolver{ PreferGo: true, Dial: func(ctx context.Context, network, address string) (net.Conn, error) { return net.Dial("tcp", address) }, } addrs, err := resolver.LookupHost(context.TODO(), "example.com") if err != nil { fmt.Println("Error:", err) return } fmt.Println("Addresses:", addrs) }
What to do if headless Service domain names cannot be resolved after updating CoreDNS
After upgrading to Kubernetes 1.20 or later with CoreDNS 1.8.4 or later, open-source components such as etcd, Nacos, and Kafka fail to discover services.
CoreDNS 1.8.4 switched to the EndpointSlice API. Some open-source components rely on the service.alpha.kubernetes.io/tolerate-unready-endpoints annotation from the older Endpoint API to publish not-ready Services during initialization. This annotation is not supported in EndpointSlice — it was replaced by publishNotReadyAddresses.
Check whether the YAML or Helm chart for the affected component uses service.alpha.kubernetes.io/tolerate-unready-endpoints. If it does, upgrade the component or consult the component's community.
What to do if StatefulSet pod domain names cannot be resolved
Domain names of StatefulSet pods (e.g., pod.headless-svc.ns.svc.cluster.local) cannot be resolved, but the headless Service's own domain name resolves correctly.
The StatefulSet pod YAML template has serviceName set to the wrong value or left blank. Set serviceName in the StatefulSet spec to the exact name of the headless Service that exposes the StatefulSet.
What to do if security group rules block DNS queries
DNS resolution fails on some or all nodes, persistently.
The security group rules or network access control lists (ACLs) on the ECS instances are blocking UDP port 53. Modify the security group rules or network ACLs to allow UDP port 53.
What to do if container network connectivity errors occur
DNS resolution fails on some or all nodes, persistently.
Container network connectivity errors or other issues are blocking UDP port 53. Use the network diagnostics feature to diagnose network connectivity between the application pods and the CoreDNS pod. If the issue persists, submit a ticket.
What to do if CoreDNS pods are overloaded
DNS resolution latency is high, or failures occur persistently or intermittently. CoreDNS pod CPU or memory usage is near the upper limit.
The number of CoreDNS replicas is too low to handle the DNS query volume. Take one or both of these steps:
Enable NodeLocal DNSCache to reduce the load on CoreDNS. See Configure NodeLocal DNSCache.
Scale out CoreDNS pods so that peak CPU utilization per pod stays below the node's available CPU headroom.
What to do if DNS query load is unbalanced
DNS resolution latency is high or failures are intermittent on some (not all) nodes. CoreDNS pod CPU utilization differs significantly between pods. Fewer than two CoreDNS replicas are running, or multiple pods are scheduled on the same node.
DNS queries are unevenly distributed due to imbalanced pod scheduling or SessionAffinity settings on the kube-dns Service. To fix this:
Scale out CoreDNS pods and schedule them on separate nodes.
Remove the
SessionAffinitysetting from the kube-dns Service. See Configure ACK to automatically update CoreDNS.
What to do if CoreDNS pods are not running as expected
DNS resolution latency is high, failures occur on some nodes, CoreDNS pods are not in Running state, the restart count keeps increasing, or the CoreDNS log shows errors.
Misconfigured YAML or a misconfigured CoreDNS ConfigMap is preventing pods from running. Check pod status and logs.
Common error messages:
| Error | Cause | Fix |
|---|---|---|
/etc/coredns/Corefile:4 - Error during parsing: Unknown directive 'ready' | The ready plugin in the Corefile is not supported by the current CoreDNS version | Delete ready (or the unsupported plugin) from the CoreDNS ConfigMap in kube-system |
Failed to watch *v1.Pod: Get "https://192.168.0.1:443/api/v1/": dial tcp 192.168.0.1:443: connect: connection refused | API server connection interrupted at log time | If DNS resolution was not affected during this period, this is not the root cause. Otherwise, diagnose CoreDNS network connectivity. |
[ERROR] plugin/errors: 2 www.aliyun.com. A: read udp 172.20.6.53:58814->100.100.2.136:53: i/o timeout | Upstream DNS server unreachable at log time | Check CoreDNS network connectivity to upstream DNS servers |
What to do if DNS fails because the client is overloaded
DNS errors occur intermittently or during peak hours. ECS instance monitoring shows abnormal NIC retransmission rates or high CPU utilization.
The ECS instance hosting the pod that sends DNS queries is fully loaded, causing UDP packet loss. Submit a ticket. In parallel, enable NodeLocal DNSCache to reduce per-node DNS load. See Configure NodeLocal DNSCache.
What to do if the conntrack table is full
DNS resolution fails frequently on some or all nodes during peak hours but works during off-peak hours. Running dmesg -H on the instance shows conntrack full in the logs during the failure window.
The Linux kernel conntrack table is full, so UDP and TCP packets cannot be processed. Increase the maximum number of entries in the conntrack table. See How do I increase the maximum number of tracked connections in the conntrack table of the Linux kernel?
What to do if the autopath plugin does not work as expected
External domain names occasionally fail to resolve or resolve to a wrong IP address, while internal domain names resolve correctly. When the cluster creates containers at a high rate, internal domain names are occasionally resolved to wrong IP addresses.
The autopath plugin in CoreDNS has a known defect. Disable it:
Edit the CoreDNS ConfigMap:
kubectl -n kube-system edit configmap corednsDelete the
autopath @kubernetesline, save the file, and exit.Verify that CoreDNS loaded the new configuration by checking the logs for the
reloadkeyword.
What to do if DNS fails due to concurrent A and AAAA record queries
CoreDNS DNS resolution fails intermittently. Packet captures or DNS query logs show A record and AAAA record queries sent simultaneously over the same source port.
Concurrent A and AAAA record queries cause conntrack table errors, which lead to UDP packet loss. On ARM machines, libc versions earlier than 2.33 have this issue (see GLIBC#26600).
Apply one or more of these fixes based on your environment:
NodeLocal DNSCache: reduces the impact of packet loss. See Configure NodeLocal DNSCache.
CentOS or Ubuntu with libc: update libc to 2.33 or later, or add resolver options:
options timeout:2 attempts:3 rotate single-request-reopen.PHP cURL: add
CURL_IPRESOLVE_V4to specify that domain names can be resolved only to IPv4 addresses. See curl_setopt.Alpine Linux: replace with a non-Alpine base image. See Alpine Linux caveats.
What to do if DNS fails due to IPVS errors
DNS resolution fails intermittently when nodes are added or removed from the cluster, when nodes shut down, or when CoreDNS is scaled in. Failures typically last about 5 minutes.
kube-proxy is running in IPVS mode. When UDP backend pods are removed from CentOS or Alibaba Cloud Linux 2 nodes with kernel versions earlier than 4.19.91-25.1.al7.x86_64, source port conflicts cause UDP packets to be dropped.
To fix this:
Enable NodeLocal DNSCache to bypass IPVS for DNS traffic. See Configure NodeLocal DNSCache.
Shorten the UDP session timeout in IPVS mode. See Change the UDP timeout period in IPVS mode.
NodeLocal DNSCache issues
What to do if NodeLocal DNSCache is not working
All DNS queries are reaching CoreDNS instead of NodeLocal DNSCache.
One of two things is happening:
DNSConfig injection is not configured, so pods still use the kube-dns Service IP.
The pod uses an Alpine Linux base image, which sends DNS queries concurrently to all configured nameservers (including both NodeLocal DNSCache and CoreDNS).
To fix the first cause, configure automatic DNSConfig injection. To fix the second, replace the Alpine-based image with a non-Alpine image. See Configure NodeLocal DNSCache and Alpine Linux caveats.
What to do if Alibaba Cloud DNS PrivateZone domain names cannot be resolved
When NodeLocal DNSCache is in use, domain names added to Alibaba Cloud DNS PrivateZone cannot be resolved, Alibaba Cloud service API endpoints containing vpc-proxy fail to resolve, or domain names resolve to wrong IP addresses.
Alibaba Cloud DNS PrivateZone does not support TCP. NodeLocal DNSCache must forward these queries over UDP. Add the prefer_udp setting to the CoreDNS configuration. See Configure CoreDNS.
If none of the above steps resolve the issue, submit a ticket.