DataWorks connects to Cloudera Distribution for Hadoop (CDH) and Cloudera Data Platform (CDP) clusters. After registering a cluster, you can run task development, scheduling, metadata management in Data Map, and Data Quality monitoring against it — without migrating the cluster itself.
Supported scope
Check the following constraints before you start. If your setup falls outside this scope, the registration will not succeed.
| Dimension | Supported values |
|---|---|
| Cluster versions | CDH 5.16.2, CDH 6.1.1, CDH 6.2.1, CDH 6.3.2, CDP 7.1.7, Custom Version |
| Resource group types | Serverless resource group (recommended), exclusive resource group for scheduling (earlier version only) |
| Regions | China (Beijing), China (Shanghai), China (Hangzhou), China (Shenzhen), China (Zhangjiakou), China (Chengdu), Germany (Frankfurt) |
Additional constraints:
-
New users can purchase only serverless resource groups.
-
Custom Version clusters can only use an exclusive resource group for scheduling of an earlier version, and require a support ticket after registration to initialize the environment.
Prerequisites
Before you begin, make sure you have:
-
Permission — one of the following:
-
An Alibaba Cloud account
-
A workspace member with the Workspace Administrator role. See Add workspace members and manage their roles.
-
A workspace member attached to the AliyunDataWorksFullAccess policy. See Grant permissions to a RAM user and Manage permissions for a RAM role, then add the user to the workspace.
-
-
A deployed CDH or CDP cluster with its configuration information ready. See Preparations: Obtain CDH or CDP cluster information and configure network connectivity.
Step 1: Go to the cluster registration page
-
Log on to the DataWorks console. In the top navigation bar, select the target region. In the left-side navigation pane, choose More > Management Center, select the workspace from the drop-down list, and then click Go to Management Center.
-
In the left-side navigation pane, click Cluster Management. On the Cluster Management page, click Register Cluster, and select CDH as the open source cluster type.
Step 2: Configure basic information
| Parameter | Description |
|---|---|
| Display Name of Cluster | The cluster's display name in DataWorks. Must be unique. |
| Cluster Version | The version to register. Fixed-component versions available: CDH 5.16.2, CDH 6.1.1, CDH 6.2.1, CDH 6.3.2, CDP 7.1.7. If none fits your needs, select Custom Version to configure component versions manually. |
| Cluster Name | Determines where the cluster's configuration information comes from. Select Registered cluster to reference a cluster already registered in another workspace, or New cluster to enter the configuration yourself. |
Step 3: Configure cluster connection information
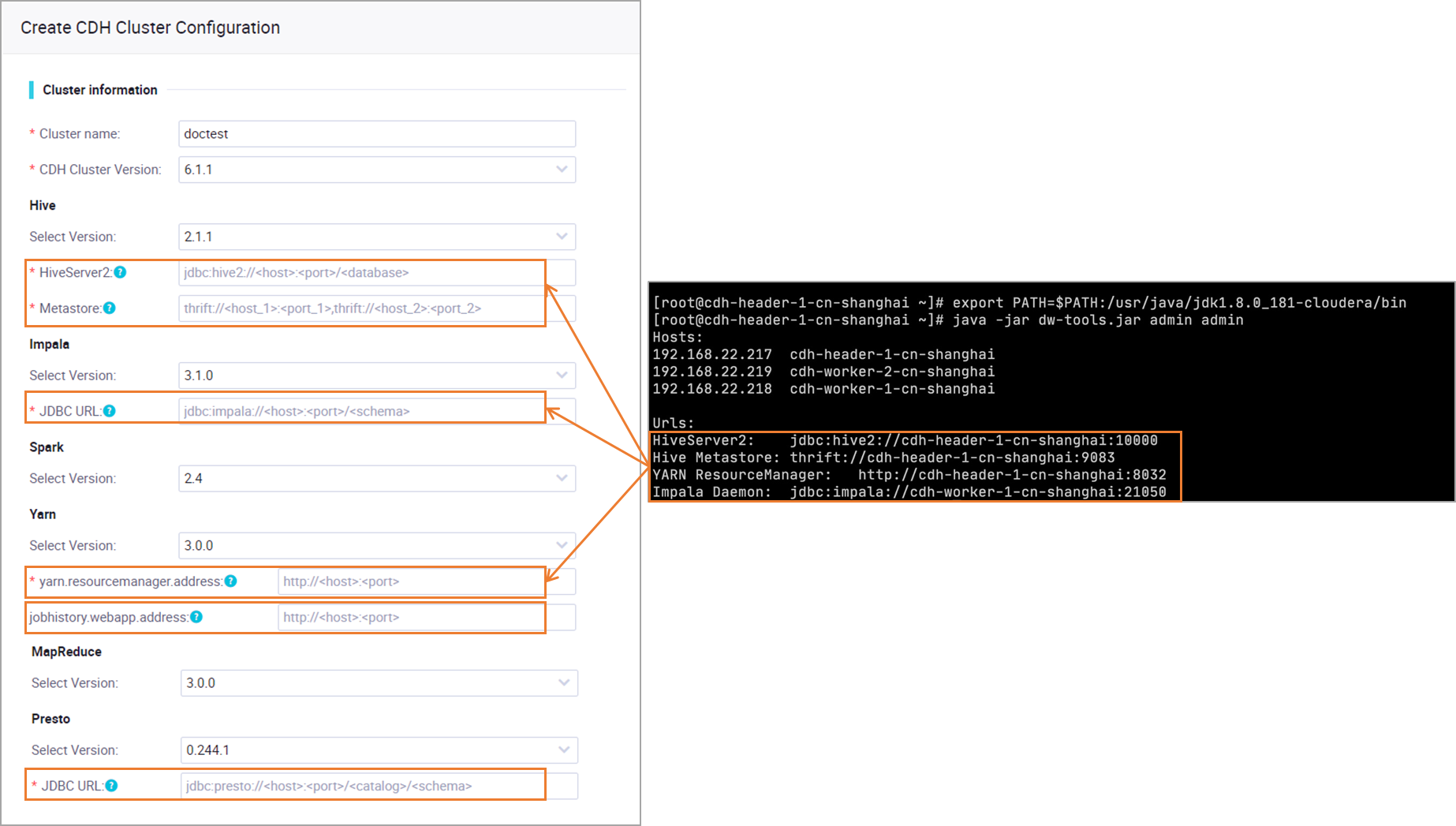
Select the component versions deployed in your cluster and enter the component addresses you obtained from the preparations guide. See Preparations: Obtain CDH or CDP cluster information and configure network connectivity.
Step 4: Add cluster configuration files
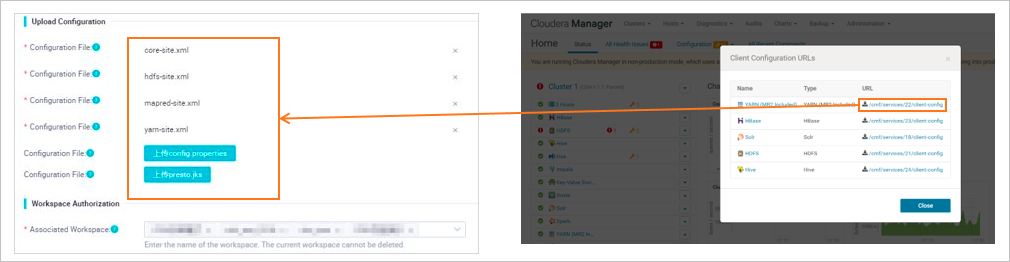
Upload the configuration files for the components you use. See Preparations: Obtain CDH or CDP cluster information and configure network connectivity for how to get these files.
| Configuration file | Description | Required when |
|---|---|---|
core-site.xml |
Global configurations of the Hadoop Core library, including common I/O settings for Hadoop Distributed File System (HDFS) and MapReduce | Running Spark or MapReduce tasks |
hdfs-site.xml |
HDFS configurations: data block size, number of replicas, and path names | |
mapred-site.xml |
MapReduce parameters: execution method and scheduling behavior | Running MapReduce tasks |
yarn-site.xml |
YARN daemon configurations: resource manager, node manager, and application runtime settings | Running Spark or MapReduce tasks, or when using Kerberos as the account mapping type (see Step 5) |
hive-site.xml |
Hive parameters: database connection info, Hive Metastore settings, and execution engine | Using Kerberos as the account mapping type (see Step 5) |
spark-defaults.conf |
Default Spark job settings: memory size and CPU cores | Running Spark tasks |
config.properties |
Presto server configurations: global properties for coordinator and worker nodes | Using the Presto component with OPEN LDAP or Kerberos as the account mapping type |
presto.jks |
Java KeyStore (JKS) file for SSL/TLS encrypted communication in Presto |
Step 5: Configure the default access identity
Choose the account used to access the CDH cluster when tasks run in DataWorks.
Cluster account
A fixed cluster account runs all CDH tasks, regardless of which DataWorks user (Alibaba Cloud account or RAM user) triggered them. This applies to both development and production environments.
Mapped account
DataWorks maps each task executor's account to a cluster account before running the task. The mapping rules differ by environment:
-
Development environment: Map the task executor's account (Alibaba Cloud account or RAM user with development permissions) to a cluster account.
-
Production environment: Map the task owner, Alibaba Cloud account, or RAM user to a cluster account.
To configure mappings, see Set cluster identity mappings.
After configuring all settings, click Complete Creation to register the cluster.
Step 6: Initialize a resource group
Initialize the resource group the first time you associate a cluster, and again whenever the cluster service configuration changes or a component is upgraded (for example, after modifying core-site.xml). This ensures the resource group can access the cluster using the current environment configuration.
On the Cluster Management page, find the registered cluster, click Initialize Resource Group in the upper-right corner, select the resource group, and confirm.
(Optional) Set a YARN resource queue
YARN resource queues partition cluster computing resources to prevent task interference across modules. On the Cluster Management page, find the cluster, go to the YARN Resource Queue tab, and click EditYARN Resource Queue to configure the settings.
(Optional) Set Spark properties
Assign dedicated Spark properties to tasks in different modules.
-
On the Cluster Management page, find the cluster.
-
Click the Spark-related Parameter tab, then click EditSpark-related Parameter.
-
Under the target module, click Add. Enter the Spark Property Name and Spark Property Value. See Spark configuration reference for available properties.
What's next
-
Set cluster identity mappings: If the default access identity is not a cluster account, configure mappings between DataWorks accounts and cluster accounts to enforce data permission isolation.
-
After you configure the CDH computing resource, you can use CDH-related nodes in DataStudio to perform data development operations.