When a node in a workflow needs output from multiple upstream nodes, or when multiple downstream nodes share the same constants and variables, managing those parameters node-by-node becomes error-prone and hard to maintain. A parameter node centralizes this: it collects parameters from upstream ancestors, defines constants and runtime variables, and exposes them all as a single, consistent set for downstream nodes.
Unlike regular task nodes, a parameter node runs no computation. It exists solely to hold and route parameters.
Prerequisites
Before you begin, ensure that you have:
A RAM user added to your workspace with the Develop or Workspace Administrator role. The Workspace Administrator role has broader permissions than most users need — assign it with caution. For details, see Add workspace members and assign roles to them.
A serverless resource group associated with your workspace. See Use serverless resource groups.
A parameter node created in your workflow. See Create a task node.
How it works
A parameter node sits between nodes in a directed acyclic graph (DAG). Upstream nodes feed their output parameters into it, and downstream nodes read from it using ${Parameter name} in their scripts.
Two common patterns:
Parameter passing between nodes — When a node needs output from multiple upstream nodes, place a parameter node in between. The parameter node collects all required outputs and exposes them as a unified set for the downstream node.

In this example, Sq_MySQL_G depends on outputs from both Sq_MySQL_B and Sq_MySQL_E. A parameter node is placed as a descendant of both and an ancestor of Sq_MySQL_G, consolidating all required parameters in one place.
Centralized parameter management — When multiple downstream nodes share the same constants or variables, define those parameters once in a parameter node and make it an ancestor of all the nodes that need them.

In this example, Sq2_MySQL_A, Sq2_MySQL_C, Sq2_MySQL_D, Sq2_MySQL_E, and Sq2_MySQL_F all share parameters managed through a single parameter node.
A node can only read parameters from a parameter node if it is a direct descendant of that parameter node. Indirect descendants cannot access the parameters.
Choose a parameter type
Use the following table to decide which parameter type fits your situation before you start configuring.
| Type | Use when | Value format |
|---|---|---|
| Constant | The value is fixed and known at authoring time | A literal string or number |
| Variable | The value changes at runtime (for example, the scheduling date or system time) | A scheduling parameter expression. See Supported formats of scheduling parameters. |
| Pass-through Variable | The value comes from an upstream ancestor node's output | Selected from the associated ancestor node's output parameters |
Step 1: Configure the parameter node
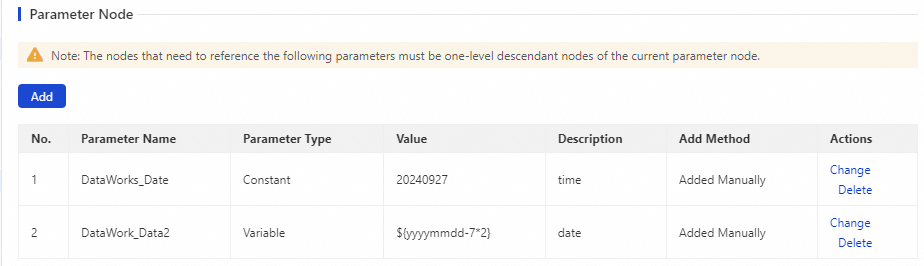
Add a constant parameter
The value of a constant parameter is fixed at authoring time.
On the configuration tab of the parameter node, click Add in the upper-left corner.
Set the following fields:
Field Description Parameter A name for this parameter. Downstream nodes reference it by this name. Parameter Type Select Constant. Value The fixed value for this parameter. Description (Optional) A description for your reference. Click Save in the Actions column.

Add a variable parameter
Use a variable parameter when the value is determined at runtime — for example, the scheduling date or a computed value.
On the configuration tab of the parameter node, click Add in the upper-left corner.
Set the following fields:
Field Description Parameter A name for this parameter. Downstream nodes reference it by this name. Parameter Type Select Variable. Value A scheduling parameter expression. See Supported formats of scheduling parameters. Description (Optional) A description for your reference. Click Save in the Actions column.
Add a pass-through variable parameter
A pass-through variable transparently forwards an upstream ancestor node's output parameter to the downstream nodes of the parameter node. Configure the upstream dependency before adding this parameter type.
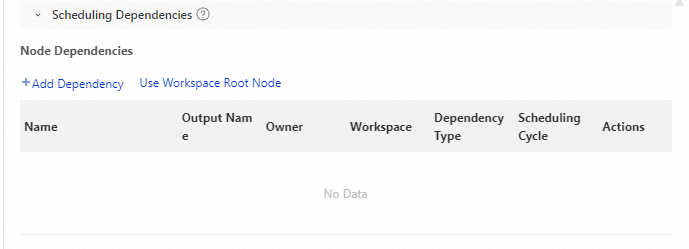
On the configuration tab of the parameter node, click Properties in the right-side navigation.
Click Scheduling Dependencies. In the Node Dependencies section, click Add Dependency and add the upstream ancestor node whose output you want to pass through.
In the Scheduling Parameters section, click Add Parameter.
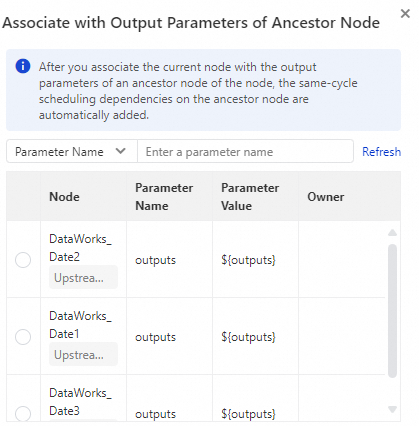
Enter a name for the parameter.
Click the
 icon to search for and select the output parameter from the ancestor node.
icon to search for and select the output parameter from the ancestor node.
Close the Properties tab and return to the configuration tab. Click Add in the upper-left corner.
Set the following fields:
Field Description Parameter A name for this parameter. Downstream nodes reference it by this name. Parameter Type Select Pass-through Variable. Value Select the parameter of the ancestor node that you associate on the Properties tab. Description (Optional) A description for your reference. Click Save in the Actions column.

After adding all parameters, configure the scheduling properties for the parameter node.
Step 2: Reference parameters in downstream nodes
Downstream nodes access parameters from the parameter node by adding a scheduling dependency on it and then referencing parameters in the node script.
Only direct descendant nodes of the parameter node can access its parameters. If a node is an indirect descendant (a descendant of a descendant), it cannot read the parameters.
Open the downstream node. In the Properties tab, click Scheduling Dependencies.
In the Node Dependencies section, click Add Dependency and add the parameter node as an upstream dependency.
In the Scheduling Parameters section, click Add Parameter.
Enter a name for the parameter.
Click the
icon to search for and associate the output parameters from the parameter node.
In the node script, reference each parameter using
${Parameter name}.
Step 3: Deploy and monitor
Deploy the parameter node along with its ancestor and descendant nodes to the production environment. See Node or workflow deployment.
After deployment, go to Operation Center > Auto Triggered Nodes to view the deployed nodes and perform O&M operations. DataWorks runs the nodes periodically based on the scheduling properties you configured. See Getting started with Operation Center.